Introduction
Supposons que votre entreprise dispose d'un formulaire de contact sur son site Web. Vous recevez chaque jour de nombreux messages du formulaire, dont beaucoup sont exploitables. Toutefois, tous ces messages arrivent tous ensemble et vous pouvez facilement vous retrouver débordé dans la mesure où selon leur type, les différents messages ne sont pas gérés par les mêmes employés. Pour remédier à cela, il faudrait que les commentaires soient classés par un système automatisé afin qu'ils soient adressés à la personne appropriée.
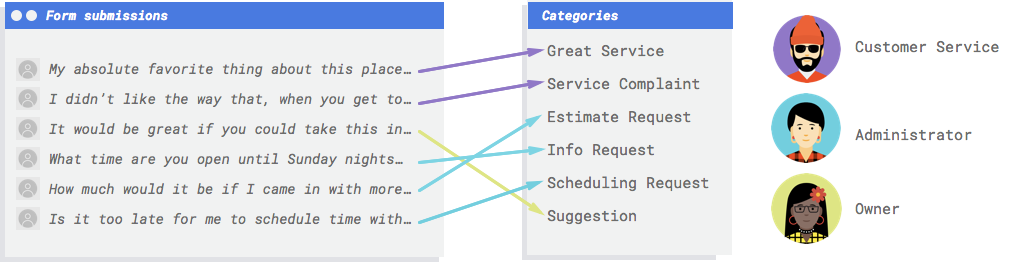
Vous avez besoin d'un système pour examiner les commentaires et déterminer s'ils représentent des réclamations, des compliments sur vos services, des demandes d'informations sur votre entreprise, des prises de rendez-vous ou des mises en relation.
En quoi un système de machine learning (ML) constitue-t-il un outil adapté pour résoudre ce problème ?
 Généralement, un programme suppose que le programmeur spécifie des instructions détaillées que l'ordinateur doit suivre. Mais cette approche devient rapidement impossible. Les commentaires des clients utilisent un vocabulaire et une structure larges et variés, trop diversifiés pour être capturés par un simple ensemble de règles. Si vous essayez de créer des filtres manuels, vous vous apercevrez rapidement que vous n'étiez pas en mesure de classer la grande majorité des commentaires de vos clients. Vous avez besoin d'un système capable de généraliser à une grande variété de commentaires.
Dans un scénario où une séquence de règles spécifiques est censée se développer de manière exponentielle, vous avez besoin d'un système capable d'apprendre à partir d'exemples. Heureusement, les systèmes de ML
sont bien positionnés pour résoudre ce problème.
Généralement, un programme suppose que le programmeur spécifie des instructions détaillées que l'ordinateur doit suivre. Mais cette approche devient rapidement impossible. Les commentaires des clients utilisent un vocabulaire et une structure larges et variés, trop diversifiés pour être capturés par un simple ensemble de règles. Si vous essayez de créer des filtres manuels, vous vous apercevrez rapidement que vous n'étiez pas en mesure de classer la grande majorité des commentaires de vos clients. Vous avez besoin d'un système capable de généraliser à une grande variété de commentaires.
Dans un scénario où une séquence de règles spécifiques est censée se développer de manière exponentielle, vous avez besoin d'un système capable d'apprendre à partir d'exemples. Heureusement, les systèmes de ML
sont bien positionnés pour résoudre ce problème.
L'API Cloud Natural Language ou AutoML Natural Language sont-ils les outils adaptés pour moi ?
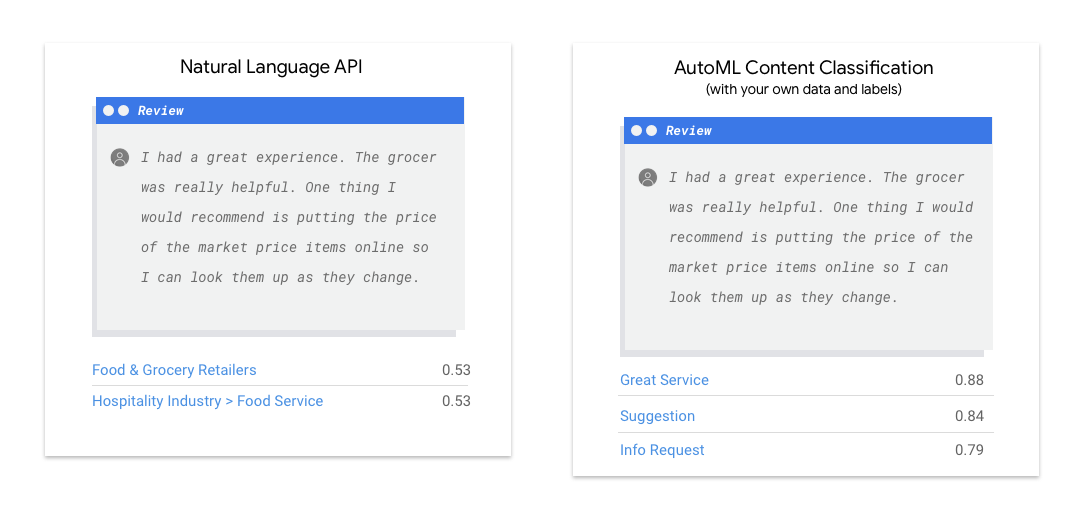
L'API Natural Language détecte la syntaxe, les entités et les sentiments dans les chaînes de texte, puis classe celles-ci dans un ensemble de catégories prédéfinies. Si votre texte contient des articles de presse ou tout autre contenu que vous souhaitez classer par catégories, ou si vous souhaitez connaître le sentiment de vos exemples, l'API Natural Language peut s'avérer utile. En revanche, si vos exemples textuels ne s'intègrent pas parfaitement au schéma de classification basé sur les sentiments ou les sujets verticaux disponible dans l'API Natural Language et que vous souhaitez utiliser vos propres libellés à la place, cela vaut la peine de tester un classificateur personnalisé afin de déterminer s'il répond à vos besoins.
| Essayer l'API Natural Language | Premiers pas avec AutoML |
Qu'implique le machine learning dans AutoML Natural Language ?
 Le machine learning implique l'utilisation de données pour entraîner des algorithmes afin d'obtenir le résultat souhaité. Les spécificités de l'algorithme et les méthodes d'entraînement varient selon le cas d'utilisation. Il existe de nombreuses sous-catégories de machine learning, qui résolvent toutes des problèmes différents et fonctionnent avec des contraintes variées. AutoML Natural Language vous permet d'effectuer un apprentissage supervisé. Cela consiste à entraîner un ordinateur à détecter des tendances à partir de données étiquetées. Avec l'apprentissage supervisé, vous pouvez entraîner un modèle personnalisé pour identifier du contenu qui vous intéresse dans du texte.
Le machine learning implique l'utilisation de données pour entraîner des algorithmes afin d'obtenir le résultat souhaité. Les spécificités de l'algorithme et les méthodes d'entraînement varient selon le cas d'utilisation. Il existe de nombreuses sous-catégories de machine learning, qui résolvent toutes des problèmes différents et fonctionnent avec des contraintes variées. AutoML Natural Language vous permet d'effectuer un apprentissage supervisé. Cela consiste à entraîner un ordinateur à détecter des tendances à partir de données étiquetées. Avec l'apprentissage supervisé, vous pouvez entraîner un modèle personnalisé pour identifier du contenu qui vous intéresse dans du texte.
Préparation des données
Pour entraîner un modèle personnalisé avec AutoML Natural Language, vous devez fournir des exemples étiquetés des types d'éléments textuels (les "entrées") que vous souhaitez classifier, ainsi que les catégories ou libellés (la "réponse") que les systèmes de machine learning doivent prédire.
Appréciation de votre cas d'utilisation

Lorsque vous constituez un ensemble de données, commencez toujours par définir son cas d'utilisation. Dans un premier temps, posez-vous les questions suivantes :
- Quel résultat souhaitez-vous obtenir ?
- Quels types de catégories devez-vous identifier pour atteindre ce résultat ?
- En tant qu'humain, est-il possible de reconnaître ces catégories ? La capacité d'AutoML Natural Language à gérer et à attribuer à tout moment un panel de catégories est certes supérieure à celle de l'être humain. Toutefois, si ce dernier ne parvient pas à reconnaître une catégorie spécifique, son traitement posera également problème à AutoML Natural Language.
- Quels types d'exemples refléteraient le mieux le type et la plage de données que votre système va classer ?
Les produits de ML de Google reposent sur un principe fondamental : le machine learning centré sur l'humain, une approche qui met en avant les pratiques d'IA responsables, y compris l'équité. En matière de ML, l'équité consiste à comprendre et éviter tout traitement injuste ou préjudiciable des individus en fonction de leur origine ethnique, leurs revenus, leur orientation sexuelle, leur religion, leur genre ou d'autres caractéristiques qui sont associées, historiquement, à des faits de discrimination et de marginalisation, lorsque ces phénomènes se manifestent dans les systèmes algorithmiques ou les processus décisionnels assistés par un algorithme. Pour en savoir plus, consultez le Guide sur le machine learning inclusif et recherchez les remarques portant sur l'équité ✽ dans les consignes suivantes. Lors de la lecture des consignes permettant la mise en place de votre ensemble de données, nous vous incitons à appliquer ce principe d'équité dans le machine learning lorsque cela est pertinent pour votre cas d'utilisation.
Collecter des données
 Une fois que vous avez défini les données dont vous avez besoin, vous devez trouver un moyen de les collecter. Vous pouvez commencer par prendre en compte toutes les données que votre organisation recueille.
Vous constaterez peut-être que vous collectez déjà les données dont vous avez besoin pour entraîner un modèle.
Dans le cas contraire, vous pouvez les obtenir manuellement ou confier cette étape à un fournisseur tiers.
Une fois que vous avez défini les données dont vous avez besoin, vous devez trouver un moyen de les collecter. Vous pouvez commencer par prendre en compte toutes les données que votre organisation recueille.
Vous constaterez peut-être que vous collectez déjà les données dont vous avez besoin pour entraîner un modèle.
Dans le cas contraire, vous pouvez les obtenir manuellement ou confier cette étape à un fournisseur tiers.
Inclure suffisamment d'exemples avec libellé pour chaque catégorie
 Pour entraîner votre modèle, vous devez inclure au strict minimum 10 exemples textuels par catégorie ou libellé sur AutoML Natural Language.
Plus vous fournissez d'exemples de bonne qualité par libellé, plus les chances qu'elle soit correctement reconnue augmentent. De manière générale, plus vous incluez de données étiquetées dans le processus d'entraînement, meilleur sera votre modèle. Le nombre d'échantillons nécessaires varie également en fonction du degré de cohérence des données à prédire et du niveau de précision à atteindre. Vous pouvez utiliser moins d'exemples pour des ensembles de données cohérents ou pour atteindre une précision de 80 % plutôt que 97 %.
Entraînez un modèle en utilisant 50 exemples par libellé, puis évaluez les résultats. Ajoutez plus d'exemples et reprenez l'entraînement jusqu'à ce que vous atteigniez vos objectifs de précision, ce qui peut nécessiter des centaines, voire des milliers d'exemples par libellé.
Pour entraîner votre modèle, vous devez inclure au strict minimum 10 exemples textuels par catégorie ou libellé sur AutoML Natural Language.
Plus vous fournissez d'exemples de bonne qualité par libellé, plus les chances qu'elle soit correctement reconnue augmentent. De manière générale, plus vous incluez de données étiquetées dans le processus d'entraînement, meilleur sera votre modèle. Le nombre d'échantillons nécessaires varie également en fonction du degré de cohérence des données à prédire et du niveau de précision à atteindre. Vous pouvez utiliser moins d'exemples pour des ensembles de données cohérents ou pour atteindre une précision de 80 % plutôt que 97 %.
Entraînez un modèle en utilisant 50 exemples par libellé, puis évaluez les résultats. Ajoutez plus d'exemples et reprenez l'entraînement jusqu'à ce que vous atteigniez vos objectifs de précision, ce qui peut nécessiter des centaines, voire des milliers d'exemples par libellé.
Répartir équitablement les exemples entre les catégories
Il est important d'obtenir un nombre d'exemples d'entraînement similaire pour chaque catégorie. Même si vous disposez d'une abondance de données pour un libellé, il est préférable d'avoir une distribution égale pour chaque libellé. Pour comprendre pourquoi, imaginez que 80 % des commentaires des clients que vous utilisez pour créer votre modèle correspondent à des demandes de devis. En présence d'une répartition des libellés aussi déséquilibrée, il est très probable que votre modèle apprenne qu’il est judicieux de toujours indiquer que les commentaires des clients correspondent à des demandes de devis, plutôt que d'essayer de prédire un libellé beaucoup moins courant. Ce cas de figure est comparable à un questionnaire à choix multiples où presque toutes les bonnes réponses sont "C" et où la personne répondant au questionnaire va très vite déduire qu'elle peut répondre "C" à chaque fois, sans même regarder la question.

Il n'est pas toujours possible de trouver un nombre à peu près équivalent d'exemples pour chaque libellé. Pour certaines catégories, il peut être plus difficile de collecter des exemples non biaisés de bonne qualité. Dans ce cas, le libellé comprenant le moins d'exemples doit compter au moins 10 % du total d'exemples du libellé en comportant le plus. Par exemple, si le libellé le plus représenté comporte 10 000 exemples, le libellé le moins représenté devrait en présenter au moins 1 000.
Tenir compte des variations dans votre espace de problème
Pour des raisons similaires, essayez de faire en sorte que vos données tiennent compte de la variété et de la diversité de votre espace de problème. Lorsque vous fournissez un ensemble d'exemples plus important, le modèle peut plus facilement être généralisé à de nouvelles données. Supposons que vous essayiez de classer des articles sur les produits électroniques grand public en fonction de leur sujet. Plus vous fournissez de noms de marques et de caractéristiques techniques, plus le modèle comprendra facilement le sujet d'un article, même si cet article concerne une marque qui n'a pas été intégrée à l'ensemble de données d'entraînement. Vous pouvez également inclure un libellé "Autres" pour les documents ne correspondant à aucun des libellé définis afin d'améliorer plus encore les performances du modèle.
Trouver des données correspondant aux résultats souhaités du modèle

Trouvez des exemples textuels similaires à ceux sur lesquels vous prévoyez d'effectuer des prédictions. Si vous essayez de classer des posts sur les réseaux sociaux concernant le soufflage de verre, un modèle entraîné sur des sites Web contenant des informations sur ce sujet risque de ne pas s'avérer très performant, car le vocabulaire et le style peuvent varier sensiblement. Dans l'idéal, vos exemples d'entraînement sont constitués de données réelles tirées du même ensemble de données que celui sur lequel vous prévoyez d'utiliser le modèle pour la classification.
Comprendre comment AutoML Natural Language utilise les ensembles de données lors de la création de modèles personnalisés
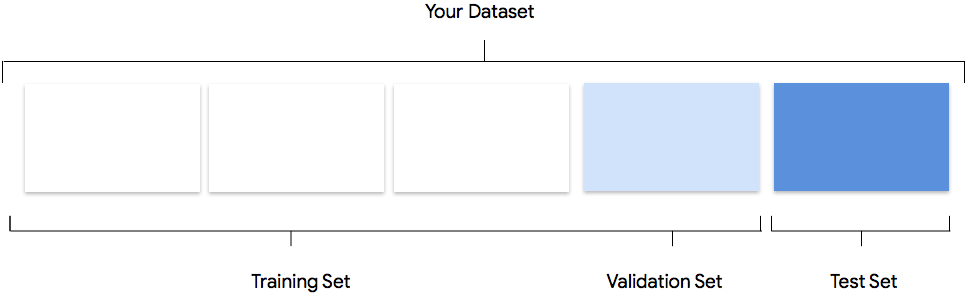
Votre ensemble de données contient des ensembles d'entraînement, de validation et de test. Si vous ne spécifiez pas cette répartition comme décrit sur la page Préparer vos données, AutoML Natural Language utilise par défaut 80 % de vos documents textuels pour l'entraînement, 10 % pour la validation et 10 % pour l'évaluation.
Ensemble d'entraînement
 La grande majorité de vos données doit figurer dans l'ensemble d'entraînement. Il s'agit des données auxquelles votre modèle accède pendant l'entraînement. Elles sont utilisées pour apprendre ses paramètres, à savoir les pondérations des connexions entre les nœuds du réseau de neurones.
La grande majorité de vos données doit figurer dans l'ensemble d'entraînement. Il s'agit des données auxquelles votre modèle accède pendant l'entraînement. Elles sont utilisées pour apprendre ses paramètres, à savoir les pondérations des connexions entre les nœuds du réseau de neurones.
Ensemble de validation
 L'ensemble de validation, parfois également appelé "ensemble de dev", est également utilisé lors du processus d'entraînement. Une fois que le framework d'apprentissage du modèle a incorporé les données d'entraînement à chaque itération du processus, il utilise les performances du modèle sur l'ensemble de validation pour ajuster ses hyperparamètres, qui sont des variables spécifiant sa structure. Si vous essayez d'utiliser l'ensemble d'entraînement pour régler les hyperparamètres, il est probable que le modèle finisse par trop se focaliser sur les données d'entraînement. Vous aurez alors du mal à généraliser le modèle à des exemples légèrement différents. L'utilisation d'un ensemble de données relativement nouveau pour affiner la structure du modèle permet une meilleure généralisation du modèle à d'autres données.
L'ensemble de validation, parfois également appelé "ensemble de dev", est également utilisé lors du processus d'entraînement. Une fois que le framework d'apprentissage du modèle a incorporé les données d'entraînement à chaque itération du processus, il utilise les performances du modèle sur l'ensemble de validation pour ajuster ses hyperparamètres, qui sont des variables spécifiant sa structure. Si vous essayez d'utiliser l'ensemble d'entraînement pour régler les hyperparamètres, il est probable que le modèle finisse par trop se focaliser sur les données d'entraînement. Vous aurez alors du mal à généraliser le modèle à des exemples légèrement différents. L'utilisation d'un ensemble de données relativement nouveau pour affiner la structure du modèle permet une meilleure généralisation du modèle à d'autres données.
Ensemble de test
 L'ensemble de test n'est pas impliqué dans le processus d'entraînement. Une fois celui-ci terminé, AutoML Natural Language utilise l'ensemble de test qui représente un défi pour votre modèle. Les performances de votre modèle sur l'ensemble de test sont supposées vous fournir une idée des performances de votre modèle sur des données réelles.
L'ensemble de test n'est pas impliqué dans le processus d'entraînement. Une fois celui-ci terminé, AutoML Natural Language utilise l'ensemble de test qui représente un défi pour votre modèle. Les performances de votre modèle sur l'ensemble de test sont supposées vous fournir une idée des performances de votre modèle sur des données réelles.
Répartition manuelle
 Vous pouvez scinder votre ensemble de données vous-même. Répartir manuellement vos données vous permet d'exercer davantage de contrôle sur le processus ou si vous souhaitez absolument inclure des exemples spécifiques dans une certaine partie du cycle de vie de l'entraînement d'un modèle.
Vous pouvez scinder votre ensemble de données vous-même. Répartir manuellement vos données vous permet d'exercer davantage de contrôle sur le processus ou si vous souhaitez absolument inclure des exemples spécifiques dans une certaine partie du cycle de vie de l'entraînement d'un modèle.
Préparer les données pour l'importation

Une fois que vous avez déterminé si vous souhaitez procéder à la répartition manuelle ou automatique de vos données, trois méthodes vous permettent d'ajouter des données dans AutoML Natural Language :
- Vous pouvez importer des données avec vos exemples textuels triés et stockés dans des dossiers correspondant aux libellés.
- Vous pouvez importer des données à partir de votre ordinateur ou de Cloud Storage au format CSV avec les libellés intégrés, comme indiqué dans la section Préparer vos données d'entraînement. Si vous souhaitez effectuer une répartition manuelle de l'ensemble de données, vous devez choisir cette option et procéder à la mise en forme appropriée du fichier CSV.
- Si vos données n'ont pas de libellé, vous pouvez importer des exemples textuels sans libellé et utiliser l'interface utilisateur d'AutoML Natural Language pour appliquer des libellés à chaque exemple.
Évaluation
Une fois le modèle entraîné, vous recevez un résumé de ses performances. Pour afficher une analyse détaillée, cliquez sur evaluate ou evaluate.
Que dois-je garder à l'esprit avant d'évaluer un modèle ?
 Le débogage d'un modèle consiste davantage à déboguer les données que le modèle proprement dit. Si votre modèle commence à agir de manière inattendue lorsque vous évaluez ses performances avant et après le passage en production, vous devez revenir en arrière et vérifier vos données pour déterminer comment les améliorer.
Le débogage d'un modèle consiste davantage à déboguer les données que le modèle proprement dit. Si votre modèle commence à agir de manière inattendue lorsque vous évaluez ses performances avant et après le passage en production, vous devez revenir en arrière et vérifier vos données pour déterminer comment les améliorer.
Quels types d'analyses puis-je effectuer dans AutoML Natural Language ?
Dans la section d'évaluation d'AutoML Natural Language, vous pouvez évaluer les performances de votre modèle personnalisé en vous appuyant sur la sortie générée par le modèle sur les exemples de test et sur les principales statistiques d'apprentissage du machine learning. Cette section explique la signification de chacun des concepts suivants :
- Les résultats du modèle
- Le seuil de score
- Les vrais positifs, les vrais négatifs, les faux positifs et les faux négatifs
- La précision et le rappel
- Les courbes de précision et de rappel
- La précision moyenne
Comment interpréter la sortie du modèle ?
AutoML Natural Language tire des exemples de vos données de test afin de présenter de nouveaux défis pour votre modèle. Pour chaque exemple, le modèle génère une série de nombres qui indiquent le degré de confiance selon lequel il associe chaque libellé à cet échantillon. Si le nombre est élevé, le modèle conclut avec une confiance élevée que le libellé doit être attribué à ce document.

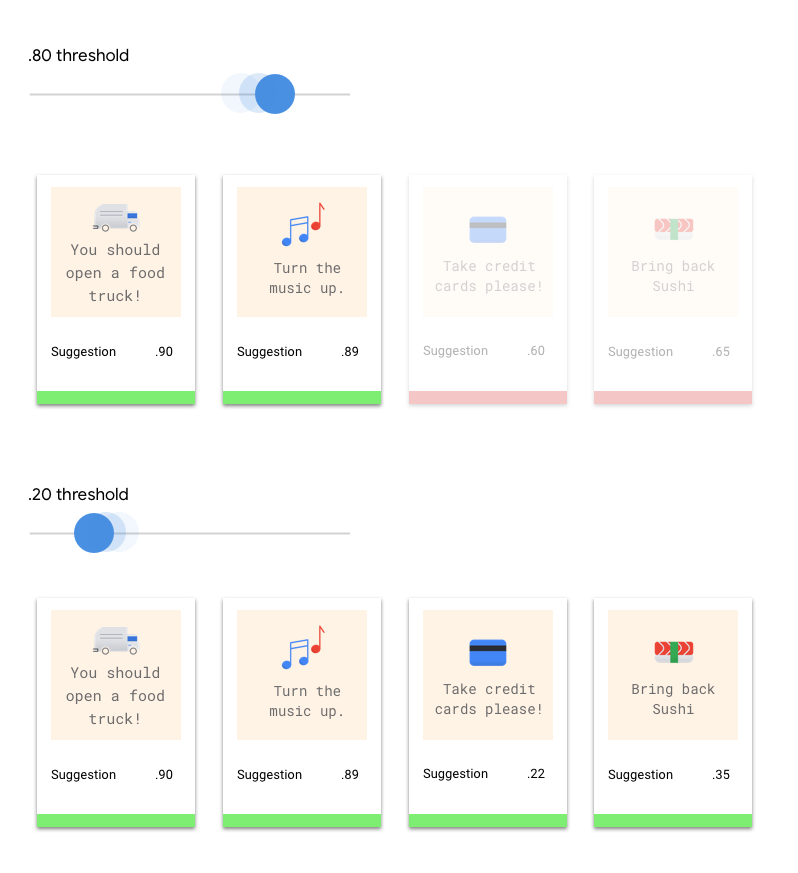
Qu'est-ce que le seuil de score ?
Le seuil de score permet à AutoML Natural Language de convertir les probabilités en valeurs binaires "on"/"off". Le seuil de score représente le degré de confiance que le modèle doit avoir pour attribuer une catégorie à un élément de test. Le curseur du seuil du score dans l'interface utilisateur est un outil visuel permettant de tester l'impact des différents seuils dans votre ensemble de données. Dans l'exemple ci-dessus, si nous définissons le seuil de score sur 0,8 pour toutes les catégories, les libellés "Excellent service" et "Suggestion" seront attribués, mais pas "Demande d'informations". Si votre seuil de score est faible, votre modèle classera davantage d'éléments textuels, mais risque de mal classer plus d'éléments textuels par la même occasion. Si votre seuil de score est élevé, le modèle classera moins d'éléments textuels, mais le risque d'erreur de classification de ces éléments sera moindre. Vous pouvez modifier les seuils par catégorie dans l'interface utilisateur. Cependant, lors de l'utilisation de votre modèle en production, vous devrez appliquer les seuils que vous avez constatés comme étant les plus performants.
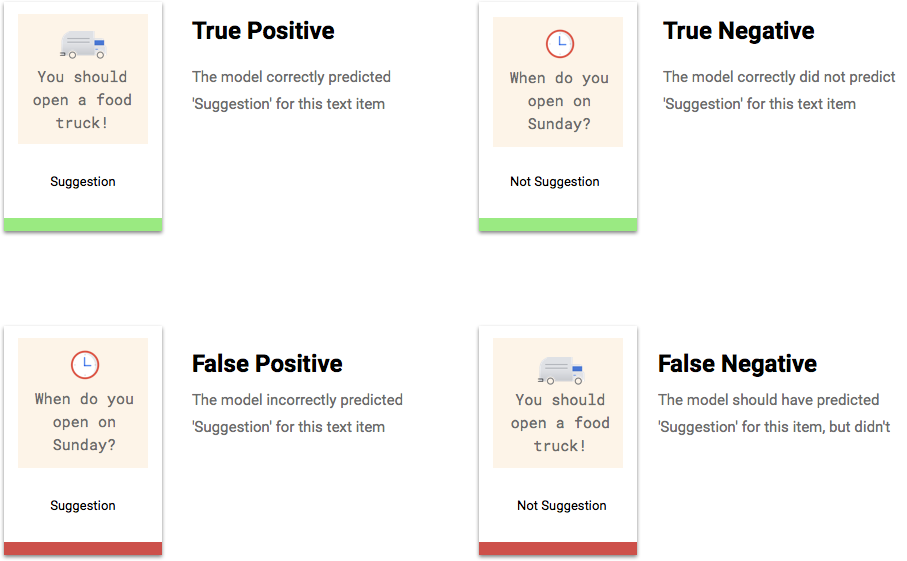
En quoi consistent les vrais positifs, vrais négatifs, faux positifs et faux négatifs ?
Après application du seuil de score, les prédictions effectuées par votre modèle sont classées dans l’une des quatre catégories suivantes.
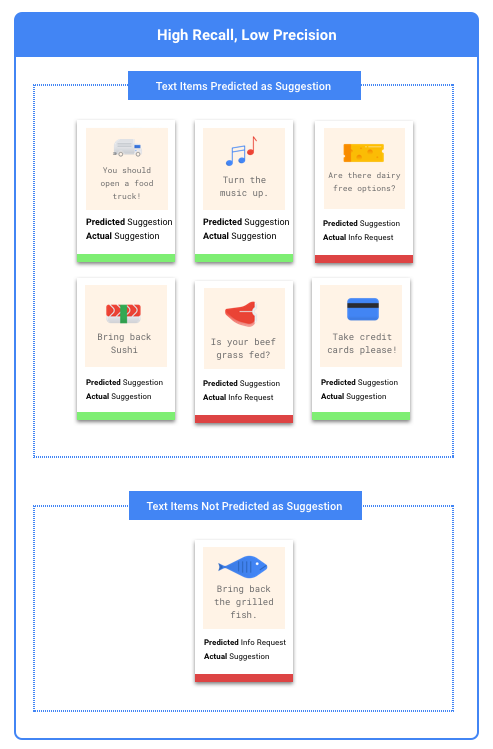
Ces catégories peuvent être utilisées pour calculer la précision et le rappel, des statistiques permettant d'évaluer plus facilement l'efficacité d'un modèle.
Que sont la précision et le rappel ?
La précision et le rappel permettent d'évaluer la qualité de la collecte d'informations, ainsi que la quantité d'informations omises par un modèle. La précision indique le nombre d'exemples de test auxquels un libellé a été correctement attribué parmi tous les exemples classifiés. Le rappel indique le nombre d'exemples de test auxquels un libellé donné a été attribué, parmi tous les exemples qui auraient dû être classifiés sous ce libellé.

Dois-je privilégier l'optimisation de la précision ou celle du rappel ?
Selon votre cas d'utilisation, il se peut que vous souhaitiez privilégier la précision ou le rappel. Étudions comment prendre cette décision à l'aide des deux cas d'utilisation suivants.
Cas d'utilisation : documents urgents
Imaginons que vous vouliez créer un système capable de hiérarchiser les documents urgents par rapport à ceux qui ne le sont pas.

Dans ce cas, un faux positif correspond à un document qui n’est pas urgent, mais qui est indiqué comme tel. L'utilisateur peut le classifier de nouveau comme non urgent avant de consulter les autres documents.

Dans ce cas, un faux négatif correspond à un document urgent, mais non détecté comme tel par le système. Cela risque d'entraîner des problèmes.
Dans cette situation, il convient d'optimiser le paramètre de rappel. Cette statistique mesure le nombre de documents non détectés sur l'ensemble des prédictions effectuées. Un modèle disposant d'un taux de rappel élevé est susceptible d'attribuer un libellé à des exemples dont la pertinence est faible, ce qui est utile dans les cas où une catégorie contient peu de données d'entraînement.
Cas d'utilisation : filtre anti-spam
Supposons que vous souhaitiez créer un système permettant de filtrer automatiquement les e-mails en séparant le spam des autres messages.

Dans ce cas, un faux négatif correspond à un message de spam non détecté qui s'affiche dans votre boîte de réception. En général, c'est un peu frustrant.

Dans ce cas, un faux positif correspond à un e-mail signalé à tort comme du spam, et qui est supprimé de votre boîte de réception. Si l'e-mail était important, cela peut avoir une incidence négative sur l'utilisateur.
Dans cette situation, il convient d'optimiser le paramètre de précision. Cette statistique mesure l'exactitude de l'ensemble des prédictions effectuées. Un modèle disposant d'un taux de précision élevé est susceptible de n'indiquer que les exemples les plus pertinents, ce qui est utile dans les cas où une catégorie est récurrente dans les données d'entraînement.
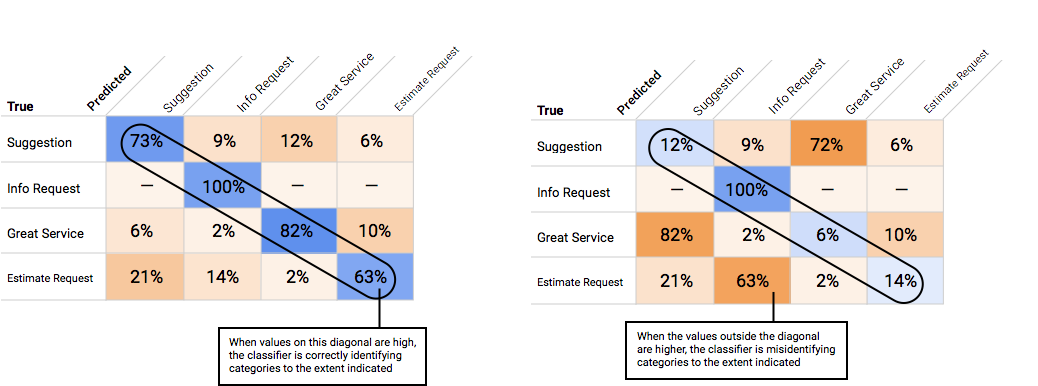
Comment utiliser la matrice de confusion ?
Nous pouvons comparer les performances du modèle pour chaque libellé en utilisant une matrice de confusion. Dans un modèle idéal, toutes les valeurs comprises dans la diagonale de la matrice sont élevées, et toutes les autres valeurs sont faibles. Cela indique que les catégories souhaitées sont correctement identifiées. Si d'autres valeurs sont élevées, cela permet de comprendre les motifs d'erreurs de classification des éléments d'évaluation du modèle.
Comment interpréter les courbes de précision et de rappel ?
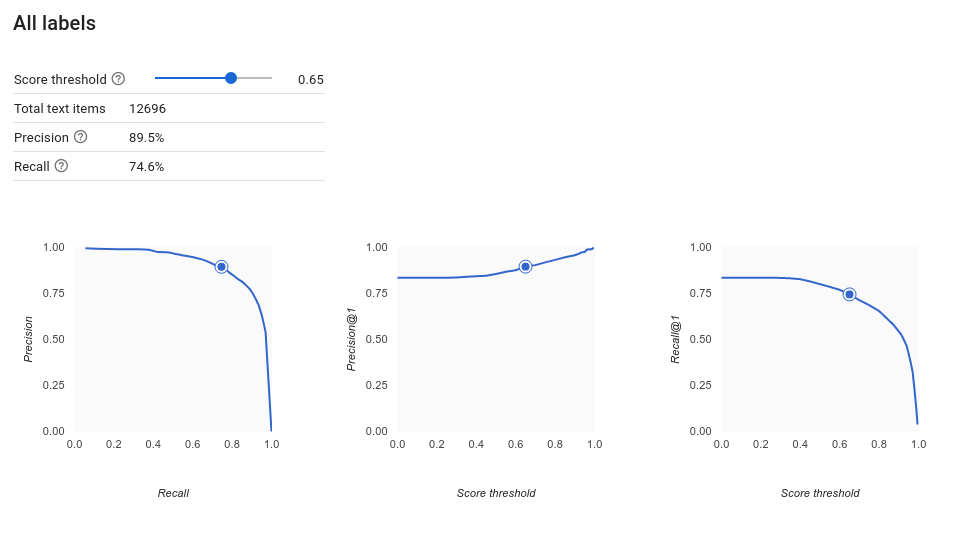
L'outil de seuil de score permet de découvrir comment le seuil choisi affecte la précision et le rappel. En faisant glisser le curseur le long de la barre de seuil de score, vous pouvez constater où se situe ce seuil sur la courbe de précision et de rappel, ainsi que son effet sur ces paramètres. Pour les modèles multiclasses, les paramètres de précision et de rappel de ces graphiques indiquent que le seul libellé utilisé pour calculer ces statistiques correspond au mieux noté parmi l'ensemble de libellés renvoyés. Cela permet de trouver un bon équilibre entre les faux positifs et les faux négatifs.
Une fois que vous avez choisi un seuil qui semble globalement acceptable pour votre modèle, vous pouvez cliquer sur des libellés spécifiques afin de voir pour chaque libellé où se situe ce seuil sur la courbe de précision/rappel. Dans certains cas, cela peut impliquer un grand nombre de prédictions incorrectes pour certains libellés, ce qui peut vous conduire à définir un seuil personnalisé pour les classes correspondant à ces libellés. Supposons, par exemple, que vous examiniez l'ensemble de données contenant les commentaires de vos clients et que vous remarquiez qu'un seuil de 0,5 dispose d'un taux de précision et de rappel convenable pour tous les types de commentaires, à l'exception des suggestions. Vous constatez en effet une multitude de faux positifs pour cette catégorie. Dans ce cas, vous pouvez décider d'utiliser un seuil de 0,8 uniquement pour la catégorie "Suggestion", lorsque vous appelez le classificateur pour effectuer des prédictions.
Qu'est-ce que la précision moyenne ?
La zone présente sous la courbe de précision et de rappel constitue une statistique utile pour cerner la précision du modèle. Elle permet de mesurer les performances de votre modèle vis-à-vis de l'ensemble des seuils de score. Dans AutoML Natural Language, cette statistique s'appelle la précision moyenne. Plus ce score est proche de 1,0, meilleures seront les performances de votre modèle sur l'ensemble de test. Pour un modèle effectuant des prédictions au hasard pour chaque libellé, la précision moyenne obtenue avoisinerait le score de 0,5.
Tester le modèle
 Pour tester le modèle, AutoML Natural Language utilise automatiquement 10% de vos données (ou le pourcentage que vous avez choisi d'utiliser, si vous avez choisi de les répartir vous-même). La page "Évaluation" vous indique les performances du modèle sur ces données de test. Toutefois, si vous souhaitez vérifier l'intégrité de votre modèle, plusieurs méthodes s'offrent à vous. Le plus simple consiste à saisir des exemples textuels dans la zone de texte de la page "Prédiction" et à examiner les étiquettes choisies par le modèle pour vos exemples. J'espère que cela correspond
à vos attentes. Essayez de saisir quelques exemples pour chaque type de commentaire que vous pensez recevoir.
Pour tester le modèle, AutoML Natural Language utilise automatiquement 10% de vos données (ou le pourcentage que vous avez choisi d'utiliser, si vous avez choisi de les répartir vous-même). La page "Évaluation" vous indique les performances du modèle sur ces données de test. Toutefois, si vous souhaitez vérifier l'intégrité de votre modèle, plusieurs méthodes s'offrent à vous. Le plus simple consiste à saisir des exemples textuels dans la zone de texte de la page "Prédiction" et à examiner les étiquettes choisies par le modèle pour vos exemples. J'espère que cela correspond
à vos attentes. Essayez de saisir quelques exemples pour chaque type de commentaire que vous pensez recevoir.
Si vous souhaitez utiliser votre modèle dans vos propres tests automatisés, la page "Prédiction" vous indique comment appeler le modèle par programmation.