Questa pagina descrive e mette a confronto due servizi Sensitive Data Protection che ti aiutano a comprendere i tuoi dati e a abilitare i flussi di lavoro di governance dei dati: il servizio di rilevamento e il servizio di ispezione.
Rilevamento di dati sensibili
Il servizio di rilevamento monitora i dati dell'intera organizzazione. Questo servizio viene eseguito in modo continuo e automatico e rileva, classifica e profila i dati. La scoperta può aiutarti a comprendere la posizione e la natura dei dati che stai archiviando, incluse le risorse di dati di cui potresti non essere a conoscenza. I dati sconosciuti (a volte chiamati dati in ombra) typically don't undergo the same level of data governance and risk management as known data.
La scoperta viene configurata in vari ambiti. Puoi impostare pianificazioni di profilazione diverse per sottoinsiemi diversi di dati. Puoi anche escludere sottoinsiemi di dati di cui non è necessario creare un profilo.
Output della scansione di Discovery: profili di dati
L'output di un'analisi di rilevamento è un insieme di profili di dati per ogni risorsa dati nell'ambito. Ad esempio, una scansione di rilevamento dei dati di BigQuery o Cloud SQL genera profili di dati a livello di progetto, tabella e colonna.
Un profilo dati contiene metriche e approfondimenti sulla risorsa profilata. Include le classificazioni dei dati (o infoType), i livelli di sensibilità, i livelli di rischio dei dati, le dimensioni dei dati, la forma dei dati e altri elementi che descrivono la natura dei dati e la relativa posizione in termini di sicurezza dei dati (ovvero il livello di sicurezza dei dati). Puoi utilizzare i profili dei dati per prendere decisioni consapevoli su come proteggere i tuoi dati, ad esempio impostando i criteri di accesso nella tabella.
Considera una colonna BigQuery denominata ccn, in cui ogni riga contiene un
numero di carta di credito univoco e non sono presenti valori null. Il profilo dei dati a livello di colonna generato avrà i seguenti dettagli:
| Nome visualizzato | Valore |
|---|---|
Field ID |
ccn |
Data risk |
High |
Sensitivity |
High |
Data type |
TYPE_STRING |
Policy tags |
No |
Free text score |
0 |
Estimated uniqueness |
High |
Estimated null proportion |
Very low |
Last profile generated |
DATE_TIME |
Predicted infoType |
CREDIT_CARD_NUMBER |
Inoltre, questo profilo a livello di colonna fa parte di un profilo a livello di tabella, che fornisce informazioni come la posizione dei dati, lo stato della crittografia e se la tabella è condivisa pubblicamente. Nella console Google Cloud, puoi anche visualizzare le voci di Cloud Logging per la tabella, gli entità IAM con i ruoli per la tabella e i tag Dataplex associati alla tabella.
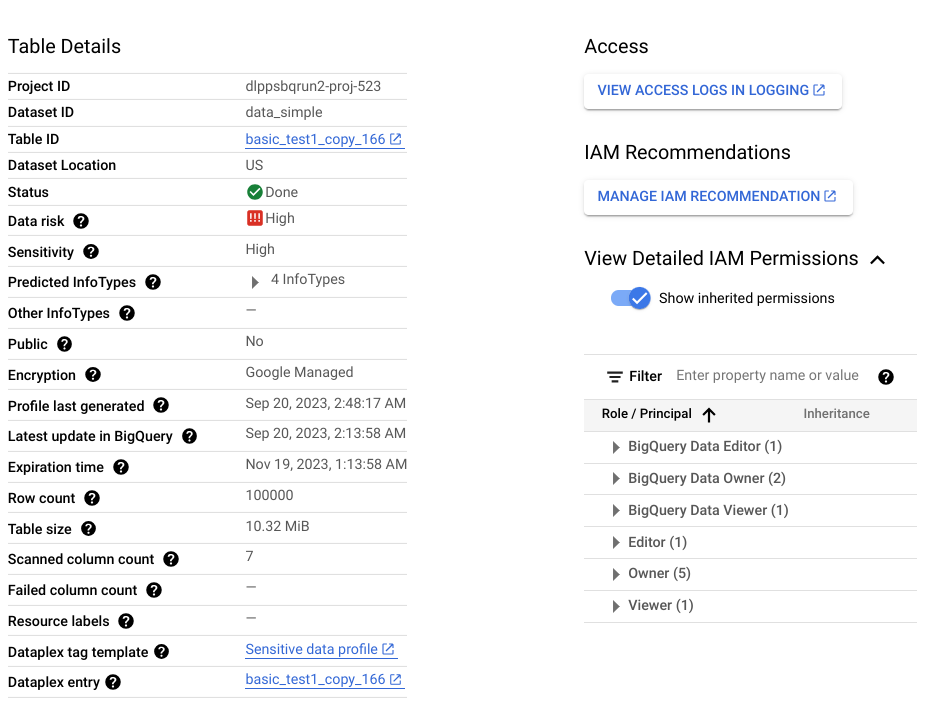
Per un elenco completo delle metriche e degli approfondimenti disponibili nei profili dei dati, consulta la documentazione di riferimento sulle metriche.
Quando utilizzare il rilevamento
Quando pianifichi il tuo approccio alla gestione del rischio dei dati, ti consigliamo di iniziare con la scoperta. Il servizio di rilevamento ti aiuta a ottenere una visione ampia dei tuoi dati e a attivare avvisi, report e correzione dei problemi.
Inoltre, il servizio di rilevamento può aiutarti a identificare le risorse dove potrebbero trovarsi i dati non strutturati. Queste risorse potrebbero richiedere un'indagine approfondita. I dati non strutturati sono specificati da un punteggio del testo libero elevato su una scala da 0 a 1.
Ispezione dei dati sensibili
Il servizio di ispezione esegue una scansione completa di una singola risorsa per individuare ogni singola istanza di dati sensibili. Un'ispezione genera un risultato per ogni istanza rilevata.
I job di ispezione forniscono un ampio insieme di opzioni di configurazione per aiutarti a individuare i dati che vuoi ispezionare. Ad esempio, puoi attivare il campionamento per limitare i dati da ispezionare a un determinato numero di righe (per i dati di BigQuery) o a determinati tipi di file (per i dati di Cloud Storage). Puoi anche scegliere come target un periodo di tempo specifico in cui i dati sono stati creati o modificati.
A differenza della scoperta, che monitora continuamente i dati, un'ispezione è un'operazione on demand. Tuttavia, puoi pianificare job di ispezione ricorrenti chiamati attivatori di job.
Output della scansione di ispezione: risultati
Ogni risultato include dettagli come la posizione dell'istanza rilevata, il suo potenziale infoType e la certezza (chiamata anche probabilità) che il risultato corrisponda all'infoType. A seconda delle impostazioni, puoi anche ottenere la stringa effettiva a cui si riferisce il rilevamento. Questa stringa è chiamata citazione in Sensitive Data Protection.
Per un elenco completo dei dettagli inclusi in un rilievo dell'ispezione, consulta
Finding.
Quando utilizzare l'ispezione
Un'ispezione è utile quando devi esaminare dati non strutturati (come commenti o recensioni creati dagli utenti) e identificare ogni istanza di informazioni che consentono l'identificazione personale (PII). Se una ricerca di risorse identifica risorse contenenti dati non strutturati, ti consigliamo di eseguire una ricerca di ispezione su queste risorse per ottenere i dettagli su ogni singola scoperta.
Quando non utilizzare l'ispezione
L'ispezione di una risorsa non è utile se si applicano entrambe le seguenti condizioni. Una scansione di rilevamento può aiutarti a decidere se è necessaria una scansione di ispezione.
- La risorsa contiene solo dati strutturati. In altre parole, non sono presenti colonne di dati in formato libero, come commenti o recensioni degli utenti.
- Conosci già gli infoType archiviati nella risorsa.
Ad esempio, supponiamo che i profili dei dati di una scansione di rilevamento indichino che una determinata tabella BigQuery non abbia colonne con dati non strutturati, ma abbia una colonna di numeri di carte di credito univoci. In questo caso, non è utile controllare la presenza di numeri di carte di credito nella tabella. Un'ispezione produrrà un
risultato per ogni elemento della colonna. Se hai un milione di righe e ogni riga contiene un numero di carta di credito, un job di ispezione produrrà un milione di risultati per l'infoType CREDIT_CARD_NUMBER. In questo esempio, l'ispezione non è necessaria perché la ricerca di elementi indica già che la colonna contiene numeri di carte di credito univoci.
Localizzazione, elaborazione e archiviazione dei dati
Sia il rilevamento che l'ispezione supportano i requisiti di residenza dei dati:
- Il servizio di rilevamento elabora i dati dove si trovano e archivia i profili di dati generati nella stessa regione o area multiregionale dei dati profilati. Per ulteriori informazioni, consulta Considerazioni sulla residenza dei dati.
- Quando ispezioni i dati all'interno di un sistema di archiviazione Google Cloud, il servizio di ispezione elabora i dati nella stessa regione in cui si trovano e archivia il job di ispezione in quella regione. Quando ispezioni i dati tramite un job ibrido o un metodo
content, il servizio di ispezione ti consente di specificare dove elaborare i dati. Per ulteriori informazioni, consulta la pagina Come vengono memorizzati i dati.
Riepilogo del confronto: servizi di rilevamento e ispezione
| Discovery | Ispezione | |
|---|---|---|
| Vantaggi |
|
|
| Costo |
10 TB costano circa 300$al mese in modalità a consumo. |
10 TB costano circa 10.000$per scansione. |
| Origini dati supportate | BigLake BigQuery Variabili di ambiente delle funzioni Cloud Run Variabili di ambiente della revisione del servizio Cloud Run Cloud SQL Cloud Storage Vertex AI (anteprima) Amazon S3 |
BigQuery Cloud Storage Datastore Ibrida (qualsiasi origine)1 |
| Ambiti supportati |
|
Una singola tabella BigQuery, un bucket Cloud Storage o un tipo di Datastore. |
| Modelli di ispezione integrati | Sì | Sì |
| InfoType integrati e personalizzati | Sì | Sì |
| Output scansione | Panoramica generale (profili di dati) di tutti i dati supportati. | Risultati concreti del rilevamento di dati sensibili nella risorsa ispezionata. |
| Salva i risultati in BigQuery | Sì | Sì |
| Invia a Dataplex come tag | Sì | Sì |
| Pubblicare i risultati in Security Command Center | Sì | Sì |
| Pubblica i risultati in Google Security Operations | Sì per la scoperta a livello di organizzazione e di cartella | No |
| Pubblica in Pub/Sub | Sì | Sì |
| Supporto della residenza dei dati | Sì | Sì |
1 L'ispezione ibrida ha un modello di prezzi diverso. Per ulteriori informazioni, vedi Ispezione dei dati da qualsiasi origine .
Passaggi successivi
- Esplora le strategie consigliate per ridurre il rischio associato ai dati (documento successivo di questa serie)