借助 Error Reporting,您可以自动捕获应用崩溃并将这些崩溃的堆栈轨迹分组到错误组中,以识别、了解和管理应用错误。但是,某些 Google Cloud 服务错误会被记录为错误消息,不会以堆栈轨迹的形式提供。Error Reporting 的服务错误功能会自动捕获这些类型的 Google Cloud 服务错误并对其进行分组,以便您快速识别系统中的问题并在出现新错误时收到通知。
例如,您在使用 Cloud Run 时可能会遇到以下情况:在发出请求时达到容器实例数上限。当此事件记录到 Cloud Logging 中时,Error Reporting 中的服务错误会自动捕获此错误,将其与类似错误归为一组,并通知您此事件的发生。此外,为帮助解决这些错误,一些 Google Cloud 服务提供了问题排查文档,您可以从 Error Reporting 页面访问这些文档。
查看服务错误
在 Google Cloud 控制台的导航面板中,选择 Error Reporting,然后选择您的 Google Cloud 项目:
当 Error Reporting 检测到包含新服务错误的日志并对其进行分组后,您可以在 Error Reporting 概览页面的类型列中看到这些服务错误。
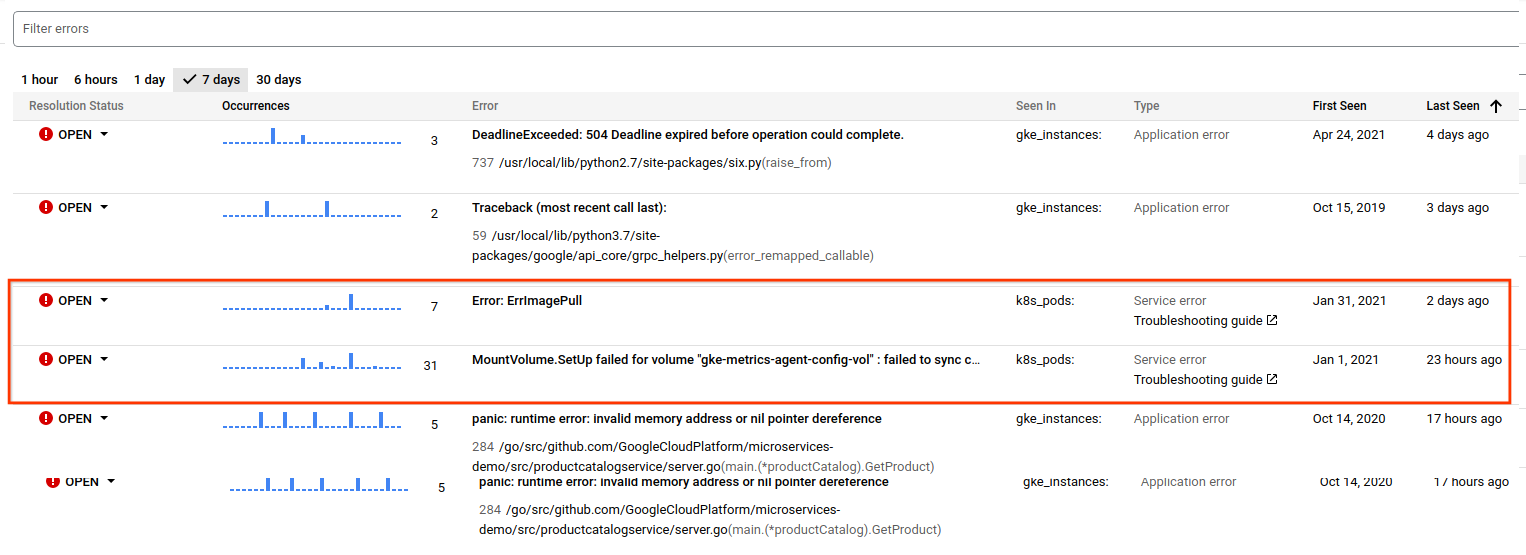
对于已记录有解决方案的服务错误,Error Reporting 提供了 Google Cloud 服务提供的问题排查指南的链接。
服务错误示例
下表列出了 Error Reporting 的服务错误捕获的一些(但不是全部)错误。
| Google Cloud 服务名称 | 错误类型 |
|---|---|
| Dataflow | 工作器日志限制 内存不足(系统) 缺少自定义子网 步骤有冗长的操作 JRE 崩溃 工作器 JAR 文件配置错误 |
| Cloud Run | 超出内存上限 无可用实例 |
| Google Kubernetes Engine | Pod 运行状况不佳,探测失败 Pod 无法调度 使用退避算法重启失败的容器 未装载的卷 容器映像拉取失败 未能更新端点 未找到密钥/configmap |