Multi Cluster Ingress est un contrôleur hébergé dans le cloud pour les clusters Google Kubernetes Engine (GKE). Il s'agit d'un service hébergé par Google qui permet de déployer des ressources d'équilibrage de charge partagées entre les clusters et entre les régions. Pour déployer un objet Ingress multicluster sur plusieurs clusters, suivez les instructions de la section Configurer un objet Ingress multicluster, puis consultez la section Déployer une entrée sur plusieurs clusters.
Pour consulter une comparaison détaillée entre le service Multi Cluster Ingress (MCI), la passerelle multicluster (MCG) et un équilibreur de charge avec des groupes de points de terminaison du réseau autonomes (LB avec NEG autonomes), consultez la page Choisir votre API d'équilibrage de charge multicluster pour GKE.
Mise en réseau multicluster
De nombreux facteurs influencent les topologies multiclusters, notamment la proximité des utilisateurs pour les applications, la haute disponibilité des clusters et des régions, la séparation organisationnelle et de sécurité, la migration des clusters et la localité des données. Ces cas d'utilisation sont rarement isolés. À mesure que les raisons de la multiplication des clusters augmentent, il devient de plus en plus urgent de créer une plate-forme multicluster formelle et industrialisée.
Un objet objetIngress multicluster est conçu pour répondre aux besoins d'équilibrage de charge des environnements multicluster et multirégionaux. Il s'agit d'une commande permettant à l'équilibreur de charge HTTP(S) externe de fournir une entrée pour le trafic provenant d'Internet sur un ou plusieurs clusters.
La compatibilité multicluster de l'objet Ingress multicluster est assurée par de nombreux cas d'utilisation, parmi lesquels :
- Une adresse IP virtuelle (IPV) unique et cohérente pour une application, indépendamment de l'endroit où celle-ci est déployée dans le monde entier.
- La disponibilité multirégionale et multicluster via la vérification d'état et le basculement du trafic.
- Le routage basé sur la proximité via les IPV publiques Anycast pour une faible latence du client.
- La migration transparente des clusters pour les mises à niveau ou les reconstructions de clusters.
Quotas par défaut
Multi Cluster Ingress est soumis aux quotas par défaut suivants :
- Pour en savoir plus sur les limites relatives aux adhésions pour les parcs et savoir combien de membres sont acceptés dans un parc, consultez la page Quotas de gestion de parc.
- 100 ressources
MultiClusterIngresset 100 ressourcesMultiClusterServicepar projet. Vous pouvez créer jusqu'à 100 ressourcesMultiClusterIngresset 100 ressourcesMultiClusterServicedans un cluster de configuration pour un nombre illimité de clusters de backend, dans la limite du nombre maximal de clusters par projet.
Tarifs et essais
Pour en savoir plus sur la tarification des entrées multicluster, consultez la page Tarifs des entrées multiclusters.
Fonctionnement d'un objet Ingress multicluster
Multi Cluster Ingress s'appuie sur l'architecture de l'équilibreur de charge d'application externe global. L'équilibreur de charge d'application externe global est un équilibreur de charge distribué à l'échelle mondiale avec des proxys déployés dans plus de 100 points of presence (PoP) Google dans le monde. Ces proxys appelés Google Front End (GFE) se trouvent à la périphérie du réseau de Google, à proximité des clients. Multi Cluster Ingress crée des équilibreurs de charge d'application externes de niveau Premium. Ces équilibreurs de charge utilisent des adresses IP externes globales annoncées par anycast. Les requêtes sont traitées par les GFE et par le cluster le plus proche du client. Le trafic Internet est dirigé vers le POP Google le plus proche et utilise le réseau Google pour atteindre un cluster GKE. Cette configuration d'équilibrage de charge entraîne une latence plus faible du client au serveur GFE. Vous pouvez également réduire la latence entre la diffusion des clusters GKE et des GFE en exécutant vos clusters GKE dans les régions les plus proches de vos clients.
L'interruption de connexions HTTP et HTTPS en périphérie permet à l'équilibreur de charge Google de choisir où acheminer le trafic en déterminant la disponibilité du backend avant que le trafic entre dans un centre de données ou une région. Le trafic suit ainsi le chemin le plus efficace entre le client et le backend, tout en tenant compte de l'état et de la capacité des backends.
Un objet Ingress multicluster est un contrôleur d'entrée qui programme l'équilibreur de charge HTTP(S) externe à l'aide de groupes de points de terminaison du réseau (NEG).
Lorsque vous créez une ressource MultiClusterIngress, GKE déploie les ressources de l'équilibreur de charge Compute Engine et configure les pods appropriés sur les clusters en tant que backends. Les NEG sont utilisés pour effectuer le suivi dynamique des points de terminaison des pods de sorte que l'équilibreur de charge Google dispose de backends opérationnels.

Lorsque vous déployez des applications sur plusieurs clusters dans GKE, l'objet Ingress multicluster s'assure que l'équilibreur de charge est synchronisé avec les événements qui se produisent dans le cluster :
- Un déploiement est créé avec les libellés appropriés correspondants.
- Le processus d'un pod disparaît et échoue à sa vérification d'état.
- Un cluster est supprimé du pool de backends.
L'objet Ingress multicluster met à jour l'équilibreur de charge, en maintenant la cohérence avec l'environnement et l'état souhaité des ressources Kubernetes.
Architecture de l'objet Ingress multicluster
L'objet Ingress multicluster utilise un serveur d'API Kubernetes centralisé pour déployer l'objet Ingress sur plusieurs clusters. Ce serveur d'API centralisé est appelé "cluster de configuration". Tout cluster GKE peut faire office de cluster de configuration. Celui-ci utilise deux types de ressources personnalisés : MultiClusterIngress et MultiClusterService.
En déployant ces ressources sur le cluster de configuration, le contrôleur d'entrée multicluster déploie des équilibreurs de charge sur plusieurs clusters.
Les concepts et composants suivants constituent un objet Ingress multicluster :
Contrôleur d'entrée multicluster : il s'agit d'un plan de contrôle distribué à l'échelle mondiale qui s'exécute en tant que service en dehors de vos clusters. Ainsi, le cycle de vie et les opérations du contrôleur peuvent être indépendants des clusters GKE.
Cluster de configuration : cluster GKE choisi s'exécutant sur Google Cloud, et où les ressources
MultiClusterIngressetMultiClusterServicesont déployées. Il s'agit d'un point de contrôle centralisé pour ces ressources multiclusters. Celles-ci existent dans une seule API logique et sont accessibles depuis celle-ci pour conserver la cohérence entre tous les clusters. Le contrôleur d'Ingress surveille le cluster de configuration et procède au rapprochement de l'infrastructure d'équilibrage de charge.Un parc vous permet de regrouper et de normaliser logiquement des clusters GKE, ce qui facilite l'administration de l'infrastructure et permet d'utiliser des fonctionnalités multicluster telles que l'objet Ingress multicluster. Pour en savoir plus sur les avantages des parcs et leur création, consultez la documentation sur la gestion des parcs. Un cluster ne peut être membre que d'un seul parc.
Cluster membre : les clusters enregistrés dans une Fleet sont appelés clusters membres. Les clusters membres dans le parc comprennent l'ensemble des backends dont Ingress multicluster a connaissance. La vue Gestion des clusters Google Kubernetes Engine fournit une console sécurisée permettant d'afficher l'état de tous vos clusters enregistrés.

Workflow de déploiement
La procédure suivante illustre un workflow de haut niveau pour l'utilisation de l'objet Ingress multicluster sur plusieurs clusters.
Enregistrez les clusters GKE dans un parc du projet choisi.
Configurez un cluster GKE en tant que cluster de configuration central. Ce cluster peut être un plan de contrôle dédié ou exécuter d'autres charges de travail.
Déployez des applications sur les clusters GKE où elles doivent être exécutées.
Déployez une ou plusieurs ressources
MultiClusterServicedans le cluster de configuration avec des correspondances libellés et de clusters, afin de sélectionner des clusters, des espaces de noms et des pods considérés comme des backends pour un service donné. Cela crée des NEG dans Compute Engine, qui commence à enregistrer et à gérer les points de terminaison de service.Déployez une ressource
MultiClusterIngressdans le cluster de configuration qui référence une ou plusieurs ressourcesMultiClusterServiceen tant que backends pour l'équilibreur de charge. Celle-ci déploie les ressources de l'équilibreur de charge externe Compute Engine et expose les points de terminaison entre les clusters via une seule IPV d'équilibreur de charge.
Concepts d'Ingress
L'objet Ingress multicluster utilise un serveur d'API Kubernetes centralisé pour déployer l'objet Ingress sur plusieurs clusters. Les sections suivantes décrivent le modèle de ressource de l'objet Ingress multicluster, comment déployer l'objet Ingress et les concepts importants pour gérer ce plan de contrôle de réseau à disponibilité élevée.
Ressources MultiClusterService
Une ressource MultiClusterService est une ressource personnalisée utilisée par un objet Multi Cluster Ingress pour représenter les services de partage entre clusters. Une ressource MultiClusterService sélectionne les pods, de la même manière que la ressource Service, mais une ressource MultiClusterService peut également sélectionner des libellés et des clusters. Les clusters qu'un MultiClusterService sélectionne pour sélectionner sont appelés clusters membres. Tous les clusters enregistrés dans le parc sont des clusters membres.
Une MultiClusterService n'existe que dans le cluster de configuration et n'achemine pas de trafic comme le fait un service ClusterIP, LoadBalancer ou NodePort. Au lieu de cela, il permet au contrôleur Multi Cluster Ingress de faire référence à une ressource distribuée particulière.
L'exemple de fichier manifeste suivant décrit une MultiClusterService pour une application nommée foo :
apiVersion: networking.gke.io/v1
kind: MultiClusterService
metadata:
name: foo
namespace: blue
spec:
template:
spec:
selector:
app: foo
ports:
- name: web
protocol: TCP
port: 80
targetPort: 80
Ce fichier manifeste déploie un service dans tous les clusters membres à l'aide du sélecteur app:
foo. Si des pods app: foo existent dans ce cluster, les adresses IP de ces pods sont ajoutées en tant que backends pour le MultiClusterIngress.
Le service mci-zone1-svc-j726y6p1lilewtu7 suivant est un service dérivé généré dans l'un des clusters cibles. Ce service crée un NEG qui effectue le suivi des points de terminaison des pods pour tous les pods correspondant au sélecteur de libellés spécifié dans ce cluster. Il existe un service dérivé et un NEG dans chaque cluster cible, pour chaque MultiClusterService (sauf si vous utilisez des sélecteurs de cluster). Si aucun pod correspondant n'existe dans un cluster cible, le service et le NEG seront vides. Les services dérivés sont entièrement gérés par le MultiClusterService, et non directement par les utilisateurs.
apiVersion: v1
kind: Service
metadata:
annotations:
cloud.google.com/neg: '{"exposed_ports":{"8080":{}}}'
cloud.google.com/neg-status: '{"network_endpoint_groups":{"8080":"k8s1-a6b112b6-default-mci-zone1-svc-j726y6p1lilewt-808-e86163b5"},"zones":["us-central1-a"]}'
networking.gke.io/multiclusterservice-parent: '{"Namespace":"default","Name":"zone1"}'
name: mci-zone1-svc-j726y6p1lilewtu7
namespace: blue
spec:
selector:
app: foo
ports:
- name: web
protocol: TCP
port: 80
targetPort: 80
Remarques sur le service dérivé :
- Sa fonction est un regroupement logique de points de terminaison en tant que backends pour l'objet Ingress multicluster.
- Il gère le cycle de vie du NEG pour un cluster et une application donnés.
- Il est créé en tant que service sans adresse IP de cluster. Notez que seuls les champs
SelectoretPortssont transférés du serviceMultiClusterServicevers le service dérivé. - Le contrôleur d'entrée gère son cycle de vie.
Ressource MultiClusterIngress
Une ressource MultiClusterIngress se comporte de manière identique à la ressource Ingress principale. Elles ont toutes deux la même spécification pour la définition des hôtes, des chemins, de la terminaison de protocole et des backends.
Le fichier manifeste suivant décrit une classe MultiClusterIngress qui achemine le trafic vers les backends foo et bar en fonction des en-têtes d'hôte HTTP :
apiVersion: networking.gke.io/v1
kind: MultiClusterIngress
metadata:
name: foobar-ingress
namespace: blue
spec:
template:
spec:
backend:
serviceName: default-backend
servicePort: 80
rules:
- host: foo.example.com
backend:
serviceName: foo
servicePort: 80
- host: bar.example.com
backend:
serviceName: bar
servicePort: 80
Cette ressource MultiClusterIngress correspond au trafic vers l'adresse IP virtuelle sur foo.example.com et bar.example.com en envoyant ce trafic aux ressources MultiClusterService nommées foo et bar. Ce MultiClusterIngress dispose d'un backend par défaut qui établit une correspondance avec tout le reste du trafic et l'envoie au MultiClusterService du backend par défaut.
Le diagramme suivant illustre la manière dont le trafic circule d'un objet Ingress vers un cluster :

Le schéma présente deux clusters, gke-us et gke-eu. Le trafic circule depuis foo.example.com vers les pods portant le libellé app:foo sur les deux clusters. À partir de bar.example.com, le trafic circule vers les pods portant le libellé app:bar sur les deux clusters.
Ressources Ingress sur plusieurs clusters
Le cluster de configuration est le seul à pouvoir disposer de ressources MultiClusterIngress et MultiClusterService. Un service dérivé correspondant est également planifié sur chaque cluster cible dont les pods correspondent aux sélecteurs de libellés MultiClusterService. Si un cluster n'est pas explicitement sélectionné par un MultiClusterService, aucun service dérivé correspondant n'est créé dans ce cluster.

Identité de l'espace de noms
L'uniformité d'espace de noms est une propriété des clusters Kubernetes dans lesquels un espace de noms s'étend sur plusieurs clusters et est considéré comme le même espace de noms.
Dans le schéma suivant, l'espace de noms blue existe dans les clusters GKE gke-cfg, gke-eu et gke-us. L'uniformité d'espace de noms considère l'espace de noms blue comme identique sur tous les clusters. Cela signifie qu'un utilisateur dispose des mêmes droits sur les ressources de l'espace de noms blue dans chaque cluster.
L'uniformité de l'espace de noms signifie également que les ressources de service portant le même nom sur plusieurs clusters dans l'espace de noms blue sont considérées comme le même service.
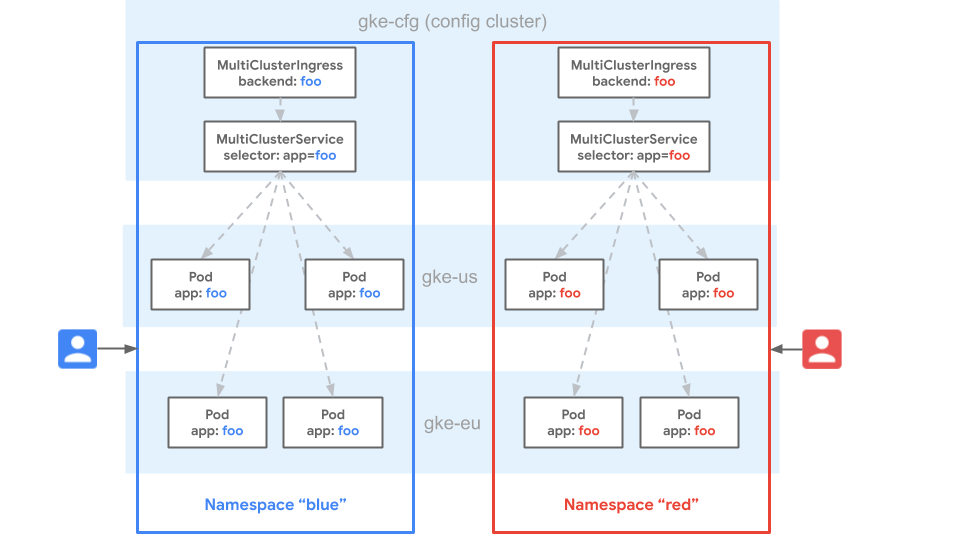
Gateway traite le service comme un pool de points de terminaison unique pour les trois clusters. Comme les routes et les ressources MultiClusterIngress ne peuvent être acheminées que vers des services dans le même espace de noms, cela permet une configuration mutualisée cohérente pour la configuration sur tous les clusters du parc. Les parcs offrent une grande portabilité, car les ressources peuvent être déployées ou déplacées d'un cluster à l'autre sans aucune modification de leur configuration. Le déploiement dans le même espace de noms de parc assure la cohérence entre les clusters.
Tenez compte des principes de conception suivants pour assurer l'uniformité des espaces de noms :
- Les espaces de noms ayant des objectifs différents ne doivent pas avoir le même nom sur l'ensemble des clusters.
- Les espaces de noms doivent être réservés explicitement en allouant un espace de noms, ou implicitement, via des règles hors bande, aux équipes et aux clusters au sein d'un parc.
- Les espaces de noms ayant le même objectif sur l'ensemble des clusters doivent partager le même nom.
- L'autorisation utilisateur sur les espaces de noms pour l'ensemble des clusters doit être étroitement contrôlée pour empêcher tout accès non autorisé.
- Vous ne devez pas utiliser l'espace de noms par défaut ou les espaces de noms génériques tels que "prod" ou "dev" pour le déploiement normal d'une application. En effet, les utilisateurs pourraient déployer accidentellement des ressources dans l'espace de noms par défaut et enfreindre les principes de segmentation des espaces de noms.
- Le même espace de noms doit être créé dans les clusters, dès lors qu'une équipe ou un groupe d'utilisateurs donné doit déployer des ressources.
Conception du cluster de configuration
Le cluster de configuration de l'objet Ingress multicluster est un cluster GKE unique qui héberge les ressources MultiClusterIngress et MultiClusterService, et sert de point de contrôle unique pour l'objet Ingress sur l'ensemble des clusters GKE cibles. Vous choisissez le cluster de configuration lorsque vous activez l'objet Ingress multicluster. Vous pouvez choisir n'importe quel cluster GKE comme cluster de configuration et le modifier à tout moment.
Disponibilité du cluster de configuration
Comme le cluster de configuration est un point de contrôle unique, les ressources de l'objet Ingress multicluster ne peuvent pas être créées ni mises à jour si l'API du cluster de configuration n'est pas disponible. Les équilibreurs de charge et le trafic desservi ne sont pas affectés par une panne du cluster de configuration. Toutefois, les modifications apportées aux ressources MultiClusterIngress et MultiClusterService ne sont pas rapprochées par le contrôleur tant que celui-ci n'est pas à nouveau disponible.
Tenez compte des principes de conception suivants pour les clusters de configuration :
- Le cluster de configuration doit être choisi de sorte qu'il soit hautement disponible. Les clusters régionaux sont préférables aux clusters zonaux.
- Pour activer l'objet Multi Cluster Ingress, le cluster de configuration ne doit pas nécessairement être un cluster dédié. Le cluster de configuration peut héberger des charges de travail d'administration, voire d'application. Veillez cependant à ce que les applications hébergées n'affectent pas la disponibilité du serveur d'API du cluster de configuration. Le cluster de configuration peut être un cluster cible qui héberge des backends pour les ressources
MultiClusterService. Toutefois, si des précautions supplémentaires sont nécessaires, il peut également être exclu en tant que backend via la sélection de clusters. - Les clusters de configuration doivent détenir tous les espaces de noms utilisés par les backends de cluster cible. Un
MultiClusterServicene peut référencer des pods que dans le même espace de noms sur plusieurs clusters ; cet espace de noms doit donc être présent dans le cluster de configuration. - Les utilisateurs qui déploient Ingress sur plusieurs clusters doivent avoir accès au cluster de configuration pour déployer des ressources
MultiClusterIngressetMultiClusterService. Toutefois, les utilisateurs ne doivent avoir accès qu'aux espaces de noms qu'ils sont autorisés à utiliser.
Sélectionner et migrer le cluster de configuration
Vous choisissez le cluster de configuration lorsque vous activez l'objet Ingress multicluster. Tout cluster membre d'une Fleet peut être sélectionné en tant que cluster de configuration. Vous pouvez mettre à jour le cluster de configuration à tout moment, mais vous devez veiller à ce que cela n'entraîne pas de perturbations. Le contrôleur d'entrée rapproche toutes les ressources présentes dans le cluster de configuration. Lors de la migration du cluster de configuration du cluster actuel vers le suivant, les ressources MultiClusterIngress et MultiClusterService doivent être identiques.
Si les ressources ne sont pas identiques, les équilibreurs de charge Compute Engine risquent d'être mis à jour ou détruits après la mise à jour du cluster de configuration.
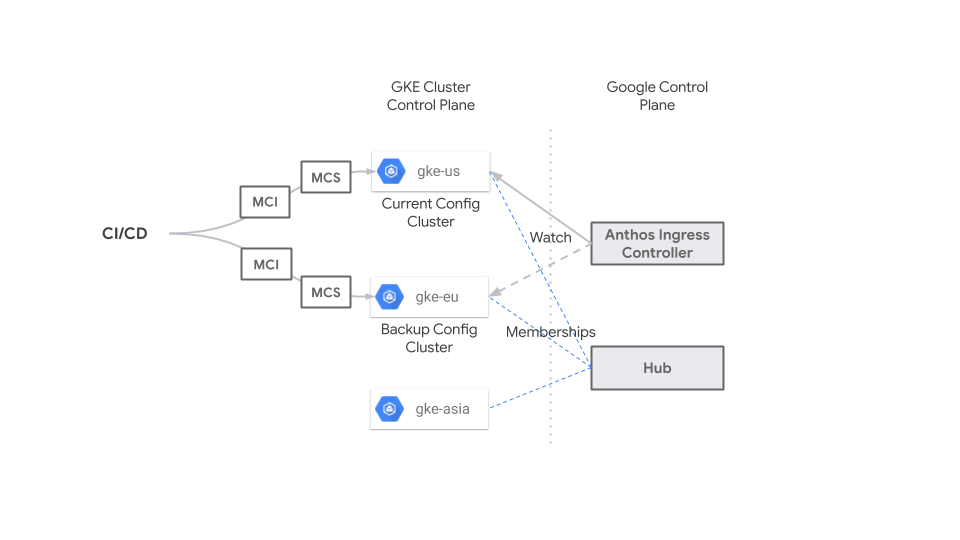
Le schéma suivant montre comment un système CI/CD centralisé applique à tout moment des ressources MultiClusterIngress et MultiClusterService au serveur d'API GKE pour le cluster de configuration (gke-us) et un cluster de sauvegarde (gke-eu) afin que les ressources soient identiques sur les deux clusters. Vous pouvez modifier le cluster de configuration en cas d'urgence ou de temps d'arrêt planifié à tout moment, sans aucun impact, car les ressources MultiClusterIngress et MultiClusterService sont identiques.
Sélection des clusters
Les ressources MultiClusterService peuvent être sélectionnées dans tous les clusters. Par défaut, le contrôleur planifie un service dérivé sur chaque cluster cible. Si vous ne souhaitez pas de service dérivé sur chaque cluster cible, vous pouvez définir une liste de clusters à l'aide du champ spec.clusters du fichier manifeste MultiClusterService.
Vous pouvez définir une liste de clusters si vous devez effectuer l'une des actions suivantes :
- Isoler le cluster de configuration pour empêcher les ressources
MultiClusterServicede le sélectionner. - Contrôler le trafic entre les clusters pour la migration des applications.
- Router vers des backends d'application qui n'existent que dans un sous-ensemble de clusters.
- Utiliser une seule adresse IP virtuelle HTTP(S) pour le routage vers des backends qui résident sur différents clusters.
Vous devez vous assurer que les clusters membres d'un même parc et d'une même région ont des noms uniques pour éviter les conflits de noms.
Pour savoir comment configurer la sélection des clusters, consultez la page Configurer un objet Ingress multicluster.
Le fichier manifeste suivant décrit un objet MultiClusterService ayant un champ clusters qui fait référence à europe-west1-c/gke-eu et asia-northeast1-a/gke-asia :
apiVersion: networking.gke.io/v1
kind: MultiClusterService
metadata:
name: foo
namespace: blue
spec:
template:
spec:
selector:
app: foo
ports:
- name: web
protocol: TCP
port: 80
targetPort: 80
clusters:
- link: "europe-west1-c/gke-eu"
- link: "asia-northeast1-a/gke-asia-1"
Ce fichier manifeste spécifie que les pods avec les libellés correspondants dans les clusters gke-asia et gke-eu peuvent être inclus en tant que backends pour le MultiClusterIngress.
Tous les autres clusters sont exclus, même s'ils comportent des pods avec le libellé app: foo.
Le schéma suivant présente un exemple de configuration MultiClusterService utilisant le fichier manifeste précédent :
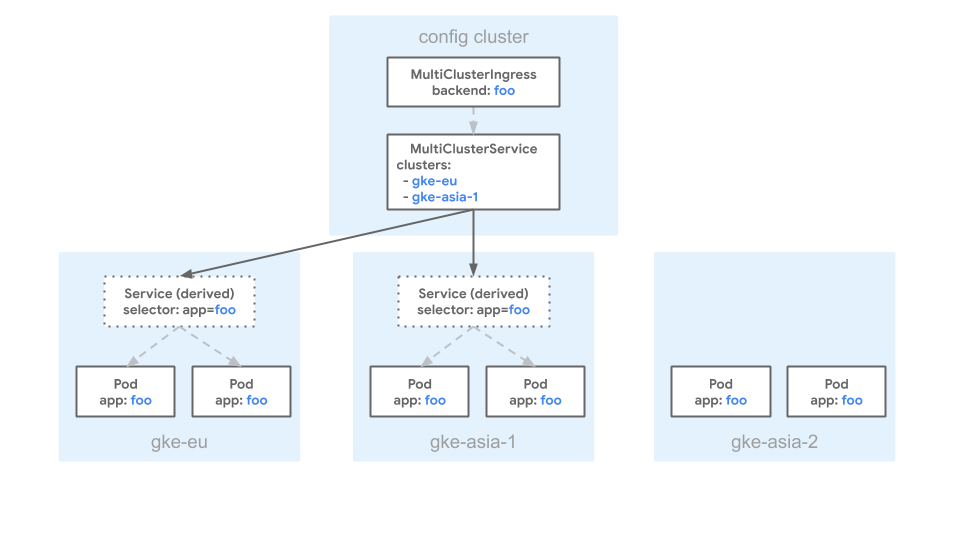
Le schéma présente trois clusters : gke-eu, gke-asia-1 et gke-asia-2. Le cluster gke-asia-2 n'est pas inclus en tant que backend, même s'il existe des pods avec des libellés correspondants, car il ne figure pas dans la liste spec.clusters. Le cluster ne reçoit pas de trafic pour les opérations de maintenance ou autres.
Étape suivante
- Découvrez comment configurer un objet Multi Cluster Ingress.
- Découvrez comment déployer des passerelles multiclusters.
- Découvrez comment déployer un objet Multi Cluster Ingress.
- Mettez en œuvre Multi-Cluster Ingress pour l'équilibrage de charge externe.