本主题介绍如何使用敏感数据保护衡量数据集的 k-匿名性,并在 Looker Studio 中将其直观呈现。这样,您也可以更好地了解风险,同时有助于评估您在工具中对数据进行遮盖和去标识化时可能采用的折中。
虽然这个主题的主要内容是 k-匿名性重标识风险分析指标,但是您也可以使用同样的方法直观呈现 I-多样性指标。
本主题假设您已熟悉 k-匿名性的概念以及它在评估数据集中记录的可重标识性方面的效用。至少在一定程度上熟悉如何使用敏感数据保护计算 k-匿名性以及如何使用 Looker Studio 也会很有帮助。
简介
在您处理或使用数据时,去标识化技术有助于保护您主体的隐私。但是,如何知道数据集是否已充分进行去标识化?如何知道去标识化对于您的使用场景来说是否损失了太多数据?也就是说,如何将重标识风险与数据的效用进行比较,从而帮助您以数据为依据做出决策?
计算数据集的 k-匿名性值可帮助您解答这些问题,因为此操作会评估数据集记录的可重标识性。 敏感数据保护包含内置功能,可根据您指定的准标识符计算数据集的 k-匿名性值。借助此功能,您可以快速评估对某个列或列组合进行去标识化是否或多或少有可能导致对数据集进行重标识。
示例数据集
以下是某个大型数据集示例的前几行。
user_id |
age |
title |
score |
|---|---|---|---|
602-61-8588 |
24 |
Biostatistician III |
733 |
771-07-8231 |
46 |
Executive Secretary |
672 |
618-96-2322 |
69 |
Programmer I |
514 |
... |
... |
... |
... |
在本教程中,我们的侧重点在于准标识符,因此不处理 user_id。在实际场景中,您需要确保对 user_id 进行适当的遮盖或令牌化处理。由于 score 列为此数据集专有,并且攻击者不太可能通过其他方式了解该列,因此您不用将其纳入分析中。您将重点关注剩下的 age 和 title 列;利用这些列,攻击者可以通过其他数据源了解个人信息。您需要回答以下有关数据集的问题:
- 对于经过去标识化处理的数据来说,这两个准标识符(
age和title)对其整体的重标识风险有什么影响? - 应用去标识化转换将如何影响这种风险?
您希望确保 age 和 title 的组合不会映射到少数用户。例如,假设数据集中只有一个用户的职称为程序员且年龄为 69 岁。攻击者可能会将这些信息与人口统计信息或其他可用信息进行交叉引用,查出该用户的身份,并了解真实情报的价值。如需详细了解此现象,请参阅风险分析概念主题中的“实体 ID 与 k-匿名性计算”部分。
步骤 1:计算数据集的 k-匿名性
首先,将以下 JSON 发送到 DlpJob 资源,使用敏感数据保护计算数据集的 k-匿名性。在此 JSON 中,将实体 ID设置为 user_id 列,并将两个准标识符标识为 age 和 title 列。您还将指示敏感数据保护将结果保存到新的 BigQuery 表中。
JSON 输入:
POST https://dlp.googleapis.com/v2/projects/dlp-demo-2/dlpJobs
{
"riskJob": {
"sourceTable": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "dlp_test_data_kanon"
},
"privacyMetric": {
"kAnonymityConfig": {
"entityId": {
"field": {
"name": "id"
}
},
"quasiIds": [
{
"name": "age"
},
{
"name": "job_title"
}
]
}
},
"actions": [
{
"saveFindings": {
"outputConfig": {
"table": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "test_results"
}
}
}
}
]
}
}
k-匿名性作业完成后,敏感数据保护会将作业结果发送到名为 dlp-demo-2.dlp_testing.test_results 的 BigQuery 表。
第 2 步:将结果关联到 Looker 数据洞察
接下来,将第 1 步中生成的 BigQuery 表连接到 Looker Studio 中的新报告。
打开 Looker 数据洞察。
依次点击创建 > 报告。
在向报告添加数据窗格的连接到数据之下,点击 BigQuery。您可能需要授权 Looker Studio 访问您的 BigQuery 表。
在列选择器中,选择我的项目。然后选择项目、数据集和表。完成后,点击添加。如果系统通知您您要向此报告添加数据,请点击添加到报告。
k-匿名性扫描结果现已添加到新的 Looker Studio 报告中。在下一步中,您将创建图表。
步骤 3:创建图表
执行以下操作来插入和配置图表:
- 在 Looker Studio 中,如果显示值表,请选择该表,然后按 Delete 键将其移除。
- 在插入菜单上,点击组合图表。
- 在画布上想要显示图表的位置点击并绘制一个矩形。
接下来在数据标签页之下配置图表数据,以便图表显示更改存储分区大小和值范围的效果:
- 将光标指向每个字段并点击 X,以清除以下标题中的字段,如下所示:
- 日期范围维度
- 维度
- 指标
- 排序
- 清除所有字段后,将 upper_endpoint 字段从可用字段列拖动到维度标题中。
- 将 upper_endpoint 字段拖动到排序标题中,然后选择升序。
- 将 bucket_size 和 bucket_value_count 字段拖动到指标标题中。
- 将光标指向 bucket_size 指标左侧的图标,此时将显示修改图标。点击修改图标,然后执行以下操作:
- 在名称字段中,输入
Unique row loss。 - 在类型下,选择百分比。
- 在比较计算下,选择占总数的百分比。
- 在运行计算下,选择运行总和。
- 在名称字段中,输入
- 对 bucket_value_count 指标重复上一步,但在名称字段中输入
Unique quasi-identifier combination loss。
完成后,列应显示如下:
最后,将图表配置为显示两个指标的折线图:
- 点击窗口右侧窗格中的样式标签。
- 为这两个系列(#1 和 #2)选择拆线图。
- 如需单独查看最终图表,请点击窗口右上角的查看按钮。
以下是完成上述步骤后的示例图表。
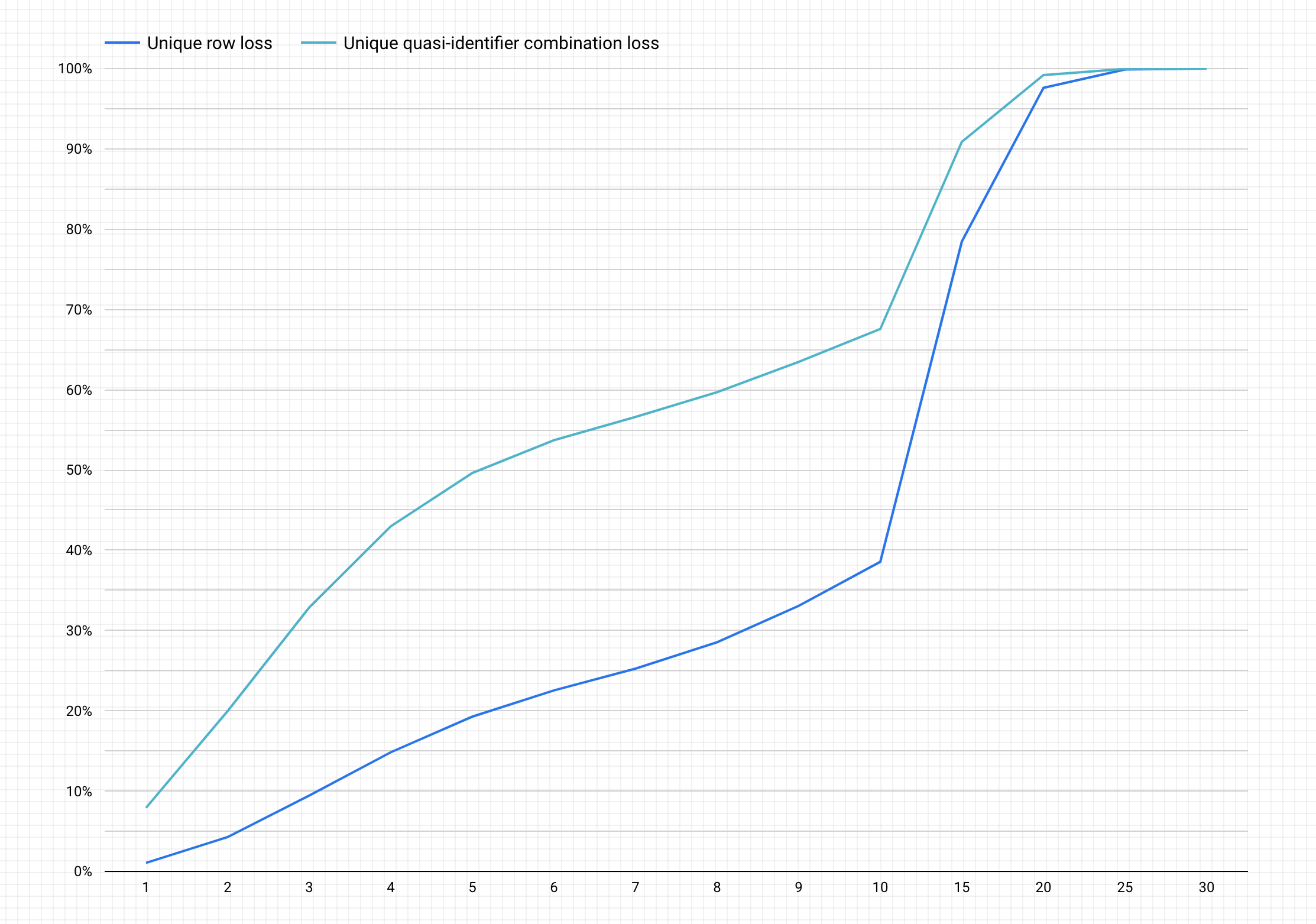
解读图表
重标识风险图表在 y 轴上绘制唯一行和唯一准标识符组合的潜在数据泄露百分比,以在 x 轴上实现 k-匿名性值。
k-匿名性值越大,表示重标识的风险越小。但是,要实现较大的 k-匿名性值,您需要移除总行数的较大百分比以及较大的唯一准标识符组合,这可能会降低数据的效用。
所幸的是,删除数据并不是减少重标识风险的唯一选项。使用其他去标识化技术可以更好地平衡泄露和效用。例如,为了解决这种与较高的 k-匿名性值和此类数据集相关的数据泄露问题,您可以尝试对年龄或工作职称进行分桶,以降低年龄/工作职称组合的唯一性。例如,您可以尝试使用 20-25、25-30、30-35 等范围对年龄进行分桶。如需详细了解如何执行此操作,请参阅泛化和分桶以及对文本内容中的敏感数据进行去标识化。