After training a model, AutoML Natural Language uses documents from the TEST set to evaluate the quality and accuracy of the new model.
AutoML Natural Language provides an aggregate set of evaluation metrics indicating how well the model performs overall, as well as evaluation metrics for each category label, indicating how well the model performs for that label.
Precision and recall measure how well the model is capturing information, and how much it's leaving out. Precision indicates, from all the documents identified as a particular entity or label, how many actually were supposed to be assigned to that entity or label. Recall indicates, from all the documents that should have been identified as a particular entity or label, how many were actually assigned to that entity or label.
The Confusion matrix (Only present for single-label-per-document models)
represents the percentage of times each label was predicted in
the training set during evaluation. Ideally, label one would be assigned
only to documents classified as label one, etc, so a perfect matrix would look
like:
100 0 0 0
0 100 0 0
0 0 100 0
0 0 0 100
In the example above, if a document was classified as one but the model predicted two,
the first row would instead look like:
99 1 0 0
AutoML Natural Language creates the confusion matrix for up to 10 labels. If you have more than 10 labels, the matrix includes the 10 labels with the most confusion (incorrect predictions).
For sentiment models:
Mean absolute error (MAE) and mean squared error (MSE) measure the distance between the predicted sentiment value and the actual sentiment value. Lower values indicate more accurate models.
Linear-weighted kappa and quadratic-weighted kappa measure how closely the sentiment values assigned by the model agree with values assigned by human raters. Higher values indicate more accurate models.
Use these metrics to evaluate your model's readiness. Low precision and recall scores can indicate that your model needs additional training data or has inconsistent annotations. Perfect precision and recall can indicate that the data is too easy and may not generalize well. See the Beginner's Guide for more tips about evaluating models.
If you're not happy with the quality levels, you can go back to earlier steps to improve the quality:
- Consider adding more documents to any labels with low quality.
- You may need to add different types of documents. For example, longer or shorter documents, documents by different authors that use different wording or style.
- You can clean up labels.
- Consider removing labels altogether if you don't have enough training documents.
Once you've made changes, train and evaluate a new model until you reach a high enough quality level.
Web UI
To review the evaluation metrics for your model:
Click the lightbulb icon in the left navigation bar to display the available models.
To view the models for a different project, select the project from the drop-down list in the upper right of the title bar.
Click the row for the model you want to evaluate.
If necessary, click the Evaluate tab just below the title bar.
If training has been completed for the model, AutoML Natural Language shows its evaluation metrics.
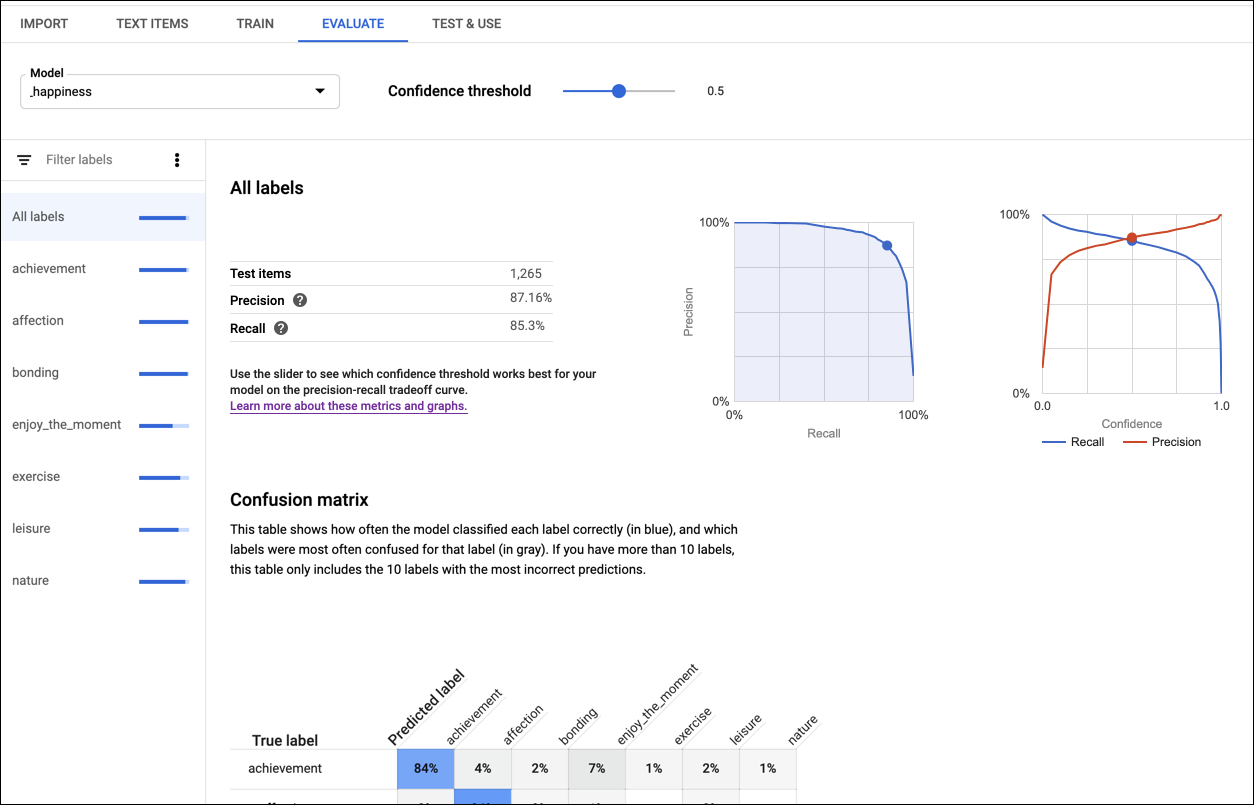
To view the metrics for a specific label, select the label name from the list of labels in the lower part of the page.
Code samples
The samples provide evaluation for the model as a whole. You can also get the
metrics for a specific label (displayName) using an evaluation ID.
REST
Before using any of the request data, make the following replacements:
- project-id: your project ID
- location-id: the location for the resource,
us-central1for the Global location oreufor the European Union - model-id: your model ID
HTTP method and URL:
GET https://automl.googleapis.com/v1/projects/project-id/locations/location-id/models/model-id/modelEvaluations
To send your request, expand one of these options:
You should receive a JSON response similar to the following:
{
"modelEvaluation": [
{
"name": "projects/434039606874/locations/us-central1/models/7537307368641647584/modelEvaluations/9009741181387603448",
"annotationSpecId": "17040929661974749",
"classificationMetrics": {
"auPrc": 0.99772006,
"baseAuPrc": 0.21706384,
"evaluatedExamplesCount": 377,
"confidenceMetricsEntry": [
{
"recall": 1,
"precision": -1.3877788e-17,
"f1Score": -2.7755576e-17,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
{
"confidenceThreshold": 0.05,
"recall": 0.997,
"precision": 0.867,
"f1Score": 0.92746675,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
{
"confidenceThreshold": 0.1,
"recall": 0.995,
"precision": 0.905,
"f1Score": 0.9478684,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
{
"confidenceThreshold": 0.15,
"recall": 0.992,
"precision": 0.932,
"f1Score": 0.96106446,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
{
"confidenceThreshold": 0.2,
"recall": 0.989,
"precision": 0.951,
"f1Score": 0.96962786,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
{
"confidenceThreshold": 0.25,
"recall": 0.987,
"precision": 0.957,
"f1Score": 0.9717685,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
...
],
},
"createTime": "2018-04-30T23:06:14.746840Z"
},
{
"name": "projects/434039606874/locations/us-central1/models/7537307368641647584/modelEvaluations/9009741181387603671",
"annotationSpecId": "1258823357545045636",
"classificationMetrics": {
"auPrc": 0.9972302,
"baseAuPrc": 0.1883289,
...
},
"createTime": "2018-04-30T23:06:14.649260Z"
}
]
}
Python
To learn how to install and use the client library for AutoML Natural Language, see AutoML Natural Language client libraries. For more information, see the AutoML Natural Language Python API reference documentation.
To authenticate to AutoML Natural Language, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Java
To learn how to install and use the client library for AutoML Natural Language, see AutoML Natural Language client libraries. For more information, see the AutoML Natural Language Java API reference documentation.
To authenticate to AutoML Natural Language, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Node.js
To learn how to install and use the client library for AutoML Natural Language, see AutoML Natural Language client libraries. For more information, see the AutoML Natural Language Node.js API reference documentation.
To authenticate to AutoML Natural Language, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Go
To learn how to install and use the client library for AutoML Natural Language, see AutoML Natural Language client libraries. For more information, see the AutoML Natural Language Go API reference documentation.
To authenticate to AutoML Natural Language, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Additional languages
C#: Please follow the C# setup instructions on the client libraries page and then visit the AutoML Natural Language reference documentation for .NET.
PHP: Please follow the PHP setup instructions on the client libraries page and then visit the AutoML Natural Language reference documentation for PHP.
Ruby: Please follow the Ruby setup instructions on the client libraries page and then visit the AutoML Natural Language reference documentation for Ruby.