Introduction
Imagine your business has a contact form on its website. Every day you get many messages from the form, many of which are actionable in some way, but they all come in together and it's easy to fall behind on dealing with them since different employees handle different message types. It would be great if an automated system could categorize them so that the right person sees the right comments.
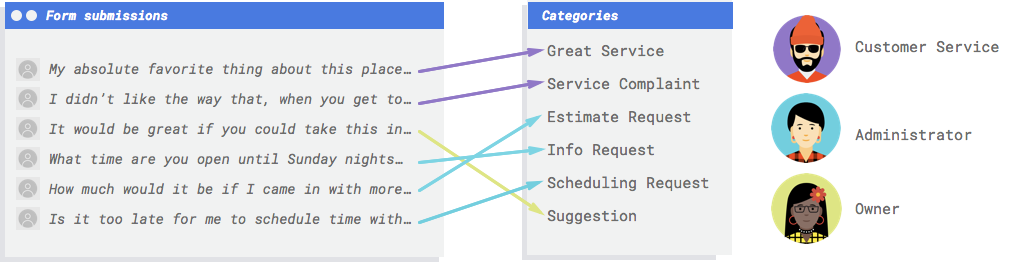
You need a system to look at the comments and decide if they represent complaints, praise for past service, an attempt to learn more about your business, schedule an appointment, or establish a relationship.
Why is Machine Learning (ML) the right tool for this problem?
 Classical programming requires the programmer to specify step-by-step instructions
for the computer to follow. But this approach quickly gets infeasible. Customer
comments use a broad and varied vocabulary and structure — too diverse to be
captured by a simple set of rules. If you tried to build manual filters, you'd
quickly find that you weren't able to categorize the vast majority of your customer
comments. You need a system that can generalize to a wide variety of comments.
In a scenario where a sequence of specific rules is bound to expand exponentially,
you need a system that can learn from examples. Fortunately, machine learning
systems are well-positioned to solve this problem.
Classical programming requires the programmer to specify step-by-step instructions
for the computer to follow. But this approach quickly gets infeasible. Customer
comments use a broad and varied vocabulary and structure — too diverse to be
captured by a simple set of rules. If you tried to build manual filters, you'd
quickly find that you weren't able to categorize the vast majority of your customer
comments. You need a system that can generalize to a wide variety of comments.
In a scenario where a sequence of specific rules is bound to expand exponentially,
you need a system that can learn from examples. Fortunately, machine learning
systems are well-positioned to solve this problem.
Is the Cloud Natural Language API or AutoML Natural Language the right tool for me?
The Natural Language API discovers syntax, entities, and sentiment in text, and classifies text into a predefined set of categories. If your text consists of news articles or other content you want to categorize, or if you want to discover the sentiment of your examples, the Natural Language API is worth trying. But if your text examples don't fit neatly into the sentiment-based or vertical-topic-based classification scheme available in the Natural Language API, and you want to use your own labels instead, it's worth experimenting with a custom classifier to see if it fits your needs.

| Try the Natural Language API | Get started with AutoML |
What does machine learning in AutoML Natural Language involve?
 Machine learning involves using data to train algorithms to achieve a desired
outcome. The specifics of the algorithm and training methods change based on the
use case. There are many different subcategories of machine learning, all of which
solve different problems and work within different constraints. AutoML Natural Language enables
you to perform supervised learning, which involves training a computer to recognize
patterns from labeled data. Using supervised learning, you can train a custom model
to recognize content that you care about in text.
Machine learning involves using data to train algorithms to achieve a desired
outcome. The specifics of the algorithm and training methods change based on the
use case. There are many different subcategories of machine learning, all of which
solve different problems and work within different constraints. AutoML Natural Language enables
you to perform supervised learning, which involves training a computer to recognize
patterns from labeled data. Using supervised learning, you can train a custom model
to recognize content that you care about in text.
Data Preparation
To train a custom model with AutoML Natural Language, you supply labeled examples of the kinds of text items (inputs) that you want to classify and the categories or labels (the answer) that you want the ML systems to predict.
Assess your use case

While putting together the dataset, always start with the use case. You can begin with the following questions:
- What outcome are you trying to achieve?
- What kinds of categories do you need to recognize to achieve this outcome?
- Is it possible for humans to recognize those categories? Although AutoML Natural Language can handle more categories than humans can remember and assign at any one time, if a human can't recognize a specific category, then AutoML Natural Language will have a hard time as well.
- What kinds of examples would best reflect the type and range of data your system will classify?
A core principle underpinning Google's ML products is human-centered machine learning, an approach that foregrounds responsible AI practices, including fairness. The goal of fairness in ML is to understand and prevent unjust or prejudicial treatment of people related to race, income, sexual orientation, religion, gender, and other characteristics historically associated with discrimination and marginalization, when and where they manifest in algorithmic systems or algorithmically aided decision-making. You can read more in Inclusive ML guide and find "fair-aware" notes ✽ in the guidelines below. As you move through the guidelines for putting together your dataset, we encourage you to consider fairness in machine learning where relevant to your use case.
Source your data
 After you've established what data you will need, you need to find a way to source
it. You can begin by taking into account all the data your organization collects.
You may find that you're already collecting the data you would need to train a model.
In case you don't have the data you need, you can obtain it manually or outsource
it to a third-party provider.
After you've established what data you will need, you need to find a way to source
it. You can begin by taking into account all the data your organization collects.
You may find that you're already collecting the data you would need to train a model.
In case you don't have the data you need, you can obtain it manually or outsource
it to a third-party provider.
Include enough labeled examples in each category
 The bare minimum required by AutoML Natural Language for training is 10 text examples per category/label.
The likelihood of successfully recognizing a label goes up with the number of
high-quality examples for each; in general, the more labeled data that you can
bring to the training process, the better your model will be. The number of
samples needed also varies with the degree of consistency in the data you want
to predict and on your target level of accuracy. You can use fewer examples for
consistent data sets or to achieve 80% accuracy rather than 97% accuracy.
Train a model using 50 examples per label and then evaluate the results. Add
more examples and retrain until you meet your accuracy targets, which could
require hundreds or even thousands of examples per label.
The bare minimum required by AutoML Natural Language for training is 10 text examples per category/label.
The likelihood of successfully recognizing a label goes up with the number of
high-quality examples for each; in general, the more labeled data that you can
bring to the training process, the better your model will be. The number of
samples needed also varies with the degree of consistency in the data you want
to predict and on your target level of accuracy. You can use fewer examples for
consistent data sets or to achieve 80% accuracy rather than 97% accuracy.
Train a model using 50 examples per label and then evaluate the results. Add
more examples and retrain until you meet your accuracy targets, which could
require hundreds or even thousands of examples per label.
Distribute examples equally across categories
It's important to capture a roughly similar number of training examples for each category. Even if you have an abundance of data for one label, it is best to have an equal distribution for each label. To see why, imagine that 80% of the customer comments you use to build your model are estimate requests. With such an unbalanced distribution of labels, your model is very likely to learn that it's safe to always tell you a customer comment is an estimate request, rather than trying to predict a much less common label. It's like writing a multiple-choice test where almost all the correct answers are "C" - soon your savvy test-taker will figure out it can answer "C" every time without even looking at the question.

It might not always be possible to source an approximately equal number of examples for each label. High quality, unbiased examples for some categories may be harder to source. In those circumstances, the label with the lowest number of examples should have at least 10% of the examples as the label with the highest number of examples. So if the largest label has 10,000 examples, the smallest label should have at least 1,000 examples.
Capture the variation in your problem space
For similar reasons, try to have your data capture the variety and diversity of your problem space. When you provide a broader set of examples, the model is better able to generalize to new data. Say you're trying to classify articles about consumer electronics into topics. The more brand names and technical specifications you provide, the easier it will be for the model to figure out the topic of an article – even if that article is about a brand that didn't make it into the training set at all. You might also consider including a "none_of_the_above" label for documents that don't match any of your defined labels to further improve model performance.

Match data to the intended output for your model

Find text examples that are similar to what you're planning to make predictions on. If you are trying to classify social media posts about glassblowing, you probably won't get great performance from a model trained on glassblowing information websites, as the vocabulary and style may be very different. Ideally, your training examples are real-world data drawn from the same dataset you're planning to use the model to classify.
Consider how AutoML Natural Language uses your dataset in creating a custom model
Your dataset contains training, validation and testing sets. If you do not specify the splits as explained in Prepare Your Data), then AutoML Natural Language automatically uses 80% of your content documents for training, 10% for validating, and 10% for testing.
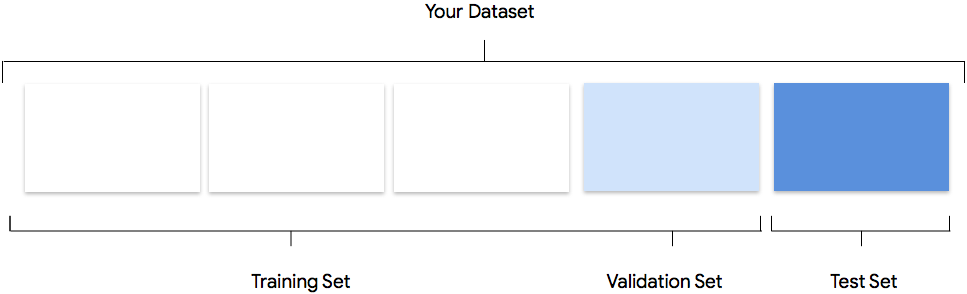
Training Set
 The vast majority of your data should be in the training set. This is the data
your model "sees" during training: it's used to learn the parameters of the
model, namely the weights of the connections between nodes of the neural
network.
The vast majority of your data should be in the training set. This is the data
your model "sees" during training: it's used to learn the parameters of the
model, namely the weights of the connections between nodes of the neural
network.
Validation Set
 The validation set, sometimes also called the "dev" set, is also used during the
training process. After the model learning framework incorporates training data
during each iteration of the training process, it uses the model's performance
on the validation set to tune the model's hyperparameters, which are variables
that specify the model's structure. If you tried to use the training set to tune
the hyperparameters, it's likely the model would end up overly focused on your
training data, and have a hard time generalizing to examples that don't exactly
match it. Using a somewhat novel dataset to fine-tune model structure means that
your model will generalize better.
The validation set, sometimes also called the "dev" set, is also used during the
training process. After the model learning framework incorporates training data
during each iteration of the training process, it uses the model's performance
on the validation set to tune the model's hyperparameters, which are variables
that specify the model's structure. If you tried to use the training set to tune
the hyperparameters, it's likely the model would end up overly focused on your
training data, and have a hard time generalizing to examples that don't exactly
match it. Using a somewhat novel dataset to fine-tune model structure means that
your model will generalize better.
Test Set
 The test set is not involved in the training process. After the model has
completed its training, AutoML Natural Language uses the test set as a
challenge for your model. The performance of your model on the test set is
intended to give you an idea of how your model will perform on real-world data.
The test set is not involved in the training process. After the model has
completed its training, AutoML Natural Language uses the test set as a
challenge for your model. The performance of your model on the test set is
intended to give you an idea of how your model will perform on real-world data.
Manual Splitting
 You can split your dataset yourself. Manually splitting your data lets you
exercise more control over the process or if there are specific examples that
you're sure you want included in a certain part of your model training
lifecycle.
You can split your dataset yourself. Manually splitting your data lets you
exercise more control over the process or if there are specific examples that
you're sure you want included in a certain part of your model training
lifecycle.
Prepare your data for import

After you've decided if a manual or automatic split of your data is right for you, there are three ways to add data in AutoML Natural Language:
- You can import data with your text examples sorted and stored in folders that correspond to your labels.
- You can import data either from your computer or Cloud Storage in CSV format with the labels inline, as specified in Preparing your training data. If you want to split your dataset manually, you must choose this option and format your CSV accordingly.
- If your data hasn't been labeled, you can upload unlabeled text examples and use the AutoML Natural Language UI to apply labels to each one.
Evaluate
After your model is trained, you receive a summary of your model performance. To view a detailed analysis, click evaluate or see full evaluation.
What should I keep in mind before evaluating my model?
 Debugging a model is more about debugging the data than the model itself. If
your model starts acting in an unexpected manner as you're evaluating its
performance before and after pushing to production, you should return and check
your data to see where it might be improved.
Debugging a model is more about debugging the data than the model itself. If
your model starts acting in an unexpected manner as you're evaluating its
performance before and after pushing to production, you should return and check
your data to see where it might be improved.
What kinds of analysis can I perform in AutoML Natural Language?
In the AutoML Natural Language evaluate section, you can assess your custom model's performance using the model's output on test examples and common machine learning metrics. This section covers what each of the following concepts means:
- The model output
- The score threshold
- True positives, true negatives, false positives, and false negatives
- Precision and recall
- Precision/Recall Curves
- Average precision
How do I interpret the model's output?
AutoML Natural Language pulls examples from your test data to present new challenges for your model. For each example, the model outputs a series of numbers that communicate how strongly it associates each label with that example. If the number is high, the model has high confidence that the label should be applied to that document.

What is the Score Threshold?
The score threshold lets AutoML Natural Language convert probabilities into binary 'on'/'off' values. The score threshold refers to the level of confidence the model must have to assign a category to a test item. The score threshold slider in the UI is a visual tool to test the impact of different thresholds in your dataset. In the example above, if we set the score threshold to 0.8 for all categories, "Great Service" and "Suggestion" will be assigned but not "Info Request." If your score threshold is low, your model will classify more text items, but runs the risk of misclassifying more text items in the process. If your score threshold is high, your model will classify fewer text items, but it will have a lower risk of misclassifying text items. You can tweak the per-category thresholds in the UI to experiment. However, when using your model in production, you will have to enforce the thresholds you found optimal on your side.

What are True Positives, True Negatives, False Positives, False Negatives?
After applying the score threshold, the predictions made by your model will fall in one of the following four categories.
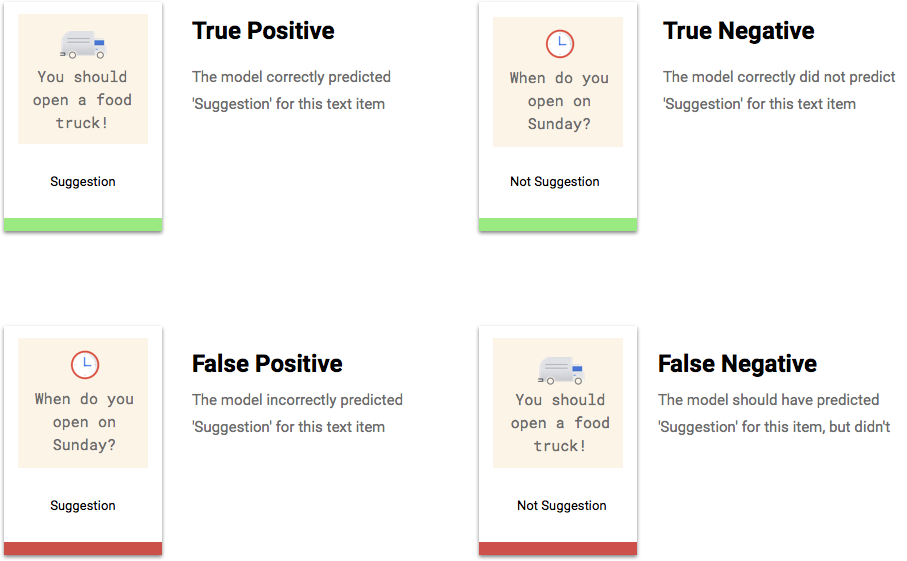
You can use these categories to calculate precision and recall — metrics that help gauge the effectiveness of your model.
What are precision and recall?
Precision and recall help us understand how well our model is capturing information, and how much it's leaving out. Precision tells us, from all the test examples that were assigned a label, how many actually were supposed to be categorized with that label. Recall tells us, from all the test examples that should have had the label assigned, how many were actually assigned the label.


Should I optimize for precision or recall?
Depending on your use case, you may want to optimize for either precision or recall. Let's examine how you might approach this decision with the following two use cases.
Use case: Urgent documents
Let's say you want to create a system that can prioritize documents that are urgent from ones that are not.

A false positive in this case would be a document that is not urgent, but gets marked as such. The user can dismiss them as non urgent and move on.

A false negative in this case would be, a document that is urgent, but the system fails to flag it as such. This could cause problems!
In this case, you would want to optimize for recall. This metric measures, for all the predictions made, how much is being left out. A high-recall model is likely to label marginally relevant examples, which is useful for cases where your category has scarce training data.
Use case: Spam filtering
Let's say you want to create a system that automatically filters email messages that are spam from messages that are not.

A false negative in this case would be a spam email that does not get caught and that you see you see in your inbox. Usually, this is just a bit annoying.

A false positive in this case would be an email that is falsely flagged as spam and gets removed from your inbox. If the email was important, the user might be adversely impacted.
In this case, you would want to optimize for precision. This metric measures, for all the predictions made, how correct they are. A high-precision model is likely to label only the most relevant examples, which is useful for cases where your category is common in the training data.
How do I use the Confusion Matrix?
We can compare the model's performance on each label using a confusion matrix. In an ideal model, all the values on the diagonal will be high, and all the other values will be low. This shows that the desired categories are being identified correctly. If any other values are high, it gives us a clue into how the model is misclassifying test items.

How do I interpret the Precision-Recall curves?
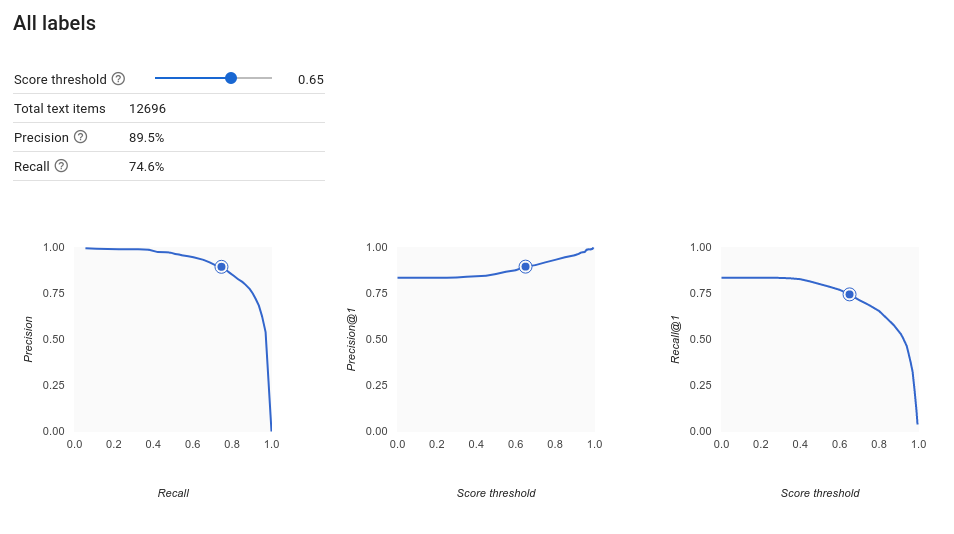
The score threshold tool allows you to explore how your chosen score threshold affects your precision and recall. As you drag the slider on the score threshold bar, you can see where that threshold places you on the precision-recall tradeoff curve, as well as how that threshold affects your precision and recall individually (for multiclass models, on these graphs, precision and recall means the only label used to calculate precision and recall metrics is the top-scored label in the set of labels we return). This can help you find a good balance between false positives and false negatives.
After you've chosen a threshold that seems to be acceptable for your model on the whole, you can click individual labels and see where that threshold falls on their per-label precision-recall curve. In some cases, it might mean you get a lot of incorrect predictions for a few labels, which might help you decide to choose a per-class threshold that's customized to those labels. For example, let's say you look at your customer comments dataset and notice that a threshold at 0.5 has reasonable precision and recall for every comment type except "Suggestion", perhaps because it's a very general category. For that category, you see tons of false positives. In that case, you might decide to use a threshold of 0.8 just for "Suggestion" when you call the classifier for predictions.
What is Average Precision?
A useful metric for model accuracy is the area under the precision-recall curve. It measures how well your model performs across all score thresholds. In AutoML Natural Language, this metric is called Average Precision. The closer to 1.0 this score is, the better your model is performing on the test set; a model guessing at random for each label would get an average precision around 0.5.
Testing your model
 AutoML Natural Language uses 10% of your data automatically (or, if you chose your data split
yourself, whatever percentage you opted to use) to test the model, and the
"Evaluate" page tells you how the model did on that test data. But just in case
you want to sanity check your model, there are a few ways to do it. The easiest
is to input text examples into the text box on the "Predict" page, and look at
the labels the model chooses for your examples. Hopefully, this matches your
expectations. Try a few examples of each type of comment you expect to receive.
AutoML Natural Language uses 10% of your data automatically (or, if you chose your data split
yourself, whatever percentage you opted to use) to test the model, and the
"Evaluate" page tells you how the model did on that test data. But just in case
you want to sanity check your model, there are a few ways to do it. The easiest
is to input text examples into the text box on the "Predict" page, and look at
the labels the model chooses for your examples. Hopefully, this matches your
expectations. Try a few examples of each type of comment you expect to receive.
If you want to use your model in your own automated tests, the "Predict" page tells you how to make calls to the model programmatically.