Cette page explique comment afficher les métriques d'état de l'infrastructure pour vos clusters et charges de travail Google Kubernetes Engine (GKE). Ces métriques peuvent vous aider à résoudre les problèmes liés à vos clusters et charges de travail GKE.
Conditions requises
- Vous devez activer les métriques système sur votre cluster pour utiliser les métriques de présentation dans l'onglet Observabilité. Les métriques système sont toujours activées dans les clusters Autopilot et sont activées par défaut dans les clusters Standard.
- Les métriques du plan de contrôle doivent être activées sur votre cluster pour que vous puissiez utiliser les métriques du plan de contrôle dans l'onglet Observabilité. Si vous sélectionnez Plan de contrôle dans l'onglet Observabilité pour votre cluster et que les métriques ne sont pas activées, vous verrez une notification indiquant que les métriques ne sont pas activées. Vous pouvez les activer en cliquant sur Activer le package. Pour en savoir plus sur les autres façons d'activer les métriques du plan de contrôle, consultez la page Configurer la collecte de métriques du plan de contrôle.
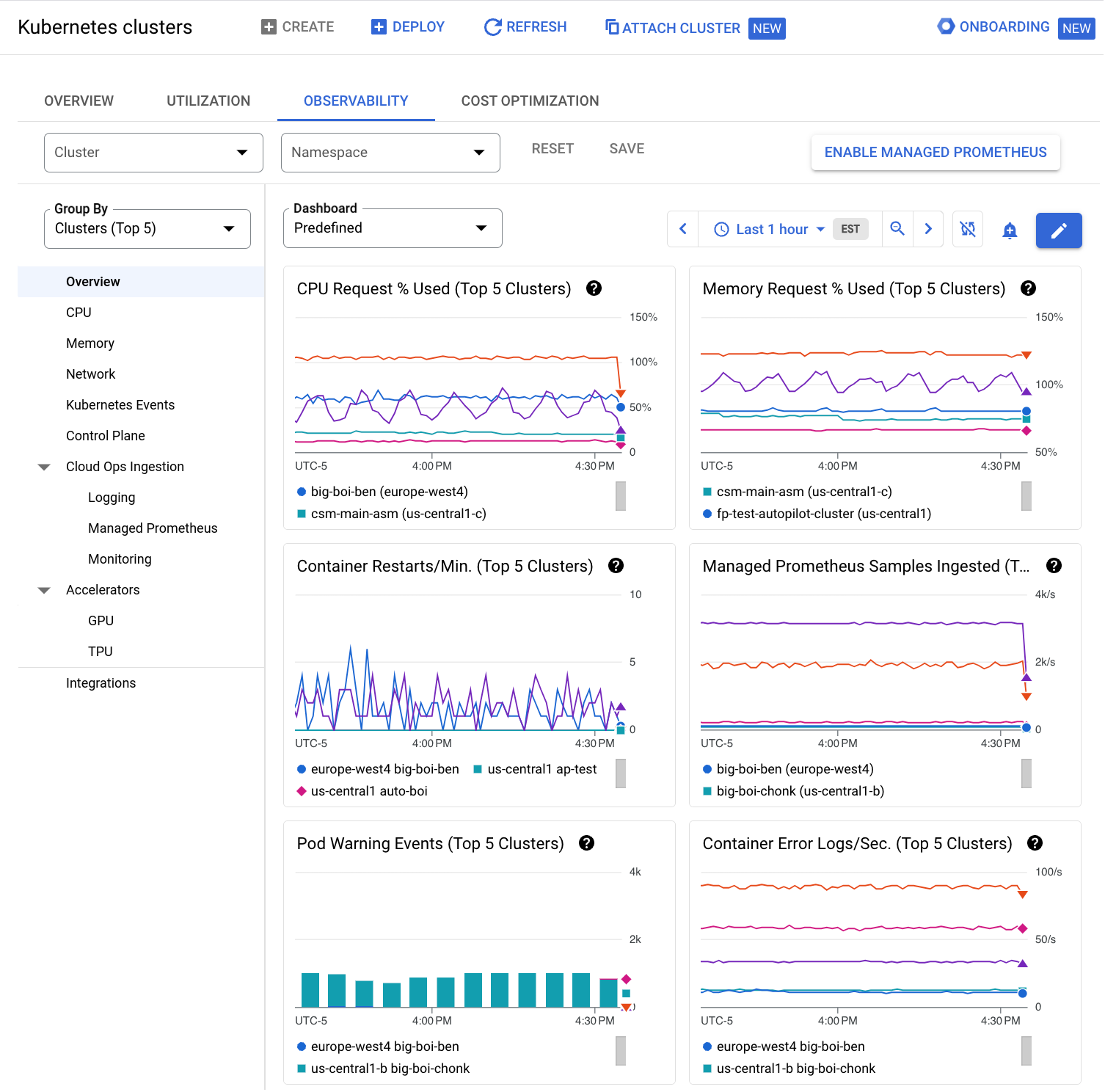
Métriques d'observabilité
L'onglet Observabilité de la console Google Cloud vous permet d'afficher les métriques de performances des clusters et des charges de travail.
Pour l'édition Google Kubernetes Engine (GKE) Enterprise, les graphiques affichent tous les clusters d'un parc.
Métriques pour les clusters et les charges de travail
Les métriques suivantes sont disponibles pour les clusters et les charges de travail :
- Présentation : affiche les métriques d'état récapitulatives de l'infrastructure, telles que l'utilisation des requêtes de processeur et de mémoire, les journaux d'erreurs et les événements d'avertissement.
- Processeur : affiche l'utilisation du processeur et des requêtes principales.
- Mémoire : affiche l'utilisation des requêtes de mémoire.
Les métriques suivantes sont disponibles pour les clusters :
- Événements Kubernetes : fournit une visibilité sur le nombre d'événements au fil du temps et un journal détaillé des événements.
- Plan de contrôle : fournit une visibilité sur l'état des composants du plan de contrôle Kubernetes tels que kube-apiserver et le programmeur. Fournit également des informations telles que le nombre de pods non programmables. Des pods à l'état non programmable ont fait l'objet d'une tentative de planification et ont été identifiés comme non programmables. Cet état des pods indique que le cluster n'a subi aucune modification susceptible de rendre ces pods programmables.
- Ingestion d'opérations Cloud : fournit une visibilité sur la quantité d'ingestion de journaux et de métriques corrélée aux coûts. Pour en savoir plus, consultez les tarifs de la suite Google Cloud Operations.
- Éphémère : (disponible dans l'onglet Observabilité d'un cluster choisi) : fournit une visibilité sur le stockage éphémère utilisé par un cluster afin que vous puissiez déterminer si l'espace de stockage du cluster est utilisé efficacement. Dans l'onglet Observabilité de la page Présentation, un graphique montre le stockage éphémère utilisé par le cluster, et la page Éphémère affiche des métriques supplémentaires, y compris la capacité, le débit, le taux d'opérations d'E/S, etc. Certaines de ces métriques ne sont pas disponibles pour les clusters Autopilot.
- Persistant : fournit une visibilité sur les volumes persistants et les demandes de volume persistant.
- État des charges de travail : fournit une visibilité sur les types de ressources Pod, Deployment, StatefulSet, DaemonSet et Autoscaler horizontal de pods.
Interpréter les métriques d'observabilité
Les métriques peuvent vous aider à résoudre les problèmes liés à vos clusters GKE. Par exemple :
- Des tendances d'utilisation élevée des ressources mémoire ou de processeur peuvent indiquer que vous devez configurer des conteneurs dans un cluster ou un espace de noms pour utiliser moins de ressources.
- Un nombre élevé de redémarrages peut indiquer que les conteneurs plantent.
- Un nombre élevé de pods non programmables indique des ressources insuffisantes ou des erreurs de configuration.
- Une ingestion élevée de Cloud Logging ou du service géré Google Cloud pour Prometheus est en corrélation avec le coût de la suite Google Cloud Operations. Vous devriez pouvoir réduire les coûts en réduisant l'ingestion Pour en savoir plus sur Google Cloud Managed Service pour Prometheus, consultez la page Contrôle et attribution des coûts. Pour en savoir plus sur la journalisation, consultez la section Filtres d'exclusion.
Afficher les métriques d'observabilité des clusters et des charges de travail
Pour afficher les métriques d'observabilité pour vos clusters ou vos charges de travail, procédez comme suit dans la console Google Cloud :
Accédez à la page Clusters Kubernetes ou Charges de travail Kubernetes :
Sélectionnez l'onglet Observabilité.
Choisissez la période sur laquelle les métriques sont agrégées. Faites glisser un élément du graphique pour cibler une période spécifique. Cliquez sur Reset Zoom (Réinitialiser le zoom) pour revenir à la plage sélectionnée précédemment.
Pour afficher les métriques d'observabilité pour un cluster ou une charge de travail spécifiques, procédez comme suit dans la console Google Cloud :
Accédez à la page Clusters Kubernetes ou Charges de travail Kubernetes :
Cliquez sur le nom d'un cluster ou d'une charge de travail.
Sélectionnez l'onglet Observabilité.
Choisissez la période sur laquelle les métriques sont agrégées. Faites glisser un élément du graphique pour cibler une période spécifique. Cliquez sur Reset Zoom (Réinitialiser le zoom) pour revenir à la plage sélectionnée précédemment.
Créer un tableau de bord personnalisé à partir d'une vue sélectionnée
Pour ajouter les graphiques visibles à un tableau de bord personnalisable dans Cloud Monitoring, procédez comme suit dans la console Google Cloud :
Accédez à la page Clusters Kubernetes ou Charges de travail Kubernetes :
Sélectionnez l'onglet Observabilité.
Si vous le souhaitez, sélectionnez des filtres pour les données.
Cliquez sur Enregistrer en tant que tableau de bord personnalisé.
Spécifiez un nom pour le nouveau tableau de bord.
Cliquez sur Envoyer pour créer un tableau de bord.
Cliquez sur Afficher dans Monitoring pour afficher le tableau de bord.
Afficher les tableaux de bord GKE dans Cloud Monitoring
Monitoring fournit des tableaux de bord supplémentaires pour GKE et d'autres services Google Cloud. Vous pouvez utiliser les tableaux de bord fournis ou créer une copie d'un tableau de bord afin de le personnaliser en fonction de vos besoins.
La liste des tableaux de bord inclut également des playbooks GKE que vous pouvez utiliser pour vous aider à résoudre les problèmes courants.
-
Dans la console Google Cloud, sélectionnez Monitoring puis
 Tableaux de bord, ou cliquez sur le bouton suivant :
Tableaux de bord, ou cliquez sur le bouton suivant :
Dans la liste "Catégories", sélectionnez G C P.
Sélectionnez le tableau de bord ou le playbook que vous souhaitez afficher.
- Le tableau de bord GKE fournit un aperçu de vos clusters, charges de travail, services et autres ressources que vous pouvez filtrer. Vous pouvez cliquer sur une ressource pour afficher les détails des métriques et des journaux. Pour les espaces de noms, les charges de travail et les services Kubernetes, vous pouvez également afficher et créer des objectifs de niveau de service (SLO) à partir de la vue détaillée.
- Les autres tableaux de bord et playbooks GKE se concentrent sur des ressources ou des conditions spécifiques, telles que les charges de travail à risque.