Créer un modèle de ML à l'aide d'AutoML Natural Language
Ce guide de démarrage rapide explique comment utiliser AutoML Natural Language pour créer un modèle de machine learning (apprentissage automatique) personnalisé. Vous pouvez créer un modèle pour classer des documents, identifier des entités dans des documents ou analyser les éléments affectifs prédominants d'un document.
Avant de commencer
Configurer votre projet
Avant de pouvoir utiliser AutoML Natural Language, vous devez créer un projet Google Cloud et activer AutoML Natural Language pour ce projet.
- Connectez-vous à votre compte Google Cloud. Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $ de crédits gratuits pour exécuter, tester et déployer des charges de travail.
-
Dans Google Cloud Console, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
-
Vérifiez que la facturation est activée pour votre projet Google Cloud.
-
Activer les API Cloud AutoML and Storage.
-
Dans Google Cloud Console, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
-
Vérifiez que la facturation est activée pour votre projet Google Cloud.
-
Activer les API Cloud AutoML and Storage.
Objectifs du modèle
AutoML Natural Language peut entraîner des modèles personnalisés pour effectuer quatre tâches distinctes, appelées objectifs du modèle :
- La classification par étiquette unique classe les documents en leur attribuant une étiquette.
- La classification multi-étiquette attribue plusieurs étiquettes à un document.
- L'extraction d'entités identifie les entités dans les documents.
- L'analyse des sentiments analyse les attitudes au sein des documents.
Dans le cadre de ce guide de démarrage rapide, vous pouvez choisir le type de modèle à créer en sélectionnant l'un des trois exemples de jeux de données hébergés dans un bucket Cloud Storage public :
Pour créer un modèle de classification par étiquette unique, sélectionnez l'ensemble de données "moments heureux" issu de l'ensemble de données Open Source Kaggle HappyDB. Le modèle qui en résulte classe les moments heureux en catégories qui reflètent les causes du bonheur.
Les données sont mises à disposition via une licence Creative Commons CCO : domaine public.
Pour créer un modèle d'extraction d'entité, utilisez un corpus de résumés de recherche biomédicale qui fait référence à des centaines de maladies et de concepts. Le modèle résultant identifie ces entités médicales dans d'autres documents.
Cet ensemble de données se trouve dans le domaine public en tant qu'"ouvrage du gouvernement américain", conformément aux dispositions de la loi américaine sur les droits d'auteur.
Pour créer un modèle d'analyse des sentiments, utilisez l'ensemble de données ouvert FigureEight qui analyse les mentions sur Twitter du médicament Claritin contre les allergies.
Créer un ensemble de données
Ouvrez l'interface utilisateur d'AutoML Natural Language, puis sélectionnez Premiers pas dans le champ correspondant au type de modèle que vous souhaitez entraîner.
Cliquez sur le bouton Nouvel ensemble de données de la barre de titre.
Saisissez un nom pour l'ensemble de données et sélectionnez l'objectif du modèle qui correspond à l'exemple d'ensemble de données que vous avez choisi.
Laissez le champ Emplacement défini sur Global.
Dans la section Importer des éléments de texte, choisissez Sélectionner un fichier CSV hébergé sur Cloud Storage, puis saisissez dans la zone de texte le chemin d'accès à l'ensemble de données souhaité.
- Pour l'ensemble de données "moments heureux" :
cloud-ml-data/NL-classification/happiness.csv - Pour l'ensemble de données de recherche biomédicale :
cloud-ml-data/NL-entity/dataset.csv - Pour l'ensemble de données de sentiment Claritin :
cloud-ml-data/NL-sentiment/crowdflower-twitter-claritin-80-10-10.csv
(Le préfixe
gs://est automatiquement ajouté.) Vous pouvez également cliquer sur Parcourir pour accéder au fichier CSV.Si vous choisissez l'ensemble de données de sentiment, AutoML Natural Language demande la valeur de sentiment maximale. La valeur maximale de cet ensemble de données est 4.
- Pour l'ensemble de données "moments heureux" :
Cliquez sur Créer un ensemble de données.
Vous êtes redirigé vers la page Datasets (Ensembles de données). Pendant l'importation de vos documents, l'ensemble de données affiche une animation indiquant que l'opération est en cours. Ce processus prend environ 10 minutes pour 1 000 documents, mais peut être plus long ou plus court.
Une fois l'ensemble de données créé, vous recevrez un message à l'adresse e-mail associée à votre projet.
Entraîner le modèle
Une fois les données d'entraînement importées, sélectionnez un ensemble sur la page répertoriant les ensembles de données afin d'en afficher les détails correspondants. Le nom de l'ensemble de données sélectionné apparaît dans la barre de titre. La page répertorie les différents documents qu'il contient ainsi que leurs étiquettes. La barre de navigation située à gauche indique le nombre de documents étiquetés et non étiquetés. Elle vous permet de filtrer la liste de documents par étiquette.
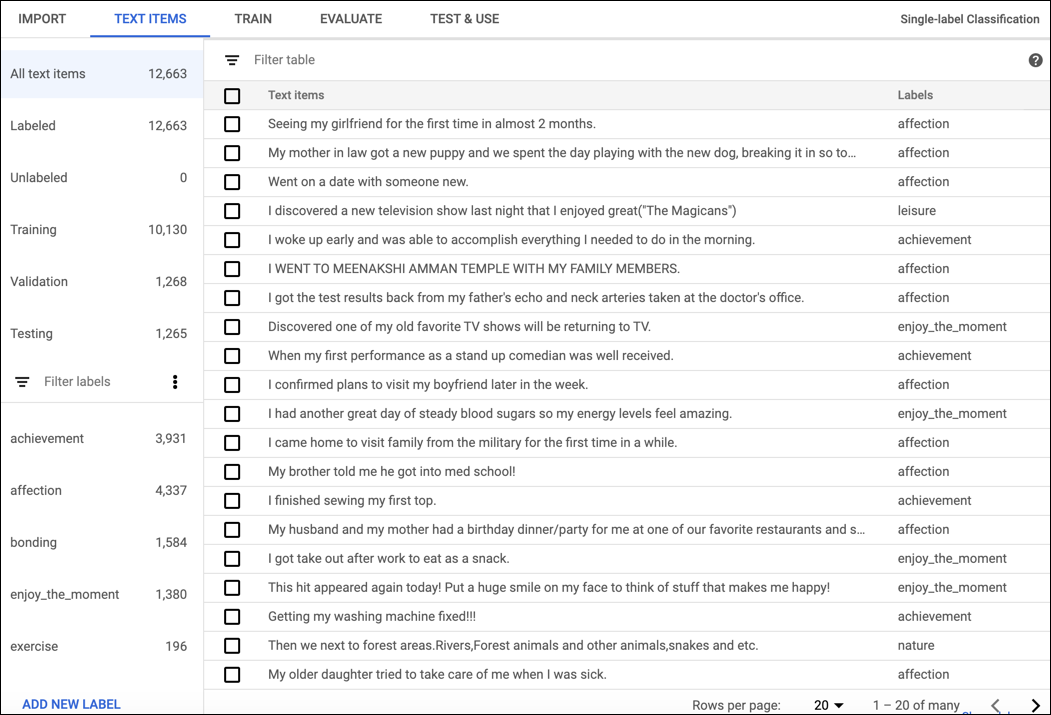
Lorsque vous avez terminé l'examen de l'ensemble de données, cliquez sur l'onglet Entraînement situé sous la barre de titre.
Cliquez sur Démarrer l'entraînement.
Saisissez un nom pour le nouveau modèle et cochez la case Déployer le modèle une fois l'entraînement terminé.
Cliquez sur Démarrer l'entraînement.
L'entraînement d'un modèle peut prendre plusieurs heures. Une fois le modèle entraîné, vous recevez un message à l'adresse e-mail associée à votre projet.
Après l’entraînement du modèle, la page Train (Apprentissage) affiche dans sa partie inférieure les métriques générales du modèle, telles que la précision et le rappel. Pour afficher plus de détails, cliquez sur l'onglet Evaluate (Évaluation).
Utiliser le modèle personnalisé
Une fois votre modèle entraîné, vous pouvez l'utiliser pour analyser d'autres documents. Cliquez sur l'onglet Test et utilisation situé juste en dessous de la barre de titre. Saisissez du texte dans la zone Texte d'entrée ou l'URL d'un fichier PDF ou TIFF dans un compartiment Cloud Storage, puis cliquez sur Prédire. AutoML Natural Language analyse le texte à l'aide de votre modèle et affiche les annotations.
Effectuer un nettoyage
Pour éviter que les ressources utilisées sur cette page soient facturées sur votre compte Google Cloud, procédez comme suit :
Pour éviter d'encourir des frais inutiles liés à Google Cloud Platform, supprimez votre projet à l'aide de la console Google Cloud si vous n'en avez plus besoin.