一部のエンティティは特定の用語ではなくパターンと照合する必要があります。たとえば、国識別番号、ID、ナンバー プレートなどです。正規表現エンティティを使用すると、正規表現のマッチングを行うことができます。
このデータがある場所
エージェントを作成する際は、Dialogflow ES コンソール(ドキュメントに移動、コンソールを開く)を使用するのが最も一般的です。コンソールの使用方法は次のとおりです。エンティティ データにアクセスするには:
- Dialogflow ES コンソールに移動します。
- エージェントを選択します。
- 左側のサイドバーのメニューで [Entities] を選択します。
コンソールではなく API を使用してエージェントを作成する場合は、EntityTypes リファレンスをご覧ください。API のフィールド名はコンソールのフィールド名と同様です。以下の手順では、コンソールと API の間の重要な違いを説明します。
複合正規表現
各正規表現エンティティは 1 つのパターンに対応しますが、複数の正規表現を指定して、1 つのパターンの変化形を表すこともできます。エージェントのトレーニングでは、1 つのエンティティのすべての正規表現が、代替演算子(|)と結合されて複合正規表現を形成します。
たとえば、電話番号に次の正規表現を指定したとします。
^[2-9]\d{2}-\d{3}-\d{4}$^(1?(-?\d{3})-?)?(\d{3})(-?\d{4})$
複合正規表現は次のようになります。
^[2-9]\d{2}-\d{3}-\d{4}$|^(1?(-?\d{3})-?)?(\d{3})(-?\d{4})$
正規表現では順序が重要です。複合正規表現の各正規表現は、順序に従って処理されます。検索は、有効な一致が見つかると停止します。たとえば、「Seattle」というエンドユーザー表現の場合、次のようになります。
Sea|Seattleの場合は、「Sea」に一致することになるSeattle|Seaの場合は「Seattle」に一致することになる
音声認識の特殊な処理
エージェントが音声認識(音声入力、STT とも呼ばれる)を使用している場合は、正規表現で文字と数字を照合させる際に特殊な処理が必要になります。話者のエンドユーザーの発話は、エンティティとの照合前に、最初に音声認識装置によって処理されます。発話に一連の文字や数字が含まれている場合、認識装置によって文字ごとにスペースが埋め込まれる場合があります。さらに、この装置では単語の形で数字を解釈することもありますたとえば、「My ID is 123」というエンドユーザーの発話は、次のように認識されます。
- 「私の ID は 123 です」
- 「私の ID は 1 2 3 です」
- 「私の ID はワンツースリーです」
3 桁の数字に対応するには、次の正規表現を使用します。
\d{3}\d \d \d
(zero|one|two|three|four|five|six|seven|eight|nine) (zero|one|two|three|four|five|six|seven|eight|nine) (zero|one|two|three|four|five|six|seven|eight|nine)
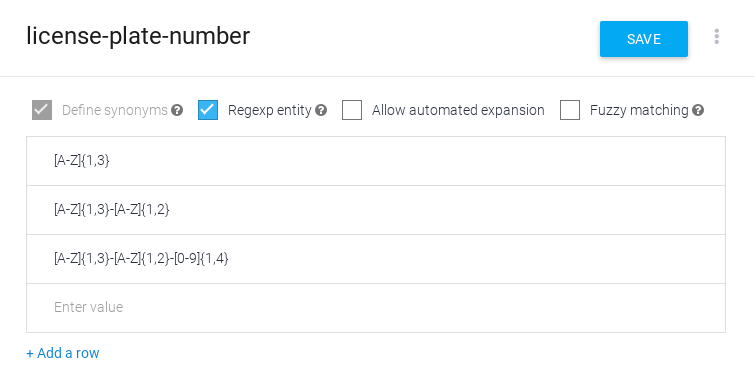
正規表現エンティティを作成する
正規表現エンティティを作成するには、次の手順を行います。
- 既存のエンティティを開くか、新しいエンティティを作成します。
- Regexp entity を確認します。
- entries テーブルに 1 つ以上の正規表現を入力します。
- [保存] をクリックします。
API を使用してエンティティを作成または更新する場合は、entity kind フィールドに KIND_REGEXP を使用します。
制限事項
次の制限が適用されます。
- 正規表現エンティティでファジー一致有効にはできません。これらの機能は相互排他的です。
- 各エージェントには最大 50 個の正規表現エンティティを設定できます。
- 1 つのエンティティの複合正規表現の最大長は 2,000 文字です。