En este instructivo, se muestra cómo activar Filestore como un sistema de archivos de red en un servicio de Cloud Run para compartir datos entre varios contenedores y servicios. En este instructivo, se usa el entorno de ejecución de segunda generación de Cloud Run.
El entorno de ejecución de segunda generación permite que los sistemas de archivos de red se activen en un directorio en el contenedor. La activación de un sistema de archivos permite compartir recursos entre un sistema host y las instancias, y que los recursos se conserven después de que una instancia se recolecte de elementos no utilizados.
Usar un sistema de archivos de red con Cloud Run requiere conocimiento avanzado de Docker porque tu contenedor debe ejecutar varios procesos, incluidos el proceso de activación del sistema de archivos y la aplicación. En este instructivo, se explican los conceptos necesarios junto con un ejemplo funcional. Sin embargo, a medida que adaptas este instructivo a tu propia aplicación, asegúrate de comprender las implicaciones de cualquier cambio que puedas hacer.
Descripción general del diseño
La instancia de Filestore se aloja en una red (VPC) de nube privada virtual. Los recursos dentro de una red de VPC usan un rango de direcciones IP privadas para comunicarse con los servicios y las API de Google. Por lo tanto, los clientes deben estar en la misma red que la instancia de Filestore para acceder a los archivos almacenados en esa instancia. Se necesita un conector de Acceso a VPC sin servidores para que el servicio de Cloud Run se conecte a la red de VPC a fin de comunicarse con Filestore. Obtén más información sobre el Acceso a VPC sin servidores.
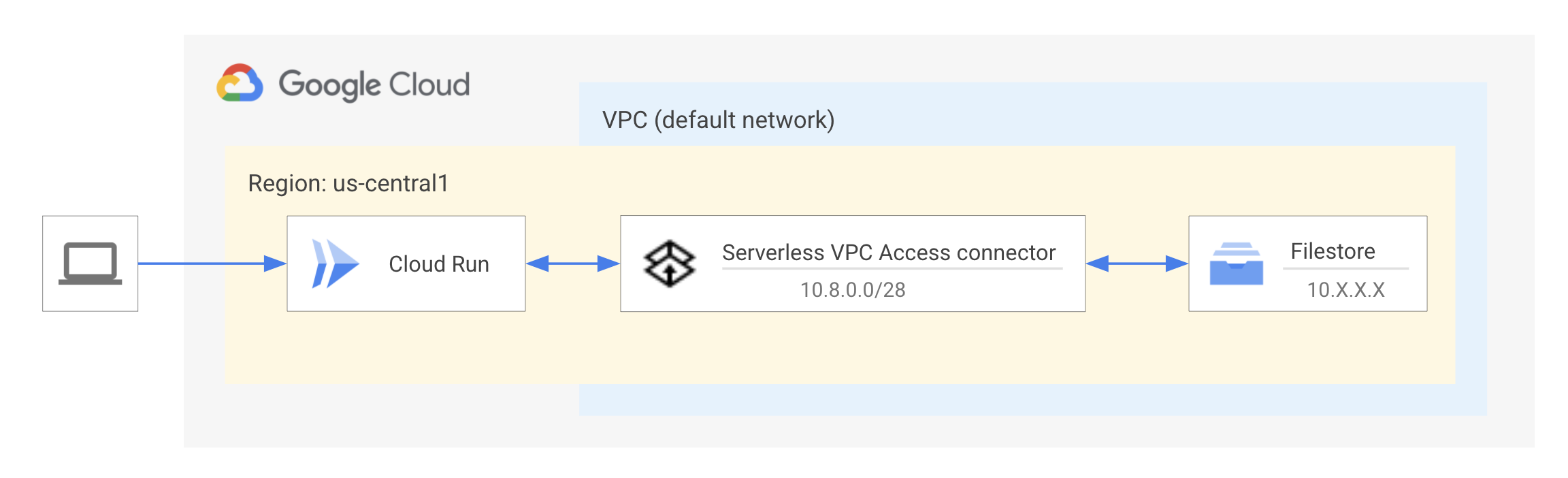
En el diagrama, se muestra el servicio de Cloud Run que se conecta a la instancia de Filestore a través de un conector de Acceso a VPC sin servidores. La instancia y el conector de Filestore están ubicados dentro de la misma red de VPC, “predeterminada” y en la misma región o zona que el servicio de Cloud Run para obtener el mejor rendimiento.
Limitaciones
En este instructivo, no se describe cómo elegir un sistema de archivos o requisitos listos para la producción. Obtén más información sobre Filestore y los niveles de servicio disponibles.
En este instructivo, no se muestra cómo trabajar con un sistema de archivos ni analizar los patrones de acceso a los archivos.
Objetivos
Crear una instancia de Filestore en la red de VPC predeterminada para que funcione como un recurso compartido de archivos.
Crear un conector de Acceso a VPC sin servidores en la misma red de VPC predeterminada para conectarte al servicio de Cloud Run.
Compilar un Dockerfile con paquetes del sistema y también init-process para administrar los procesos de activación y de la aplicación.
Implementar en Cloud Run y verificar el acceso al sistema de archivos en el servicio
Costos
En este instructivo, se usan componentes facturables de Google Cloud, incluidos los siguientes:
Antes de comenzar
- Accede a tu cuenta de Google Cloud. Si eres nuevo en Google Cloud, crea una cuenta para evaluar el rendimiento de nuestros productos en situaciones reales. Los clientes nuevos también obtienen $300 en créditos gratuitos para ejecutar, probar y, además, implementar cargas de trabajo.
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
-
Habilita las API de Cloud Run, Filestore, Serverless VPC Access, Artifact Registry, and Cloud Build .
- Instala e inicializa la CLI de gcloud
- Actualiza Google Cloud CLI:
gcloud components update
Roles obligatorios
Si quieres obtener los permisos que necesitas para completar el instructivo, pídele a tu administrador que te otorgue los siguientes roles de IAM en tu proyecto:
-
Administrador de Artifact Registry (
roles/artifactregistry.admin) -
Editor de Cloud Build (
roles/cloudbuild.builds.editor) -
Editor de Cloud Filestore (
roles/file.editor) -
Administrador de Cloud Run (
roles/run.admin) -
Usuario de la red de Compute (
roles/compute.networkUser) -
Administrador de Acceso a VPC sin servidores (
roles/vpcaccess.admin) -
Usuario de cuenta de servicio (
roles/iam.serviceAccountUser) -
Consumidor de Service Usage (
roles/serviceusage.serviceUsageConsumer) -
Administrador de almacenamiento (
roles/storage.admin)
Si quieres obtener más información para otorgar roles, consulta Administra el acceso.
También puedes obtener los permisos necesarios mediante roles personalizados o cualquier otro rol predefinido.
Configura los valores predeterminados de gcloud
A fin de configurar gcloud con los valores predeterminados para el servicio de Cloud Run, sigue estos pasos:
Configura el proyecto predeterminado:
gcloud config set project PROJECT_ID
Reemplaza PROJECT_ID por el nombre del proyecto que creaste para este instructivo.
Configura gcloud en la región que elegiste:
gcloud config set run/region REGION
Reemplaza REGION por la región de Cloud Run compatible que prefieras.
Configura gcloud para Filestore:
gcloud config set filestore/zone ZONE
Reemplaza ZONE por la zona de Filestore compatible que prefieras.
Recupera la muestra de código
A fin de recuperar la muestra de código para su uso, haz lo siguiente:
Clona el repositorio de la app de muestra en tu máquina local:
Node.js
git clone https://github.com/GoogleCloudPlatform/nodejs-docs-samples.git
De manera opcional, puedes descargar la muestra como un archivo zip y extraerla.
Python
git clone https://github.com/GoogleCloudPlatform/python-docs-samples.git
De manera opcional, puedes descargar la muestra como un archivo ZIP y extraerla.
Java
git clone https://github.com/GoogleCloudPlatform/java-docs-samples.git
De manera opcional, puedes descargar la muestra como un archivo ZIP y extraerla.
Ve al directorio que contiene el código de muestra de Cloud Run:
Node.js
cd nodejs-docs-samples/run/filesystem/
Python
cd python-docs-samples/run/filesystem/
Java
cd java-docs-samples/run/filesystem/
Comprende el código
Por lo general, debes ejecutar un solo proceso o aplicación dentro de un contenedor. Ejecutar un solo proceso por contenedor reduce la complejidad de administrar el ciclo de vida de varios procesos: administrar los reinicios, finalizar el contenedor si falla algún proceso y las responsabilidades del PID 1, como reenvío de señal y beneficios secundarios de zombis. Sin embargo, el uso de sistemas de archivos de red en Cloud Run requiere que uses contenedores de varios procesos para ejecutar el proceso de activación y la aplicación del sistema de archivos. En este instructivo, se muestra cómo finalizar el contenedor en caso de fallas en el proceso y administrar las responsabilidades del PID 1. El comando de activación tiene una funcionalidad integrada para controlar los reintentos.
Puedes usar un administrador de procesos para ejecutar y administrar varios procesos como el punto de entrada del contenedor. En este instructivo, se usa tini, un reemplazo de inicialización que limpia los procesos inertes y realiza el reenvío de señales. Específicamente, este proceso init permite que la señal SIGTERM en el cierre se propague a la aplicación. Se puede detectar la señal SIGTERM para obtener una finalización correcta de la aplicación. Obtén más información sobre el ciclo de vida de un contenedor en Cloud Run.
Define la configuración del entorno con el Dockerfile
Este servicio de Cloud Run requiere uno o más paquetes de sistema adicionales que no están disponibles de forma predeterminada. La instrucción RUN instalará tini como nuestro proceso init y nfs-common, que proporciona una funcionalidad mínima del cliente de NFS. Obtén más información para trabajar con paquetes del sistema en el servicio de Cloud Run en el instructivo Usa paquetes del sistema.
El siguiente conjunto de instrucciones creará un directorio de trabajo, copiará el código fuente e instalará las dependencias de la app.
ENTRYPOINT especifica el objeto binario init-process que se antepone a las instrucciones CMD, en este caso, es la secuencia de comandos de inicio. Esto inicia un único init-process y, luego, envía por proxy todas las señales recibidas a una sesión con permisos de administrador en ese proceso secundario.
Los conjuntos de instrucciones CMD establecen el comando que se ejecutará cuando se ejecute la imagen, la secuencia de comandos de inicio. También proporciona argumentos predeterminados para ENTRYPOINT. Comprende cómo interactúan CMD y ENTRYPOINT.
Node.js
Python
Java
Define tus procesos en la secuencia de comandos de inicio
La secuencia de comandos de inicio crea un directorio para que sea el punto de activación, en el que se podrá acceder a la instancia de Filestore. A continuación, la secuencia de comandos usa el comando mount a fin de adjuntar la instancia de Filestore. Para ello, especifica la dirección IP y el nombre del archivo compartido de la instancia, al punto de activación del servicio, y, luego, inicia el servidor de la aplicación. El comando mount tiene una función de reintento integrada. Por lo que no se necesita ninguna secuencia de comandos Bash. Por último, el comando wait se usa para detectar procesos en segundo plano y salir de la secuencia de comandos.
Node.js
Python
Java
Trabaja con archivos
Node.js
Consulta index.js para interactuar con el sistema de archivos.
Python
Consulta main.py para interactuar con el sistema de archivos.
Java
Consulta FilesystemApplication.java para interactuar con el sistema de archivos.
Envía el servicio
Crea una instancia de Filestore
gcloud filestore instances create INSTANCE_ID \ --tier=basic-hdd \ --file-share=name=FILE_SHARE_NAME,capacity=1TiB \ --network=name="default"Reemplaza INSTANCE_ID por el nombre de la instancia de Filestore, es decir,
my-filestore-instance, y FILE_SHARE_NAME por el nombre del directorio entregado desde la instancia de Filestore, es decir,vol1. Consulta Asigna un nombre a la instancia y Asigna un nombre al archivo compartido.Los clientes (servicio de Cloud Run) deben estar en la misma red que la instancia de Filestore para acceder a los archivos almacenados en esa instancia. Este comando crea la instancia en la red de VPC predeterminada y asigna un rango de direcciones IP gratuito. Los proyectos nuevos comienzan con una red predeterminada y es probable que no sea necesario crear una red separada.
Obtén más información sobre la configuración de instancias en Crea instancias.
Configura un conector de Acceso a VPC sin servidores.
Para conectarte a tu instancia de Filestore, tu servicio de Cloud Run necesita acceso a la red de VPC autorizada de la instancia de Filestore.
Cada conector de VPC requiere su propia subred
/28para colocar sus instancias. Este rango de IP no debe superponerse con ninguna reserva de dirección IP existente en la red de VPC. Por ejemplo,10.8.0.0(/28) funcionará en la mayoría de los proyectos nuevos o puedes especificar otro rango de IP personalizado sin usar, como10.9.0.0(/28). Puedes ver qué rangos de IP están reservados en este momento en la consola de Google Cloud.gcloud compute networks vpc-access connectors create CONNECTOR_NAME \ --region REGION \ --range "10.8.0.0/28"
Reemplaza CONNECTOR_NAME con el nombre de tu conector.
Este comando crea un conector en la red de VPC predeterminada, igual que la instancia de Filestore, con el tamaño de la máquina e2-micro. Aumentar el tamaño de la máquina del conector puede mejorar la capacidad de procesamiento del conector, pero también puede aumentar el costo. El conector también debe estar en la misma región que el servicio de Cloud Run. Obtén más información sobre la configuración del Acceso a VPC sin servidores.
Define una variable de entorno con la dirección IP para la instancia de Filestore:
export FILESTORE_IP_ADDRESS=$(gcloud filestore instances describe INSTANCE_ID --format "value(networks.ipAddresses[0])")
Crea una cuenta de servicio para que funcione como la identidad del servicio. De forma predeterminada, esta no tiene otros privilegios más que la membresía del proyecto.
gcloud iam service-accounts create fs-identity
No es necesario que este servicio interactúe con ningún otro elemento de Google Cloud. Por lo tanto, no se deben asignar permisos adicionales a esta cuenta de servicio.
Compila e implementa la imagen de contenedor en Cloud Run:
gcloud run deploy filesystem-app --source . \ --vpc-connector CONNECTOR_NAME \ --execution-environment gen2 \ --allow-unauthenticated \ --service-account fs-identity \ --update-env-vars FILESTORE_IP_ADDRESS=$FILESTORE_IP_ADDRESS,FILE_SHARE_NAME=FILE_SHARE_NAMEEste comando compila e implementa el servicio de Cloud Run, y especifica el conector de VPC y el entorno de ejecución de segunda generación. La implementación desde la fuente compilará la imagen según el Dockerfile y la enviará al repositorio de Artifact Registry:
cloud-run-source-deploy.Obtén más información sobre Implementa a partir del código fuente.
Depuración
Si la implementación no se realiza correctamente, consulta Cloud Logging para obtener más detalles.
Si se agota el tiempo de espera de la conexión, asegúrate de proporcionar la dirección IP correcta de la instancia de Filestore.
Si el servidor rechazó el acceso, verifica que el nombre del archivo compartido sea correcto.
Si deseas todos los registros del proceso de activación, usa la marca
--verboseen combinación con el comando de activación:mount --verbose -o nolock $FILESTORE_IP_ADDRESS:/$FILE_SHARE_NAME $MNT_DIR.
Prueba
Para probar el servicio completo, haz lo siguiente:
- Dirige tu navegador a la URL proporcionada en el paso de implementación anterior.
- Debería ver un archivo recién creado en su instancia de Filestore.
- Haz clic en el archivo para ver el contenido.
Si eliges seguir desarrollando estos servicios, recuerda que tienen acceso restringido de la administración de identidades y accesos (IAM) al resto de Google Cloud y necesitarán tener funciones de IAM adicionales para acceder a muchos otros servicios.
Análisis de costos
Ejemplo de desglose de costos para un servicio, alojado en Iowa (us-central1) con una instancia de Filestore de 1 TiB y un conector de Acceso a VPC sin servidores Visita las páginas de precios individuales para obtener los precios más actualizados.
| Producto | Costo mensual |
|---|---|
| Filestore (no depende de la cantidad que se usó) | Costo = Capacidad aprovisionada (1,024 GiB o 1 TiB) * precio del nivel regional (us-central1) Nivel HDD básico: 1,024 GiB * $0.16 por mes = $163.84 Zonal (SSD): 1,024 GiB * $0.25/mes = $256.00 Enterprise (SSD, disponibilidad regional): 1,024 GiB * $0.45 por mes = $460.80 |
| Acceso a VPC sin servidores | Costo = Precio del tamaño de la máquina * cantidad de instancias (la cantidad mínima de instancias es 2 de forma predeterminada) f1-micro: $3.88 * 2 instancias = $7.76 e2- micro: $6.11 * 2 instancias = $12.22 e2-standard-4: $97.83 * 2 instancias = $195.66 |
| Cloud Run | Costo = CPU + Memoria + Solicitudes + Herramientas de redes |
| Total | $163.84 + $12.22 = $176.06 por mes + costo de Cloud Run |
En este instructivo, se usa una instancia de Filestore de nivel HDD básico. El nivel de servicio de una instancia de Filestore es una combinación de su tipo de instancia y del tipo de almacenamiento. El tipo de instancia se puede actualizar para obtener más capacidad y escalabilidad. El tipo de almacenamiento se puede actualizar para mejorar el rendimiento. Obtén más información sobre las recomendaciones de los tipos de almacenamiento. La región y la capacidad también afectan los precios de Filestore. Por ejemplo, una instancia de TiB de nivel 1 de HDD básico en Iowa (us-central1) cuesta $0.16 por GiB por mes, que es alrededor de $163.84 por mes.
El precio del conector de Acceso a VPC sin servidores depende del tamaño y la cantidad de instancias, así como del tráfico de salida de la red. El aumento del tamaño y la cantidad puede mejorar la capacidad de procesamiento o reducir la latencia de los mensajes. Hay 3 tamaños de máquinas, f1-micro, e2-micro y e2-standard-4. El número mínimo de instancias es 2; por lo tanto, el costo mínimo es el doble del costo de ese tamaño de máquina.
Cloud Run se cobra por usurpación de recursos y se redondea a los 100 ms más cercana para la memoria, la CPU, la cantidad de solicitudes y las herramientas de redes. Por lo tanto, el costo variará según la configuración del servicio, la cantidad de solicitudes y el tiempo de ejecución. Este servicio costaría un mínimo de $176.06 al mes. Visualiza y explora una estimación en la calculadora de precios de Google Cloud.
Limpia
Si creaste un proyecto nuevo para este instructivo, bórralo. Si usaste un proyecto existente y deseas conservarlo sin los cambios que se agregaron en este instructivo, borra los recursos creados para el instructivo.
Borra el proyecto
La manera más fácil de eliminar la facturación es borrar el proyecto que creaste para el instructivo.
Para borrar el proyecto, sigue estos pasos:
- En la consola de Google Cloud, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que quieres borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrar el proyecto.
Borra los recursos del instructivo
Usa este comando para borrar el servicio de Cloud Run que implementaste en este instructivo:
gcloud run services delete SERVICE-NAME
En el ejemplo anterior, SERVICE-NAME es el nombre del servicio que elegiste.
También puedes borrar los servicios de Cloud Run desde la consola de Google Cloud.
Quita la configuración de región predeterminada de gcloud que agregaste durante la configuración en el instructivo:
gcloud config unset run/regionQuita la configuración del proyecto:
gcloud config unset projectBorra otros recursos de Google Cloud que creaste en este instructivo:
- Eliminar la instancia de Filestore
- Borra el conector de Acceso a VPC sin servidores
- Borra la imagen de contenedor del servicio llamada
gcr.io/PROJECT_ID/filesystem-appde Artifact Registry. - Borra la cuenta de servicio
fs-identity@PROJECT_ID.iam.gserviceaccount.com.
¿Qué sigue?
- Consulta la guía de solución de problemas.
- Obtén más información sobre Filestore.
- Obtén más información en Configura el acceso a VPC sin servidores.
- Explora Herramientas de diagnóstico de acceso a VPC sin servidores para solucionar cualquier problema de red sin servidores.
- Obtén más información sobre Elige un proceso init para contenedores de varios procesos.