Depois do treinamento de um modelo, os documentos do conjunto TEST são usados pelo AutoML Natural Language para avaliar a qualidade e a acurácia desse modelo.
No AutoML Natural Language, há um conjunto agregado de métricas de avaliação que indicam o desempenho geral do modelo e outras para cada rótulo de categoria que especificam o desempenho do modelo para o rótulo.
Precisão e recall avaliam quanta informação o modelo está capturando e quanto está deixando de fora. A precisão indica quantos documentos identificados como uma entidade ou rótulo específico deveriam ter sido atribuídos a essa entidade ou rótulo. O recall indica, dentre todos os documentos que deveriam ter sido identificados com uma entidade ou rótulo específico, quantos foram realmente atribuídos a essa entidade ou rótulo.
A matriz de confusão representa somente a porcentagem de vezes que cada rótulo foi previsto no conjunto de treinamento durante a avaliação. Idealmente, o rótulo one é atribuído apenas a documentos classificados como one. Sendo assim, uma matriz perfeita tem esta aparência:
100 0 0 0
0 100 0 0
0 0 100 0
0 0 0 100
No exemplo acima, se um documento tiver sido classificado como one, e a previsão do modelo como two, a primeira linha terá esta aparência:
99 1 0 0
O AutoML Natural Language cria a matriz de confusão para até 10 rótulos. Se você tiver mais do que isso, a matriz incluirá os dez rótulos com a confusão maior (previsões incorretas).
Para modelos de sentimento:
O erro médio absoluto (MAE, na sigla em inglês) e o erro quadrático médio (MSE, na sigla em inglês) medem a distância entre o valor do sentimento previsto e o valor do sentimento real. Valores mais baixos indicam modelos mais precisos.
O kappa linear e o kappa quadrático medem a relação entre os valores de sentimento atribuídos pelo modelo e os valores atribuídos por rotuladores humanos. Valores mais altos indicam modelos mais precisos.
Use essas métricas para avaliar a prontidão do seu modelo. Índices de baixa precisão e recall podem indicar que o modelo precisa de mais dados de treinamento ou tem anotações inconsistentes. A precisão e o recall perfeitos podem indicar que os dados são muito fáceis e podem não ser bem generalizados. Consulte o Guia para iniciantes para mais dicas sobre a avaliação de modelos.
Se você não estiver satisfeito com os níveis de qualidade, volte às etapas anteriores para melhorá-los:
- Pense em adicionar mais documentos a qualquer rótulo com baixa qualidade.
- Talvez seja necessário adicionar tipos diferentes de documentos. Por exemplo, documentos maiores ou menores, de autores distintos ou com diferentes palavras ou estilos.
- Limpe os rótulos.
- Pense em remover rótulos completamente se não houver documentos de treinamento suficientes.
Depois de fazer as alterações, treine e avalie um novo modelo até atingir um nível de qualidade alto o suficiente.
IU da Web
Para analisar as métricas de avaliação do modelo, faça o seguinte:
Clique no ícone de lâmpada na barra de navegação esquerda para exibir os modelos disponíveis.
Para ver os modelos de outro projeto, selecione o projeto na lista suspensa na parte superior direita da barra de título.
Clique na linha do modelo que você quer avaliar.
Se necessário, clique na guia Avaliar abaixo da barra de título.
Se o treinamento do modelo tiver sido concluído, as métricas de avaliação serão mostradas.
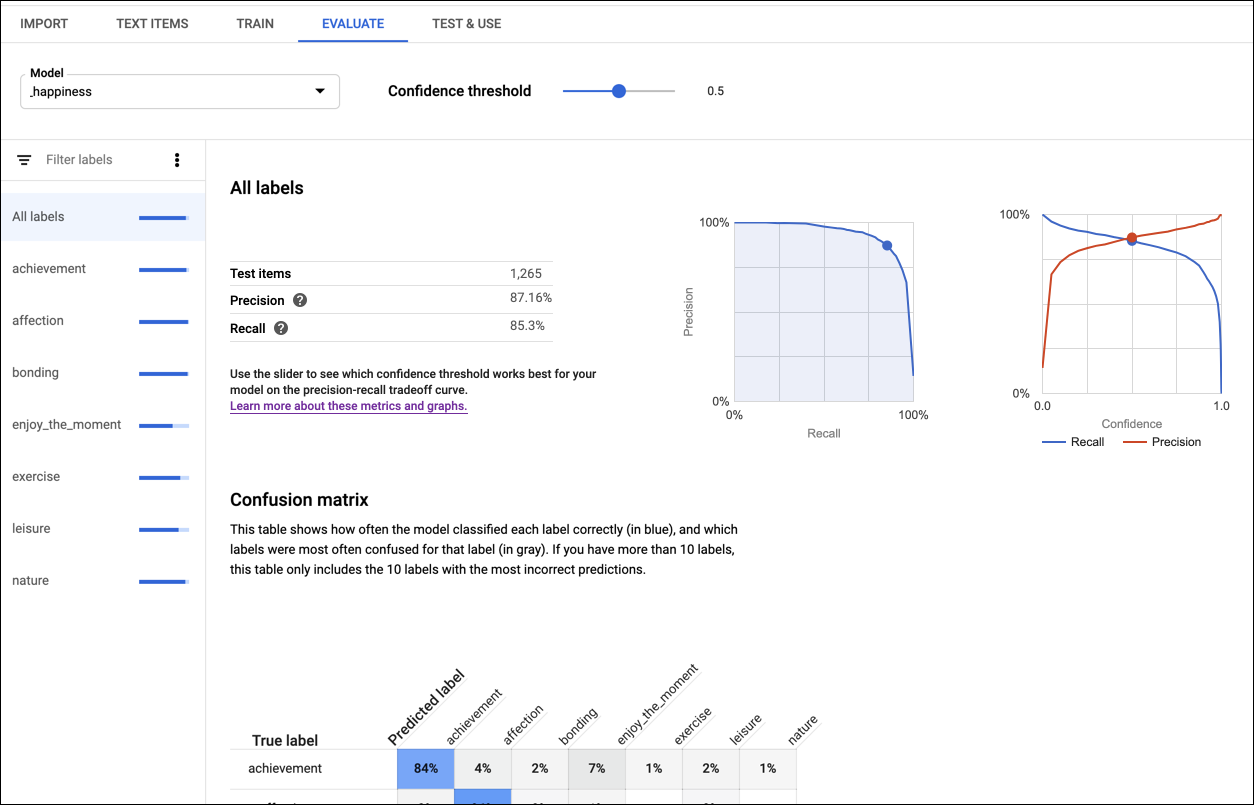
Para visualizar as métricas de um rótulo específico, selecione o nome dele na lista na parte inferior da página.
Amostras de código
As amostras permitem avaliar o modelo como um todo. Também é possível ver as métricas de um rótulo específico (displayName) usando um ID de avaliação.
REST
Antes de usar os dados da solicitação, faça as substituições a seguir:
- project-id: ID do projeto;
- location-id: o local do recurso,
us-central1para o local Global oueupara a União Europeia - model-id: o ID do modelo
Método HTTP e URL:
GET https://automl.googleapis.com/v1/projects/project-id/locations/location-id/models/model-id/modelEvaluations
Para enviar a solicitação, expanda uma destas opções:
Você receberá uma resposta JSON semelhante a esta:
{
"modelEvaluation": [
{
"name": "projects/434039606874/locations/us-central1/models/7537307368641647584/modelEvaluations/9009741181387603448",
"annotationSpecId": "17040929661974749",
"classificationMetrics": {
"auPrc": 0.99772006,
"baseAuPrc": 0.21706384,
"evaluatedExamplesCount": 377,
"confidenceMetricsEntry": [
{
"recall": 1,
"precision": -1.3877788e-17,
"f1Score": -2.7755576e-17,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
{
"confidenceThreshold": 0.05,
"recall": 0.997,
"precision": 0.867,
"f1Score": 0.92746675,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
{
"confidenceThreshold": 0.1,
"recall": 0.995,
"precision": 0.905,
"f1Score": 0.9478684,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
{
"confidenceThreshold": 0.15,
"recall": 0.992,
"precision": 0.932,
"f1Score": 0.96106446,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
{
"confidenceThreshold": 0.2,
"recall": 0.989,
"precision": 0.951,
"f1Score": 0.96962786,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
{
"confidenceThreshold": 0.25,
"recall": 0.987,
"precision": 0.957,
"f1Score": 0.9717685,
"recallAt1": 0.9761273,
"precisionAt1": 0.9761273,
"f1ScoreAt1": 0.9761273
},
...
],
},
"createTime": "2018-04-30T23:06:14.746840Z"
},
{
"name": "projects/434039606874/locations/us-central1/models/7537307368641647584/modelEvaluations/9009741181387603671",
"annotationSpecId": "1258823357545045636",
"classificationMetrics": {
"auPrc": 0.9972302,
"baseAuPrc": 0.1883289,
...
},
"createTime": "2018-04-30T23:06:14.649260Z"
}
]
}
Python
Para saber como instalar e usar a biblioteca de cliente para o AutoML Natural Language, consulte Bibliotecas de cliente do AutoML Natural Language. Para mais informações, consulte a documentação de referência da API AutoML Natural Language Python.
Para se autenticar no Natural Language do AutoML, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Java
Para saber como instalar e usar a biblioteca de cliente para o AutoML Natural Language, consulte Bibliotecas de cliente do AutoML Natural Language. Para mais informações, consulte a documentação de referência da API AutoML Natural Language Java.
Para se autenticar no Natural Language do AutoML, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Node.js
Para saber como instalar e usar a biblioteca de cliente para o AutoML Natural Language, consulte Bibliotecas de cliente do AutoML Natural Language. Para mais informações, consulte a documentação de referência da API AutoML Natural Language Node.js.
Para se autenticar no Natural Language do AutoML, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Go
Para saber como instalar e usar a biblioteca de cliente para o AutoML Natural Language, consulte Bibliotecas de cliente do AutoML Natural Language. Para mais informações, consulte a documentação de referência da API AutoML Natural Language Go.
Para se autenticar no Natural Language do AutoML, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Outras linguagens
C# : Siga as Instruções de configuração do C# na página das bibliotecas de cliente e acesse a Documentação de referência do AutoML Natural Language para .NET.
PHP : Siga as Instruções de configuração do PHP na página das bibliotecas de cliente e acesse Documentação de referência do AutoML Natural Language para PHP.
Ruby Siga as Instruções de configuração do Ruby na página das bibliotecas de cliente e acesse Documentação de referência do AutoML Natural Language para Ruby.