En este instructivo, se explica el método recomendado para crear una configuración de Looker agrupada.
Descripción general
La aplicación de Looker puede ejecutarse en un solo nodo o agrupado en clústeres:
- Una aplicación de Looker de un solo nodo, la configuración predeterminada, tiene todos los servicios que conforman la aplicación de Looker ejecutándose en un solo servidor.
- Una configuración de Looker agrupada en clústeres es una configuración más compleja, que generalmente involucra servidores de bases de datos, balanceadores de cargas y varios servidores que ejecutan la aplicación de Looker. Cada nodo en una aplicación agrupada en clústeres de Looker es un servidor que ejecuta una sola instancia de Looker.
Hay dos motivos principales por los que una organización podría querer ejecutar Looker como un clúster:
- Balanceo de cargas
- Disponibilidad y conmutación por error mejoradas
Según los problemas de escalamiento, es posible que un Looker agrupado en clústeres no proporcione la solución. Por ejemplo, si una pequeña cantidad de consultas grandes consumen la memoria del sistema, la única solución es aumentar la memoria disponible para el proceso de Looker.
Alternativas de balanceo de cargas
Antes de realizar el balanceo de cargas de Looker, considera aumentar la memoria y, posiblemente, el recuento de CPU de un solo servidor que ejecuta Looker. Looker recomienda configurar una supervisión de rendimiento detallada para el uso de memoria y CPU a fin de asegurarse de que el servidor de Looker tenga el tamaño adecuado para su carga de trabajo.
Las consultas grandes necesitan más memoria para obtener un mejor rendimiento. El agrupamiento en clústeres puede proporcionar mejoras en el rendimiento cuando muchos usuarios ejecutan consultas pequeñas.
Para configuraciones con un máximo de 50 usuarios que usan Looker ligeramente, Looker recomienda ejecutar un solo servidor al equivalente de una instancia de AWS EC2 de gran tamaño (M4.large: 8 GB de RAM, 2 núcleos de CPU). Para configuraciones con más usuarios o muchos usuarios activos, observa si la CPU aumenta o si los usuarios notan lentitud en la aplicación. Si es así, mueve Looker a un servidor más grande o ejecuta una configuración de Looker agrupada.
Disponibilidad/conmutación por error mejorada
Ejecutar Looker en un entorno agrupado puede mitigar el tiempo de inactividad en caso de una interrupción. La alta disponibilidad es especialmente importante si la API de Looker se usa en los sistemas comerciales principales o si Looker está incorporado en productos para los clientes.
En una configuración de Looker agrupada en clústeres, un servidor proxy o balanceador de cargas redireccionará el tráfico cuando determine que un nodo está inactivo. Looker controla automáticamente los nodos que salen del clúster y se unen a él.
Componentes obligatorios
Los siguientes componentes son necesarios para una configuración agrupada en Looker:
- Base de datos de aplicaciones de MySQL
- Nodos de Looker (servidores que ejecutan el proceso de Looker para Java)
- Balanceador de cargas
- Sistema de archivos compartido
- Versión correcta de los archivos JAR de la aplicación de Looker
En el siguiente diagrama, se ilustra cómo interactúan los componentes. En términos generales, un balanceador de cargas distribuye el tráfico de red entre nodos de Looker agrupados en clústeres. Los nodos se comunican con una base de datos de aplicaciones de MySQL compartida, un directorio de almacenamiento compartido y los servidores de Git para cada proyecto de LookML.
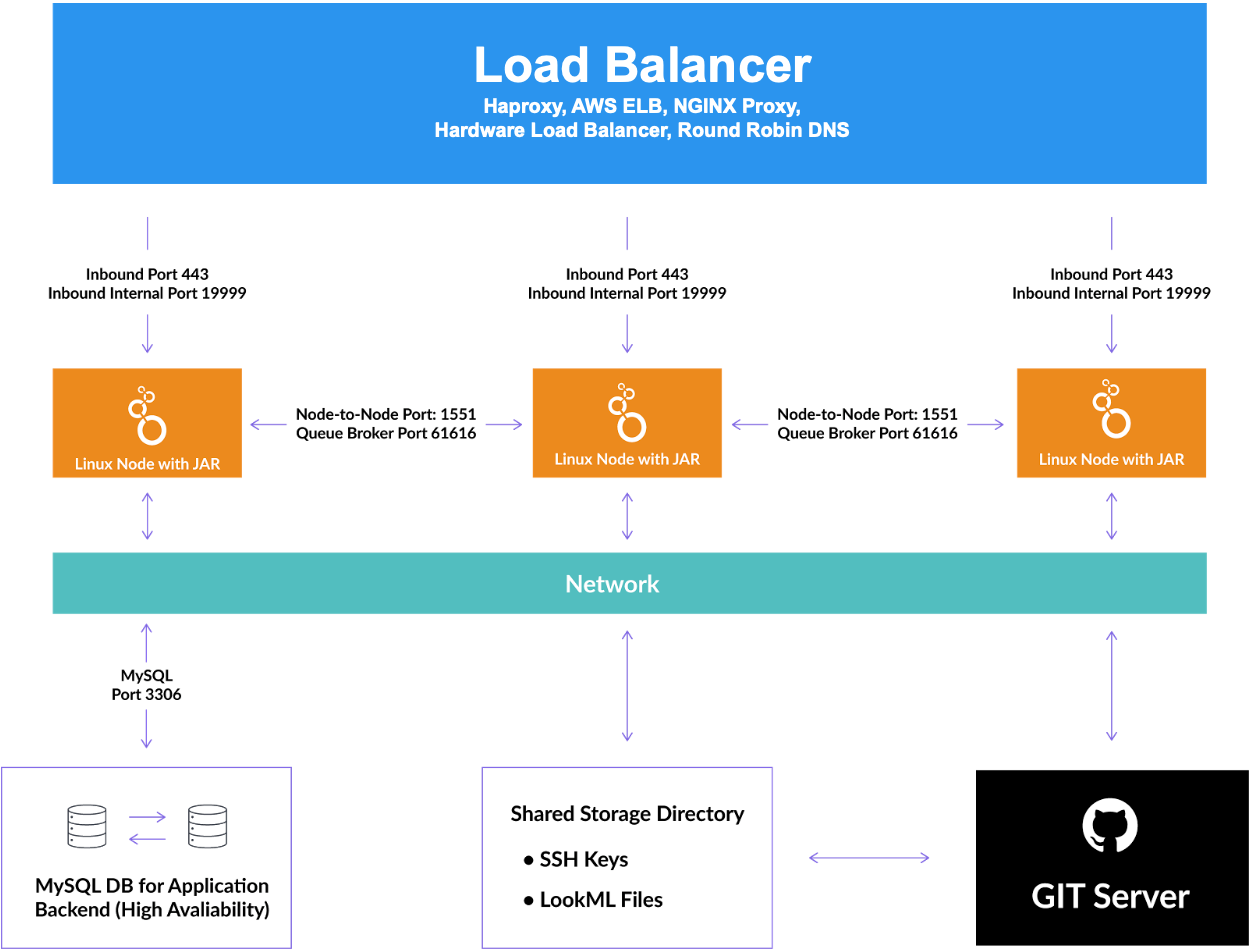
Base de datos de aplicaciones de MySQL
Looker usa una base de datos de aplicaciones (a menudo llamada base de datos interna) para almacenar datos de aplicaciones. Cuando Looker se ejecuta como una aplicación de un solo nodo, suele usar una base de datos de HyperSQL en la memoria.
En una configuración de Looker agrupada en clústeres, la instancia de Looker de cada nodo debe apuntar a una base de datos transaccional compartida (la aplicación compartida o base de datos interna). La asistencia para la base de datos de aplicaciones para Looker agrupados en clústeres es la siguiente:
- Solo MySQL es compatible con la base de datos de aplicaciones para instancias de Looker agrupadas en clústeres. No se admiten Amazon Aurora ni MariaDB.
- Se admiten las versiones 5.7 y 8.0 o posteriores de MySQL.
- No se admiten bases de datos agrupadas como Galera.
Looker no administra el mantenimiento ni las copias de seguridad de esa base de datos. Sin embargo, dado que la base de datos aloja casi todos los datos de configuración de la aplicación de Looker, debe aprovisionarse como una base de datos de alta disponibilidad y crear una copia de seguridad al menos una vez al día.
Nodos de Looker
Cada nodo es un servidor en el que se ejecuta el proceso de Java de Looker. Los servidores del clúster de Looker deben poder comunicarse entre sí y con la base de datos de aplicaciones de Looker. Los puertos predeterminados se enumeran en Abrir los puertos para que los nodos se comuniquen en esta página.
Balanceador de cargas
Para balancear la carga o redireccionar solicitudes a los nodos disponibles, se requiere un balanceador de cargas o servidor proxy (por ejemplo, NGINX o AWS ELB) a fin de dirigir el tráfico a cada nodo de Looker. El balanceador de cargas controla las verificaciones de estado. En caso de que se produzca una falla en el nodo, el balanceador de cargas debe configurarse para redirigir el tráfico a los nodos restantes en buen estado.
Cuando elija y configure el balanceador de cargas, asegúrese de que pueda configurarse para funcionar solo como capa 4. El Amazon Classic ELB es uno de esos ejemplos. Además, el balanceador de cargas debe tener un tiempo de espera prolongado (3,600 segundos) para evitar que se cierren las consultas.
Sistema de archivos compartido
Debes usar un sistema de archivos compartidos que cumpla con POSIX (como NFS, AWS EFS, Gluster, BeeGFS, Lustre y muchos otros). Looker usa el sistema de archivos compartidos como repositorio para varios datos que usan todos los nodos del clúster.
Aplicación de Looker (JAR ejecutable)
Debes usar un archivo JAR de aplicación de Looker que sea Looker 3.56 o una versión posterior.
Looker recomienda que cada nodo de un clúster ejecute la misma versión de parche y la misma versión de Looker, como se explica en Iniciar Looker en los nodos de esta página.
Configura el clúster
Se requieren las siguientes tareas:
- Instala Looker
- Configura una base de datos de aplicaciones de MySQL
- Configura el sistema de archivos compartidos
- Comparte el repositorio de claves SSH (según tu situación).
- Abrir los puertos para que se comuniquen los nodos
- Iniciar Looker en los nodos
Cómo instalar Looker
Asegúrese de tener instalado Looker en cada nodo con los archivos JAR de la aplicación de Looker y las instrucciones de la página de documentación de pasos de instalación alojados por el cliente.
Cómo configurar una base de datos de aplicaciones de MySQL
Para una configuración de Looker agrupada, la base de datos de la aplicación debe ser de MySQL. Si ya tiene una instancia de Looker sin clústeres que usa HyperSQL para la base de datos de la aplicación, debe migrar los datos de la aplicación desde los datos de HyperSQL hacia la nueva base de datos de MySQL compartida.
Consulta la página de documentación sobre cómo migrar a MySQL para obtener información sobre cómo crear una copia de seguridad de Looker y, luego, migrar la base de datos de la aplicación de HyperSQL a MySQL.
Cómo configurar el sistema de archivos compartidos
Solo los tipos de archivo específicos (archivos de modelo, claves de implementación, complementos y, potencialmente, archivos de manifiesto de la aplicación) pertenecen al sistema de archivos compartidos. Para configurar el sistema de archivos compartidos, haz lo siguiente:
- En el servidor que almacenará el sistema de archivos compartidos, verifica que tengas acceso a otra cuenta que pueda usar
supara la cuenta de usuario de Looker. - En el servidor del sistema de archivos compartidos, accede a la cuenta de usuario de Looker.
- Si Looker se está ejecutando, cierra la configuración de este.
- Si antes agrupabas clústeres con iscript de Linux, detén las secuencias, quítalas de cron y bórralas.
- Cree un recurso compartido de red y actívelo en cada nodo del clúster. Asegúrate de que esté configurado para activarse automáticamente en cada nodo y de que el usuario de Looker tenga la capacidad de leerlo y escribirlo. En el siguiente ejemplo, el recurso compartido de red se llama
/mnt/looker-share. En un nodo, copia tus claves de implementación y mueve tus complementos y los directorios
looker/modelsylooker/models-user-*, que almacenan tus archivos del modelo, a tu red compartida. Por ejemplo:mv looker/models /mnt/looker-share/ mv looker/models-user-* /mnt/looker-share/Para cada nodo, agrega el parámetro de configuración
--shared-storage-diraLOOKERARGS. Especifica el recurso compartido de red, como se muestra en este ejemplo:--shared-storage-dir /mnt/looker-shareSe debe agregar
LOOKERARGSa$HOME/looker/lookerstart.cfgpara que la configuración no se vea afectada por las actualizaciones. Si tus archivosLOOKERARGSno aparecen en ese archivo, es posible que alguien los haya agregado directamente a la secuencia de comandos de shell$HOME/looker/looker.Cada nodo del clúster debe escribir en un directorio
/logúnico o en un archivo de registro único.
Comparte el repositorio de claves SSH
- Estás creando un clúster de sistema de archivos compartido a partir de una configuración existente de Looker.
- Tienes proyectos creados en Looker 4.6 o versiones anteriores.
Configura el repositorio de claves SSH que se compartirá:
En el servidor de archivos compartidos, crea un directorio llamado
ssh-share. Por ejemplo:/mnt/looker-share/ssh-share.Asegúrate de que el directorio
ssh-sharesea propiedad del usuario de Looker y de que los permisos sean 700. Además, asegúrate de que los directorios que están por encima del directoriossh-share(como/mnty/mnt/looker-share) no puedan escribirse en todo el mundo ni escribir en grupos.En un nodo, copia el contenido de
$HOME/.sshen el nuevo directorio dessh-share. Por ejemplo:cp $HOME/.ssh/* /mnt/looker-share/ssh-sharePara cada nodo, haz una copia de seguridad del archivo SSH existente y crea un symlink al directorio
ssh-share. Por ejemplo:cd $HOME mv .ssh .ssh_bak ln -s /mnt/looker-share/ssh-share .sshAsegúrese de realizar este paso para cada nodo.
Abrir los puertos para que se comuniquen los nodos
Los nodos de Looker agrupados en clústeres se comunican entre sí a través de HTTPS con certificados autofirmados y un esquema de autenticación adicional basado en secretos rotativos en la base de datos de aplicaciones.
Los puertos predeterminados que deben estar abiertos entre los nodos del clúster son 1551 y 61616. Estos puertos se pueden configurar mediante las marcas de inicio que se indican aquí. Recomendamos restringir el acceso de red a estos puertos para permitir el tráfico solo entre los hosts del clúster.
Inicia Looker en los nodos
Reinicia el servidor en cada nodo con las marcas de inicio necesarias.
Marcas de inicio disponibles
En la siguiente tabla, se muestran las marcas de inicio disponibles, incluidas las marcas necesarias para iniciar o unirse a un clúster:
| Flag | ¿Es obligatorio? | Valores | Purpose |
|---|---|---|---|
--clustered |
Sí | Agrega una marca para especificar que este nodo se ejecuta en modo agrupado. | |
-H o --hostname |
Sí | 10.10.10.10 |
El nombre de host que usan otros nodos para comunicarse con este nodo, como la dirección IP o el nombre de host del sistema. Debe ser diferente de los nombres de host de todos los demás nodos del clúster. |
-n |
No | 1551 |
El puerto para la comunicación entre nodos. El valor predeterminado es 1551. Todos los nodos deben usar el mismo número de puerto para la comunicación entre nodos. |
-q |
No | 61616 |
El puerto para poner en cola eventos de todo el clúster. El valor predeterminado es 61616. |
-d |
Sí | /path/to/looker-db.yml |
La ruta del archivo que contiene las credenciales de la base de datos de la aplicación de Looker. |
--shared-storage-dir |
Sí | /path/to/mounted/shared/storage |
La opción debe apuntar a la configuración del directorio compartido anterior en esta página que contiene los directorios looker/model y looker/models-user-*. |
Ejemplo de LOOKERARGS y especificación de las credenciales de la base de datos
Coloca las marcas de inicio de Looker en un archivo lookerstart.cfg, ubicado en el mismo directorio que los archivos JAR de Looker.
Por ejemplo, es posible que quieras indicarle a Looker lo siguiente:
- Si quieres usar el archivo llamado
looker-db.ymlpara las credenciales de tu base de datos, haz lo siguiente: - de que es un nodo agrupado
- que los otros nodos del clúster deben comunicarse con este host en la dirección IP 10.10.10.10.
Especificaría lo siguiente:
LOOKERARGS="-d looker-db.yml --clustered -H 10.10.10.10"
El archivo looker-db.yml contendrá las credenciales de la base de datos, como se muestra a continuación:
host: your.db.hostname.com
username: db_user
database: looker
dialect: mysql
port: 3306
password: secretPassword
Si tu base de datos MySQL requiere una conexión SSL, el archivo looker-db.yml también requiere lo siguiente:
ssl: true
Si no quieres almacenar la configuración en el archivo looker-db.yml del disco, puedes configurar la variable de entorno LOOKER_DB para que contenga una lista de claves/valores para cada línea en el archivo looker-db.yml. Por ejemplo:
export LOOKER_DB="dialect=mysql&host=localhost&username=root&password=&database=looker&port=3306"
Encuentra tus claves de implementación SSH de Git
La ubicación en la que Looker almacena las claves de implementación SSH de Git depende de la versión en la que se creó el proyecto:
- Para los proyectos creados antes de Looker 4.8, las claves de implementación se almacenan en el directorio nativo de SSH del servidor,
~/.ssh. - Para los proyectos creados en Looker 4.8 o versiones posteriores, las claves de implementación se almacenan en un directorio controlado por Looker,
~/looker/deploy_keys/PROJECT_NAME.
Modifica un clúster de Looker
Después de crear un clúster de Looker, puedes agregar o quitar nodos sin realizar cambios en los otros nodos agrupados.
Actualiza un clúster a una nueva versión de Looker
Las actualizaciones pueden implicar cambios de esquema en la base de datos interna de Looker que no serían compatibles con las versiones anteriores de Looker. Existen dos métodos para actualizar Looker.
Método más seguro
- Crear una copia de seguridad de la base de datos de la aplicación
- Detén todos los nodos del clúster.
- Reemplaza los archivos JAR de cada servidor.
- Inicia un nodo a la vez.
Método más rápido
Para actualizar con este método más rápido, pero menos completo, haz lo siguiente:
- Crear una réplica de la base de datos de aplicaciones de Looker
- Iniciar un clúster nuevo que apunta a la réplica
- Apuntar el servidor proxy o el balanceador de cargas a los nodos nuevos, después de lo cual puede detener los nodos antiguos