La seudonimización es una técnica de desidentificación que reemplaza valores de datos sensibles por los tokens generados de manera criptográfica. La seudonimización se usa mucho en industrias como las finanzas y la atención médica para ayudar a reducir el riesgo de los datos en uso, reducir el alcance del cumplimiento y minimizar la exposición de los datos sensibles a los sistemas, a la vez que conserva la precisión y utilidad de los datos.
La Protección de datos sensibles admite tres técnicas de seudonimización de desidentificación y genera tokens mediante la aplicación de uno de tres métodos de transformación criptográfica a los valores de datos sensibles originales. Cada valor sensible original se reemplaza por su token correspondiente. A veces, se hace referencia a la seudonimización como tokenización o reemplazo subrogado.
Las técnicas de seudonimización habilitan tokens unidireccionales o bidireccionales. Un token unidireccional se transformó de forma irreversible, mientras que un token bidireccional se puede revertir. Debido a que el token se crea mediante una encriptación simétrica, la misma clave criptográfica que puede generar tokens nuevos también puede revertir tokens. Para las situaciones en las que no necesitas reversibilidad, puedes usar tokens unidireccionales que usen mecanismos de hash seguros.
Resulta útil comprender cómo la seudonimización puede ayudar a proteger los datos sensibles y, al mismo tiempo, permitir que las operaciones de la empresa y los flujos de trabajo estadísticos accedan a los datos que necesitan. En este tema, se explora el concepto de seudonimización y los tres métodos criptográficos para transformar los datos que admite la Protección de datos sensibles.
Si deseas obtener instrucciones sobre cómo implementar estos métodos de seudonimización y ver más ejemplos de uso de Sensitive Data Protection, consulta Desidentifica datos sensibles.
Métodos criptográficos compatibles con Sensitive Data Protection
La Protección de datos sensibles admite tres técnicas de seudonimización, de las cuales todas usan claves criptográficas. Los siguientes son los métodos disponibles:
- Encriptación determinista mediante el uso de AES-SIV: Se reemplaza un valor de entrada por un valor encriptado mediante el algoritmo de encriptación AES-IVO con una clave criptográfica, codificada en Base64, y se la precede con una anotación subrogada, si se especifica. Mediante este método, se produce un valor con hash, de modo que no se conserva el grupo de caracteres o la longitud del valor de entrada. Los valores encriptados y con hash se pueden reidentificar mediante el uso de la clave criptográfica original y el valor de salida completo, incluida la anotación subrogada. Obtén más información sobre el formato de los valores con asignación de token mediante el uso de la encriptación AES-SIV.
- Encriptación de preservación de formato: Se reemplaza un valor de entrada por un valor encriptado mediante el algoritmo de encriptación FPE-FFX con una clave criptográfica y, luego, se lo precede con una anotación subrogada, si se especifica. Por diseño, tanto el grupo de caracteres como la longitud del valor de entrada se conservan en el valor de salida. Los valores encriptados se pueden reidentificar mediante el uso de la clave criptográfica original y el valor de salida completo, incluida la anotación subrogada. Para obtener algunas consideraciones importantes sobre el uso de este método de encriptación, consulta Encriptación de preservación de formato más adelante en este tema.
- Hashing criptográfico: Se reemplaza un valor de entrada por un valor que se encripto y se le generó un hash mediante el algoritmo de hash de autenticación segura de mensajes basados en hash (HMAC). (SHA)-256 en el valor de entrada con una clave criptográfica. La salida con hash de la transformación siempre tiene la misma longitud y no se puede reidentificar. Obtén más información sobre el formato de los valores con asignación de token mediante el hashing criptográfico.
Estos métodos de seudonimización se resumen en la siguiente tabla. Las filas de la tabla se explican después de la tabla.
| Encriptación determinista mediante AES-SIV | Encriptación de preservación de formato | Hashing criptográfico | |
|---|---|---|---|
| Tipo de encriptación | AES-SIV | FPE-FFX | HMAC-SHA-256 |
| Valores de entrada admitidos | Debe tener al menos 1 carácter de longitud, sin limitaciones de grupos de caracteres. | Debe tener al menos 2 caracteres de longitud y debe codificarse como ASCII. | Debe ser una string o un valor de número entero. |
| Anotación subrogada | Opcional. | Opcional. | N/A |
| Ajuste de contexto | Opcional. | Opcional. | N/A |
| Grupo de caracteres y longitud conservados | ✗ | ✓ | ✗ |
| Reversible | ✓ | ✓ | ✗ |
| Integridad referencial | ✓ | ✓ | ✓ |
- Tipo de encriptación: Es el tipo de encriptación que se usa en la transformación de desidentificación.
- Valores de entrada admitidos: Son los requisitos mínimos para los valores de entrada.
- Anotación subrogada: Es una anotación especificada por el usuario que se antepone a valores encriptados con el fin de proporcionar contexto a los usuarios y proporcionar información para que Sensitive Data Protection use en la reidentificación de un valor desidentificado. Se requiere una anotación subrogada para la reidentificación de datos no estructurados. Es opcional cuando se transforma una columna de datos estructurados o tabulares con una
RecordTransformation. - Ajuste de contexto: Es una referencia a un campo de datos que "ajusta" el valor de entrada para que los valores de entrada idénticos se puedan desidentificar con valores de salida diferentes. El ajuste de contexto es opcional cuando se transforma una columna de datos estructurados o tabulares con una
RecordTransformation. Para obtener más información, consulta Usa ajustes de contexto. - Conjunto de caracteres y longitud conservados: Si un valor desidentificado se compone del mismo conjunto de caracteres que el valor original y si la longitud del valor desidentificado coincide la del valor original.
- Reversible: Se puede reidentificar mediante el uso de la clave criptográfica, la anotación subrogada y cualquier ajuste de contexto.
- Integridad referencial: La integridad referencial permite que los registros mantengan la relación entre sí, incluso después de que se desidentifiquen sus datos de forma individual. Cuando se proporcione la misma clave criptográfica y el mismo ajuste de contexto, se reemplazará una tabla de datos por el mismo formulario ofuscado cada vez que se transforme, lo cual asegura que se preserven las conexiones entre valores (y entre registros y datos estructurados), incluso en las tablas.
Cómo funciona la tokenización en Sensitive Data Protection
El proceso básico de asignación de token es el mismo para los tres métodos que admite Sensitive Data Protection.
Paso 1: Sensitive Data Protection selecciona los datos a los cuales asignar tokens. La forma más común de hacerlo es usar un detector de Infotipo integrado o personalizado para hacer coincidir los valores de datos sensibles deseados. Si analisas datos estructurados (como una tabla de BigQuery), también puedes realizar la asignación de tokens en columnas completas de datos mediante transformaciones de registro.
Para obtener más información sobre las dos categorías de las transformaciones, de Infotipo y de registro, consulta Transformaciones de desidentificación.
Paso 2: Con una clave criptográfica, la Protección de datos sensibles encripta cada valor de entrada. Puedes proporcionar esta clave de tres maneras:
- Puedes unirla mediante Cloud Key Management Service (Cloud KMS). (Para obtener una mayor seguridad, Cloud KMS es el método preferido).
- Puedes usar una clave transitoria, que la Protección de datos sensibles genera en el momento de la desidentificación y que luego descarta. Una clave transitoria solo mantiene la integridad por solicitud a la API. Si necesitas integridad o planeas volver a identificar estos datos, no uses este tipo de clave.
- Puedes hacerlo directamente en formato de texto sin formato. (No recomendado)
Para obtener más detalles, consulta la sección Usa claves criptográficas más adelante en este tema.
Paso 3 (Hashing criptográfico y encriptación determinista con solo AES-SIV): La Protección de datos sensibles codifica el valor encriptado mediante Base64. Con el hashing criptográfico, este valor encriptado y codificado es el token, y el proceso continúa con el paso 6. Con la encriptación determinista mediante AES-SIV, este valor encriptado y codificado es el valor subrogado, que solo es un componente del token. El proceso continúa con el paso 4.
Paso 4 (encriptación determinista y de conservación de formato solo con AES-SIV): Sensitive Data Protection agrega una anotación subrogada opcional al valor encriptado. La anotación subrogada ayuda a identificar los valores subrogados encriptados mediante la preposición de una string descriptiva que defines. Por ejemplo, sin una anotación, es posible que no puedas distinguir un número de teléfono desidentificado de un número de seguridad social u otro número de identificación desidentificados. Además, para volver a identificar los valores en datos no estructurados que se desidentificaron mediante la encriptación de preservación de formato o la encriptación determinista, debes especificar una anotación subrogada. (Las anotaciones subrogadas no son necesarias cuando se transforma una columna de datos estructurados o tabulares con una RecordTransformation).
Paso 5 (encriptación determinista y de conservación de formato con AES-SIV solo de datos estructurados): Sensitive Data Protection puede usar un contexto opcional de otro campo para “ajustar” el token generado. Esto te permite cambiar el alcance del token. Por ejemplo, supón que tienes una base de datos de campañas de marketing que incluye direcciones de correo electrónico y deseas generar tokens únicos para la misma dirección de correo electrónico que “ajustó” el ID de la campaña. Esto permitiría que una persona una los datos del mismo usuario que están dentro de la misma campaña, pero no en las diferentes campañas. Si se usa un ajuste de contexto para crear el token, este ajuste de contexto también es necesario para que las transformaciones de desidentificación se reviertan. Formatea la encriptación determinista y de preservación mediante los contextos de asistencia de AES-SIV. Obtén más información sobre cómo usar los ajustes de contexto.
Paso 6: La Protección de datos sensibles reemplaza el valor original por el valor desidentificado.
Comparación de valores con asignación de tokens
En esta sección, se muestra cómo se ven los tokens típicos después de desidentificarlos mediante cada uno de los tres métodos mencionados en este tema. El valor de los datos sensibles de ejemplo es un número de teléfono de América del Norte (1-206-555-0123).
Encriptación determinista mediante AES-SIV
Con la desidentificación mediante la encriptación determinista y AES-SIV, se encripta un valor de entrada (y, de forma opcional, cualquier ajuste de contexto especificado) mediante AES-SIV con una clave criptográfica, codificada en Base64, y, de forma opcional, se le antepone una anotación subrogada, si se especifica. Mediante este método, no se conserva el conjunto de caracteres (o el "alfabeto") del valor de entrada. Para generar un resultado que se pueda imprimir, el valor resultante se codifica en Base64.
El token resultante, si suponemos que se especificó un Infotipo subrogado, tiene el siguiente formato:
SURROGATE_INFOTYPE(SURROGATE_VALUE_LENGTH):SURROGATE_VALUE
En el siguiente diagrama anotado, se muestra un token de ejemplo, que es el resultado de una operación de desidentificación mediante la encriptación determinista con AES-SIV en el valor 1-206-555-0123. El Infotipo subrogado opcional se configuró como NAM_PHONE_NUMB:

- Anotación subrogada
- Infotipo subrogado (que define el usuario)
- Longitud de caracteres del valor transformado
- Valor subrogado (transformado)
Si no especificas una anotación subrogada, el token resultante es igual al valor transformado o al valor 4 del diagrama anotado. Para volver a identificar datos no estructurados, se necesita todo el token, incluida la anotación subrogada. Cuando se transforman datos estructurados, como una tabla, la anotación subrogada es opcional. Sensitive Data Protection puede realizar la desidentificación y la reidentificación en una columna completa mediante una RecordTransformation sin una anotación subrogada.
Encriptación de preservación de formato
Con la desidentificación mediante la encriptación de preservación de formato, se encripta un valor de entrada (y, de forma opcional, cualquier ajuste de contexto especificado) mediante el modo de FFX de la encriptación de preservación de formato ("FPE-FFX") con una clave criptográfica y, de forma opcional, se le antepone una anotación subrogada, si se especifica.
A diferencia de en los otros métodos de asignación de tokens descritos en este tema, el valor subrogado de salida tiene la misma longitud que el valor de entrada y no se codifica mediante Base64. Debes definir el conjunto de caracteres (o “alfabeto”) que conforma el valor encriptado. Existen tres maneras de especificar el alfabeto para que Sensitive Data Protection lo use en el valor de salida:
- Usa uno de los cuatro valores enumerados que representan los cuatro grupos de caracteres o alfabetos más comunes.
- Usa un valor de Radix, que especifica el tamaño del alfabeto. Si especificas el valor mínimo de Radix de
2, se genera un alfabeto que consta solo de0y1. Cuando especificas el valor máximo de Radix de95, se genera un alfabeto que incluye todos los caracteres numéricos, los caracteres alfanuméricos en mayúscula y minúscula y los caracteres de símbolos. - Para compilar un alfabeto, enumera los caracteres exactos que se deben usar. Por ejemplo, si especificas
1234567890-*, se generaría un valor subrogado que solo esta compuesto por números, guiones y asteriscos.
En la siguiente tabla, se enumeran cuatro grupos de caracteres comunes según el valor enumerado de cada uno (FfxCommonNativeAlphabet), el valor de Radix y la lista de caracteres del conjunto. En la fila final, se enumera el conjunto de caracteres completo, que corresponde al valor máximo de Radix.
| Nombre del conjunto de caracteres o el alfabeto | Radix | Lista de caracteres |
|---|---|---|
NUMERIC |
10 |
0123456789 |
HEXADECIMAL |
16 |
0123456789ABCDEF |
UPPER_CASE_ALPHA_NUMERIC |
36 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ |
ALPHA_NUMERIC |
62 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz |
| - | 95 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz~`!@#$%^&*()_-+={[}]|\:;"'<,>.?/ |
El token resultante, si suponemos que se especificó un Infotipo subrogado, tiene el siguiente formato:
SURROGATE_INFOTYPE(SURROGATE_VALUE_LENGTH):SURROGATE_VALUE
El siguiente diagrama anotado es el resultado de una operación de desidentificación de Sensitive Data Protection mediante una encriptación de preservación de formato en el valor 1-206-555-0123 con un Radix de 95. El Infotipo subrogado opcional se configuró como NAM_PHONE_NUMB:
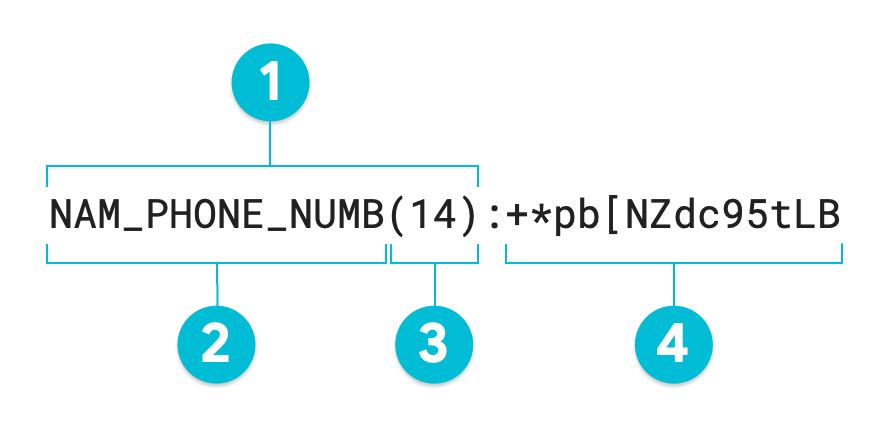
- Anotación subrogada
- Infotipo subrogado (que define el usuario)
- Longitud de caracteres del valor transformado
- Valor subrogado (transformado), con la misma longitud que el valor de entrada
Si no especificas una anotación subrogada, el token resultante es igual al valor transformado o al valor 4 del diagrama anotado. Para volver a identificar datos no estructurados, se necesita todo el token, incluida la anotación subrogada. Cuando se transforman datos estructurados, como una tabla, la anotación subrogada es opcional. Sensitive Data Protection puede realizar la desidentificación y la reidentificación en una columna completa mediante una RecordTransformation sin un subrogado.
Hashing criptográfico
Con la desidentificación mediante el hashing criptográfico, a un valor de entrada se le genera un hash mediante HMAC-SHA-256 con una clave criptográfica y, luego, se lo codifica a través de Base64. El valor desidentificado siempre es una longitud uniforme, en función del tamaño de la clave.
A diferencia de los otros métodos de asignación de tokens que se analizan en este tema, el hashing criptográfico crea un token unidireccional. Es decir, la desidentificación mediante el hashing criptográfico no se puede revertir.
A continuación, se muestra el resultado de una operación de desidentificación mediante el uso del hashing criptográfico en el valor 1-206-555-0123. Este resultado es una representación codificada en Base64 del valor con hash:
XlTCv8h0GwrCZK+sS0T3Z8txByqnLLkkF4+TviXfeZY=
Usa claves criptográficas
Existen tres opciones para las claves criptográficas que puedes usar con los métodos de desidentificación criptográfica en la Protección de datos sensibles:
Clave criptográfica unida de Cloud KMS: Este es el tipo de clave criptográfica más seguro disponible para usar con los métodos de desidentificación de la Protección de datos sensibles. Una clave unida de Cloud KMS consta de una clave criptográfica de 128, 192 o 256 bits que se encriptó mediante el uso de otra clave. Debes proporcionar la primera clave criptográfica, que luego se une mediante una clave criptográfica almacenada en Cloud Key Management Service. Estos tipos de claves se almacenan en Cloud KMS para su reidentificación posterior. Consulta Guía de inicio rápido: desidentifica y reidentifica texto sensible a fin de obtener más información a fin de crear y unir una clave para la desidentificación y la reidentificación.
Clave criptográfica transitoria: La Protección de datos sensibles genera una clave criptográfica transitoria en el momento de la desidentificación y, luego, la descarta. Por este motivo, no uses una clave criptográfica transitoria con ningún método de desidentificación criptográfica que desees revertir. Las claves criptográficas transitorias solo mantienen la integridad por solicitud a la API. Si necesitas integridad en más de una solicitud a la API o planeas volver a identificar los datos, no uses este tipo de clave.
Clave criptográfica separada: Una clave separada es una clave criptográfica sin formato basada en Base64 de 128, 192 o 256 bits que proporcionas dentro de la solicitud de desidentificación a la API de DLP. Eres responsable de mantener estos tipos de claves criptográficas seguras para su identificación posterior. Debido al riesgo de filtrar la clave por accidente, no se recomiendan estos tipos de claves. Estas claves pueden ser útiles para las pruebas, pero para las cargas de trabajo de producción se recomienda una clave criptográfica unida de Cloud KMS en su lugar.
Para obtener más información sobre las opciones disponibles cuando se usan claves criptográficas, consulta CryptoKey en la referencia de la API de DLP.
Usa ajustes de contexto
De forma predeterminada, todos los métodos de transformación criptográfica de desidentificación tienen integridad referencial, ya sea que los tokens de salida sean unidireccionales o bidireccionales. Es decir, si se proporciona la misma clave criptográfica, un valor de entrada siempre se transforma en el mismo valor encriptado. En situaciones en las que pueden ocurrir patrones de datos o datos repetitivos, aumenta el riesgo de reidentificación. En cambio, para hacerlo de modo que el mismo valor de entrada siempre se transforme en un valor encriptado diferente, puedes especificar un ajuste de contexto único.
Debes especificar un ajuste de contexto (llamado simplemente context en la API de DLP) cuando transformas datos tabulares, ya que el ajuste es, de hecho, un puntero a una columna de datos, como un identificador.
Sensitive Data Protection usa el valor en el campo especificado por el ajuste de contexto cuando se encripta el valor de entrada. A fin de garantizar que el valor encriptado siempre sea un valor único, debes especificar una columna para el ajuste que contiene identificadores únicos.
Considera este ejemplo simple. En la siguiente tabla, se muestran varios registros médicos, algunos de los cuales incluyen ID de pacientes duplicados.
| record_id | patient_id | icd10_code |
|---|---|---|
| 5437 | 43789 | E11.9 |
| 5438 | 43671 | M25.531 |
| 5439 | 43789 | N39.0, I25.710 |
| 5440 | 43766 | I10 |
| 5441 | 43766 | I10 |
| 5442 | 42989 | R07.81 |
| 5443 | 43098 | I50.1, R55 |
| … | … | … |
Si le indicas a la Protección de datos sensibles que desidentifique los IDs de pacientes en la tabla, desidentifica los IDs de pacientes repetidos con los mismos valores de forma predeterminada, como se muestra en la siguiente tabla. Por ejemplo, ambas instancias del ID de paciente “43789” se desidentifican como “47222”. En la columna patient_id, se muestran los valores de token después de la seudonimización mediante FPE-FFX y no incluyen anotaciones subrogadas. Para obtener más información, consulta Formatea la encriptación de preservación.
| record_id | patient_id | icd10_codes |
|---|---|---|
| 5437 | 47222 | E11.9 |
| 5438 | 82160 | M25.531 |
| 5439 | 47222 | N39.0, I25.710 |
| 5440 | 04452 | I10 |
| 5441 | 04452 | I10 |
| 5442 | 47826 | R07.81 |
| 5443 | 52428 | I50.1, R55 |
| … | … | … |
Esto significa que el alcance de la integridad referencial abarca todo el conjunto de datos.
Para limitar el alcance de modo que evites este comportamiento, especifica un ajuste de contexto. Puedes especificar cualquier columna como un ajuste de contexto, pero para garantizar que cada valor desidentificado sea único, debes especificar una columna para la que cada valor sea único.
Supongamos que deseas ver si el mismo paciente aparece en cada valor icd10_codes, pero no deseas ver si el mismo paciente aparece en valores icd10_codes diferentes. Para ello, debes especificar la columna icd10_codes como el ajuste de contexto.
Esta es la tabla después de desidentificar la columna patient_id mediante el uso de la columna icd10_codes como un ajuste de contexto:
| record_id | patient_id | icd10_codes |
|---|---|---|
| 5437 | 18954 | E11.9 |
| 5438 | 33068 | M25.531 |
| 5439 | 76368 | N39.0, I25.710 |
| 5440 | 29460 | I10 |
| 5441 | 29460 | I10 |
| 5442 | 23877 | R07.81 |
| 5443 | 96129 | I50.1, R55 |
| … | … | … |
Ten en cuenta que el cuarto y el quinto de los valores desidentificados patient_id (29460) son iguales, ya que los valores patient_id originales eran idénticos y los valores icd10_codes de ambas filas también eran idénticos. Debido a que necesitabas ejecutar un análisis con ID de pacientes coherentes dentro del alcance del valor icd10_codes, este comportamiento es el que buscas.
Para romper la integridad referencial completa entre valores patient_id y valores icd10_codes, puedes usar la columna record_id como un ajuste de contexto en su lugar:
| record_id | patient_id | icd10_code |
|---|---|---|
| 5437 | 15826 | E11.9 |
| 5438 | 61722 | M25.531 |
| 5439 | 34424 | N39.0, I25.710 |
| 5440 | 02875 | I10 |
| 5441 | 52549 | I10 |
| 5442 | 17945 | R07.81 |
| 5443 | 19030 | I50.1, R55 |
| … | … | … |
Ten en cuenta que cada valor patient_id desidentificado de la tabla ahora es único.
Para aprender a usar ajustes de contexto en la API de DLP, ten en cuenta el uso de context en los siguientes temas de referencia de métodos de transformación:
- Encriptación de preservación de formato:
CryptoReplaceFfxFpeConfig - Encriptación determinista mediante AES-SIV:
CryptoDeterministicConfig - Cambio de fechas:
DateShiftConfig
¿Qué sigue?
Revisa las muestras de código que demuestran cómo asignar tokens a los datos sensibles.
Obtén información para desidentificar datos con la API de DLP.