Most load balancers use a round-robin or flow-based hashing approach to distribute traffic. However, load balancers that use this approach can have difficulty adapting when demand spikes beyond available serving capacity. This article explains how using Cloud Load Balancing can address these issues and optimize your global application capacity. This often results in a better user experience and lower costs compared to traditional load-balancing implementations.
This article is part of a best practices series focused on Google's Cloud Load Balancing products. For a tutorial that accompanies this article, see Capacity Management with Load Balancing. For a deep dive on latency, see Optimizing Application Latency with Load Balancing.
Capacity challenges in global applications
Scaling global applications can be challenging, especially if you have limited IT budgets and unpredictable and bursty workloads. In public cloud environments such as Google Cloud, the flexibility provided by features like autoscaling and load balancing can help. However, autoscalers have some limitations, as explained in this section.
Latency in starting new instances
The most common issue with autoscaling is that the requested application isn't ready to serve your traffic quickly enough. Depending on your VM instance images, scripts typically must be run and information loaded before VM instances are ready. It often takes a few minutes before load balancing is able to direct users to new VM instances. During that time, traffic is distributed to existing VM instances, which might already be over capacity.
Applications limited by backend capacity
Some applications can't be autoscaled at all. For example, databases often have limited backend capacity. Only a specific number of frontends can access a database that doesn't scale horizontally. If your application relies on external APIs that support only a limited number of requests per second, the application also can't be autoscaled.
Non-elastic licenses
When you use licensed software, your license often limits you to a preset maximum capacity. Your ability to autoscale might therefore be restricted because you can't add licenses on the fly.
Too little VM instance headroom
To account for sudden bursts of traffic, an autoscaler should include ample headroom (for example, the autoscaler is triggered at 70% of CPU capacity). To save costs, you might be tempted to set this target higher, such as 90% of CPU capacity. However, higher trigger values might result in scaling bottlenecks when confronted with bursts of traffic, such as an advertising campaign that suddenly increases demand. You need to balance headroom size based on how spiky your traffic is and how long your new VM instances take to get ready.
Regional quotas
If you have unexpected bursts in a region, your existing resource quotas might limit the number of instances you can scale to below the level required to support the current burst. Processing an increase to your resource quota can take a few hours or days.
Addressing these challenges with global load balancing
The external Application Load Balancers and external proxy Network Load Balancers are global load balancing products proxied through globally synchronized Google Front End (GFE) servers, making it easier to mitigate these types of load balancing challenges. These products offer a solution to the challenges because traffic is distributed to backends differently than in most regional load balancing solutions.
These differences are described in the following sections.
Algorithms used by other load balancers
Most load balancers use the same algorithms to distribute traffic between backends:
- Round-robin. Packets are equally distributed between all backends regardless of the packets' source and destination.
- Hashing. Packet flows are identified based on hashes of traffic information, including source IP, destination IP, port, and protocol. All traffic that produces the same hash value flows to the same backend.
Hashing load balancing is the algorithm currently available for external passthrough Network Load Balancers. This load balancer supports 2-tuple hashing (based on source and destination IP), 3-tuple hashing (based on source IP, destination IP, and protocol), and 5-tuple hashing (based on source IP, destination IP, source port, destination port, and protocol).
With both of these algorithms, unhealthy instances are taken out of the distribution. However, current load on the backends is rarely a factor in load distribution.
Some hardware or software load balancers use algorithms that forward traffic based on other metrics, such as weighted round-robin, lowest load, fastest response time, or number of active connections. However, if load increases over the expected level due to sudden traffic bursts, traffic is still distributed to backend instances that are over capacity, leading to drastic increases in latency.
Some load balancers allow advanced rules where traffic that exceeds the backend's capacity is forwarded to another pool or redirected to a static website. This enables you to effectively reject this traffic and send a "service unavailable, please try again later" message. Some load balancers give you the option to put requests in a queue.
Global load balancing solutions are often implemented with a DNS-based algorithm, serving different regional load balancing IPs based on the user's location and backend load. These solutions offer failover to another region for all or part of the traffic for a regional deployment. However, on any DNS-based solution, failover usually takes minutes, depending on the time-to-live (TTL) value of the DNS entries. In general, a small amount of traffic will continue to be directed to the old servers well past the time that the TTL should have expired everywhere. DNS-based global load balancing is therefore not the optimal solution for dealing with traffic in bursty scenarios.
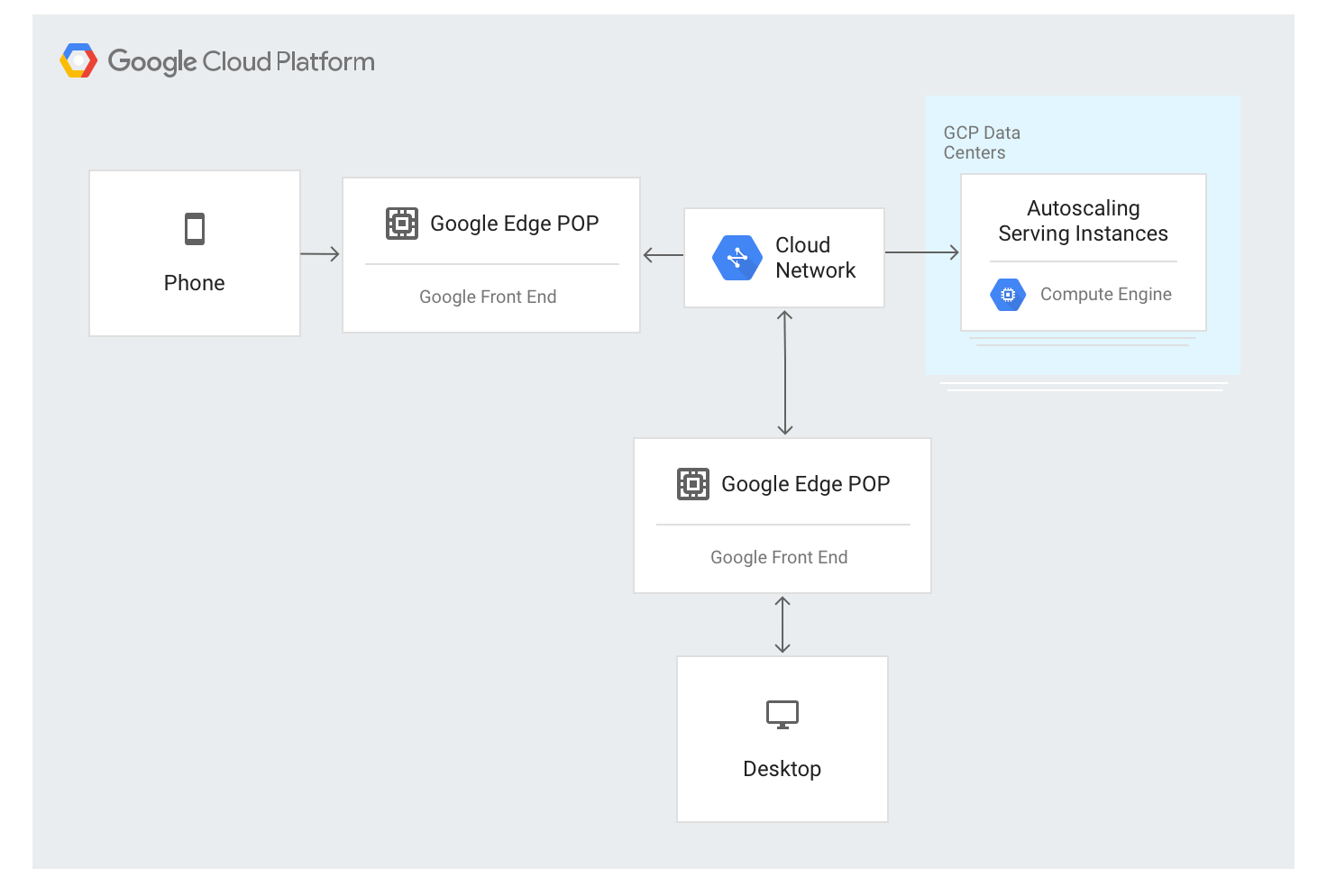
How external Application Load Balancers work
The external Application Load Balancer uses a different approach. Traffic is proxied through GFE servers deployed throughout most of Google's global network edge locations. This currently constitutes over 80 locations around the world. The load balancing algorithm is applied at the GFE servers.

The external Application Load Balancer is available through a single stable IP address that is announced globally at the edge nodes, and the connections are terminated by any of the GFEs.
The GFEs are interconnected through Google's global network. Data that describes available backends and the available serving capacity for each load-balanced resource is continually distributed to all GFEs using a global control plane.
Traffic to load-balanced IP addresses is proxied to backend instances that are defined in the external Application Load Balancer configuration using a special load balancing algorithm called Waterfall by Region. This algorithm determines the optimal backend for servicing the request by taking into account the proximity of the instances to the users, the incoming load as well as the available capacity of backends in each zone and region. Finally, worldwide load and capacity is also taken into account.
The external Application Load Balancer distributes traffic based on available instances. To add new instances based on load, the algorithm works in conjunction with autoscaling instance groups.
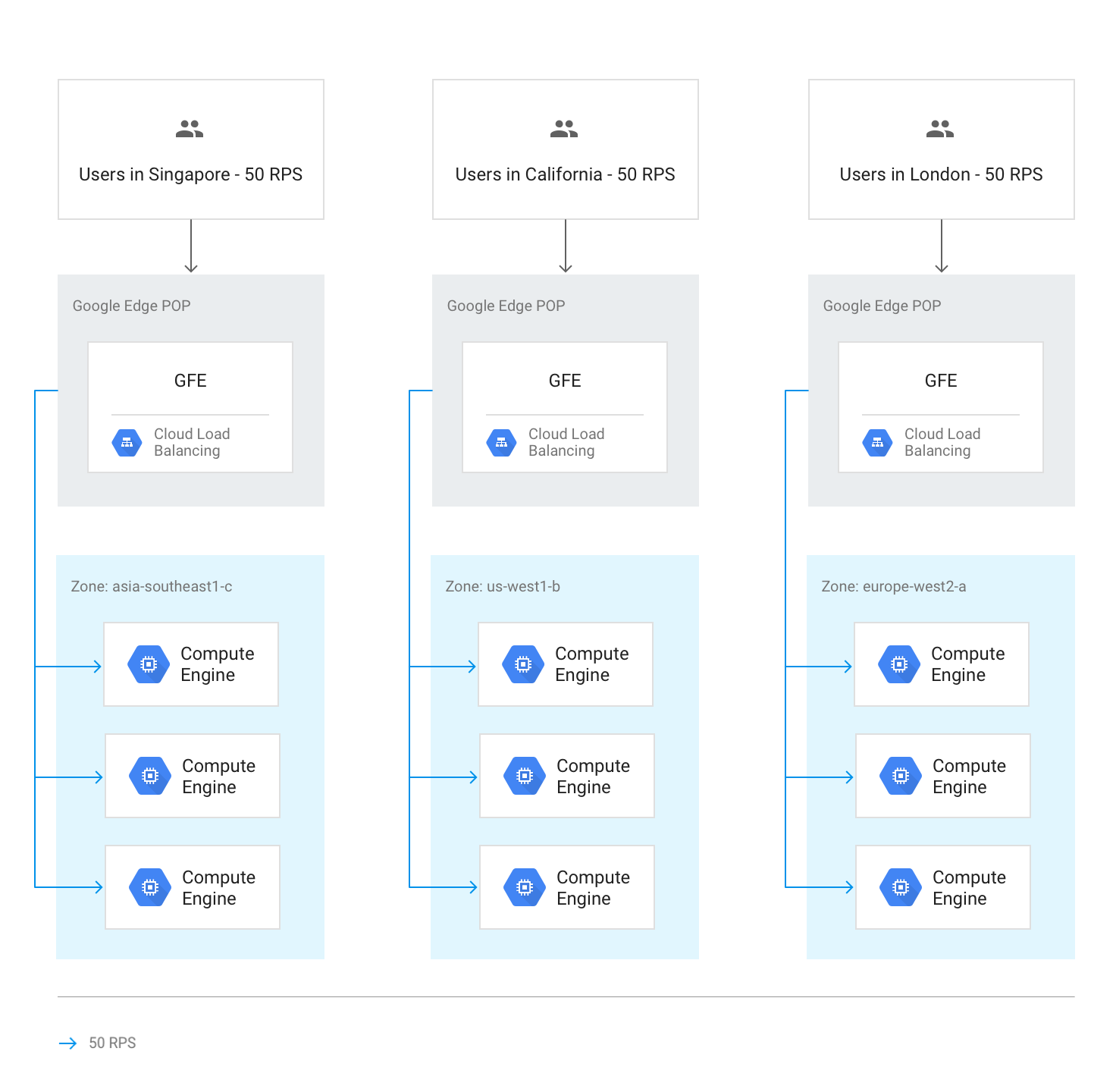
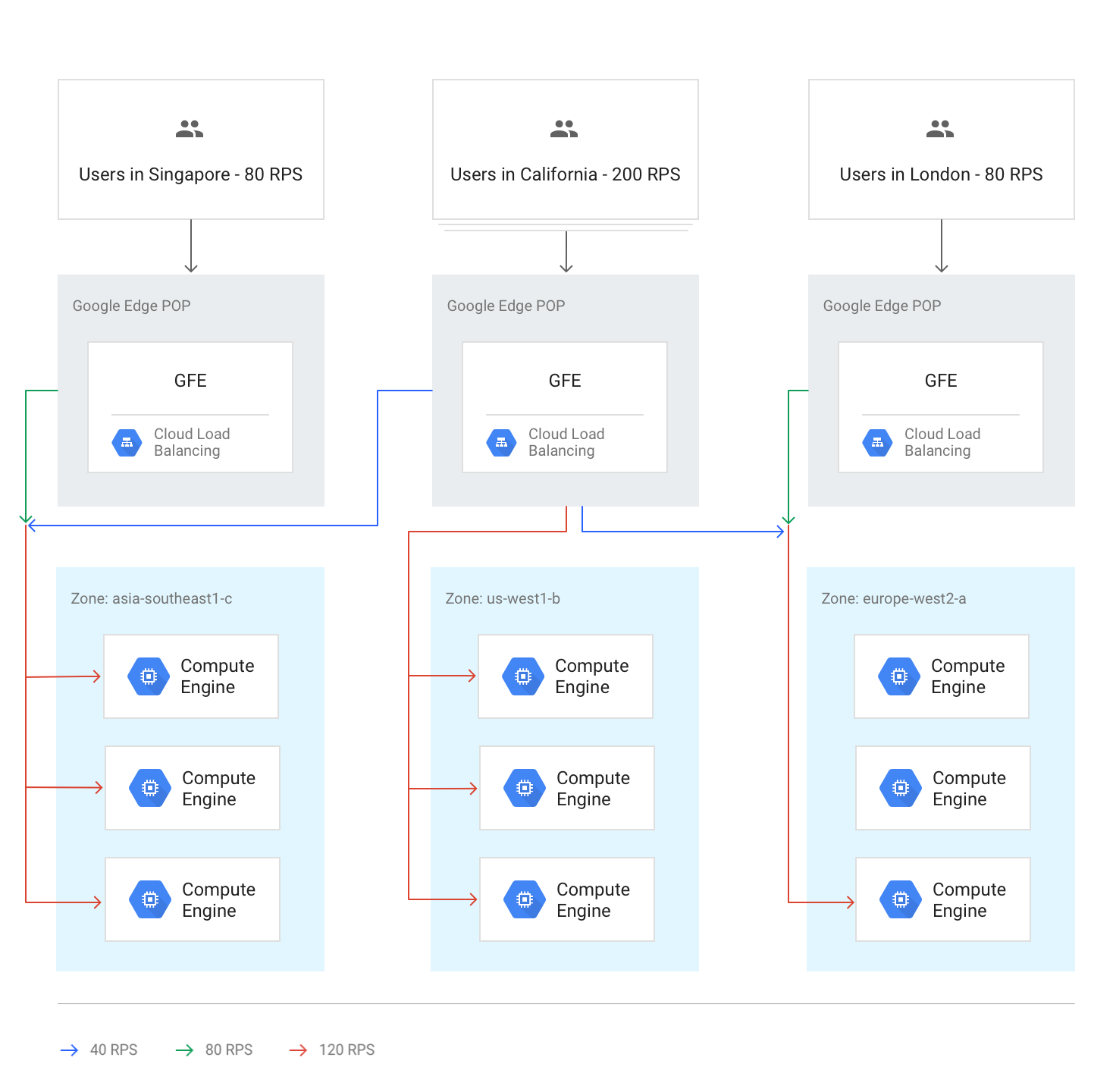
Traffic flow within a region
Under normal circumstances, all traffic is sent to the region closest to the user. Load balancing is then performed according to these guidelines:
Within each region, traffic is distributed across instance groups, which can be in multiple zones according to each group's capacity.
If capacity is unequal between zones, zones are loaded in proportion to their available serving capacity.
Within zones, requests are spread evenly over the instances in each instance group.
Sessions are persisted based on client IP address or on a cookie value, depending on the session affinity setting.
Unless the backend becomes unavailable, existing TCP connections never move to a different backend.
The following diagram shows load distribution in this case, where each region is under capacity and can handle the load from the users closest to that region.
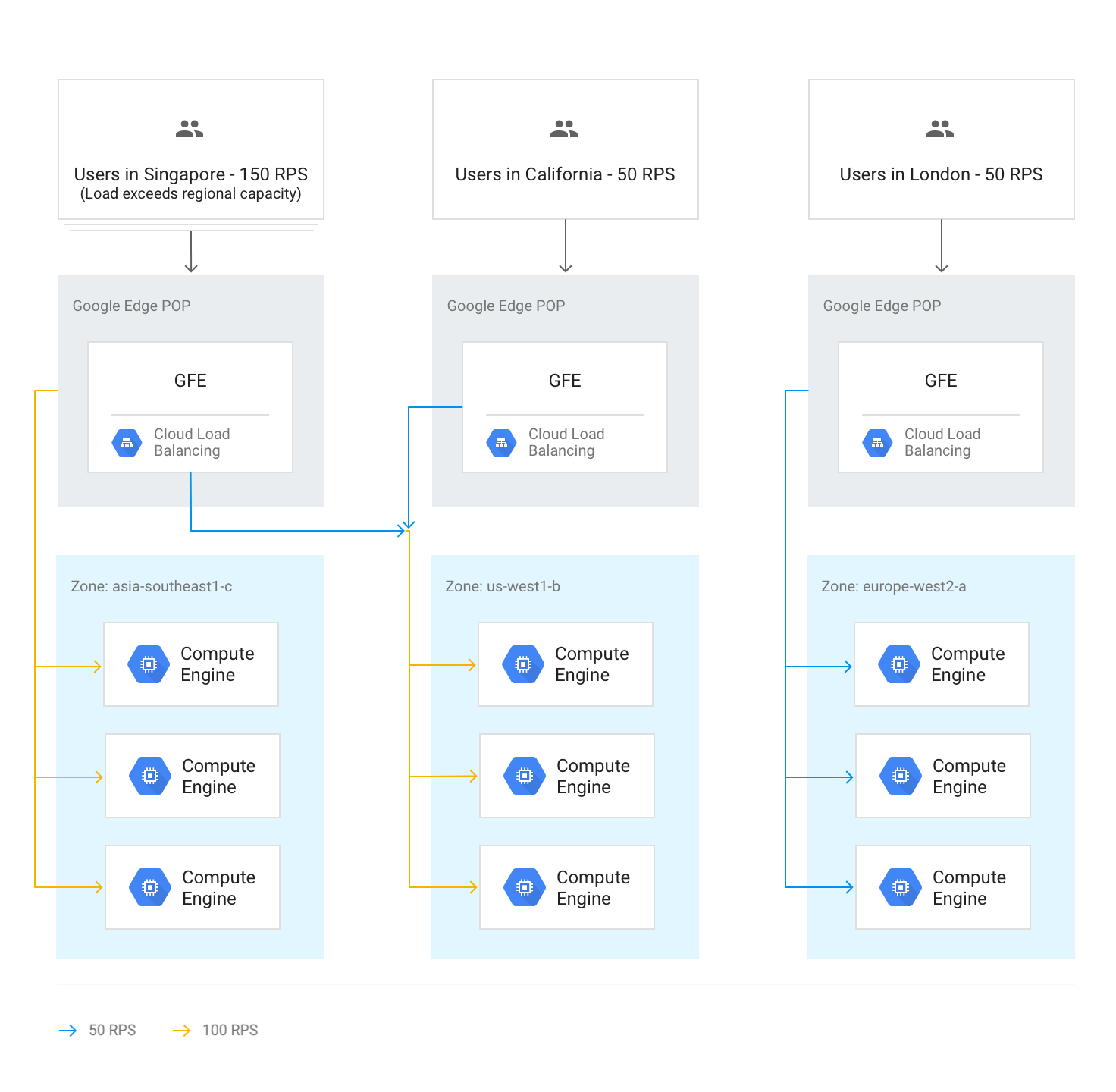
Traffic overflow to other regions
If an entire region reaches capacity as determined by the serving capacity set in the backend services, the Waterfall by Region algorithm is triggered, and traffic overflows to the closest region that has available capacity. As each region reaches capacity, traffic spills to the next closest region, and so on. A region's proximity to the user is defined by network round-trip time from the GFE to the instance backends.
The following diagram shows the overflow to the next closest region when one region receives more traffic than it can handle regionally.
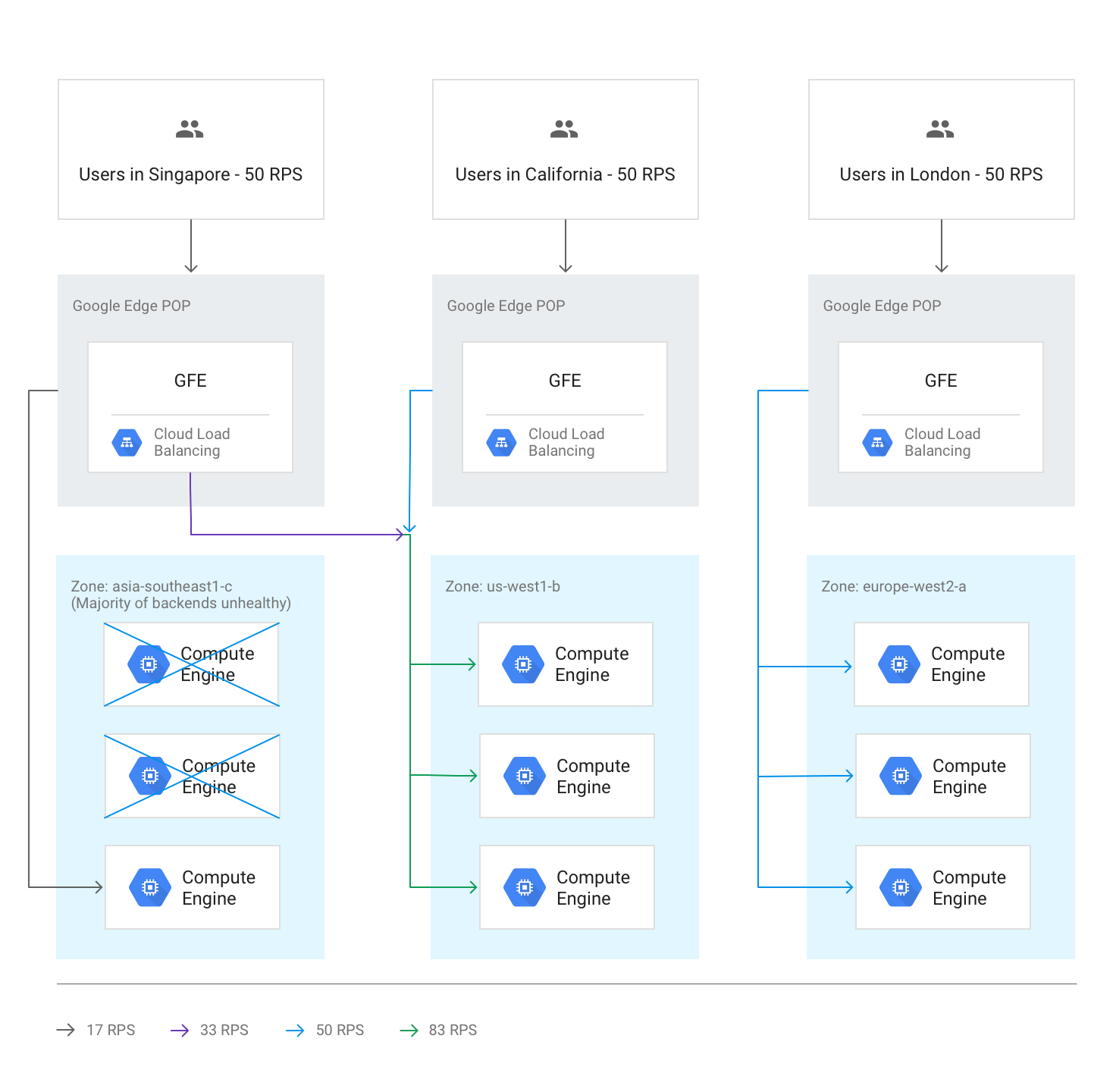
Cross-regional overflow due to unhealthy backends
If health checks discover that more than half of the backends in a region are unhealthy, the GFEs preemptively overflow some traffic to the next closest region. This happens in order to avoid traffic completely failing as the region becomes unhealthy. This overflow occurs even if the remaining capacity in the region with the unhealthy backends is sufficient.
The following diagram shows the overflow mechanism in effect, because the majority of backends in one zone are unhealthy.
All regions above capacity
When traffic to all regions is at or above capacity, traffic is balanced so that every region is at the same relative level of overflow compared to its capacity. For example, if global demand exceeds global capacity by 20%, traffic is distributed in a way that all regions receive requests at 20% over their regional capacity, while keeping traffic as local as possible.
The following diagram shows this global overflow rule in effect. In this case a single region receives so much traffic that it cannot be distributed at all with the available serving capacity globally.
Temporary overflow during autoscaling
Autoscaling is based on the capacity limits configured on each backend service and brings up new instances when traffic gets close to configured capacity limits. Depending on how quickly request levels are rising and how fast new instances come online, overflow to other regions might be unnecessary. In other cases, overflow can act as a temporary buffer until new local instances are online and ready to serve live traffic. When the capacity expanded by autoscaling is sufficient, all new sessions are distributed to the closest region.
Latency effects of overflow
According to the Waterfall by Region algorithm, overflow of some traffic by the external Application Load Balancer to other regions can occur. However, TCP sessions and SSL traffic are still terminated by the GFE closest to the user. This is beneficial to application latency; for details, see Optimizing Application Latency with Load Balancing.
Hands-on: Measuring effects of capacity management
To understand how overflow occurs and how you can manage it using the HTTP load balancer, see the Capacity Management with Load Balancing tutorial that accompanies this article.
Using an external Application Load Balancer to address capacity challenges
To help address the challenges discussed earlier, external Application Load Balancers and external proxy Network Load Balancers can overflow capacity to other regions. For global applications, responding to users with slightly higher overall latency results in a better experience than using a regional backend. Applications that use a regional backend have nominally lower latency, but they can become overloaded.
Let's revisit how an external Application Load Balancer can help address the scenarios mentioned at the beginning of the article:
Latency in starting new instances. If the autoscaler can't add capacity fast enough during local traffic bursts, the external Application Load Balancer temporarily overflows connections to the next closest region. This ensures that existing user sessions in the original region are handled at optimal speed as they remain on existing backends, while new user sessions experience only a slight latency bump. As soon as additional backend instances are scaled up in the original region, new traffic is again routed to the region closest to the users.
Applications limited by backend capacity. Applications that can't be autoscaled but that are available in multiple regions can still overflow to the next closest region when demand in one region is beyond capacity deployed for the usual traffic needs.
Non-elastic licenses. If the number of software licenses is limited, and if the license pool in the current region has been exhausted, the external Application Load Balancer can move traffic to a region where licenses are available. For this to work, the maximum number of instances is set to the maximum number of licenses on the autoscaler.
Too little VM headroom. The possibility of regional overflow helps to save money, because you can set up autoscaling with a high CPU usage trigger. You can also configure available backend capacity below each regional peak, because overflow to other regions ensures that global capacity will always be sufficient.
Regional quotas. If Compute Engine resource quotas don't match demand, the external Application Load Balancer overflow automatically redirects part of the traffic to a region that can still scale within its regional quota.
What's next
The following pages provide more information and background on Google's load balancing options:
- Capacity Management with Load Balancing Tutorial
- Optimizing Application Latency with Load Balancing
- Networking 101 Codelab
- External passthrough Network Load Balancer
- External Application Load Balancer
- External proxy Network Load Balancer