Introdução
Imagine que sua empresa tenha um formulário de contato no site. Todos os dias, você recebe muitas mensagens do formulário, muitas podem ser resolvidas de alguma forma, mas todas entram juntas e é fácil se perder ao lidar com elas porque funcionários diferentes lidam com tipos de mensagens diferentes. Seria ótimo se um sistema automatizado pudesse categorizar as mensagens para que a pessoa certa visse os comentários certos.
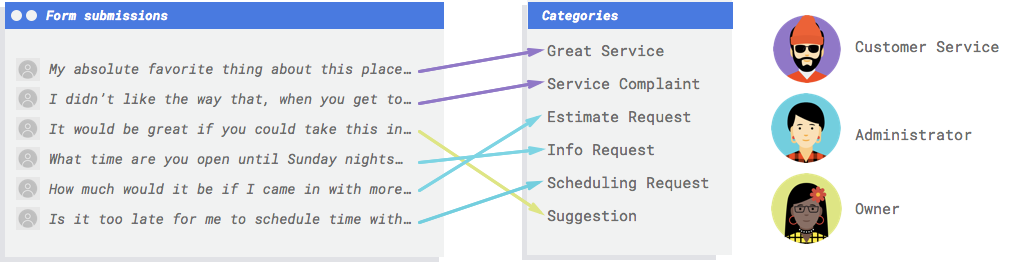
Você precisa de um sistema para analisar os comentários e decidir se representam reclamações, elogios por serviços prestados, uma tentativa de saber mais sobre a empresa, o agendamento de um compromisso ou uma ação em busca de estabelecer um relacionamento.
Por que o machine learning (ML) é a ferramenta certa para esse problema?
 Na programação clássica, o programador precisa descrever instruções passo a passo para serem seguidas pelo computador. Mas essa abordagem logo se torna inviável. Os comentários dos clientes têm uma estrutura e um vocabulário amplos e variados, muito diversos para serem capturados por um simples conjunto de regras. Se você tentar criar filtros manuais, descobrirá rapidamente que não é capaz de categorizar a grande maioria dos comentários dos clientes. Você precisa de um sistema que seja capaz de generalizar uma ampla variedade de comentários.
Em um cenário em que uma sequência de regras específicas deve se expandir exponencialmente,
você precisa de um sistema que aprenda com exemplos. Felizmente, os sistemas de machine learning
estão bem preparados para resolver esse problema.
Na programação clássica, o programador precisa descrever instruções passo a passo para serem seguidas pelo computador. Mas essa abordagem logo se torna inviável. Os comentários dos clientes têm uma estrutura e um vocabulário amplos e variados, muito diversos para serem capturados por um simples conjunto de regras. Se você tentar criar filtros manuais, descobrirá rapidamente que não é capaz de categorizar a grande maioria dos comentários dos clientes. Você precisa de um sistema que seja capaz de generalizar uma ampla variedade de comentários.
Em um cenário em que uma sequência de regras específicas deve se expandir exponencialmente,
você precisa de um sistema que aprenda com exemplos. Felizmente, os sistemas de machine learning
estão bem preparados para resolver esse problema.
Qual é a ferramenta certa para mim, API Cloud Natural Language ou AutoML Natural Language?
A API Natural Language revela sintaxe, entidades e sentimentos em um texto, além de classificá-lo de acordo com um conjunto predefinido de categorias. Se o texto consistir em artigos de notícias ou outro conteúdo que você queira categorizar ou se quiser descobrir o sentimento dos exemplos, vale a pena usar a API Natural Language. Mas se os exemplos de texto não se encaixarem perfeitamente no esquema de classificação, baseado em sentimentos ou em tópicos verticais disponível na API Natural Language, e você quiser usar seus próprios rótulos, vale a pena experimentar um classificador personalizado para ver se ele atende às suas necessidades.
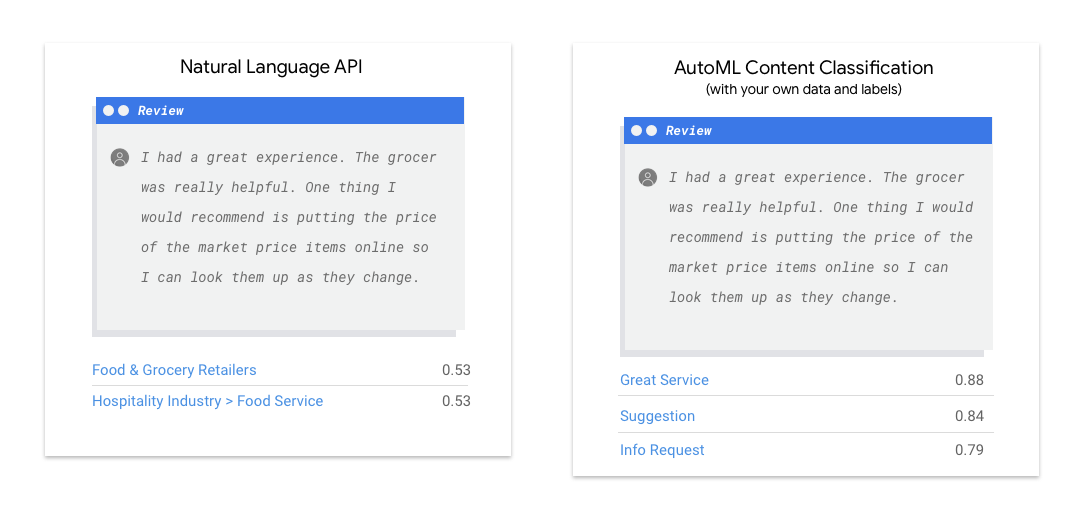
| Teste a API Natural Language | Introdução ao AutoML |
O que o aprendizado de máquina no AutoML Natural Language envolve?
 O machine learning inclui o uso de dados para treinar algoritmos e alcançar determinado resultado. As especificidades do algoritmo e dos métodos de treinamento variam de acordo com o caso de uso. Existem muitas subcategorias de aprendizado de máquina, cada uma delas soluciona problemas distintos e trabalha com diferentes restrições. O AutoML Natural Language permite executar o aprendizado supervisionado, que envolve o treinamento de um computador para reconhecer padrões a partir de dados rotulados. Com o aprendizado supervisionado, é possível treinar um modelo personalizado
para reconhecer conteúdo importante para o texto.
O machine learning inclui o uso de dados para treinar algoritmos e alcançar determinado resultado. As especificidades do algoritmo e dos métodos de treinamento variam de acordo com o caso de uso. Existem muitas subcategorias de aprendizado de máquina, cada uma delas soluciona problemas distintos e trabalha com diferentes restrições. O AutoML Natural Language permite executar o aprendizado supervisionado, que envolve o treinamento de um computador para reconhecer padrões a partir de dados rotulados. Com o aprendizado supervisionado, é possível treinar um modelo personalizado
para reconhecer conteúdo importante para o texto.
Preparação de dados
Para treinar um modelo personalizado com o AutoML Natural Language, é necessário fornecer exemplos rotulados dos tipos de itens de texto (entradas) que você quer classificar e as categorias ou rótulos (resposta) que você quer que os sistemas de ML detectem.
Avaliar o caso de uso

Ao reunir o conjunto de dados, veja primeiro o caso de uso. Comece com as perguntas a seguir:
- Que resultado você está tentando alcançar?
- Que tipos de categorias você precisa reconhecer para alcançar esse resultado?
- Pessoas são capazes de reconhecer essas categorias? O AutoML Natural Language processa mais categorias do que as pessoas conseguem memorizar e atribuir. No entanto, se um humano não conseguir reconhecer uma determinada categoria, o AutoML Natural Language também terá dificuldades com isso.
- Que exemplos refletem com mais precisão o tipo e o intervalo de dados que seu sistema classificará?
Um princípio fundamental que sustenta os produtos de ML do Google é o machine learning centrado na pessoa, uma abordagem que enfatiza práticas de IA responsáveis (em inglês), incluindo a imparcialidade. O objetivo da imparcialidade no ML é entender e evitar o tratamento injusto ou preconceituoso de pessoas, em relação a raça, renda, orientação sexual, religião, gênero e outras características historicamente associadas à discriminação e marginalização, quando e onde se manifestem em sistemas algorítmicos ou na tomada de decisões auxiliada por algoritmos. Leia mais sobre o Guia de ML inclusivo e encontre observações sobre imparcialidade ✽ nas diretrizes abaixo. À medida que avançar pelas diretrizes para definir seu conjunto de dados, recomendamos que você pense na imparcialidade com o machine learning, quando relevante ao seu caso de uso.
Fonte dos dados
 Depois de determinar quais dados são necessários, é preciso achar uma forma de
localizá-los. Para começar, considere todos os dados que sua organização coleta.
Você pode descobrir que já está coletando os dados necessários para treinar um modelo.
Se você não tiver os dados de que precisa, é possível reuni-los manualmente ou terceirizar essa tarefa.
Depois de determinar quais dados são necessários, é preciso achar uma forma de
localizá-los. Para começar, considere todos os dados que sua organização coleta.
Você pode descobrir que já está coletando os dados necessários para treinar um modelo.
Se você não tiver os dados de que precisa, é possível reuni-los manualmente ou terceirizar essa tarefa.
Incluir exemplos rotulados suficientes em cada categoria
 O mínimo necessário para o treinamento no AutoML Natural Language é de 10 exemplos de texto por categoria/rótulo.
A probabilidade de um rótulo ser reconhecido corretamente aumenta com o número de
exemplos de alta qualidade para cada um. Em geral, quanto mais dados rotulados você
trouxer para o processo de treinamento, melhor será o modelo. O número de
amostras necessárias também varia com o grau de consistência nos dados que você quer
prever e com o nível de precisão desejado. É possível usar menos exemplos para
conjuntos de dados consistentes ou para ter 80% de precisão em vez de 97%.
Treine um modelo usando 50 exemplos por rótulo e avalie os resultados. Adicione
mais exemplos e treine novamente até atingir as metas de precisão, o que pode
exigir que centenas ou até milhares de exemplos por rótulo.
O mínimo necessário para o treinamento no AutoML Natural Language é de 10 exemplos de texto por categoria/rótulo.
A probabilidade de um rótulo ser reconhecido corretamente aumenta com o número de
exemplos de alta qualidade para cada um. Em geral, quanto mais dados rotulados você
trouxer para o processo de treinamento, melhor será o modelo. O número de
amostras necessárias também varia com o grau de consistência nos dados que você quer
prever e com o nível de precisão desejado. É possível usar menos exemplos para
conjuntos de dados consistentes ou para ter 80% de precisão em vez de 97%.
Treine um modelo usando 50 exemplos por rótulo e avalie os resultados. Adicione
mais exemplos e treine novamente até atingir as metas de precisão, o que pode
exigir que centenas ou até milhares de exemplos por rótulo.
Distribuir exemplos igualmente entre categorias
É importante capturar uma quantidade semelhante de exemplos de treinamento para cada categoria. Mesmo que você tenha muitos dados para um rótulo só, é melhor ter uma distribuição igual para cada um deles. Para entender o motivo, imagine que 80% dos comentários dos clientes usados para criar o modelo são solicitações de orçamento. Com uma distribuição de rótulos tão desigual, provavelmente o modelo aprenderá que um comentário de cliente é sempre uma solicitação de orçamento, em vez de tentar prever um rótulo muito menos comum. É como elaborar um teste de múltipla escolha em que a maioria das respostas corretas é "C". Se a pessoa que for respondê-lo tiver experiência com testes, logo descobrirá que pode responder "C" todas as vezes sem nem ler a pergunta.

Nem sempre é possível conseguir um número similar de exemplos para cada rótulo. Para algumas categorias, pode ser mais difícil encontrar exemplos imparciais e de alta qualidade. Nessas circunstâncias, o rótulo com o menor número de exemplos precisa ter, pelo menos, 10% dos exemplos do rótulo com o maior número de exemplos. Portanto, se o maior rótulo tiver 10.000 exemplos, o menor rótulo precisa ter pelo menos 1.000 exemplos.
Capturar a variação no espaço do problema
Por motivos semelhantes, tente fazer com que os dados capturem a variedade e a diversidade do espaço do problema. Se você fornece um conjunto mais amplo de exemplos, a capacidade do modelo de generalizar dados novos é maior. Imagine que você esteja tentando classificar artigos sobre produtos eletrônicos de consumo em tópicos. Quanto mais nomes de marca e especificações técnicas você fornecer, mais fácil será para o modelo descobrir o tópico de um artigo, mesmo que seja sobre uma marca que não estava no conjunto de treinamento. Também é possível incluir um rótulo "none_of_the_above" para os documentos que não correspondem a nenhum dos rótulos definidos. Isso melhora ainda mais o desempenho do modelo.

Relacionar dados à saída pretendida do modelo

Encontre exemplos de texto semelhantes aos que você está tentando prever. Se o objetivo for classificar postagens em mídias sociais sobre vidro soprado, é pouco provável conseguir um bom desempenho com um modelo treinado em sites de informação sobre esse assunto, já que o vocabulário e o estilo podem ser muito diferentes. O ideal é que seus exemplos de treinamento sejam dados do mundo real, extraídos do mesmo conjunto de dados que você pretende usar o modelo para classificar.
Considerar como o AutoML Natural Language usa o conjunto de dados para criar um modelo personalizado
O conjunto de dados contém conjuntos de treinamento, de validação e de teste. Se você não especificar as divisões, conforme explicado em Preparação dos dados, o AutoML Natural Language usará automaticamente 80% dos documentos de conteúdo para treinamento, 10% para validação e 10% para teste.
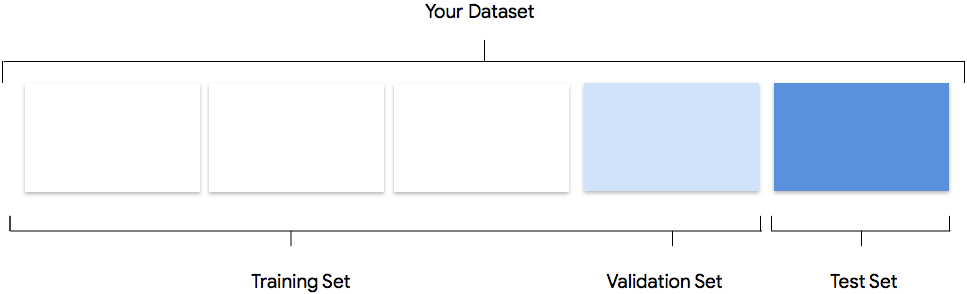
Conjunto de treinamento
 A maior parte dos dados precisa estar no conjunto de treinamento. Esses são os dados que o modelo "vê" durante o treinamento. Eles são usados para aprender os parâmetros do modelo, ou seja, os pesos das conexões entre os nós da rede neural.
A maior parte dos dados precisa estar no conjunto de treinamento. Esses são os dados que o modelo "vê" durante o treinamento. Eles são usados para aprender os parâmetros do modelo, ou seja, os pesos das conexões entre os nós da rede neural.
Conjunto de validação
 O conjunto de validação, que pode ser chamado de conjunto "dev", também é usado durante o processo de treinamento. Depois que os dados são incorporados pelo framework de aprendizado do modelo
em cada iteração do processo de treinamento, o desempenho do modelo
é usado no conjunto de validação para ajustar os hiperparâmetros do modelo, que são variáveis
que especificam a estrutura dele. Se você usar o conjunto de treinamento para ajustar
os hiperparâmetros, é provável que o modelo acabe se concentrando de maneira excessiva nos
dados de treinamento e tenha dificuldade em generalizar exemplos que não correspondam exatamente
a eles. O modelo terá melhor capacidade de generalização se você usar um conjunto de dados
relativamente novo para ajustar a estrutura.
O conjunto de validação, que pode ser chamado de conjunto "dev", também é usado durante o processo de treinamento. Depois que os dados são incorporados pelo framework de aprendizado do modelo
em cada iteração do processo de treinamento, o desempenho do modelo
é usado no conjunto de validação para ajustar os hiperparâmetros do modelo, que são variáveis
que especificam a estrutura dele. Se você usar o conjunto de treinamento para ajustar
os hiperparâmetros, é provável que o modelo acabe se concentrando de maneira excessiva nos
dados de treinamento e tenha dificuldade em generalizar exemplos que não correspondam exatamente
a eles. O modelo terá melhor capacidade de generalização se você usar um conjunto de dados
relativamente novo para ajustar a estrutura.
Conjunto de teste
 O conjunto de teste não faz parte do processo de treinamento. Depois que o treinamento do modelo
for concluído, o AutoML Natural Language usará o conjunto de teste como um
desafio para o modelo. O desempenho do modelo no conjunto de teste serve
para que você tenha uma ideia de como ele vai lidar com dados reais.
O conjunto de teste não faz parte do processo de treinamento. Depois que o treinamento do modelo
for concluído, o AutoML Natural Language usará o conjunto de teste como um
desafio para o modelo. O desempenho do modelo no conjunto de teste serve
para que você tenha uma ideia de como ele vai lidar com dados reais.
Divisão manual
 É possível dividir o conjunto de dados por conta própria. A divisão manual de dados permite
mais controle sobre o processo ou quando houver exemplos específicos que
você tem certeza de que quer incluir em determinada parte do ciclo de treinamento do
modelo.
É possível dividir o conjunto de dados por conta própria. A divisão manual de dados permite
mais controle sobre o processo ou quando houver exemplos específicos que
você tem certeza de que quer incluir em determinada parte do ciclo de treinamento do
modelo.
Preparar os dados para importação

Depois de decidir se uma divisão manual ou automática dos dados é adequada para você, existem três maneiras de adicionar dados no AutoML Natural Language:
- Importe os dados com seus exemplos de texto classificados e armazenados em pastas que correspondam aos rótulos.
- Importe os dados do seu computador ou do Cloud Storage no formato CSV com os rótulos inline, conforme especificado em Como preparar seus dados de treinamento. Se você quiser dividir o conjunto de dados manualmente, precisará escolher essa opção e formatar o CSV de acordo.
- Se os dados não tiverem sido rotulados, será possível enviar exemplos de texto sem rótulos e usar a IU do AutoML Natural Language para aplicar rótulos a cada um deles.
Avaliar
Após treinar o modelo, você receberá um resumo do desempenho. Para ver uma análise detalhada, clique em evaluate ou evaluate.
O que considerar antes de avaliar o modelo?
 A depuração de um modelo se refere mais aos dados do que ao modelo em si. Se o modelo começar a agir de maneira inesperada durante a avaliação do desempenho antes e depois do envio para produção, retorne e verifique os dados para ver como é possível melhorar.
A depuração de um modelo se refere mais aos dados do que ao modelo em si. Se o modelo começar a agir de maneira inesperada durante a avaliação do desempenho antes e depois do envio para produção, retorne e verifique os dados para ver como é possível melhorar.
Que tipos de análise posso executar no AutoML Natural Language?
Na seção de avaliação do AutoML Natural Language, é possível verificar o desempenho do modelo personalizado por meio do resultado com exemplos de teste e métricas comuns de machine learning. Esta seção aborda o significado de cada um dos conceitos a seguir:
- Saída
- Limite de pontuação
- Verdadeiros positivos, verdadeiros negativos, falsos positivos e falsos negativos
- Precisão e recall
- Curvas de precisão/recall
- Precisão média
Como interpretar a saída do modelo?
O AutoML Natural Language extrai exemplos dos dados de teste para apresentar novos desafios para o modelo. Para cada exemplo, são gerados pelo modelo vários números que servem para comunicar a intensidade da associação do rótulo a esse exemplo. Se o número for alto, o modelo terá certeza de que o rótulo precisa ser aplicado a esse documento.
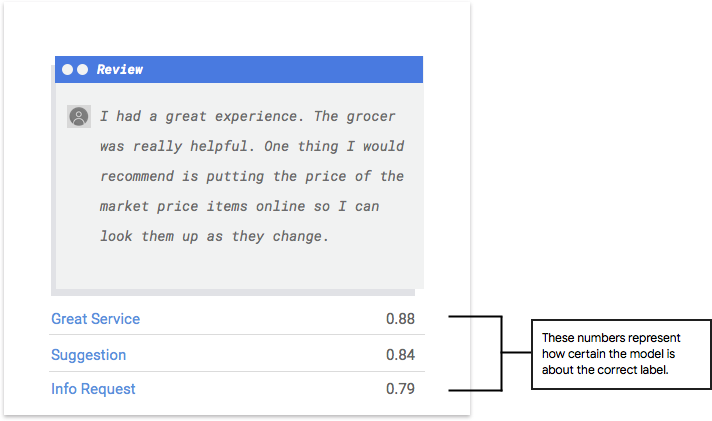
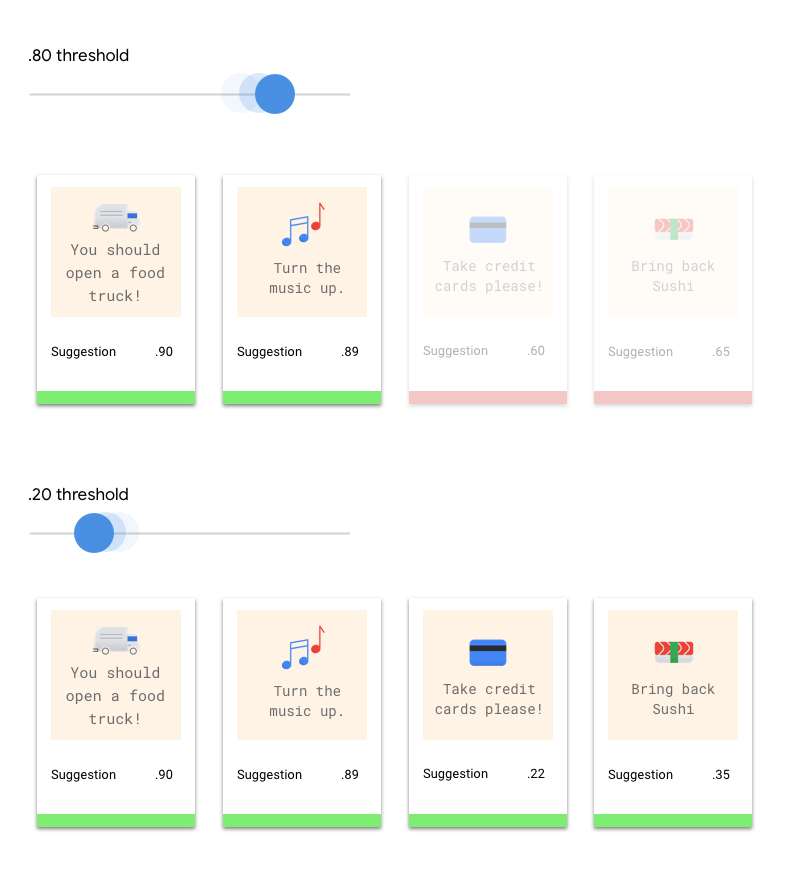
Qual é o limite de pontuação?
O limite de pontuação permite que o AutoML Natural Language converta probabilidades em valores "on"/"off" binários. Esse limite se refere ao nível de confiança que o modelo precisa ter para atribuir uma categoria a um item de teste. O controle deslizante de limite de pontuação na IU é uma ferramenta visual para testar o impacto de diferentes limites no conjunto de dados. No exemplo acima, se definirmos o limite de pontuação como 0,8 para todas as categorias, "Ótimo serviço" e "Sugestão" serão atribuídos, mas "Solicitação de informação", não. Se o limite de pontuação for baixo, o modelo classificará mais itens de texto, mas o risco de errar na classificação será maior. Se o limite de pontuação for alto, o modelo classificará menos itens de texto, mas o risco de classificar incorretamente será menor. Para testar, ajuste os limites por categoria na IU. No entanto, ao usar o modelo na produção, é necessário impor os limites que você achou ideais.
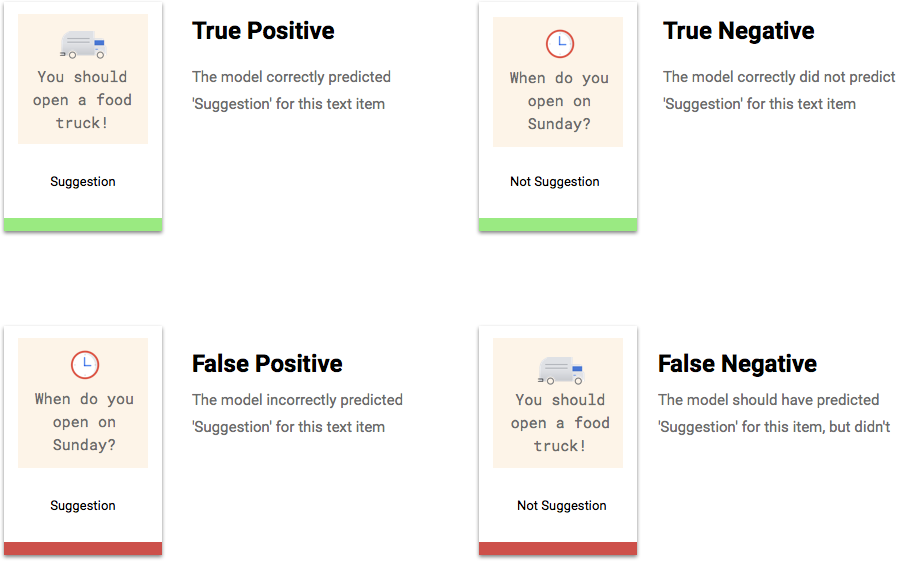
O que são verdadeiros positivos, verdadeiros negativos, falsos positivos e falsos negativos?
Depois de aplicar o limite de pontuação, cada previsão feita pelo modelo se encaixará em uma das quatro categorias a seguir.
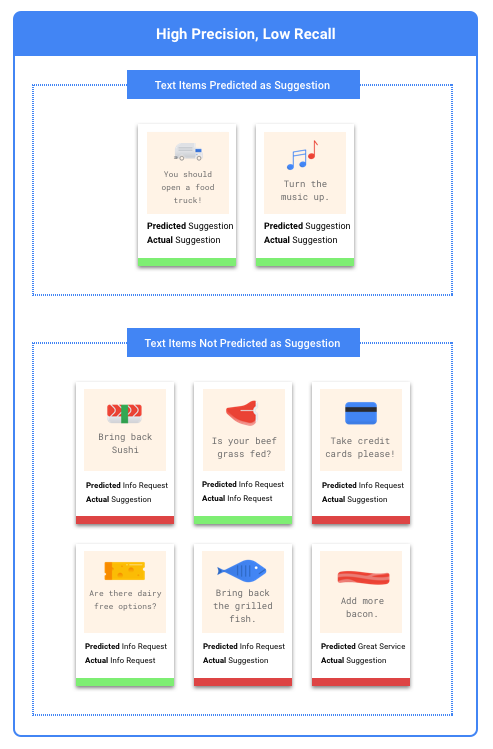
Use essas categorias para calcular a precisão e o recall, que são métricas que ajudam a avaliar a eficácia do modelo.
O que são precisão e recall?
A precisão e o recall ajudam a avaliar se o modelo está capturando informações satisfatoriamente e quanta informação não está sendo considerada. Entre todos os exemplos de teste que receberam um rótulo determinado, a precisão informa quantos realmente deveriam ser categorizados com ele. De todos os exemplos de teste que deveriam ter recebido um determinado rótulo, o recall indica quantos realmente foram categorizados com ele.

É necessário otimizar a precisão ou o recall?
Dependendo do caso de uso, é preciso otimizar a precisão ou o recall. Vamos examinar como abordar essa decisão com os dois casos de uso a seguir.
Caso de uso: documentos urgentes
Imagine que você quer criar um sistema que consiga dar prioridade a documentos urgentes.

Um falso positivo, neste caso, seria um documento que não é urgente, mas é marcado como tal. O usuário pode dispensá-lo como não urgente e seguir em frente.

Já um falso negativo seria um documento urgente, mas que o sistema não sinalizou como tal. Isso pode causar problemas!
Nesse caso, é melhor otimizar o recall. Essa métrica mede quantos dados não estão sendo considerados em todas as previsões feitas. É provável que um modelo com recall alto rotule exemplos ligeiramente relevantes, o que é útil para casos em que a categoria tem poucos dados de treinamento.
Caso de uso: filtro de spam
Digamos que você queira criar um sistema que filtre automaticamente as mensagens de e-mail que sejam spam.

Um falso negativo, neste caso, seria um e-mail de spam que não seja detectado e que você veja na sua caixa de entrada. Normalmente, isso é um pouco irritante.

Um falso positivo, neste caso, seria um e-mail falsamente marcado como spam e removido da sua caixa de entrada. Se o e-mail foi importante, é possível que o usuário seja afetado negativamente.
Nesse caso, é melhor otimizar a precisão. Essa métrica mede, para todas as previsões feitas, o quanto elas são corretas. Um modelo de alta precisão provavelmente rotulará apenas os exemplos mais relevantes, o que é útil para casos em que sua categoria é comum nos dados de treinamento.
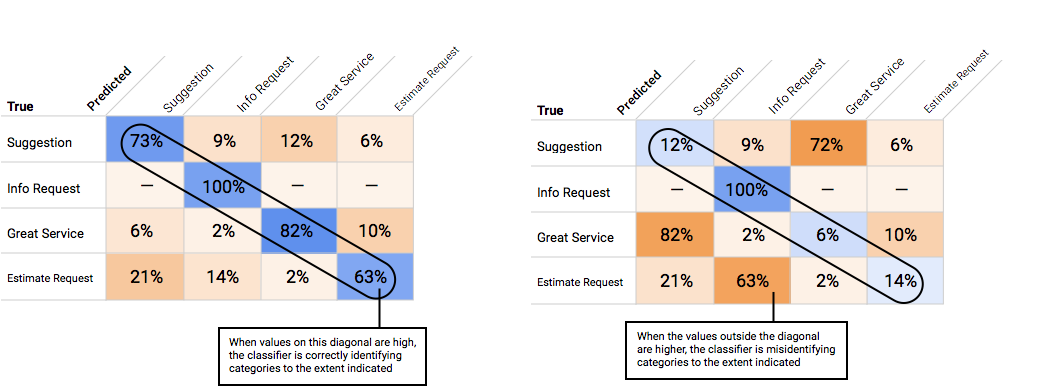
Como usar a matriz de confusão?
Podemos comparar o desempenho do modelo em cada rótulo com uma matriz de confusão. Em um modelo ideal, todos os valores na diagonal serão altos, e todos os demais serão baixos. Isso mostra que as categorias estão sendo identificadas corretamente. Se outros valores forem altos, será um indício de como o modelo está classificando erroneamente os itens de teste.
Como interpretar as curvas de precisão/recall?
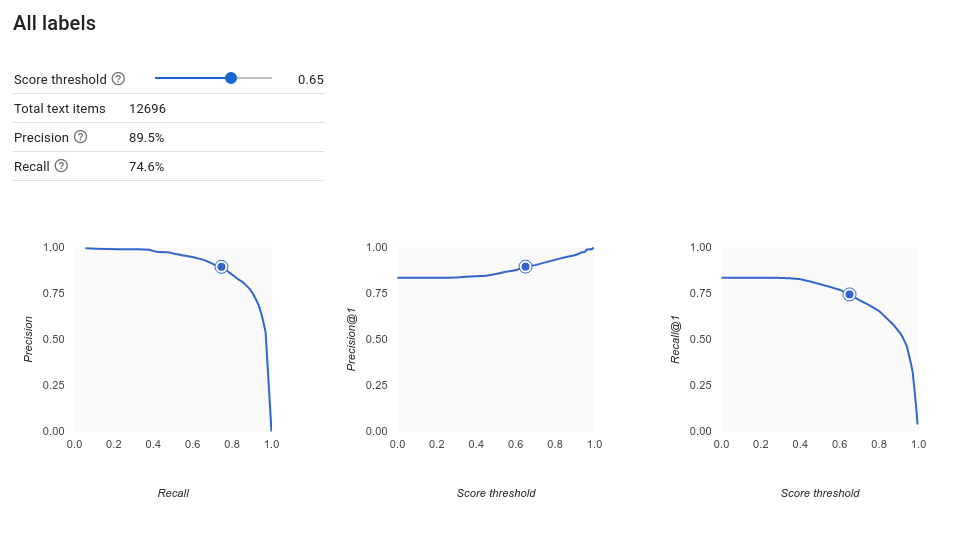
Com a ferramenta de limite de pontuação, você pode explorar como a precisão e o recall são afetados. À medida que você arrasta o controle deslizante, é possível ver a posição da curva de troca de recall e precisão, além de entender como esse limite afeta cada métrica individualmente. Para modelos com várias categorias, nesses gráficos, o único rótulo usado para calcular as métricas de precisão e recall é o mais bem classificado no conjunto retornado. Isso pode ajudar você a encontrar a melhor proporção entre falsos positivos e falsos negativos.
Depois de escolher um limite que pareça aceitável para o modelo como um todo, clique nos rótulos individuais e veja onde esse limite se encaixa na curva de recall e precisão de cada um. Em alguns casos, isso pode significar muitas previsões incorretas para alguns rótulos, o que pode ajudar você a escolher um limite por categoria personalizado para esses rótulos. Por exemplo, digamos que, no conjunto de dados de comentários de clientes, você perceba que um limite de 0,5 tem precisão e recall razoáveis para todos os tipos de comentário exceto "Sugestão", talvez porque essa seja uma categoria bem genérica. Para essa categoria, há muitos falsos positivos. Nesse caso, use um limite de 0,8 apenas para "Sugestão" quando chamar o classificador de previsões.
O que é precisão média?
Uma métrica útil para a acurácia do modelo é a área sob a curva de recall e precisão. Ele mede o desempenho do seu modelo em todos os limites de pontuação. No AutoML Natural Language, essa métrica é chamada de precisão média. Quanto mais próxima de 1.0 for essa pontuação, melhor será o desempenho do modelo no conjunto de teste. Um modelo que adivinhar aleatoriamente cada rótulo teria uma precisão média em torno de 0,5.
Como testar seu modelo
 Para testar o modelo, o AutoML Natural Language usa 10% dos dados automaticamente ou, se você escolheu a divisão de dados, a porcentagem que você escolheu usar. A página
"Avaliar" informa o desempenho do modelo nos dados de teste. Mas, caso você queira verificar a integridade do seu modelo, há algumas maneiras de fazer isso. O mais fácil é inserir exemplos de texto na caixa de texto da página "Prever" e observar os rótulos que o modelo escolhe para os exemplos. Esperamos que isso corresponda
às suas expectativas. Teste alguns exemplos de cada tipo de comentário que você espera receber.
Para testar o modelo, o AutoML Natural Language usa 10% dos dados automaticamente ou, se você escolheu a divisão de dados, a porcentagem que você escolheu usar. A página
"Avaliar" informa o desempenho do modelo nos dados de teste. Mas, caso você queira verificar a integridade do seu modelo, há algumas maneiras de fazer isso. O mais fácil é inserir exemplos de texto na caixa de texto da página "Prever" e observar os rótulos que o modelo escolhe para os exemplos. Esperamos que isso corresponda
às suas expectativas. Teste alguns exemplos de cada tipo de comentário que você espera receber.
Se você quiser usar seu modelo em testes automatizados, a página "Prever" informará como fazer chamadas para o modelo programaticamente.