In dieser Anleitung wird die empfohlene Methode zum Erstellen einer Cluster-Looker-Konfiguration erläutert.
Überblick
Die Looker-Anwendung kann einen einzelnen Knoten oder einen Cluster ausführen:
- Eine Looker-Anwendung mit einem einzelnen Knoten (die Standardkonfiguration) hat alle Dienste, aus denen die Looker-Anwendung besteht, auf einem einzigen Server ausgeführt.
- Eine geclusterte Looker-Konfiguration ist eine komplexere Konfiguration, die in der Regel Datenbankserver, Load-Balancer und mehrere Server umfasst, auf denen die Looker-Anwendung ausgeführt wird. Jeder Knoten in einer geclusterten Looker-Anwendung ist ein Server, auf dem eine einzelne Looker-Instanz ausgeführt wird.
Es gibt zwei Hauptgründe, warum eine Organisation Looker als Cluster ausführen möchte:
- Load-Balancing
- Verbesserte Verfügbarkeit und Failover
Je nach Skalierungsfehlern kann ein geclusterter Looker die Lösung möglicherweise nicht bereitstellen. Wenn beispielsweise eine kleine Anzahl großer Abfragen den Systemspeicher belegt, besteht die einzige Lösung darin, den verfügbaren Arbeitsspeicher für den Looker-Prozess zu erhöhen.
Load-Balancing-Alternativen
Prüfen Sie vor dem Load-Balancing von Looker die Speicherkapazität und möglicherweise die CPU-Anzahl eines einzelnen Servers, der Looker ausführt. Looker empfiehlt, ein detailliertes Leistungsmonitoring für die Arbeitsspeicher- und CPU-Auslastung einzurichten, damit der Looker-Server die richtige Größe für die Arbeitslast hat.
Große Abfragen benötigen mehr Arbeitsspeicher für eine bessere Leistung. Das Clustering kann die Leistung steigern, wenn viele Nutzer kleine Abfragen ausführen.
Bei Konfigurationen mit bis zu 50 Nutzern, die Looker leicht verwenden, empfiehlt Looker, einen einzigen Server mit einer großen AWS EC2-Instanz (M4.large: 8 GB RAM, 2 CPU-Kerne) auszuführen. Achten Sie bei Konfigurationen mit mehr Nutzern oder vielen aktiven Powerusern darauf, ob die CPU stark ansteigt oder ob Nutzer Verzögerungen in der Anwendung feststellen. Ist das der Fall, verschieben Sie Looker auf einen größeren Server oder führen Sie eine Cluster-Looker-Konfiguration aus.
Verbesserte Verfügbarkeit/Failover
Wenn Sie Looker in einer Clusterumgebung ausführen, kann die Ausfallzeit bei einem Ausfall minimiert werden. Hochverfügbarkeit ist besonders wichtig, wenn die Looker API in Kerngeschäftssystemen verwendet wird oder wenn Looker in kundenorientierte Produkte eingebettet ist.
In einer geclusterten Looker-Konfiguration wird ein Traffic von einem Proxyserver oder Load-Balancer umgeleitet, wenn er erkennt, dass ein Knoten ausgefallen ist. Looker verwaltet automatisch Knoten, die den Cluster verlassen und ihm beitreten.
Erforderliche Komponenten
Für eine Cluster-Looker-Konfiguration sind die folgenden Komponenten erforderlich:
- MySQL-Anwendungsdatenbank
- Looker-Knoten (Server, auf denen der Looker Java-Prozess ausgeführt wird)
- Load-Balancer
- Freigegebenes Dateisystem
- Richtige Version der JAR-Dateien der Looker-Anwendung
Das folgende Diagramm veranschaulicht, wie die Komponenten interagieren. Auf übergeordneter Ebene verteilt ein Load-Balancer den Netzwerk-Traffic auf geclusterte Looker-Knoten. Die Knoten kommunizieren jeweils mit einer freigegebenen MySQL-Anwendungsdatenbank, einem freigegebenen Speicherverzeichnis und den Git-Servern für jedes LookML-Projekt.
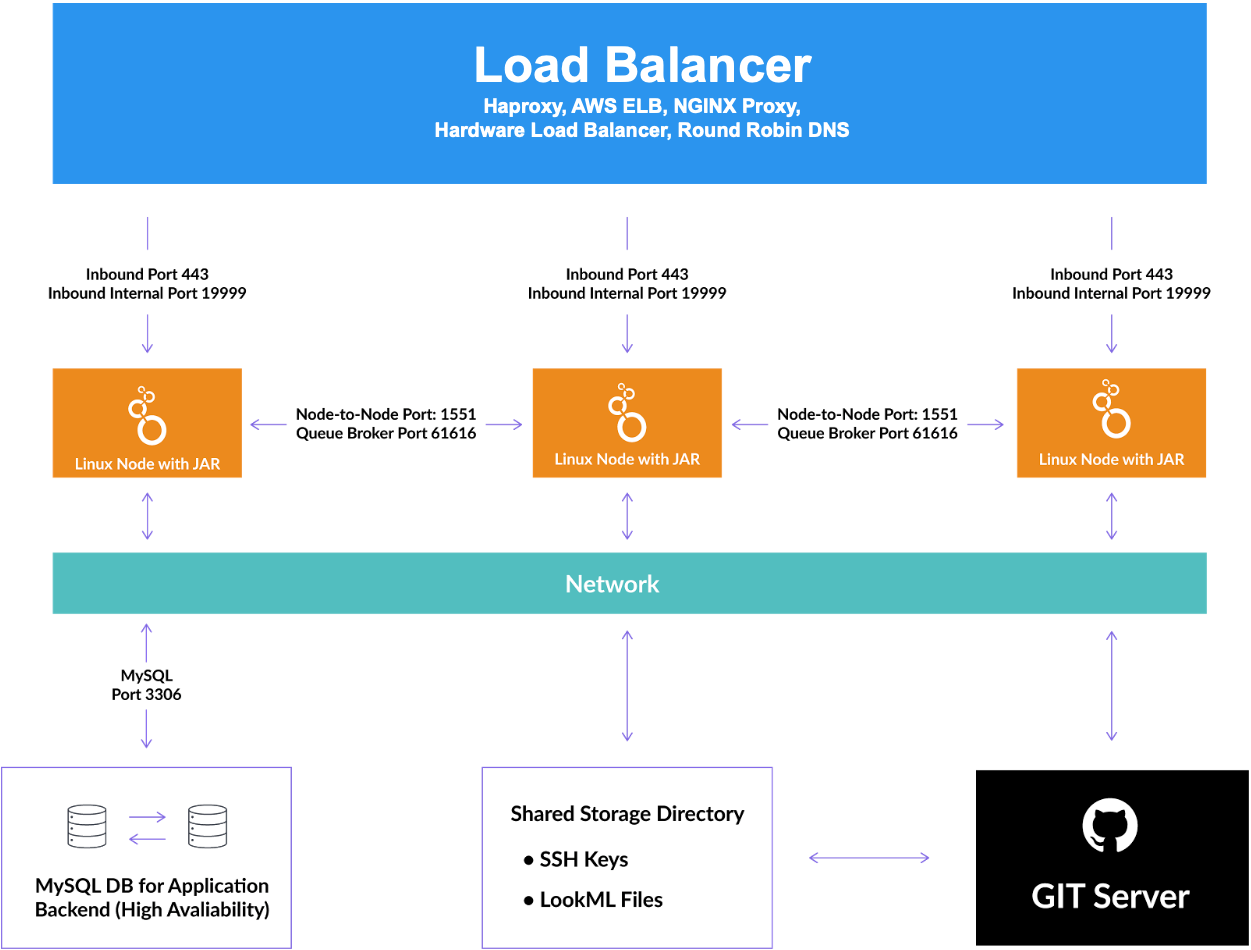
MySQL-Anwendungsdatenbank
Looker verwendet eine Anwendungsdatenbank (oft als interne Datenbank bezeichnet), um Anwendungsdaten zu speichern. Wenn Looker als Anwendung mit einem einzelnen Knoten ausgeführt wird, verwendet es normalerweise eine In-Memory-HyperSQL-Datenbank.
In einer geclusterten Looker-Konfiguration muss die Looker-Instanz jedes Knotens auf eine gemeinsame Transaktionsdatenbank (die freigegebene Anwendung oder die interne Datenbank) verweisen. Die Anwendungsdatenbank für Cluster-Looker wird so unterstützt:
- Nur MySQL wird für die Anwendungsdatenbank für Looker-Clustercluster unterstützt. Amazon Aurora und MariaDB werden nicht unterstützt.
- Die MySQL-Versionen 5.7+ und 8.0+ werden unterstützt.
- Geclusterte Datenbanken wie Galera werden nicht unterstützt.
Die Wartung und Sicherung dieser Datenbank wird nicht von Looker verwaltet. Da die Datenbank fast alle Looker-Anwendungskonfigurationsdaten hostet, sollte sie jedoch als Hochverfügbarkeitsdatenbank bereitgestellt und mindestens täglich gesichert werden.
Looker-Knoten
Jeder Knoten ist ein Server, auf dem der Looker-Java-Prozess ausgeführt wird. Die Server im Looker-Cluster müssen miteinander und mit der Looker-Anwendungsdatenbank kommunizieren können. Die Standardports sind auf dieser Seite unter Ports für die Kommunikation der Knoten öffnen aufgeführt.
Load-Balancer
Zum Ausgleichen der Load-Balancing- oder Weiterleitungsanfragen an verfügbare Knoten ist ein Load-Balancer oder Proxyserver (z. B. NGINX oder AWS ELB) erforderlich, um den Traffic an jeden Looker-Knoten weiterzuleiten. Der Load-Balancer übernimmt Systemdiagnosen. Bei einem Knotenfehler muss der Load-Balancer so konfiguriert werden, dass Traffic an die verbleibenden fehlerfreien Knoten umgeleitet wird.
Achten Sie bei der Auswahl und Konfiguration des Load-Balancers darauf, dass er nur als Layer 4 konfiguriert werden kann. Ein Beispiel dafür ist der Amazon ELB. Darüber hinaus sollte der Load-Balancer ein langes Zeitlimit haben (3.600 Sekunden), damit Abfragen nicht beendet werden.
Freigegebenes Dateisystem
Sie müssen ein POSIX-konformes freigegebenes Dateisystem wie NFS, AWS EFS, Gluster, BeeGFS oder Lustre verwenden. Looker verwendet das freigegebene Dateisystem als Repository für verschiedene Informationen, die von allen Knoten im Cluster verwendet werden.
Looker-Anwendung (ausführbare JAR-Datei)
Sie müssen eine Looker-Anwendungs-JAR-Datei mit Looker 3.56 oder höher verwenden.
Looker empfiehlt dringend, dass jeder Knoten in einem Cluster dieselbe Looker-Release- und -Patchversion ausführt, wie auf dieser Seite unter Looker auf den Knoten starten erläutert.
Cluster einrichten
Die folgenden Aufgaben sind erforderlich:
- Looker installieren
- MySQL-Anwendungsdatenbank einrichten
- System für freigegebene Dateien einrichten
- SSH-Schlüssel-Repository freigeben (je nach Situation)
- Ports für die Kommunikation der Knoten öffnen
- Looker auf den Knoten starten
Looker installieren
Prüfen Sie, ob auf jedem Knoten Looker installiert ist. Verwenden Sie dazu die Looker-Anwendungs-JAR-Dateien und die Anleitung auf der Dokumentationsseite Vom Kunden gehostete Installation.
MySQL-Anwendungsdatenbank einrichten
Bei einer geclusterten Looker-Konfiguration muss die Anwendungsdatenbank eine MySQL-Datenbank sein. Wenn Sie eine vorhandene nicht geclusterte Looker-Instanz haben, die HyperSQL für die Anwendungsdatenbank verwendet, müssen Sie die Anwendungsdaten aus den HyperSQL-Daten in die neue gemeinsame MySQL-Anwendungsdatenbank migrieren.
Informationen zum Sichern von Looker und zum Migrieren der Anwendungsdatenbank von HyperSQL zu MySQL finden Sie in der Dokumentation auf der Seite Migration zu MySQL.
Das freigegebene Dateisystem einrichten
Nur bestimmte Dateitypen – Modelldateien, Bereitstellungsschlüssel, Plug-ins und potenziell vertrauliche Manifestdateien – sollten in das freigegebene Dateisystem gehören. So richten Sie das freigegebene Dateisystem ein:
- Prüfen Sie auf dem Server, auf dem das freigegebene Dateisystem gespeichert wird, ob Sie Zugriff auf ein anderes Konto haben, das eine
su-Verknüpfung mit dem Looker-Nutzerkonto herstellen kann. - Melden Sie sich auf dem Server für das freigegebene Dateisystem im Looker-Nutzerkonto an.
- Wenn Looker derzeit ausgeführt wird, beenden Sie Ihre Looker-Konfiguration.
- Wenn Sie zuvor Cluster mit Linux-Skripts erstellt haben, stoppen Sie diese Skripts, entfernen Sie sie aus Cron und löschen Sie sie.
- Erstellen Sie eine Netzwerkfreigabe und stellen Sie sie auf jedem Knoten im Cluster bereit. Achten Sie darauf, dass es für die automatische Bereitstellung auf jedem Knoten konfiguriert ist und dass der Looker-Nutzer die Berechtigung zum Lesen und Schreiben hat. Im folgenden Beispiel heißt die Netzwerkfreigabe
/mnt/looker-share. Kopieren Sie auf einem Knoten Ihre Bereitstellungsschlüssel und verschieben Sie die Plug-ins und die Verzeichnisse
looker/modelsundlooker/models-user-*, in denen Ihre Modelldateien gespeichert sind, in Ihre Netzwerkfreigabe. Beispiel:mv looker/models /mnt/looker-share/ mv looker/models-user-* /mnt/looker-share/Fügen Sie für jeden Knoten die Einstellung
--shared-storage-dirzuLOOKERARGShinzu. Geben Sie die Netzwerkfreigabe wie in diesem Beispiel an:--shared-storage-dir /mnt/looker-shareLOOKERARGSsollte$HOME/looker/lookerstart.cfghinzugefügt werden, damit die Einstellungen nicht von Aktualisierungen betroffen sind. Wenn IhreLOOKERARGSnicht in dieser Datei aufgeführt ist, wurde sie möglicherweise direkt vom Shell-Skript$HOME/looker/lookerhinzugefügt.Jeder Knoten im Cluster muss in ein eindeutiges
/log-Verzeichnis oder zumindest eine eindeutige Logdatei schreiben.
SSH-Schlüssel-Repository freigeben
- Sie erstellen einen freigegebenen Dateisystemcluster aus einer vorhandenen Looker-Konfiguration und
- Sie haben Projekte, die in Looker 4.6 oder früher erstellt wurden.
Richten Sie das SSH-Schlüssel-Repository ein, das freigegeben werden soll:
Erstellen Sie auf dem freigegebenen Dateiserver ein Verzeichnis namens
ssh-share. Beispiel:/mnt/looker-share/ssh-shareAchten Sie darauf, dass das
ssh-share-Verzeichnis dem Looker-Nutzer gehört und die Berechtigungen 700 sind. Achten Sie außerdem darauf, dass Verzeichnisse über dem Verzeichnisssh-share(wie/mntund/mnt/looker-share) nicht für die ganze Welt beschreibbar und nicht für Gruppen zugänglich sind.Kopieren Sie auf einem Knoten den Inhalt von
$HOME/.sshin das neue Verzeichnisssh-share. Beispiel:cp $HOME/.ssh/* /mnt/looker-share/ssh-shareErstellen Sie für jeden Knoten eine Sicherung der vorhandenen SSH-Datei und erstellen Sie einen symlink zum Verzeichnis
ssh-share. Beispiel:cd $HOME mv .ssh .ssh_bak ln -s /mnt/looker-share/ssh-share .sshFühren Sie diesen Schritt für jeden Knoten aus.
Ports für die Kommunikation öffnen
Clusterierte Looker-Knoten kommunizieren über HTTPS mit selbst signierten Zertifikaten und einem zusätzlichen Authentifizierungsschema auf Grundlage von rotierenden Secrets in der Anwendungsdatenbank miteinander.
Die Standardports, die zwischen Clusterknoten geöffnet sein müssen, sind 1551 und 61616. Diese Ports können mit den hier aufgeführten Start-Flags konfiguriert werden. Wir empfehlen dringend, den Netzwerkzugriff auf diese Ports einzuschränken, um nur Traffic zwischen den Clusterhosts zuzulassen.
Looker auf den Knoten starten
Starten Sie den Server auf jedem Knoten mit den erforderlichen Start-Flags neu.
Verfügbare Start-Flags
Die folgende Tabelle enthält die verfügbaren Start-Flags, einschließlich der Flags, die zum Starten oder Verbinden eines Clusters erforderlich sind:
| Flag | Erforderlich/Optional? | Werte | Zweck |
|---|---|---|---|
--clustered |
Ja | Fügen Sie ein Flag hinzu, um anzugeben, dass dieser Knoten im Clustermodus ausgeführt wird. | |
-H oder --hostname |
Ja | 10.10.10.10 |
Der Hostname, über den andere Knoten mit diesem Knoten in Kontakt treten, z. B. die IP-Adresse des Knotens oder der Hostname des Systems. Muss sich von den Hostnamen aller anderen Knoten im Cluster unterscheiden. |
-n |
Nein | 1551 |
Der Port für die knotenübergreifende Kommunikation. Der Standardwert ist 1.551. Alle Knoten müssen für die Kommunikation zwischen Knoten dieselbe Portnummer verwenden. |
-q |
Nein | 61616 |
Der Port für clusterübergreifende Ereignisse in die Warteschlange. Der Standardwert ist 61.616. |
-d |
Ja | /path/to/looker-db.yml |
Der Pfad zur Datei, die die Anmeldedaten für die Looker-Anwendungsdatenbank enthält. |
--shared-storage-dir |
Ja | /path/to/mounted/shared/storage |
Die Option sollte auf die frühere Seite für das gemeinsame Verzeichnis verweisen, in der die Verzeichnisse looker/model und looker/models-user-* enthalten sind. |
Beispiel für LOOKERARGS und Angabe von Anmeldedaten für die Datenbank
Legen Sie die Looker-Start-Flags in einer lookerstart.cfg-Datei im selben Verzeichnis wie die Looker-JAR-Dateien ab.
Beispielsweise können Sie Looker Folgendes mitteilen:
- So verwenden Sie die Datei
looker-db.ymlfür ihre Datenbankanmeldedaten: - dass es sich um einen Clusterknoten handelt.
- dass die anderen Knoten des Clusters diesen Host über die IP-Adresse 10.10.10.10 kontaktieren sollen.
In diesem Fall würden Sie Folgendes angeben:
LOOKERARGS="-d looker-db.yml --clustered -H 10.10.10.10"
Die Datei looker-db.yml enthält die Anmeldedaten der Datenbank:
host: your.db.hostname.com
username: db_user
database: looker
dialect: mysql
port: 3306
password: secretPassword
Wenn für Ihre MySQL-Datenbank eine SSL-Verbindung erforderlich ist, gilt für die Datei looker-db.yml außerdem Folgendes:
ssl: true
Wenn Sie die Konfiguration nicht in der Datei looker-db.yml auf dem Laufwerk speichern möchten, können Sie die Umgebungsvariable LOOKER_DB so konfigurieren, dass sie eine Liste mit Schlüsseln und Werten für jede Zeile in der Datei looker-db.yml enthält. Beispiel:
export LOOKER_DB="dialect=mysql&host=localhost&username=root&password=&database=looker&port=3306"
Git-SSH-Bereitstellungsschlüssel finden
Wo Looker von Git-SSH-Bereitstellungsschlüsseln gespeichert wird, hängt davon ab, in welchem Release das Projekt erstellt wurde:
- Bei Projekten, die vor Looker 4.8 erstellt wurden, werden die Bereitstellungsschlüssel im nativen SSH-Verzeichnis des Servers gespeichert:
~/.ssh. - Bei Projekten, die in Looker 4.8 oder höher erstellt werden, werden die Bereitstellungsschlüssel in einem von Looker kontrollierten Verzeichnis (
~/looker/deploy_keys/PROJECT_NAME) gespeichert.
Looker-Cluster ändern
Nachdem Sie einen Looker-Cluster erstellt haben, können Sie Knoten hinzufügen oder entfernen, ohne Änderungen an den anderen Clusterknoten vorzunehmen.
Cluster auf einen neuen Looker-Release aktualisieren
Aktualisierungen können Schemaänderungen an der internen Looker-Datenbank beinhalten, die nicht mit vorherigen Versionen von Looker kompatibel wären. Zum Aktualisieren von Looker gibt es zwei Methoden:
Sicherer
- Erstellen Sie eine Sicherung der Anwendungsdatenbank.
- Beenden Sie alle Knoten des Clusters.
- Ersetzen Sie die JAR-Dateien auf jedem Server.
- Jeder Knoten muss nacheinander gestartet werden.
Schnellere Methode
So geht eine schnellere, aber weniger vollständige Methode:
- Erstellen Sie ein Replikat der Looker-Anwendungsdatenbank.
- einen neuen Cluster starten, der auf das Replikat verweist
- Verweisen Sie den Proxyserver oder Load-Balancer auf die neuen Knoten. Danach können Sie die alten Knoten beenden.