A dataset contains representative samples of the type of content you want to classify, labeled with the category labels you want your custom model to use. The dataset serves as the input for training a model.
The main steps for building a dataset are:
- Create a dataset resource.
- Import training data into the dataset.
- Label the documents or identify the entities.
For classification and sentiment analysis, steps 2 and 3 are often combined: you can import documents with their labels already assigned.
Creating a dataset
The first step in creating a custom model is to create an empty dataset that will eventually hold the training data for the model. The newly created dataset doesn't contain any data until you import documents into it.
Web UI
To create a dataset:
Open the AutoML Natural Language UI and select Get started in the box corresponding to the type of model you plan to train.
The Datasets page appears, showing the status of previously created datasets for the current project.
To add a dataset for a different project, select the project from the drop-down list in the upper right of the title bar.
Click the New Dataset button in the title bar.
Enter a name for the dataset and specify which geographical Location to store the dataset in.
See Locations for more information.
Select your model objective, which specifies what type of analysis you'll perform with the model you train using this dataset.
- Single label classification assigns a single label to each classified document
- Multi-label classification allows a document to be assigned multiple labels
- Entity extraction identifies entities in documents
- Sentiment analysis analyzes attitudes within documents
Click Create dataset.
The Import page for the new dataset appears. See Importing data into a dataset.
Code samples
Classification
REST
Before using any of the request data, make the following replacements:
- project-id: your project ID
- location-id: the location for the resource,
us-central1for the Global location oreufor the European Union
HTTP method and URL:
POST https://automl.googleapis.com/v1/projects/project-id/locations/location-id/datasets
Request JSON body:
{
"displayName": "test_dataset",
"textClassificationDatasetMetadata": {
"classificationType": "MULTICLASS"
}
}
To send your request, expand one of these options:
You should receive a JSON response similar to the following:
{
"name": "projects/434039606874/locations/us-central1/datasets/356587829854924648",
"displayName": "test_dataset",
"createTime": "2018-04-26T18:02:59.825060Z",
"textClassificationDatasetMetadata": {
"classificationType": "MULTICLASS"
}
}
Python
To learn how to install and use the client library for AutoML Natural Language, see AutoML Natural Language client libraries. For more information, see the AutoML Natural Language Python API reference documentation.
To authenticate to AutoML Natural Language, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Java
To learn how to install and use the client library for AutoML Natural Language, see AutoML Natural Language client libraries. For more information, see the AutoML Natural Language Java API reference documentation.
To authenticate to AutoML Natural Language, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Node.js
To learn how to install and use the client library for AutoML Natural Language, see AutoML Natural Language client libraries. For more information, see the AutoML Natural Language Node.js API reference documentation.
To authenticate to AutoML Natural Language, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Go
To learn how to install and use the client library for AutoML Natural Language, see AutoML Natural Language client libraries. For more information, see the AutoML Natural Language Go API reference documentation.
To authenticate to AutoML Natural Language, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Additional languages
C#: Please follow the C# setup instructions on the client libraries page and then visit the AutoML Natural Language reference documentation for .NET.
PHP: Please follow the PHP setup instructions on the client libraries page and then visit the AutoML Natural Language reference documentation for PHP.
Ruby: Please follow the Ruby setup instructions on the client libraries page and then visit the AutoML Natural Language reference documentation for Ruby.
Entity extraction
REST
Before using any of the request data, make the following replacements:
- project-id: your project ID
- location-id: the location for the resource,
us-central1for the Global location oreufor the European Union
HTTP method and URL:
POST https://automl.googleapis.com/v1/projects/project-id/locations/location-id/datasets
Request JSON body:
{
"displayName": "test_dataset",
"textExtractionDatasetMetadata": {
}
}
To send your request, expand one of these options:
You should receive a JSON response similar to the following:
{
name: "projects/000000000000/locations/us-central1/datasets/TEN5582774688079151104"
display_name: "test_dataset"
create_time {
seconds: 1539886451
nanos: 757650000
}
text_extraction_dataset_metadata {
}
}
Python
To learn how to install and use the client library for AutoML Natural Language, see AutoML Natural Language client libraries. For more information, see the AutoML Natural Language Python API reference documentation.
To authenticate to AutoML Natural Language, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Java
To learn how to install and use the client library for AutoML Natural Language, see AutoML Natural Language client libraries. For more information, see the AutoML Natural Language Java API reference documentation.
To authenticate to AutoML Natural Language, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Node.js
To learn how to install and use the client library for AutoML Natural Language, see AutoML Natural Language client libraries. For more information, see the AutoML Natural Language Node.js API reference documentation.
To authenticate to AutoML Natural Language, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Go
To learn how to install and use the client library for AutoML Natural Language, see AutoML Natural Language client libraries. For more information, see the AutoML Natural Language Go API reference documentation.
To authenticate to AutoML Natural Language, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Additional languages
C#: Please follow the C# setup instructions on the client libraries page and then visit the AutoML Natural Language reference documentation for .NET.
PHP: Please follow the PHP setup instructions on the client libraries page and then visit the AutoML Natural Language reference documentation for PHP.
Ruby: Please follow the Ruby setup instructions on the client libraries page and then visit the AutoML Natural Language reference documentation for Ruby.
Sentiment analysis
REST
Before using any of the request data, make the following replacements:
- project-id: your project ID
- location-id: the location for the resource,
us-central1for the Global location oreufor the European Union
HTTP method and URL:
POST https://automl.googleapis.com/v1/projects/project-id/locations/location-id/datasets
Request JSON body:
{
"displayName": "test_dataset",
"textSentimentDatasetMetadata": {
"sentimentMax": 4
}
}
To send your request, expand one of these options:
You should receive a JSON response similar to the following:
{
name: "projects/000000000000/locations/us-central1/datasets/TST8962998974766436002"
display_name: "test_dataset_name"
create_time {
seconds: 1538855662
nanos: 51542000
}
text_sentiment_dataset_metadata {
sentiment_max: 7
}
}
Python
To learn how to install and use the client library for AutoML Natural Language, see AutoML Natural Language client libraries. For more information, see the AutoML Natural Language Python API reference documentation.
To authenticate to AutoML Natural Language, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Java
To learn how to install and use the client library for AutoML Natural Language, see AutoML Natural Language client libraries. For more information, see the AutoML Natural Language Java API reference documentation.
To authenticate to AutoML Natural Language, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Node.js
To learn how to install and use the client library for AutoML Natural Language, see AutoML Natural Language client libraries. For more information, see the AutoML Natural Language Node.js API reference documentation.
To authenticate to AutoML Natural Language, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Go
To learn how to install and use the client library for AutoML Natural Language, see AutoML Natural Language client libraries. For more information, see the AutoML Natural Language Go API reference documentation.
To authenticate to AutoML Natural Language, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Additional languages
C#: Please follow the C# setup instructions on the client libraries page and then visit the AutoML Natural Language reference documentation for .NET.
PHP: Please follow the PHP setup instructions on the client libraries page and then visit the AutoML Natural Language reference documentation for PHP.
Ruby: Please follow the Ruby setup instructions on the client libraries page and then visit the AutoML Natural Language reference documentation for Ruby.
Importing training data into a dataset
After you have created a dataset, you can import document URIs and labels for documents from a CSV file stored in a Cloud Storage bucket. For details on preparing your data and creating a CSV file for import, see Preparing your training data.
You can import documents into an empty dataset or import additional documents into an existing dataset.
Web UI
To import documents into a dataset:
Select the dataset you want to import documents into from the Datasets page.
On the Import tab, specify where to find the training documents.
You can:
Upload a .csv file that contains the training documents and their associated category labels from your local computer or from Cloud Storage.
Upload a collection of .txt, .pdf, .tif, or .zip files that contain the training documents from your local computer.
Select the file(s) to import and the Cloud Storage path for the imported documents.
Click Import.
Code samples
REST
Before using any of the request data, make the following replacements:
- project-id: your project ID
- location-id: the location for the resource,
us-central1for the Global location oreufor the European Union - dataset-id: your dataset ID
- bucket-name: your Cloud Storage bucket
- csv-file-name: your CSV training data file
HTTP method and URL:
POST https://automl.googleapis.com/v1/projects/project-id/locations/location-id/datasets/dataset-id:importData
Request JSON body:
{
"inputConfig": {
"gcsSource": {
"inputUris": ["gs://bucket-name/csv-file-name.csv"]
}
}
}
To send your request, expand one of these options:
You should see output similar to the following. You can use the operation ID to get the status of the task. For an example, see Getting the status of an operation.
{
"name": "projects/434039606874/locations/us-central1/operations/1979469554520650937",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1beta1.OperationMetadata",
"createTime": "2018-04-27T01:28:36.128120Z",
"updateTime": "2018-04-27T01:28:36.128150Z",
"cancellable": true
}
}
Python
To learn how to install and use the client library for AutoML Natural Language, see AutoML Natural Language client libraries. For more information, see the AutoML Natural Language Python API reference documentation.
To authenticate to AutoML Natural Language, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Java
To learn how to install and use the client library for AutoML Natural Language, see AutoML Natural Language client libraries. For more information, see the AutoML Natural Language Java API reference documentation.
To authenticate to AutoML Natural Language, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Node.js
To learn how to install and use the client library for AutoML Natural Language, see AutoML Natural Language client libraries. For more information, see the AutoML Natural Language Node.js API reference documentation.
To authenticate to AutoML Natural Language, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Go
To learn how to install and use the client library for AutoML Natural Language, see AutoML Natural Language client libraries. For more information, see the AutoML Natural Language Go API reference documentation.
To authenticate to AutoML Natural Language, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Additional languages
C#: Please follow the C# setup instructions on the client libraries page and then visit the AutoML Natural Language reference documentation for .NET.
PHP: Please follow the PHP setup instructions on the client libraries page and then visit the AutoML Natural Language reference documentation for PHP.
Ruby: Please follow the Ruby setup instructions on the client libraries page and then visit the AutoML Natural Language reference documentation for Ruby.
Labeling training documents
To be useful for training a model, each document in a dataset needs to be labeled in the way you want AutoML Natural Language to label similar documents. The quality of your training data strongly impacts the effectiveness of the model you create, and by extension, the quality of the predictions returned from that model. AutoML Natural Language ignores non-labeled documents during training.
You can provide labels for your training documents in three ways:
- Include labels in your .csv file (for classification and sentiment analysis only)
- Label your documents in the AutoML Natural Language UI
- Request labeling from human labelers using the AI Platform Data Labeling Service
The AutoML API does not include methods for labeling.
For details about labeling documents in your .csv file, see Preparing your training data.
Labeling for classification and sentiment analysis
To label documents in the AutoML Natural Language UI, select the dataset from the dataset listing page to see its details. The display name of the selected dataset appears in the title bar, and the page lists the individual documents in the dataset along with their current labels. The navigation bar along the left summarizes the number of labeled and unlabeled documents and enables you to filter the document list by label or sentiment value.
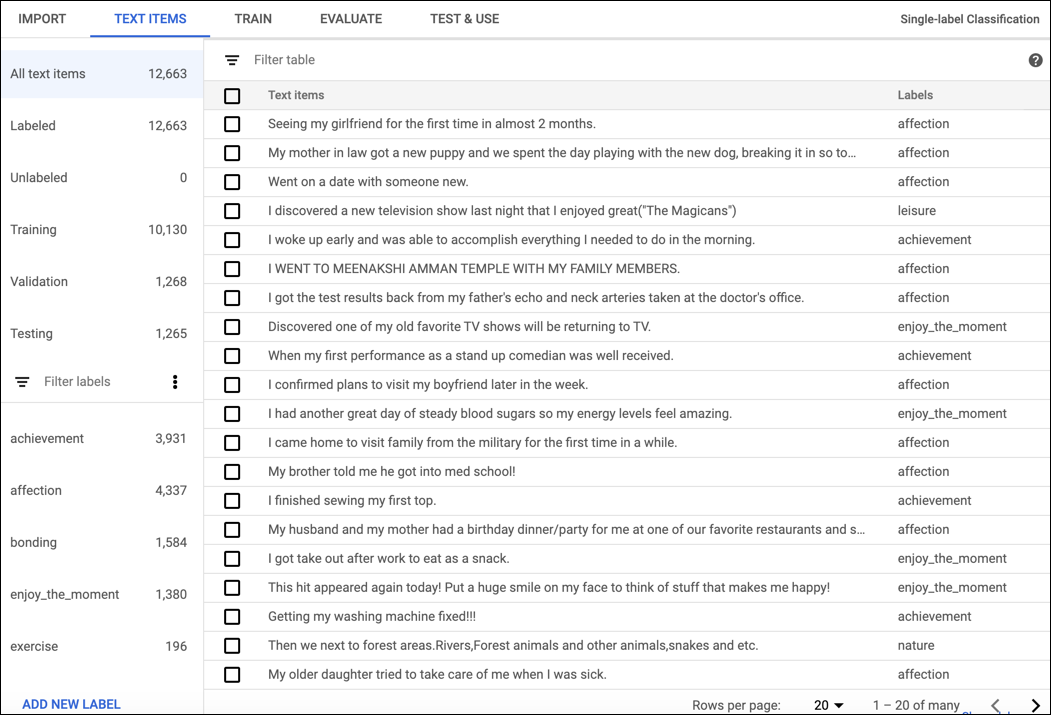
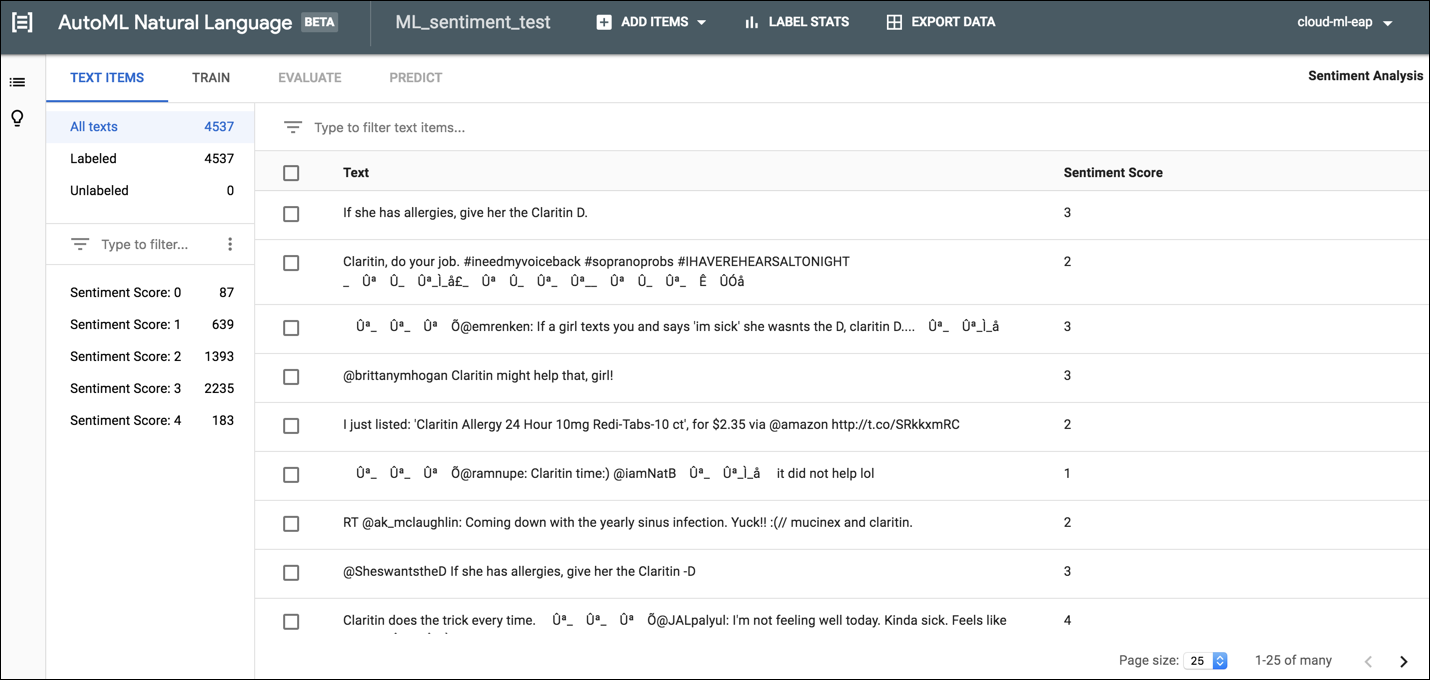
To assign labels or sentiment values to unlabeled documents or change document labels, select the documents you want to update and the label(s) or value you want to assign to them. There are two ways to update an document's label:
Click the check box next to the documents you want to update, then select the label(s) to apply from the Label drop-down list that appears at the top of the document list.
Click the row of the document you want to update, then select the label(s) or value to apply from the list that appears on the Text detail page.
Identifying entities for entity extraction
Before training your custom model, you need to annotate the training documents in the dataset. You can annotate training documents before importing them, or you can add annotations in the AutoML Natural Language UI.
To annotate in the AutoML Natural Language UI, select the dataset from the dataset listing page to see its details. The display name of the selected dataset appears in the title bar, and the page lists the individual documents in the dataset along with any annotations in them. The navigation bar along the left summarizes the labels and the number of times each label appears. You can also filter the document list by label.
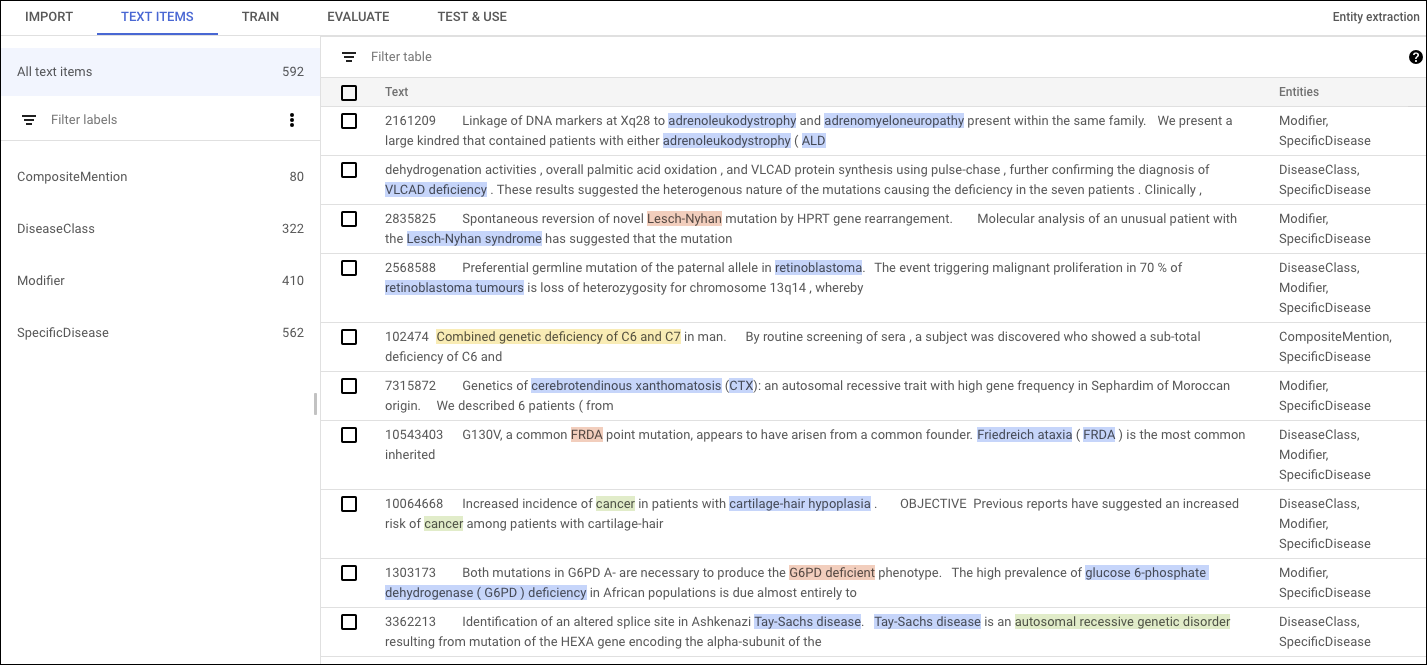
To add or delete annotations within a document, double-click the document you want to update. The Edit page shows the complete text of the selected document, with all previous annotations highlighted.

For PDF training documents or documents imported with layout information, the Edit page has two tabs: Plain text and Structured text. The Plain text tab shows the raw contents of the training document without any formatting. The Structured text tab recreates the basic layout of the training document. (The Plain text tab also has a link to the original PDF file.)
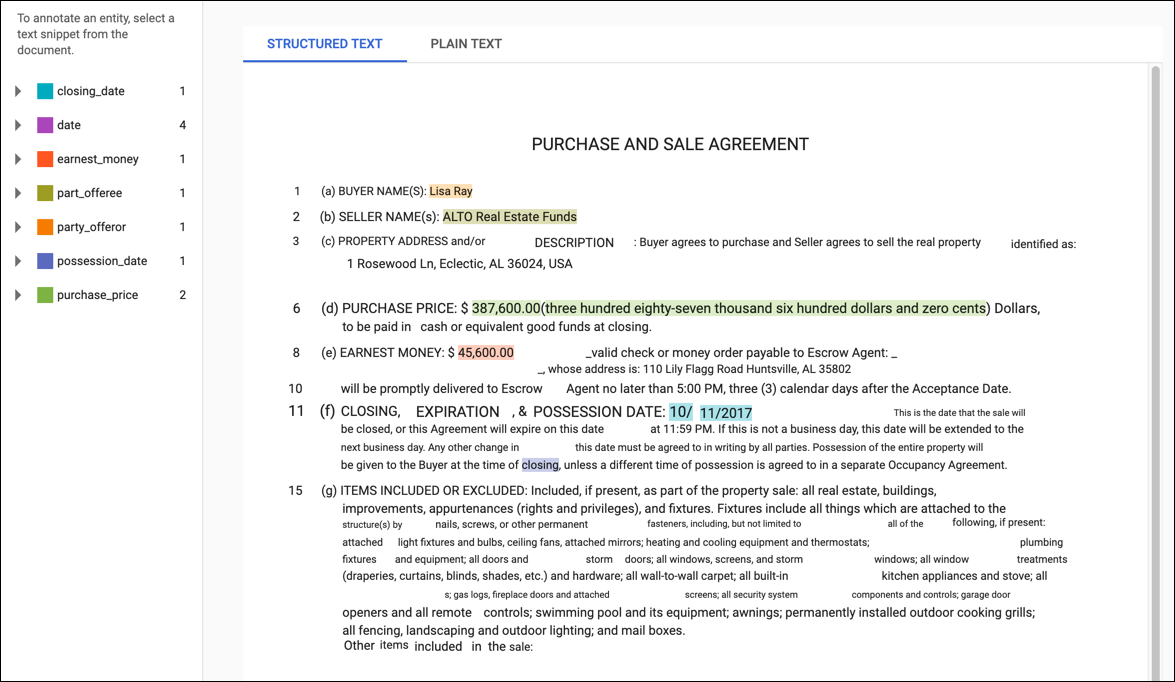
To add a new annotation, highlight the text that represents the entity, select the label from the Annotate dialog box, and click Save. When you add annotations on the Structured text tab, AutoML Natural Language captures the annotation's position on the page as a factor considered during training.
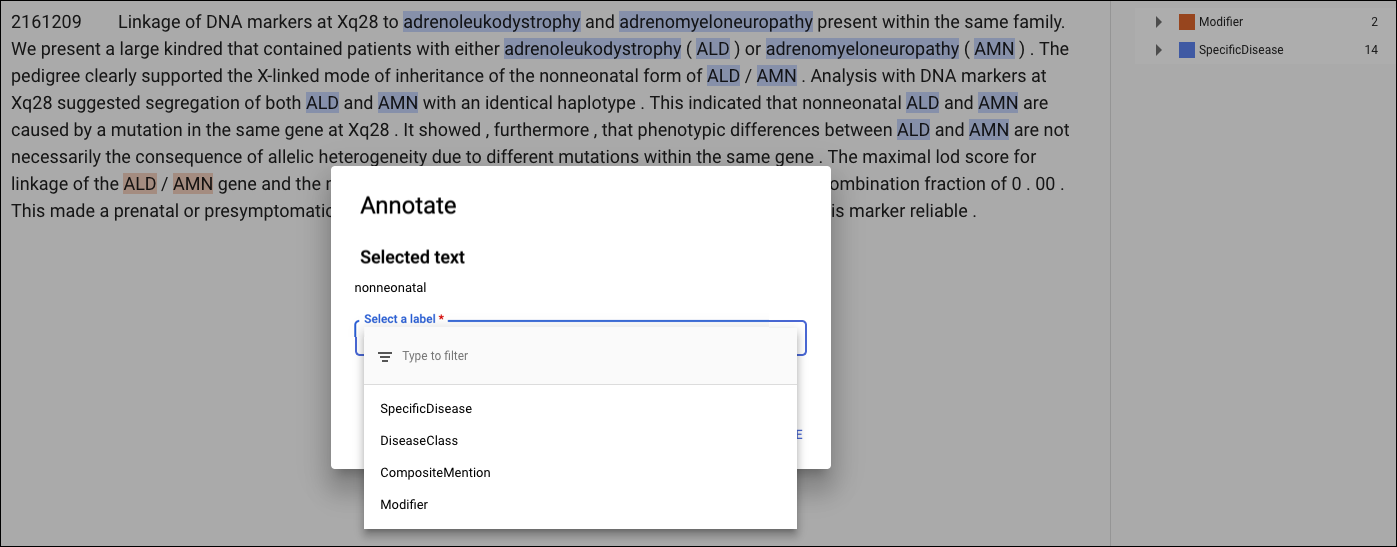
To remove an annotation, locate the text in the list of labels on the right and click the garbage can icon next to it.