Neste tutorial, mostramos como integrar um novo aplicativo, desenvolver um recurso para ele e implantá-lo na produção usando técnicas modernas de integração/entrega contínua (CI/CD) com o Google Kubernetes Engine (GKE).
Este documento faz parte de uma série:
- CI/CD moderno com GKE: um framework de entrega de software
- CI/CD moderno com o GKE: como criar um sistema de CI/CD (arquitetura de referência)
- CI/CD moderno com Anthos: como aplicar o fluxo de trabalho do desenvolvedor (este documento)
Neste tutorial, você vai usar ferramentas como
Skaffold,
kustomize,
Artifact Registry,
Config Sync,
Cloud Build e
Cloud Deploy para desenvolver, criar e implantar um aplicativo.
Este documento destina-se a arquitetos corporativos e desenvolvedores de aplicativos, bem como a equipes de segurança de TI, DevOps e engenharia de confiabilidade do site (SRE, na sigla em inglês). Ter alguma experiência com ferramentas e processos de implantação automatizados é útil para entender os conceitos apresentados neste documento.
Arquitetura
Neste tutorial, você aprenderá a integrar um novo aplicativo. Depois você vai desenvolver um novo recurso e implantar o aplicativo nos ambientes de desenvolvimento, preparo e produção. A arquitetura de referência contém a infraestrutura e as ferramentas necessárias para integrar e lançar um novo aplicativo com o fluxo de trabalho mostrado no diagrama a seguir:

A partir do repositório de código da CI, o fluxo de trabalho inclui as seguintes etapas:
Você compartilha o código-fonte do aplicativo por meio dos repositórios do seu aplicativo.
Quando você confirma e envia o código para o repositório do aplicativo, ele aciona automaticamente um pipeline de CI no Cloud Build. O processo de CI cria e envia uma imagem de contêiner para o Artifact Registry.
O processo de CI também cria uma versão de CD para o aplicativo no Cloud Deploy.
A versão CD gera manifestos do Kubernetes totalmente renderizados para o desenvolvedor usando
skaffolde os implanta no cluster dev do GKE.A versão de CD é promovida dev para um destino de preparo, que gera manifestos de preparo totalmente renderizados e os implanta no cluster de preparo do GKE.
Em seguida, a versão do CD é promovida do preparo para a produção, o que gera manifestos de produção totalmente renderizados e os implanta nos clusters de produção do GKE.
Para mais informações sobre as ferramentas e a infraestrutura usadas neste fluxo de trabalho, consulte CI/CD modernas com o GKE: como criar um sistema de CI/CD.
Objetivos
integrar um novo aplicativo.
Implante o aplicativo no ambiente de desenvolvimento.
Desenvolver um recurso novo e implantá-lo no ambiente de desenvolvimento.
Promover o novo recurso para preparo e lançamento para produção.
Testar a resiliência do aplicativo.
Custos
Neste documento, você usará os seguintes componentes faturáveis do Google Cloud:
- Google Kubernetes Engine
- Google Kubernetes Engine (GKE) Enterprise edition for Config Sync
- Artifact Registry
- Cloud Build
- Cloud Deploy
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
Ao concluir as tarefas descritas neste documento, é possível evitar o faturamento contínuo excluindo os recursos criados. Saiba mais em Limpeza.
Antes de começar
- Para este tutorial, implante a arquitetura de referência nesta série.
Prepare o ambiente
Se você estiver continuando diretamente do documento CI/CD moderno com Anthos: como criar um sistema de CI/CD, acesse a próxima etapa. No entanto, se você tiver uma nova sessão ou ela tiver expirado, abra o Cloud Shell e defina o projeto em que a infraestrutura de arquitetura de referência foi instalada:
gcloud config set core/project PROJECT_ID
Substitua
PROJECT_IDpelo ID do projeto do Google Cloud.
Integrar um novo aplicativo
A arquitetura de referência contém uma fábrica de aplicativos. Essa fábrica é uma coleção de um repositório git chamado application-factory-repo e dos seguintes gatilhos do Cloud Build:
create-apptf-plantf-applycreate-team
Use a fábrica de aplicativos para integrar um novo aplicativo dos repositórios iniciais. A integração do aplicativo consiste nas seguintes etapas:
Criar a definição do aplicativo: crie a definição do aplicativo em um arquivo do Terraform e armazene-a em
application-factory-repo, que funciona como um catálogo de aplicativos.Criar a infraestrutura do aplicativo: execute o Terraform no arquivo de definição do aplicativo para criar a infraestrutura dele. A infraestrutura do aplicativo consiste no seguinte:
Uma zona de destino para o novo aplicativo inclui a definição do namespace, da conta de serviço e das políticas básicas no repositório
acm-gke-infrastructure-repo. A zona de destino só é criada em um cluster dev GKE durante a integração de um novo aplicativo. Isso é feito para desbloquear os desenvolvedores para que eles possam usar o ambiente de desenvolvimento e começar a iterar nele. A zona de destino nos clusters de preparo e produção é criada com a abordagem GitOps. Essa abordagem é demonstrada posteriormente neste documento quando você estiver pronto para promover a versão nesses clusters.O repositório de infraestrutura do repositório inicial de infraestrutura que hospeda o código para criar o pipeline de CI no Cloud Build, o pipeline de CD no Cloud Deploy e o repositório do Artifact Registry para armazenar artefatos.
Um gatilho de infraestrutura do Cloud Build que usa o código no repositório de infraestrutura e cria os recursos com base na definição deles.
Um repositório de aplicativos do repositório inicial do aplicativo que hospeda o código-fonte do aplicativo.
Criar recursos de CI/CD do aplicativo: você usa a infraestrutura do aplicativo para criar recursos de CI/CD para ele.
Criar definição do aplicativo:
Execute o gatilho create-app para gerar um arquivo de definição de aplicativo em application-factory-repo. O arquivo de definição contém a definição declarativa dos recursos necessários para criar um aplicativo.
No console do Google Cloud, acesse a página do Cloud Build:
Clique em
create-appGatilho.Clique em MOSTRAR VISUALIZAÇÃO DO URL se quiser mostrar o URL necessário para invocar o webhook.
No Cloud Shell, invoque o gatilho fazendo uma solicitação curl no URL recebido na etapa anterior e transmitindo os parâmetros como um payload para ele.
curl "WEBHOOK_URL" -d '{"message": {"app": "sample","runtime": "python","trigger_type": "webhook","github_team": ""}}'
No exemplo de código anterior:
Substitua
WEBHOOK_URLpelo URL recebido do acionador."app": "sample": especifica o nome do aplicativo."runtime": "python"instrui a fábrica do aplicativo a usar o modelo Python para criar repositórios de aplicativos."trigger_type": "webhook"especifica o tipo de pipelines de CI/CD para o aplicativo."github_team": ""é uma equipe no GitHub que será associada aos repositórios criados para o aplicativo. Como você ainda não criou uma equipe do GitHub, transmita-a como uma string vazia.
Verifique o pipeline do gatilho
create-app:Acessar a página de gatilhos do Cloud Build
Há um novo pipeline para o gatilho
create-app. Quando esse processo for concluído, a definição do aplicativo será criada emapplication-factory-repo.Revise o arquivo de definição do aplicativo:
Em um navegador da Web, acesse o GitHub e faça login na sua conta.
Clique no ícone de imagem e depois em
Your organizations. Escolha sua organização.Clique no repositório
application-factory-repo, acesse a pastaapps/pythone abra o novo arquivo chamadosample.tf, criado pelo gatilhocreate-app. Inspecione o arquivo. Ele contém o código do Terraform para criar um novo aplicativo.
Crie a infraestrutura do aplicativo:
Agora que a definição do aplicativo foi criada, execute o gatilho tf-apply para criar a infraestrutura do aplicativo.
No console do Google Cloud
Acessar a página do Cloud Build
Clique em
tf-applyGatilho.Clique em "MOSTRAR VISUALIZAÇÃO DO URL" se quiser mostrar o URL necessário para invocar o webhook.
Invoque o gatilho:
curl "WEBHOOK_URL" -d '{}'
No exemplo de código anterior:
- Substitua
WEBHOOK_URLpelo URL recebido do acionador.
- Substitua
Verifique o pipeline do gatilho
tf-apply:Acessar a página de gatilhos do Cloud Build
Há um novo pipeline para o gatilho
tf-apply. Aguarde a conclusão.
Esse gatilho cria a infraestrutura do aplicativo.
Revise a infraestrutura do aplicativo:
Analisar os diversos componentes da infraestrutura do aplicativo.
Zona de destino
Acesse o Cloud Shell e defina o projeto.
gcloud config set core/project PROJECT_ID
Substitua
PROJECT_IDpelo ID do projeto do Google Cloud.Receber credenciais para o cluster de desenvolvimento do GKE.
gcloud container clusters get-credentials gke-dev-us-central1 --zone us-central1-aVerifique o namespace do aplicativo. O namespace tem o nome do aplicativo de amostra.
kubectl get namespaces sampleA saída será assim:
NAME STATUS AGE sample Active 15m
Verifique a conta de serviço no namespace.
kubectl get serviceaccounts -n sampleHá uma conta de serviço além da padrão. A saída será assim:
NAME SECRETS AGE default 0 15m sample-ksa 0 15m
Repositório de infraestrutura
Em um navegador da Web, acesse o GitHub e faça login na sua conta. Clique no ícone de imagem depois clique em Your organizations Escolha sua organização e clique no repositório sample-infra.
Esse repositório tem quatro ramificações: cicd-trigger, dev, staging e prod. Ela também contém quatro pastas: cicd-trigger, dev, staging e prod. A ramificação padrão é cicd-trigger e é possível enviar o código para ela enquanto outras ramificações têm regras de proteção. Portanto, não é possível enviar o código diretamente para elas. Para enviar o código para essas ramificações, é preciso criar uma solicitação de envio. A pasta cicd-trigger contém o código de criação de recursos de CI/CD para o aplicativo, enquanto as pastas dev, staging e prod têm o código para criar uma infraestrutura para diferentes ambientes do aplicativo.
Gatilho de infraestrutura
No console do Google Cloud
Acessar a página do Cloud Build
Há um novo gatilho chamado
deploy-infra-sample.Esse gatilho está conectado ao repositório
sample-infra. Quando ocorre um push de código, o gatilho é invocado e identifica a ramificação em que o push ocorreu e acessa a pasta correspondente nessa ramificação e executa o Terraform. Por exemplo, se o código for enviado para a ramificaçãocicd-trigger, o gatilho vai executar o Terraform na pasta cicd-trigger da ramificação cicd-trigger. Da mesma forma, quando um push acontece na ramificaçãodev, o gatilho executa o Terraform na pasta de desenvolvimento da ramificação dev e assim por diante.
Repositório do aplicativo
- Acesse o GitHub e extraia os repositórios da sua organização. Há um novo repositório com o nome
sample. Este repositório hospeda o código-fonte e as etapas para criar contêineres emDockerfile, configuraçõeskustomizeque descrevem as configurações necessárias do aplicativo eskaffold.yamlque define as etapas de implantação a serem usadas pelo Cloud Deploy para CD.
Criar recursos de CI/CD de aplicativo
Agora que você criou o esqueleto do aplicativo, execute o gatilho deploy-infra-sample para criar os recursos de CI/CD. É possível invocar o gatilho manualmente usando o URL do webhook ou fazendo uma confirmação no repositório git sample-infra.
Para invocar o gatilho do Cloud Build, adicione uma nova linha a um arquivo no repositório. Em seguida, envie as alterações por push:
Se você nunca usou o Git no Cloud Shell, configure-o com seu nome e endereço de e-mail. O Git usa essas informações para identificar você como o autor das confirmações que você cria no Cloud Shell.
git config --global user.email "GITHUB_EMAIL_ADDRESS" git config --global user.name "GITHUB_USERNAME"
Substitua:
GITHUB_EMAIL_ADDRESS: o endereço de e-mail associado à sua conta do GitHub.GITHUB_USERNAME: o nome de usuário associado à sua conta do GitHub.
Clonar o repositório git
sample-infra:git clone https://github.com/GITHUB_ORG/sample-infra cd sample-infra
Substitua:
GITHUB_ORGpela sua organização do GitHub.
A ramificação cicd-trigger padrão está marcada.
Adicione uma nova linha ao arquivo env/cicd-trigger/main.tf, confirme a mudança e envie por push.
echo "" >> env/cicd-trigger/main.tfConfirme e envie as alterações:
git add . git commit -m "A dummy commit to invoke the infrastrucutre trigger" git push cd ..Assim que as alterações forem enviadas, o gatilho do Cloud Deploy
deploy-infra-sampleserá iniciado.
Monitore o status do gatilho:
Acesse a página "Histórico do Cloud Build" para visualizar o pipeline e aguarde a conclusão.
Analisar os recursos de CICD do aplicativo
Revise os vários recursos de CI/CD criados para o aplicativo.
No console do Google Cloud:
Acesse a página do Cloud Build e visualize o gatilho
deploy-app-sample.Este é o gatilho do pipeline de CI. Ele está conectado ao repositório de código do aplicativo
sample. O gatilho é invocado quando um push é feito no repositório do aplicativo e executa as etapas de build conforme definido na configuração do gatilho. Para ver as etapas que o gatilho executa quando invocado, clique no nome do gatilho e no botão ABRIR O EDITOR.Acesse a página do Artifact Registry e veja o novo repositório com o nome
sample.Esse repositório de artefatos armazena os artefatos do aplicativo.
Acesse a página do pipeline do Cloud Deploy e exiba o pipeline com o nome
sample. Esse é o pipeline de implantação contínua que implanta o aplicativo nos clusters do GKE.
Implante o aplicativo no ambiente de desenvolvimento
O gatilho deploy-app-sample está conectado ao repositório do aplicativo chamado sample. Invoque o gatilho manualmente usando o URL do webhook ou enviando por push ao repositório do aplicativo.
Adicione uma nova linha a um arquivo no repositório
samplee envie as alterações por push para invocar o gatilho do Cloud Build:Clonar o repositório git
sample:No Cloud Shell, faça o seguinte:
git clone https://github.com/GITHUB_ORG/sample cd sample
Substitua
GITHUB_ORGpela sua prática do GitHub.Adicione uma nova linha ao arquivo
skaffold.yaml.echo "" >> skaffold.yamlConfirme e envie as alterações:
git add . git commit -m "A dummy commit to invoke CI/CD trigger" git pushAssim que as alterações forem enviadas, o gatilho do Cloud Deploy
deploy-app-sampleserá iniciado.
Monitore o status do gatilho:
Acesse a página "Histórico do Cloud Build" para visualizar o pipeline e aguarde a conclusão.
O gatilho executa as etapas definidas na configuração. A primeira etapa é criar uma imagem do Docker com base no código do aplicativo no repositório
sample. A última etapa é iniciar o pipeline do Cloud Deploy que implanta o aplicativo no cluster do GKE de desenvolvimento.Verifique a implantação no cluster de desenvolvimento:
Acessar a página do pipeline do Cloud Deploy.
Clique em
samplepipeline. A implantação no cluster dev GKE foi iniciada. Aguarde a conclusão.
Para validar a implantação do aplicativo:
Receber credenciais para o cluster de desenvolvimento.
gcloud container clusters get-credentials gke-dev-us-central1 --zone us-central1-aFaça um túnel no cluster do GKE.
gcloud container clusters get-credentials gke-dev-us-central1 --zone us-central1-a && kubectl port-forward --namespace sample $(kubectl get pod --namespace sample --selector="deploy.cloud.google.com/delivery-pipeline-id=sample" --output jsonpath='{.items[0].metadata.name}') 8080:8080Na barra de ferramentas do Cloud Shell, clique em
Visualização na Web e depois em Visualizar na porta 8080:
A saída é esta:
Hello World!
No Cloud Shell, pressione
CTRL+Cpara encerrar o encaminhamento da porta.
Adicionar um novo recurso ao aplicativo
Quando você desenvolve um novo recurso, é necessário implantar as alterações rapidamente em um sandbox de desenvolvimento para testá-las e iterá-las. Neste tutorial, você vai fazer alterações no repositório do código do aplicativo e implantá-las no ambiente de desenvolvimento.
No Cloud Shell, altere o diretório para o repositório
samplejá clonado:Atualize o aplicativo para gerar outra mensagem:
sed -i "s/Hello World/My new feature/g" main.pyConfirme e envie as alterações:
git add . git commit -m "Changed the message" git pushAssim que o código é enviado ao repositório do GitHub, o gatilho de webhook
deploy-app-sampleé iniciado.Monitore o status do gatilho na página "Histórico do Cloud Build" e aguarde a conclusão.
Acessar a página "Pipeline do Cloud Deploy"
Clique em
samplepipeline. A implantação no cluster dev GKE foi iniciada. Aguarde a conclusão.
Para validar a implantação do aplicativo:
Receba credenciais para o cluster de desenvolvimento se tiver aberto um novo Cloud Shell:
gcloud container clusters get-credentials gke-dev-us-central1 --zone us-central1-aConstrua um túnel no cluster do GKE:
gcloud container clusters get-credentials gke-dev-us-central1 --zone us-central1-a && kubectl port-forward --namespace sample $(kubectl get pod --namespace sample --selector="deploy.cloud.google.com/delivery-pipeline-id=sample" --output jsonpath='{.items[0].metadata.name}') 8080:8080Na barra de ferramentas do Cloud Shell, clique em
Visualização da Web e depois em Visualizar na porta 8080:
A saída é esta:
My new feature!
No Cloud Shell, pressione
CTRL+Cpara encerrar o encaminhamento da porta.
Promover a mudança nos clusters de preparo e produção
Antes de promover o aplicativo para os ambientes de preparo e produção, crie a zona de destino do aplicativo nos clusters do GKE desses ambientes. Quando você integrou o aplicativo, a zona de destino para desenvolvimento foi criada automaticamente no cluster dev GKE com a adição de código a acm-gke-infrastructure-repo na ramificação dev.
Criar zona de destino em clusters de preparo e produção do GKE
Criar zona de destino no cluster de preparo do GKE: é necessário criar uma solicitação de envio de dev para a ramificação de preparo em
acm-gke-infrastructure-repoe mesclá-la.Acesse o GitHub e navegue até o repositório
acm-gke-infrastructure-repo. Clique emPull requestse no botãoNew pull request. No menu Base, escolha staging e no menu Compare, selecione dev. Clique no botãoCreate pull request.Normalmente, alguém com acesso ao repositório revisa as alterações e, em seguida, mescla o PR para garantir que apenas as mudanças pretendidas sejam promovidas ao ambiente de teste. Para permitir que os indivíduos testem a arquitetura de referência, as regras de proteção de ramificações foram flexibilizadas para que o administrador do repositório possa ignorar a revisão e mesclar o PR. Se você for um administrador no repositório, mescle a solicitação de envio. Caso contrário, peça ao administrador para mesclá-lo.
O Config Sync sincroniza as alterações que chegam à ramificação de preparo do repositório
acm-gke-infrastructure-repocom o cluster de preparo do GKE, o que resulta na criação da zona de destino do aplicativo no cluster de preparo do GKE.Criar zona de destino em clusters de produção do GKE: é preciso criar uma solicitação de envio do preparo para a ramificação de produção e mesclá-la.
Clique em
Pull requestse no botãoNew pull request. No menu Base, escolha prod e no menu Comparar, escolha staging. Clique no botãoCreate pull request.Se você for um administrador no repositório, mescle a solicitação de envio. Caso contrário, peça ao administrador para mesclá-lo.
O Config Sync sincroniza as alterações que chegam à ramificação de produção do repositório
acm-gke-infrastructure-repocom os clusters de produção do GKE, o que resulta na criação da zona de destino do aplicativo nos clusters de produção do GKE.
Promover as mudanças do desenvolvimento para o preparo
Agora que você criou a zona de destino do aplicativo nos clusters de preparo e produção do GKE, promova o aplicativo do ambiente de desenvolvimento para o de preparo.
Encontre o nome da versão mais recente e salve-o como uma variável de ambiente:
export RELEASE=$(gcloud deploy targets describe dev --region=us-central1 --format="json" | jq -r '."Active Pipeline"[0]."projects/PROJECT_ID/locations/us-central1/deliveryPipelines/sample"."Latest release"' | awk -F '/' '{print $NF}')
Substitua
PROJECT_IDpelo ID do projeto do Google Cloud.Verifique se a variável de ambiente foi definida:
echo $RELEASE
No Cloud Shell, execute o comando a seguir para acionar a promoção da versão do ambiente de desenvolvimento para o de preparo:
gcloud deploy releases promote --release=$RELEASE --delivery-pipeline=sample --region=us-central1 --to-target=staging --quiet
Verifique a implantação de preparo:
Acessar a página "Pipeline do Cloud Deploy"
Clique em
samplepipeline. A implantação no cluster de preparo do GKE foi iniciada. Aguarde a conclusão.Verifique se a implantação de preparo foi bem-sucedida:
Receba credenciais para o cluster de preparo:
gcloud container clusters get-credentials gke-staging-us-central1 --zone us-central1-aConstrua um túnel no cluster do GKE:
gcloud container clusters get-credentials gke-staging-us-central1 --zone us-central1-a && kubectl port-forward --namespace sample $(kubectl get pod --namespace sample --selector="deploy.cloud.google.com/delivery-pipeline-id=sample" --output jsonpath='{.items[0].metadata.name}') 8080:8080Na barra de ferramentas do Cloud Shell, clique em
Visualização da Web e depois em Visualizar na porta 8080:
A saída é esta:
My new feature!
No Cloud Shell, pressione
CTRL+Cpara encerrar o encaminhamento da porta.
Promover as mudanças do preparo para a produção
Agora promova a versão de preparo para produção. Você tem dois clusters de produção, e o Cloud Deploy tem um destino para cada um deles chamado prod1 e prod2, respectivamente.
No Cloud Shell, execute o seguinte comando para acionar a promoção da versão de preparo para o cluster prod1:
gcloud deploy releases promote --release=$RELEASE --delivery-pipeline=sample --region=us-central1 --to-target=prod1 --quiet
Os clusters de lançamento para produção exigem aprovação. Por isso, o lançamento aguarda até que você o aprove. Para conferir:
Acessar a página "Pipeline do Cloud Deploy"
Clique em
samplepipeline. O lançamento para prod1 requer aprovação e o papel clouddeploy.approver é necessário para aprovar o lançamento. Como você é o proprietário do projeto, tem acesso para aprovar a liberação.Aprove a versão para prod1:
Execute o comando a seguir para buscar o nome do lançamento com aprovação pendente e salvar em uma variável de ambiente:
export ROLLOUT=$(gcloud deploy targets describe prod1 --region=us-central1 --format="json" | jq -r '."Pending Approvals"[]' | awk -F '/' '{print $NF}')
Aprove a versão:
gcloud deploy rollouts approve $ROLLOUT --delivery-pipeline=sample --region=us-central1 --release=$RELEASE --quiet
Após a aprovação, a versão prod1 é iniciada. Monitore o progresso na página do pipeline do Cloud Deploy.
Após a conclusão da implantação prod1, inicie a versão prod2.
gcloud deploy releases promote --release=$RELEASE --delivery-pipeline=sample --region=us-central1 --to-target=prod2 --quiet
A versão para prod2 também requer aprovação. Aprove a versão para o cluster prod2:
Execute o comando a seguir para buscar o nome do lançamento com aprovação pendente e salvar em uma variável de ambiente:
export ROLLOUT=$(gcloud deploy targets describe prod2 --region=us-central1 --format="json" | jq -r '."Pending Approvals"[]' | awk -F '/' '{print $NF}')
Aprove a versão:
gcloud deploy rollouts approve $ROLLOUT --delivery-pipeline=sample --region=us-central1 --release=$RELEASE --quiet
Após a aprovação, a versão prod2 é iniciada. Monitore o progresso na página do pipeline do Cloud Deploy.
Verificar se a implantação no cluster de produção foi bem-sucedida após a conclusão dos pipelines do Cloud Deploy em prod1 e prod2.
Há uma Entrada em vários clusters criada nos clusters de produção, e você usa um balanceador de carga para acessar o aplicativo de produção. Essas configurações da Entrada em vários clusters são criadas usando os arquivos YAML k8s/prod/mci.yaml e k8s/prod/mcs.yaml no repositório
sample. Quando você envia uma solicitação ao endereço IP do balanceador de carga, a Entrada em vários clusters encaminha a solicitação a uma das duas instâncias do aplicativo em execução em dois clusters diferentes do GKE.Liste a regra de encaminhamento associada ao balanceador de carga para encontrar o endereço IP.
gcloud compute forwarding-rules list
A saída será assim:
NAME: mci-qqxs9x-fw-sample-sample-ingress REGION: IP_ADDRESS: 34.36.123.118 IP_PROTOCOL: TCP TARGET: mci-qqxs9x-sample-sample-ingress
Abra um navegador da Web e digite o seguinte no URL:
http://IP_ADDRESS:80
Substitua
IP_ADDRESSpelo endereço IP do balanceador de carga.A saída é esta:
My new feature!
Isso confirma que o aplicativo foi implantado como esperado nos clusters de produção.
Testar a resiliência do aplicativo
Nesta seção, você vai testar a resiliência do aplicativo em execução na produção reiniciando um dos dois nós dos clusters de produção do GKE sem afetar o aplicativo.
O aplicativo na produção usa a entrada em vários clusters e é acessível por meio de um IP do balanceador de carga. Quando o aplicativo é acessado por esse IP, a entrada de vários clusters o encaminha para uma das duas instâncias do aplicativo em execução em dois clusters diferentes do GKE. Quando um dos clusters do GKE não está íntegro e a instância do aplicativo em execução nele não pode ser acessada, a entrada em vários clusters continua enviando o tráfego para a instância íntegra do aplicativo em execução no outro cluster do GKE. Isso faz com que a falha do cluster fique invisível para o usuário final, e o aplicativo atende às solicitações continuamente.
Para testar a resiliência:
Encontre o pool de nós dos clusters de produção do GKE em execução na região us-west1.
gcloud container clusters describe gke-prod-us-west1 --zone=us-west1-a --format=json | jq ".nodePools[0].instanceGroupUrls[]" | tr '"' ' ' | awk -F '/' '{for(i=NF-2; i<=NF; i=i+2) printf ("%s ",$i); print ""}'
A saída será assim:
us-west1-b gke-gke-prod-us-west1-node-pool-01-6ad4e1ed-grp us-west1-c gke-gke-prod-us-west1-node-pool-01-98407373-grp
A saída tem duas colunas: a primeira é a zona e a segunda é o nome do grupo de instâncias associado ao pool de nós do cluster de produção do GKE na região us-west1.
Reinicie o grupo de instâncias correspondente aos pools de nós:
gcloud compute instance-groups managed rolling-action restart INSTANCE_GROUP_1 --zone=ZONE_1 --max-unavailable=100% gcloud compute instance-groups managed rolling-action restart INSTANCE_GROUP_2 --zone=ZONE_2 --max-unavailable=100%
Substitua
INSTANCE_GROUP_1pelo nome do primeiro grupo de instâncias.Substitua
ZONE_1pela zona do primeiro grupo de instâncias.Substitua
INSTANCE_GROUP_2pelo nome do segundo grupo de instâncias.Substitua
ZONE_2pela zona do segundo grupo de instâncias.Verifique o status do grupo de instâncias.
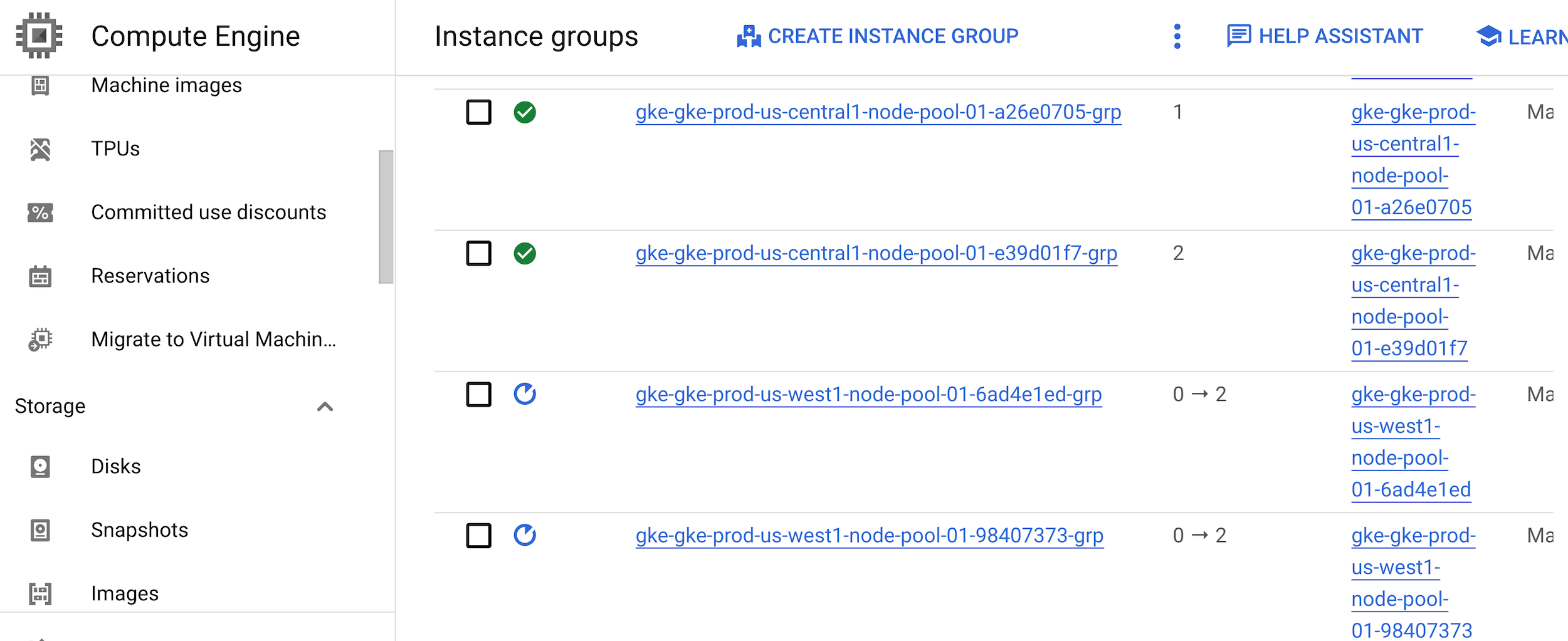
Acessar a página "Grupos de instâncias"
Os dois grupos de instâncias estão sendo reinicializados enquanto os outros grupos têm uma marca de seleção verde.
Abra um navegador da Web e digite o seguinte no URL:
http://IP_ADDRESS:80
Substitua
IP_ADDRESSpelo endereço IP do balanceador de carga.Mesmo quando um dos dois clusters do GKE está inativo, o aplicativo fica disponível, e a saída é a seguinte:
My new feature!
Isso mostra que seu aplicativo é resiliente e altamente disponível.
Gerenciar o aplicativo
Quando criou este aplicativo da fábrica de aplicativos, você recebeu repositórios Git, infraestrutura e pipelines de CI/CD separados para ele. Você usou esses recursos para implantar o aplicativo e adicionar um novo recurso. Para gerenciar ainda mais o aplicativo, você só precisa interagir com esses repositórios git e o pipeline sem precisar atualizar a fábrica do aplicativo. É possível personalizar os pipelines e os repositórios git do aplicativo com base nos seus requisitos. Como proprietário de um aplicativo, é possível definir quem tem acesso aos pipelines e aos repositórios git do seu aplicativo para gerenciá-lo.
Limpar
Para evitar cobranças dos recursos usados neste tutorial na sua conta do Google Cloud, siga estas etapas.
Excluir o projeto
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
A seguir
- Conheça as práticas recomendadas para configurar a federação de identidade.
- Leia sobre o Kubernetes e os desafios da implantação contínua de software.
- Saiba mais sobre os padrões de monitoramento e geração de registros de nuvem híbrida e várias nuvens.
- Confira arquiteturas de referência, diagramas e práticas recomendadas do Google Cloud. Confira o Centro de arquitetura do Cloud.