Neste documento, apresentamos a linguagem de consulta do Monitoring (MQL, na sigla em inglês) com exemplos. No entanto, ele não tenta abranger todos os aspectos da linguagem. O MQL é documentado de maneira abrangente na referência da linguagem de consulta do Monitoring.
Para informações sobre políticas de alertas baseadas em MQL, consulte Políticas de alertas com MQL.
É possível escrever uma consulta específica de várias formas. A linguagem é flexível, e há muitos atalhos que você pode usar depois de se familiarizar com a sintaxe. Para mais informações, veja Consultas de formato restrito.
Antes de começar
Para acessar o editor de código usando o Metrics Explorer, faça o seguinte:
-
No painel de navegação do console do Google Cloud, selecione Monitoramento e leaderboard Metrics Explorer:
- Na barra de ferramentas do painel do criador de consultas, selecione o botão code MQL ou code PromQL.
- Verifique se MQL está selecionado na opção de ativar/desativar Idioma. A alternância de idiomas está na mesma barra de ferramentas que permite formatar sua consulta.
Para executar uma consulta, cole-a no editor e clique em Executar consulta. Para uma introdução a esse editor, consulte Usar o editor de código para MQL.
Convém ter alguma familiaridade com os conceitos do Cloud Monitoring, incluindo tipos de métricas, tipos de recursos monitorados e séries temporais. Para ver uma introdução a esses conceitos, consulte Métricas, séries temporais e recursos.
Modelo de dados
As consultas MQL recuperam e manipulam dados no banco de dados de séries temporais do Cloud Monitoring. Esta seção apresenta alguns dos conceitos e terminologia relacionados a esse banco de dados. Para informações detalhadas, consulte o tópico de referência Modelo de dados.
Toda série temporal se origina de um único tipo de recurso monitorado, e cada série temporal coleta dados de um tipo de métrica.
Um descritor de recurso monitorado define um tipo de recurso monitorado. Da mesma forma, um descritor de métrica define um tipo de métrica.
Por exemplo, o tipo de recurso pode ser gce_instance, uma máquina virtual (VM) do Compute Engine, e o tipo de métrica pode ser compute.googleapis.com/instance/cpu/utilization, a utilização da CPU da VM do Compute Engine.
Esses descritores também especificam um conjunto de rótulos usados para coletar informações sobre outros atributos da métrica ou do tipo de recurso. Por exemplo, os recursos normalmente têm um rótulo zone, usado para registrar a localização geográfica do recurso.
Uma série temporal é criada para cada combinação de valores dos rótulos do par de um descritor de métrica e um descritor de recurso monitorado.
É possível encontrar os rótulos disponíveis para tipos de recursos na Lista de recursos monitorados, por exemplo, gce_instance.
Para encontrar os rótulos dos tipos de métrica, consulte a Lista de métricas.
Por exemplo, consulte métricas do Compute Engine.
O banco de dados do Cloud Monitoring armazena a série temporal de uma determinada métrica e tipo de recurso em uma tabela. A métrica e o tipo de recurso atuam como o identificador da tabela. Essa consulta MQL busca a tabela de séries temporais que registra a utilização da CPU de instâncias do Compute Engine:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
Há uma série temporal na tabela para cada combinação exclusiva de valores de rótulo de métrica e recurso.
As consultas MQL recuperam dados de série temporal dessas tabelas e os transformam em tabelas de saída. Essas tabelas de saída podem ser transmitidas para outras operações. Por exemplo, é possível isolar a série temporal gravada por recursos em uma determinada zona ou conjunto de zonas transmitindo a tabela recuperada como entrada de uma operação filter:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| filter zone =~ 'us-central.*'
A consulta anterior resulta em uma tabela que contém apenas a série temporal de recursos em uma zona que começa com us-central.
As consultas MQL são estruturadas para passar a saída de uma operação como entrada para a operação seguinte. Essa abordagem baseada em tabela permite vincular operações para manipular esses dados filtrando, selecionando e realizando outras operações de banco de dados conhecidas, como junções internas e externas. Também é possível executar várias funções nos dados da série temporal à medida que os dados são transmitidos de uma operação para outra.
As operações e funções disponíveis na MQL são documentadas de forma abrangente na Referência da linguagem de consulta do Monitoring.
Estrutura da consulta
Uma consulta é composta por uma ou mais operations. As operações são vinculadas ou canalizadas para que a saída de uma operação seja a entrada para a próxima. Portanto, o resultado de uma consulta depende da ordem das operações. Algumas das coisas que você pode fazer incluem:
- Inicie uma consulta com uma
fetchou outra operação de seleção. - Crie uma consulta com várias operações conectadas.
- Selecione um subconjunto de informações com operações
filter. - Agregue informações relacionadas com operações
group_by. - Observe os valores atípicos com as operações
topebottom. - Combine várias consultas com operações
{ ; }ejoin. - Use a operação e as funções
valuepara calcular proporções e outros valores.
Nem todas as consultas usam todas essas opções.
Esses exemplos introduzem apenas algumas das operações e funções disponíveis. Para informações detalhadas sobre a estrutura de consultas MQL, consulte o tópico de referência Estrutura de consulta.
Esses exemplos não especificam duas coisas que você pode esperar ver: períodos e alinhamento. As seções a seguir explicam o motivo.
Períodos
Quando você usa o editor de código, as configurações do gráfico definem o período das consultas. Por padrão, o período do gráfico é definido como uma hora.
Para mudar o período do gráfico, use o seletor de período. Por exemplo, se você quiser consultar os dados da última semana, selecione Última semana no seletor de período. Você também pode especificar um horário de início e de término ou um horário para ver o mapa.
Para mais informações sobre períodos no editor de código, consulte Intervalos de tempo, gráficos e o editor de código.
Alinhamento
Muitas das operações usadas nesses exemplos, como as operações join e group_by, dependem de todos os pontos de série temporal em uma tabela que ocorre em intervalos regulares. O ato de alinhar todos os pontos em carimbos de data/hora regulares é chamado de alignment. Normalmente, o alinhamento é feito implicitamente, e nenhum dos exemplos aqui o mostra.
O MQL alinha automaticamente as tabelas para operações join e group_by
quando necessário, mas também permite o alinhamento explícito.
Para informações gerais sobre o conceito de alinhamento, consulte Alinhamento: agregação dentro de séries.
Para informações sobre alinhamento na MQL, consulte o tópico de referência Alinhamento. O alinhamento pode ser controlado explicitamente usando as operações
aligneevery.
Busque e filtre dados
As consultas MQL começam com a recuperação e a seleção ou filtragem de dados. Nesta seção, ilustramos alguns processos básicos de recuperação e filtragem com o MQL.
Recuperar dados de séries temporais
Uma consulta sempre começa com uma operação fetch, que recupera séries temporais do Cloud Monitoring.
A consulta mais simples consiste em uma única operação fetch e um argumento que identifica a série temporal a ser buscada, como a seguinte:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
O argumento consiste em um tipo de recurso monitorado, gce_instance, um par de caracteres de dois pontos, :: e um tipo de métrica, compute.googleapis.com/instance/cpu/utilization.
Essa consulta recupera a série temporal escrita pelas instâncias do Compute Engine para o tipo de métrica compute.googleapis.com/instance/cpu/utilization, que registra a utilização da CPU dessas instâncias.
Se você executar a consulta do editor de código no Metrics Explorer, terá um gráfico mostrando cada uma das série temporal solicitadas:
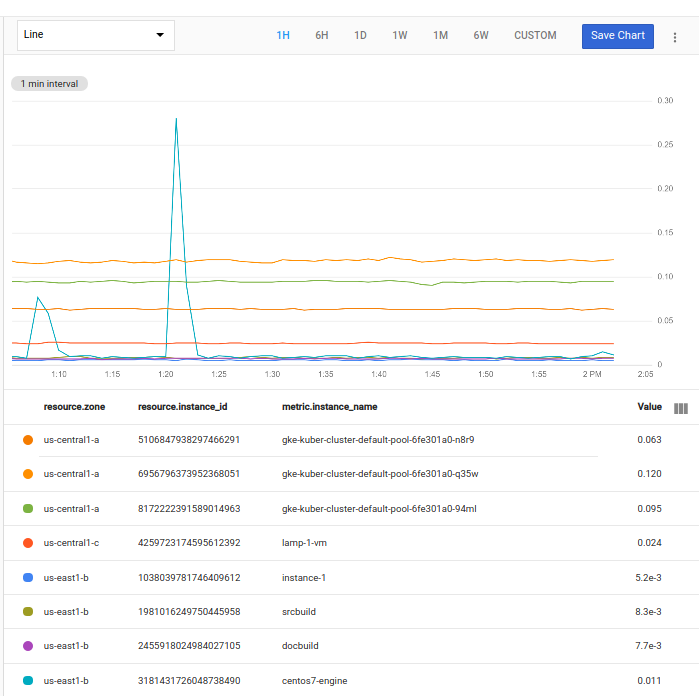
Cada uma das séries temporais solicitadas é exibida como uma linha no gráfico. Cada série temporal inclui uma lista de valores com carimbo de data/hora da métrica de utilização da CPU de uma instância de VM nesse projeto.
No armazenamento de back-end usado pelo Cloud Monitoring, as série temporal são armazenadas em tabelas. A operação fetch organiza a série temporal para os tipos de métricas e recursos monitorados especificados em uma tabela e, em seguida, retorna a tabela.
Os dados retornados são exibidos no gráfico.
A operação fetch é descrita, junto com os argumentos dela, na página de referência da operação fetch. Para mais informações sobre os dados produzidos por operações, consulte as páginas de referência de séries temporais e tabelas.
Filtrar operações
As consultas normalmente consistem em uma combinação de várias operações. A combinação mais simples é canalizar a saída de uma operação na entrada da próxima usando o operador de barra vertical, |. O exemplo a seguir ilustra o uso de uma barra vertical para inserir a tabela em uma operação de filtro:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| filter instance_name =~ 'gke.*'
Essa consulta canaliza a tabela, retornada pela operação fetch mostrada no
exemplo anterior, para uma operação filter que toma como uma expressão
que é avaliada como um valor booleano. Neste exemplo, a expressão significa que
"instance_name começa com gke".
A operação filter usa a tabela de entrada, remove a série temporal para a qual o filtro é falso e gera a tabela resultante. A captura de tela a seguir mostra o gráfico resultante:
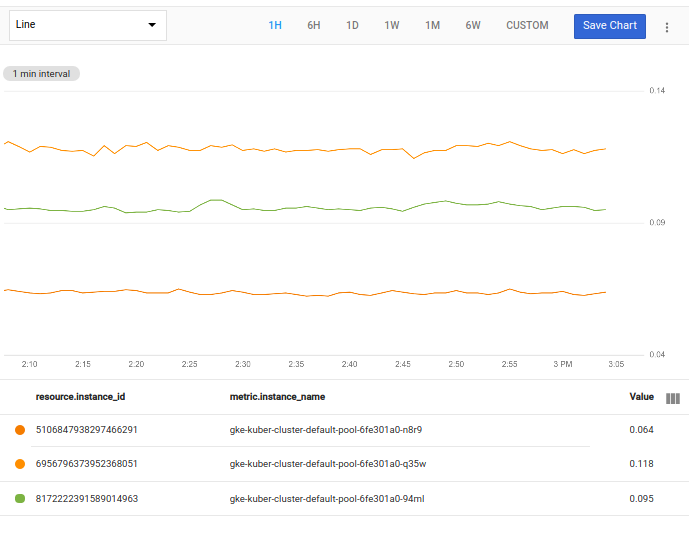
Se você não tiver nenhum nome de instância que comece com gke, altere o filtro antes de tentar essa consulta. Por exemplo, se você tiver instâncias de VM com apache no início dos nomes, use o seguinte filtro:
| filter instance_name =~ 'apache.*'
A expressão filter é avaliada uma vez para cada série temporal de entrada.
Se a expressão for avaliada como true, essa série temporal será incluída na saída. Nesse exemplo, a expressão de filtro faz uma correspondência de expressão regular, =~, no rótulo instance_name de cada série temporal. Se o valor do rótulo corresponder à expressão regular 'gke.*', a série temporal será incluída na saída. Caso contrário, a série temporal é descartada da saída.
Para mais informações sobre filtragem, consulte a página de referência filter.
O predicado filter pode ser qualquer expressão arbitrária que retorne um valor booleano. Para mais informações, consulte Expressões.
Agrupar e agregar
Com o agrupamento, é possível agrupar série temporal em dimensões específicas. A agregação combina todas as séries temporais de um grupo em uma série temporal de saída.
A consulta a seguir filtra a saída da operação fetch inicial para reter apenas as séries temporais de recursos em uma zona que começa com us-central. Em seguida, ela agrupa as séries temporais por zona e as combina usando a agregação mean.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| filter zone =~ 'us-central.*'
| group_by [zone], mean(val())
A tabela resultante da operação group_by tem uma série temporal por zona.
A captura de tela a seguir mostra o gráfico resultante:
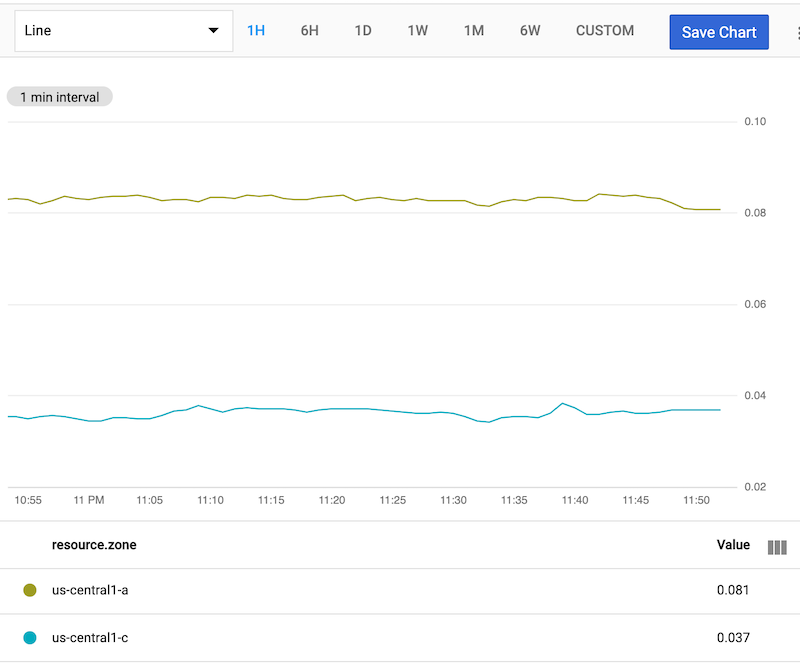
A operação group_by usa dois argumentos, separados por vírgula, ,. Esses argumentos determinam o comportamento de agrupamento preciso. Neste exemplo, group_by [zone], mean(val()), os argumentos funcionam da seguinte maneira:
O primeiro argumento,
[zone], é uma expressão de mapa que determina o agrupamento da série temporal. Neste exemplo, ele especifica os rótulos a serem usados para o agrupamento. A etapa de agrupamento coleta todas as série temporal de entrada que têm os mesmos valores dezonede saída em um grupo. Neste exemplo, a expressão coleta a série temporal das VMs do Compute Engine em uma zona.A série temporal de saída tem apenas um rótulo
zone, com o valor copiado da série temporal de entrada no grupo. Outros rótulos na série temporal de entrada são descartados da série temporal de saída.A expressão de mapa pode fazer muito mais do que listar rótulos. Para mais informações, consulte a página de referência
map.O segundo argumento,
mean(val()), determina como as séries temporais em cada grupo são combinadas, ou aggregated, em uma série temporal de saída. Cada ponto na série temporal de saída de um grupo é o resultado da agregação dos pontos com o mesmo carimbo de data/hora de todas as séries temporais de entrada no grupo.A função de agregação,
mean, neste exemplo, determina o valor agregado. A funçãoval()retorna os pontos a serem agregados, e a função de agregação é aplicada a eles. Nesse exemplo, você obtém a média da utilização da CPU das máquinas virtuais na zona em cada ponto de tempo de saída.A expressão
mean(val())é um exemplo de uma expressão de agregação.
A operação group_by sempre combina agrupamento e agregação.
Se você especificar um agrupamento, mas omitir o argumento de agregação, a group_by usará uma agregação padrão, aggregate(val()), que seleciona uma função apropriada para o tipo de dados. Consulte aggregate para ver a lista de funções de agregação padrão.
Usar group_by com uma métrica com base em registros
Suponha que você tenha criado uma métrica com base em registros de distribuição para extrair o número de pontos de dados processados de um conjunto de entradas longas, incluindo strings como estas:
... entry ID 1 ... Processed data points 1000 ... ... entry ID 2 ... Processed data points 1500 ... ... entry ID 3 ... Processed data points 1000 ... ... entry ID 4 ... Processed data points 500 ...
Para criar uma série temporal que mostre a contagem de todos os pontos de dados processados, use um MQL como o seguinte:
fetch global
| metric 'logging.googleapis.com/user/METRIC_NAME'
| group_by [], sum(sum_from(value))
Para criar uma métrica de distribuição com base em registros, consulte Configurar métricas de distribuição.
Excluir colunas de um grupo
Use o modificador drop em um mapeamento para excluir colunas de um
grupo.
Por exemplo, a métrica core_usage_time do Kubernetes tem seis colunas:
fetch k8s_container :: kubernetes.io/container/cpu/core_usage_time | group_by [project_id, location, cluster_name, namespace_name, container_name]
Se você não precisar agrupar pod_name, poderá excluí-lo com drop:
fetch k8s_container :: kubernetes.io/container/cpu/core_usage_time | group_by drop [pod_name]
Selecionar série temporal
Os exemplos nesta seção ilustram maneiras de selecionar séries temporais específicas de uma tabela de entrada.
Selecionar a série temporal principal ou inferior
Para ver os dados da série temporal das três instâncias do Compute Engine com a maior utilização da CPU no projeto, digite a seguinte consulta:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top 3
A captura de tela a seguir mostra o resultado de um projeto:
É possível recuperar a série temporal com a menor utilização da CPU substituindo top por bottom.
A operação top gera uma tabela com um número especificado de séries temporais selecionadas da tabela de entrada. As séries temporais incluídas na saída têm o maior valor para algum aspecto da série temporal.
Como essa consulta não especifica uma maneira de ordenar as série temporal, ela retorna as série temporal com o maior valor para o ponto mais recente.
Para especificar como determinar qual série temporal tem o maior valor, forneça um argumento para a operação top. Por exemplo, a consulta anterior é equivalente à seguinte consulta:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top 3, val()
A expressão val() seleciona o valor do ponto mais recente em cada série temporal a que é aplicada. Portanto, a consulta retorna essas série temporal com o maior valor para o ponto mais recente.
Você pode fornecer uma expressão que agrega em alguns ou todos os pontos de uma série temporal para fornecer o valor de classificação. Veja a seguir a média de todos os pontos nos últimos 10 minutos:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top 3, mean(val()).within(10m)
Se a função within não for usada, a função mean será aplicada aos valores de todos os pontos exibidos na série temporal.
A operação bottom funciona de maneira semelhante.
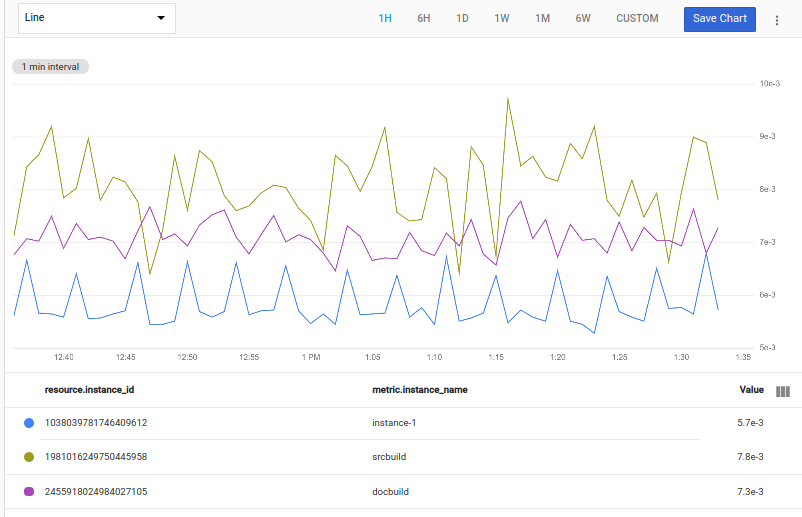
A consulta a seguir encontra o valor do maior ponto em cada série temporal com max(val()) e seleciona as três séries temporais para as quais esse valor é o menor:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| bottom 3, max(val())
A captura de tela a seguir mostra um gráfico exibindo os streams com os menores picos:
Excluir os n resultados de cima ou de baixo na série temporal
Imagine um cenário em que você tem muitas instâncias de VM do Compute Engine. Algumas dessas instâncias consomem muito mais memória do que a maioria das instâncias, e esses outliers estão dificultando a visualização dos padrões de uso no grupo maior. Os gráficos de uso da CPU têm a seguinte aparência:
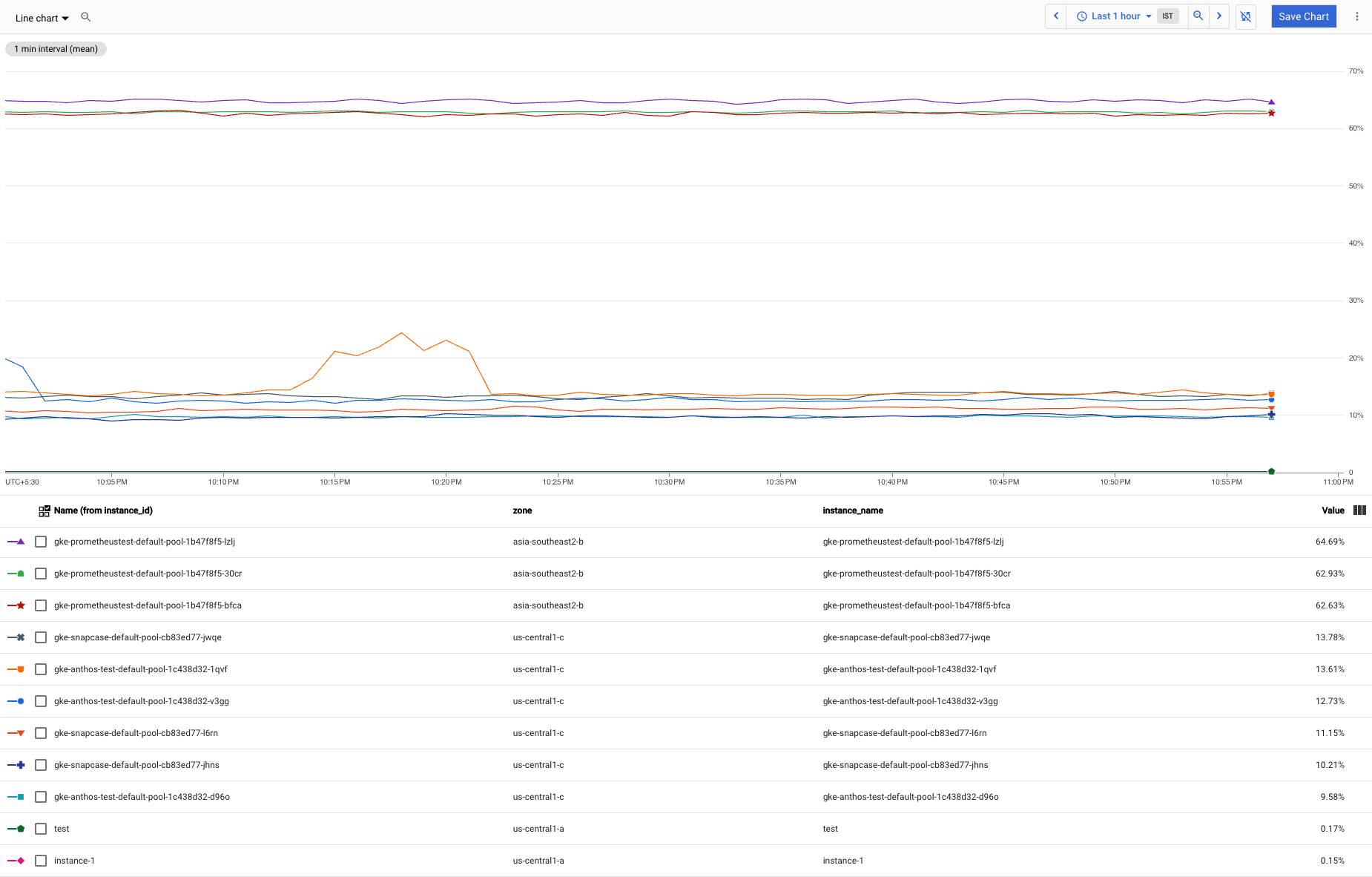
Exclua os três valores atípicos do gráfico para ver os padrões no grupo maior com mais clareza.
Para excluir as três principais séries temporais de uma consulta que recupera a série temporal referente à utilização da CPU do Compute Engine, use a operação de tabela top para identificá-la e a operação de tabela outer_join para excluir dos resultados a série temporal identificada. Use a
seguinte consulta:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| {
top 3 | value [is_default_value: false()]
;
ident
}
| outer_join true(), _
| filter is_default_value
| value drop [is_default_value]
A operação fetch retorna uma tabela de série temporal para a utilização da CPU de todas as instâncias. Essa tabela é processada em duas tabelas resultantes:
A operação de tabela
top ngera uma tabela que contém a série temporal n com os valores mais altos. Nesse caso, n = 3. A tabela resultante contém as três séries temporais a serem excluídas.A tabela que contém as três principais série temporal é canalizada para uma operação de tabela
value. Essa operação adiciona outra coluna a cada série temporal da tabela dos três primeiros itens. Essa coluna,is_default_value, recebe o valor booleanofalsepara todas as série temporal nas três primeiras tabelas.A operação
identretorna a mesma tabela que foi canalizada: a tabela original de série temporal de utilização da CPU. Nenhuma das séries temporais nesta tabela tem a colunais_default_value.
As três tabelas principais e a original são canalizadas para a
operação de tabela outer_join. A tabela de cima para baixo é a tabela à esquerda na mesclagem, e a tabela buscada é a tabela à direita na mesclagem.
A mesclagem externa é configurada para fornecer o valor true como o valor de
qualquer campo que não existe em uma linha que está sendo mesclada. O resultado da mesclagem externa é uma tabela mesclada, em que as linhas das três primeiras tabelas mantêm a coluna is_default_value com o valor false, e todas as linhas da tabela original que não estavam na tabela original recebem a coluna is_default_value com o valor true.
A tabela resultante da junção é transmitida para a operação de tabela filter, que filtra as linhas que têm um
valor de false na coluna is_default_value. A tabela resultante contém as linhas da tabela originalmente buscada, sem as linhas das três primeiras. Esta tabela contém o conjunto pretendido de série temporal, com o is_default_column adicionado.
A etapa final é descartar a coluna is_default_column que foi adicionada pela mesclagem para que a tabela de saída tenha as mesmas colunas da tabela originalmente buscada.
A captura de tela a seguir mostra o gráfico da consulta anterior:
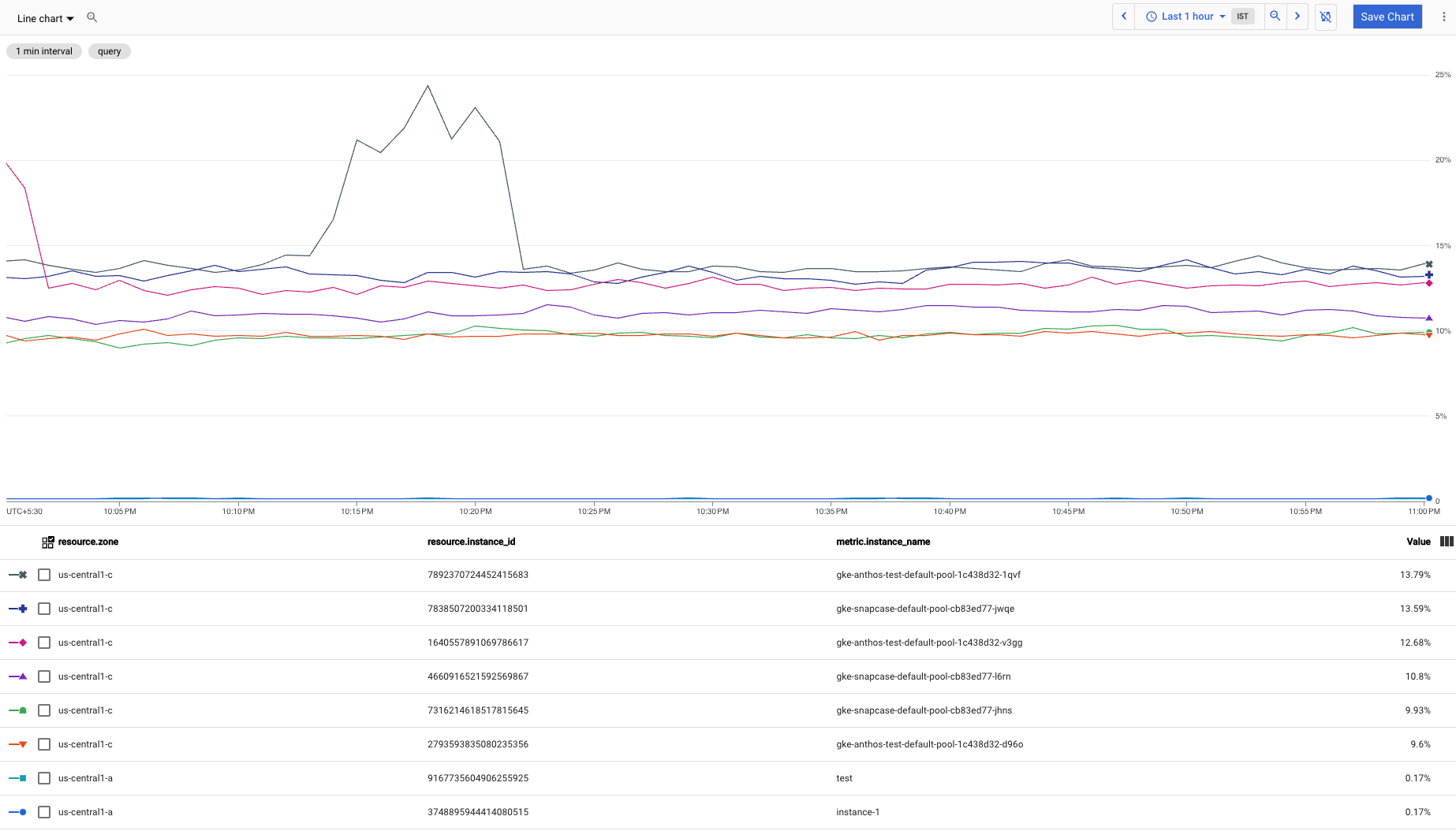
É possível criar uma consulta para excluir a série temporal com a menor
utilização de CPU substituindo top n por bottom
n.
A capacidade de excluir outliers pode ser útil nos casos em que você quer definir um alerta, mas não quer que os outliers acionem o alerta constantemente. A consulta de alerta a seguir usa a mesma lógica de exclusão que a consulta anterior para monitorar a utilização do limite da CPU por um conjunto de pods do Kubernetes depois de excluir os dois principais:
fetch k8s_container
| metric 'kubernetes.io/container/cpu/limit_utilization'
| filter (resource.cluster_name == 'CLUSTER_NAME' &&
resource.namespace_name == 'NAMESPACE_NAME' &&
resource.pod_name =~ 'POD_NAME')
| group_by 1m, [value_limit_utilization_max: max(value.limit_utilization)]
| {
top 2 | value [is_default_value: false()]
;
ident
}
| outer_join true(), _
| filter is_default_value
| value drop [is_default_value]
| every 1m
| condition val(0) > 0.73 '1'
Selecionar a parte de cima ou de baixo nos grupos
As operações de tabela top e bottom selecionam séries temporais de toda a tabela de entrada. As operações top_by e bottom_by agrupam a série temporal em uma tabela e, em seguida, selecionam algumas séries temporais de cada grupo.
A consulta a seguir seleciona a série temporal em cada zona com o maior valor de pico:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top_by [zone], 1, max(val())
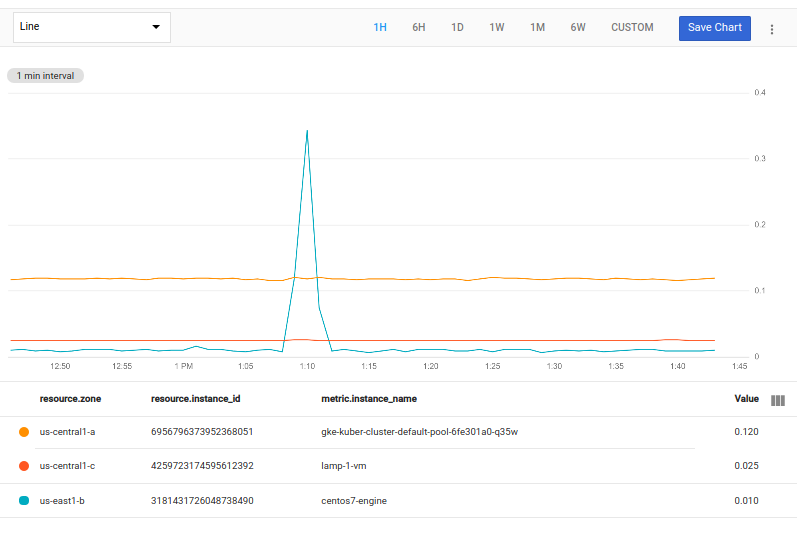
A expressão [zone] indica que um grupo consiste na série temporal com o mesmo valor da coluna zone.
O 1 no top_by indica quantas séries temporais devem ser selecionadas no grupo de cada zona. A expressão max(val()) procura o maior valor no intervalo de tempo do gráfico em cada série temporal.
Você pode usar qualquer função de agregação no lugar de max.
Por exemplo, o comando a seguir usa o agregador mean e within para especificar o intervalo de classificação de 20 minutos. Ele seleciona as duas principais séries temporais em cada zona:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top_by [zone], 2, mean(val()).within(20m)
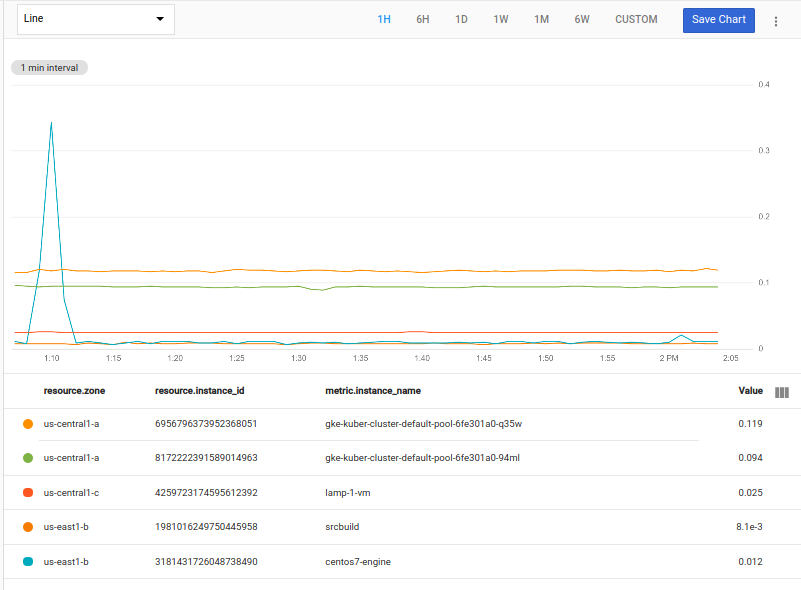
No exemplo anterior, há apenas uma instância na zona us-central-c,
então há apenas uma série temporal retornada; não há "top 2" no grupo.
Combinar seleções com union
Você pode combinar operações de seleção, como top e bottom, para criar gráficos que mostram ambos. Por exemplo, a consulta a seguir retorna a série temporal única com o valor máximo e a série temporal única com o valor mínimo:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| {
top 1, max(val())
;
bottom 1, min(val())
}
| union
O gráfico resultante mostra duas linhas, a que contém o maior valor e a que contém o menor:
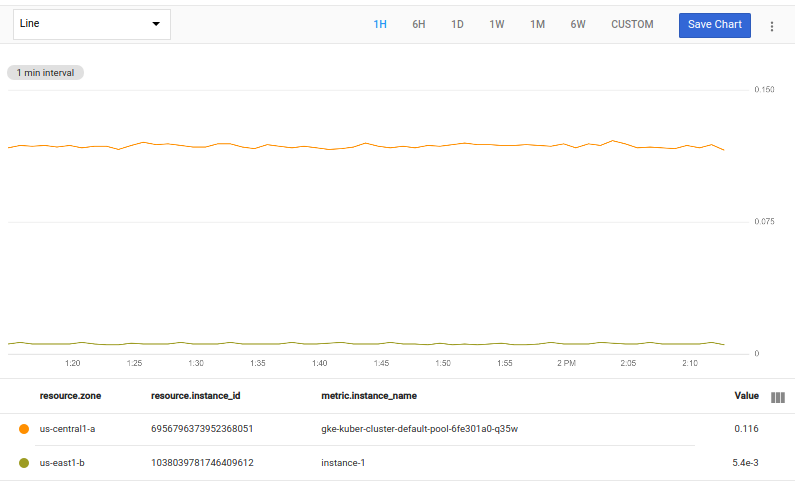
É possível usar chaves, { }, para especificar sequências de operações, cada uma produzindo uma tabela de séries temporais como saída. As operações individuais são separadas por ponto-e-vírgula, ;.
Nesse exemplo, a operação fetch retorna uma única tabela, que é canalizada para cada uma das duas operações na sequência, uma operação top e uma operação bottom. Cada uma dessas operações resulta em uma tabela de saída com base na mesma tabela de entrada. A operação union combina as duas tabelas em uma, que é exibida no gráfico.
Saiba mais sobre operações de sequenciamento usando { } no tópico de referência Estrutura de consulta.
Combinar série temporal com valores diferentes em um rótulo
Suponha que você tenha várias série temporal para o mesmo tipo de métrica e queira combinar algumas delas. Se você quiser selecioná-los com base nos valores de um único rótulo, não poderá criar a consulta usando a interface do criador de consultas no Metrics Explorer. É necessário filtrar dois ou mais valores diferentes do mesmo rótulo, mas a interface do criador de consultas exige que uma série temporal corresponda a todos os filtros a serem selecionados: a correspondência do rótulo é um teste AND. Nenhuma série temporal pode ter dois valores diferentes para o mesmo rótulo, mas não é possível criar um teste OR para filtros no Criador de consultas.
A consulta a seguir recupera a série temporal da métrica instance/disk/max_read_ops_count do Compute Engine para duas instâncias específicas do Compute Engine e alinha a saída em intervalos de um minuto:
fetch gce_instance
| metric 'compute.googleapis.com/instance/disk/max_read_ops_count'
| filter (resource.instance_id == '1854776029354445619' ||
resource.instance_id == '3124475757702255230')
| every 1m
O gráfico a seguir mostra o resultado dessa consulta:
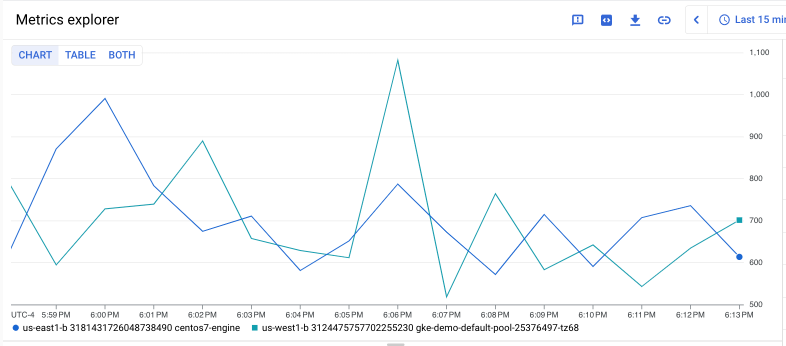
Se você quiser encontrar e somar os valores máximos de max_read_ops_count para essas duas VMs, faça o seguinte:
- Encontre o valor máximo de cada série temporal usando o operador de tabela
group_by, especificando o mesmo período de alinhamento de um minuto e agregando o período com o agregadormaxpara criar uma coluna chamadamax_val_of_read_ops_count_maxna tabela de saída. - Encontre a soma da série temporal usando o operador de tabela
group_bye o agregadorsumna colunamax_val_of_read_ops_count_max.
Veja a seguir a consulta:
fetch gce_instance
| metric 'compute.googleapis.com/instance/disk/max_read_ops_count'
| filter (resource.instance_id == '1854776029354445619' ||
resource.instance_id == '3124475757702255230')
| group_by 1m, [max_val_of_read_ops_count_max: max(value.max_read_ops_count)]
| every 1m
| group_by [], [summed_value: sum(max_val_of_read_ops_count_max)]
O gráfico a seguir mostra o resultado dessa consulta:
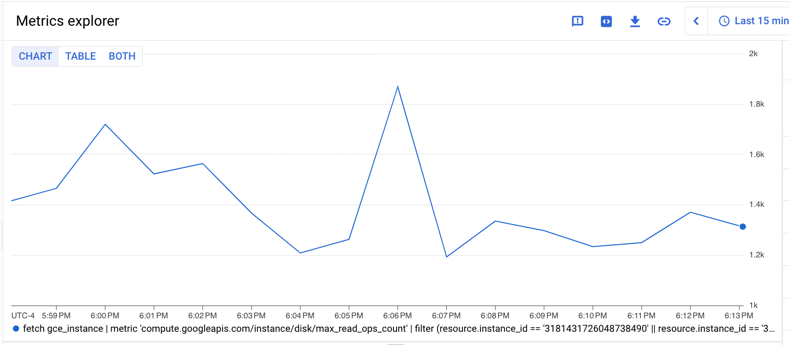
Calcule estatísticas de percentil ao longo do tempo e em vários streams
Para calcular um valor de stream de percentil em uma janela deslizante separadamente para cada
stream, use uma operação group_by temporal. Por exemplo, a consulta a seguir
calcula o valor do 99o percentil de um stream em uma janela deslizante
de uma hora:
fetch gce_instance :: compute.googleapis.com/instance/cpu/utilization | group_by 1h, percentile(val(), 99) | every 1m
Para calcular a mesma estatística de percentil em um determinado momento nos streams, e não no período de um stream, use uma operação espacial group_by:
fetch gce_instance :: compute.googleapis.com/instance/cpu/utilization | group_by [], percentile(val(), 99)
Proporções de computação
Suponha que você tenha criado um serviço da Web distribuído que seja executado em instâncias de VM do Compute Engine e use o Cloud Load Balancing.
Você quer ver um gráfico que exibe a proporção de solicitações que retornam respostas HTTP 500 (erros internos) para o número total de solicitações. Ou seja, a proporção de falha de solicitação. Esta seção ilustra várias maneiras de calcular a proporção de solicitações com falha.
O Cloud Load Balancing usa o tipo de recurso monitorado http_lb_rule.
O tipo de recurso monitorado http_lb_rule tem um rótulo matched_url_path_rule que registra o prefixo dos URLs definidos na regra. O valor padrão é UNMATCHED.
O tipo de métrica loadbalancing.googleapis.com/https/request_count tem um rótulo response_code_class. Esse rótulo captura a classe de códigos de resposta.
Usar outer_join e div
A consulta a seguir determina as respostas 500 de cada valor do rótulo matched_url_path_rule em cada recurso monitorado http_lb_rule no projeto. Em seguida, ele une essa tabela de contagem de falhas à tabela original, que contém todas as contagens de respostas e divide os valores para mostrar a proporção de respostas de falha para o total de respostas:
fetch https_lb_rule::loadbalancing.googleapis.com/https/request_count
| {
filter response_code_class = 500
;
ident
}
| group_by [matched_url_path_rule]
| outer_join 0
| div
O gráfico a seguir mostra o resultado de um projeto:
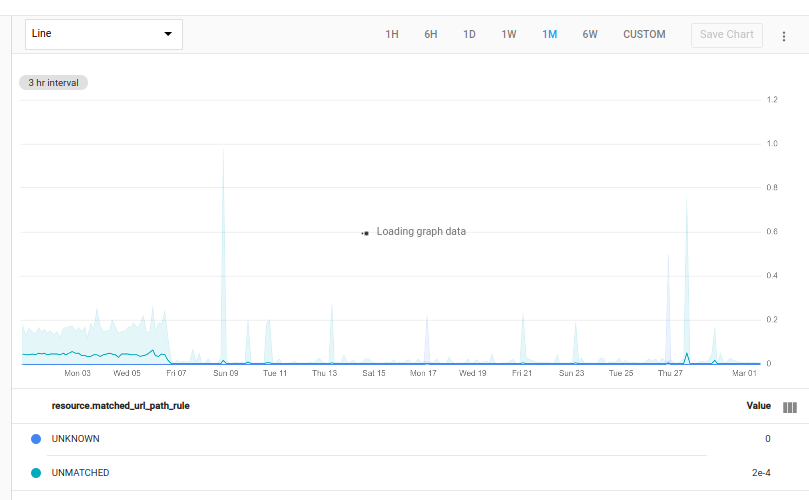
As áreas sombreadas em volta das linhas do gráfico são larguras de banda mínimas/máximas. Para mais informações, consulte Larguras de banda mínimas/máximas.
A operação fetch gera uma tabela de séries temporais contendo contagens de solicitações de todas as consultas com balanceamento de carga. Essa tabela é processada de duas maneiras pelas
duas sequências de operação nas chaves.
filter response_code_class = 500gera apenas a série temporal que tem o rótuloresponse_code_classcom o valor500. A série temporal resultante conta as solicitações com códigos de resposta HTTP 5xx (erro).Essa tabela é o numerador da proporção.
A operação
ident, ou identidade, gera a entrada. Portanto, essa operação retorna a tabela originalmente buscada. Essa é a tabela que contém série temporal com contagens para cada código de resposta.Essa tabela é o denominador da proporção.
As tabelas de numerador e denominador, produzidas pelas operações filter e ident, respectivamente, são processadas separadamente pela operação group_by.
A operação group_by agrupa a série temporal em cada tabela pelo valor do rótulo matched_url_path_rule e soma as contagens de cada valor do rótulo. Essa operação group_by não declara explicitamente a função de agregador. Portanto, um padrão, sum, é usado.
Para a tabela filtrada, o resultado
group_byé o número de solicitações que retornam uma resposta500para cada valormatched_url_path_rule.Para a tabela de identidade, o resultado
group_byé o número total de solicitações para cada valormatched_url_path_rule.
Essas tabelas são canalizadas para a operação outer_join, que combina séries temporais com valores de rótulo correspondentes, uma de cada uma das duas tabelas de entrada. As séries temporais pareadas são compactadas ao corresponder o carimbo de data/hora de cada ponto em uma série temporal com o carimbo de data/hora de um ponto em outra série temporal. Para cada par de pontos correspondentes, outer_join produz um único ponto de saída com dois valores, um de cada uma das tabelas de entrada.
A série temporal compactada é gerada pela junção com os mesmos rótulos das duas séries temporais de entrada.
Com uma junção externa, se um ponto da segunda tabela não tiver um
ponto correspondente na primeira, será necessário fornecer um valor substituto. Neste exemplo, um ponto com o valor 0, o argumento para a operação outer_join, é usado.
Por fim, a operação div usa cada ponto com dois valores e divide os
valores para produzir um único ponto de saída: a proporção de 500 respostas para todas
as respostas de cada mapa de URL.
A string div é o nome da função div, que divide dois valores numéricos. Mas é usada aqui como uma operação. Quando usadas como operações, funções como div esperam dois valores em cada ponto de entrada (o que join garante) e produzem um único valor para o ponto de saída correspondente.
A parte | div da consulta é um atalho para | value val(0) / val(1).
A operação value permite que expressões arbitrárias nas colunas de valor de uma tabela de entrada produzam as colunas de valor da tabela de saída.
Para mais informações, consulte as páginas de referência da operação value e de expressões.
Usar ratio
A função div pode ser substituída por qualquer função em dois valores, mas como as proporções são usadas com frequência, a MQL fornece uma operação de tabela ratio que calcula proporções diretamente.
A consulta a seguir é equivalente à versão anterior, usando outer_join e div:
fetch https_lb_rule::loadbalancing.googleapis.com/https/request_count
| {
filter response_code_class = 500
;
ident
}
| group_by [matched_url_path_rule]
| ratio
Nesta versão, a operação ratio substitui as operações outer_join 0 | div na versão anterior e produz o mesmo resultado.
Observe que ratio só usa outer_join para fornecer um 0 para o numerador se as entradas do numerador e do denominador tiverem os mesmos rótulos que identificam cada série temporal, o que é exigido pelo MQL outer_join. Se a entrada do numerador tiver rótulos extras, não haverá saída para nenhum ponto ausente no denominador.
Usar group_by e /
Há ainda outra maneira de calcular a proporção de respostas de erro para todas as respostas. Nesse caso, como o numerador e o denominador da proporção são derivados da mesma série temporal, você também pode calcular a proporção agrupando-a. A consulta a seguir mostra essa abordagem:
fetch https_lb_rule::loadbalancing.googleapis.com/https/request_count
| group_by [matched_url_path_rule],
sum(if(response_code_class = 500, val(), 0)) / sum(val())
Essa consulta usa uma expressão de agregação criada na proporção de duas somas:
O primeiro
sumusa a funçãoifpara contar rótulos com 500 valores e zero para outros. A funçãosumcalcula a contagem das solicitações que retornaram 500.O segundo
sumadiciona as contagens de todas as solicitações,val().
As duas somas são divididas, resultando na proporção de 500 respostas para todas as respostas. Essa consulta produz o mesmo resultado das consultas em Como usar outer_join e div e Como usar ratio.
Usar filter_ratio_by
Como as proporções são frequentemente calculadas dividindo duas somas derivadas da mesma tabela, a MQL fornece a operação filter_ratio_by para essa finalidade. A consulta a seguir faz o mesmo que a versão anterior, que divide explicitamente as somas:
fetch https_lb_rule::loadbalancing.googleapis.com/https/request_count
| filter_ratio_by [matched_url_path_rule], response_code_class = 500
O primeiro operando da operação filter_ratio_by, aqui
[matched_url_path_rule], indica como agrupar as respostas. A segunda operação, aqui response_code_class = 500, atua como uma expressão de filtro para o numerador.
- A tabela de denominadores é o resultado do agrupamento da tabela buscada por
matched_url_path_rulee agregada usandosum. - A tabela numeradora é a tabela buscada, filtrada para séries temporais com um código de resposta HTTP 5xx e, em seguida, agrupada por
matched_url_path_rulee agregada usandosum.
Proporção e métricas de cota
Para configurar consultas e alertas em métricas de cota
serviceruntime e métricas de cota específicas de recursos para monitorar
o consumo de cota, use o MQL. Para mais informações, incluindo exemplos, consulte Como usar métricas de cota.
Computação aritmética
Às vezes, você pode querer realizar uma operação aritmética nos dados antes de criar um gráfico com eles. Por exemplo, é possível dimensionar série temporal, converter os dados em escala de registro ou criar um gráfico da soma de duas série temporal. Para conferir uma lista de funções aritméticas disponíveis no MQL, consulte Aritmética.
Para escalonar uma série temporal, use a função mul. Por exemplo, a
consulta a seguir recupera a série temporal e multiplica cada valor
por 10:
fetch gce_instance
| metric 'compute.googleapis.com/instance/disk/read_bytes_count'
| mul(10)
Para somar duas série temporal, configure a consulta para buscar duas tabelas de série temporal, mescle esses resultados e chame a função add. Confira no exemplo a seguir uma consulta que calcula a soma do número de bytes lidos e gravados nas instâncias do Compute Engine:
fetch gce_instance
| { metric 'compute.googleapis.com/instance/disk/read_bytes_count'
; metric 'compute.googleapis.com/instance/disk/write_bytes_count' }
| outer_join 0
| add
Para subtrair a contagem de bytes gravados da contagem de bytes de leitura, substitua add
por sub na expressão anterior.
O MQL usa os rótulos nos conjuntos de tabelas retornados da primeira e da segunda busca para determinar como mesclar as tabelas:
Se a primeira tabela tiver um rótulo não encontrado na segunda, a MQL não poderá executar uma operação
outer_joinnas tabelas e, portanto, vai informar um erro. Por exemplo, a consulta a seguir causa um erro porque o rótulometric.throttle_reasonestá presente na primeira tabela, mas não na segunda:fetch gce_instance | { metric 'compute.googleapis.com/instance/disk/throttled_read_bytes_count' ; metric 'compute.googleapis.com/instance/disk/write_bytes_count' } | outer_join 0 | addUma maneira de resolver esse tipo de erro é aplicar cláusulas de agrupamento para garantir que as duas tabelas tenham os mesmos rótulos. Por exemplo, é possível agrupar todos os rótulos de série temporal:
fetch gce_instance | { metric 'compute.googleapis.com/instance/disk/throttled_read_bytes_count' | group_by [] ; metric 'compute.googleapis.com/instance/disk/write_bytes_count' | group_by [] } | outer_join 0 | addSe os rótulos das duas tabelas forem correspondentes ou se a segunda tabela contiver um rótulo não encontrado na primeira, a junção externa será permitida. Por exemplo, a consulta a seguir não causa um erro mesmo que o rótulo
metric.throttle_reasonesteja presente na segunda tabela, mas não na primeira:fetch gce_instance | { metric 'compute.googleapis.com/instance/disk/write_bytes_count' ; metric 'compute.googleapis.com/instance/disk/throttled_read_bytes_count' } | outer_join 0 | subUma série temporal encontrada na primeira tabela pode ter valores de rótulo que correspondem a várias séries temporais na segunda tabela. Portanto, o MQL realiza a operação de subtração para cada par.
Mudança de horário
Às vezes, você quer comparar o que está acontecendo agora com o que aconteceu no passado. Para permitir que você compare dados passados com dados atuais, o MQL fornece a operação de tabela time_shift para mover dados do passado para o período atual.
Proporções ao longo do tempo
A consulta a seguir usa time_shift, join e div para calcular a proporção da utilização média em cada zona entre agora e uma semana atrás.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| group_by [zone], mean(val())
| {
ident
;
time_shift 1w
}
| join | div
O gráfico a seguir mostra um possível resultado dessa consulta:
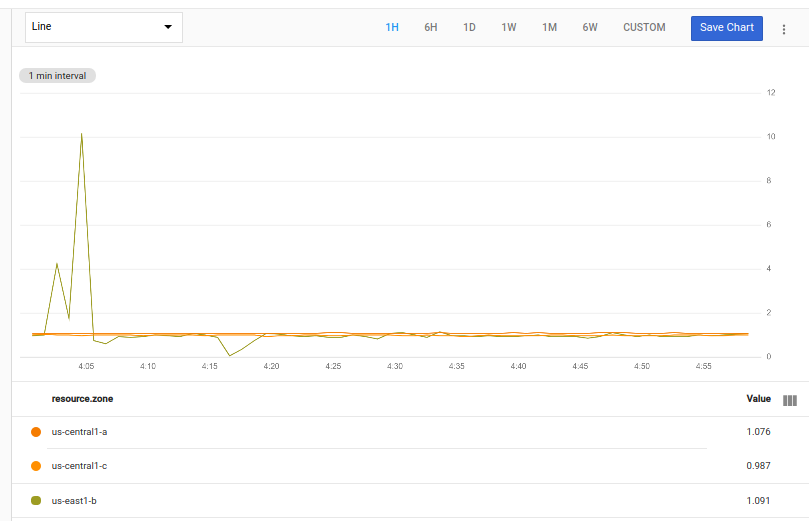
As duas primeiras operações buscam as série temporal e, em seguida, as agrupam por zona, calculando os valores médios de cada uma. A tabela resultante é então transmitida para duas operações. A primeira operação, ident, transmite a tabela inalterada.
A segunda operação, time_shift, adiciona o período (1 semana) aos carimbos de data/hora dos valores na tabela, o que muda os dados de uma semana atrás. Essa alteração faz com que os carimbos de data/hora dos dados mais antigos na segunda tabela se alinhem aos dos dados atuais na primeira.
A tabela inalterada e a tabela com alteração de horário são combinadas usando um join interno. O join produz uma tabela de séries temporais em que cada ponto tem dois valores: a utilização atual e a utilização de uma semana atrás.
A consulta usa a operação div para calcular a proporção do valor atual para o valor da semana.
Dados anteriores e atuais
Ao combinar time_shift com union, você pode criar um gráfico que mostra dados passados e presentes simultaneamente. Por exemplo, a consulta a seguir retorna a utilização média geral de agora e de uma semana atrás. Usando union, você pode exibir esses dois resultados no mesmo gráfico.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| group_by []
| {
add [when: "now"]
;
add [when: "then"] | time_shift 1w
}
| union
O gráfico a seguir mostra um possível resultado dessa consulta:
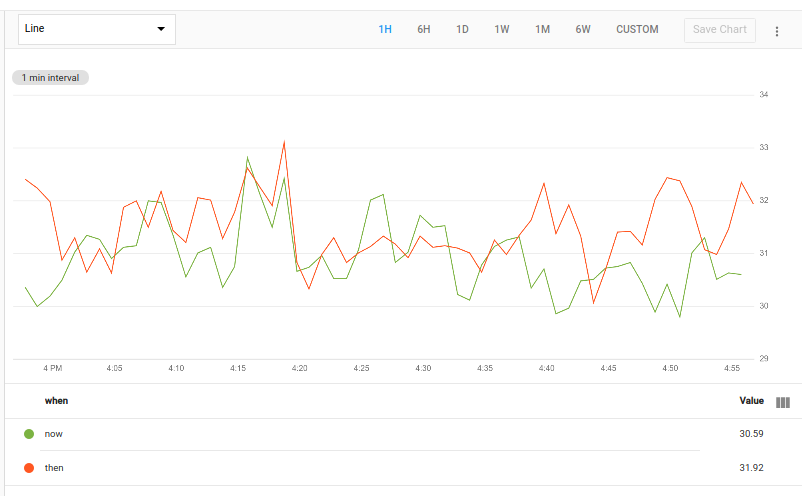
Essa consulta busca a série temporal e usa group_by []
para combiná-las em uma única série temporal sem rótulos, deixando os
pontos de dados de uso da CPU. Esse resultado é transmitido para duas operações.
O primeiro adiciona uma coluna para um novo rótulo chamado when com o valor now.
O segundo adiciona um rótulo chamado when com o valor then e transmite o resultado para a operação time_shift para mudar os valores em uma semana. Essa consulta usa o modificador de mapa add. Consulte Mapas para obter mais informações.
As duas tabelas, cada uma contendo dados para uma única série temporal, são transmitidas para union, que produz uma tabela contendo as séries temporais das duas tabelas de entrada.
A seguir
Para uma visão geral das estruturas da linguagem MQL, consulte Sobre a linguagem MQL.
Para uma descrição completa da MQL, consulte a Referência da linguagem de consulta do Monitoring.
Para mais informações sobre como interagir com gráficos, consulte Como trabalhar com gráficos.