O Cloud Monitoring coleta métricas, eventos e metadados de produtos do Google Cloud. Com o Cloud Monitoring, você também pode configurar painéis e alertas de uso personalizados.
Este documento orienta você sobre o uso de métricas, ensina sobre o painel de métricas personalizadas e como definir alertas.
Recursos monitorados
Um recurso monitorado no Cloud Monitoring representa uma entidade lógica ou física, como uma máquina virtual, um banco de dados ou um aplicativo. Os recursos monitorados contêm um conjunto exclusivo de métricas que podem ser analisadas, relatadas em um painel ou usadas para criar alertas. Cada recurso também tem um conjunto de rótulos, que são pares de chave-valor que contêm informações adicionais sobre o recurso. Os rótulos de recursos estão disponíveis para todas as métricas associadas ao recurso.
Usando a API Cloud Monitoring, o desempenho do Firestore no modo Datastore é monitorado com os seguintes recursos:
| Recursos | Descrição | Modo de banco de dados com suporte |
firestore.googleapis.com/Database (recomendado) | Tipo de recurso
monitorado que fornece detalhes sobre project,
location* e database_id . O rótulo database_id será (default) para bancos de dados criados sem um nome específico. | Todas as métricas com suporte para os dois modos,
exceto as seguintes que não têm suporte para o Firestore no
modo Datastore:
|
datastore_request | Tipo de recurso monitorado para projetos do Datastore e não fornece detalhes sobre bancos de dados. |
Métricas
O Firestore está disponível em dois modos diferentes: Firestore nativo e Firestore no modo Datastore. Para uma comparação de recursos entre esses dois modos, consulte Escolher entre os modos de banco de dados.
Para uma lista completa de métricas do Firestore no modo Datastore, consulte Métricas do Firestore no Datastore.
Métricas de execução do serviço
As métricas serviceruntime
oferecem uma visão geral de alto nível do tráfego de um projeto. Essas métricas estão
disponíveis para a maioria das APIs do Google Cloud. O tipo de recurso monitorado
consumed_api
contém essas métricas comuns. Essas métricas são coletadas
a cada 30 minutos, o que resulta em dados suavizados.
Um rótulo de recurso importante para as métricas serviceruntime é method. Esse rótulo
representa o método RPC subjacente chamado. O método do SDK chamado pode não
necessariamente ter o mesmo nome que o método RPC subjacente. O motivo é
que o SDK oferece abstração de API de alto nível. No entanto, ao tentar
entender como o aplicativo interage com o Firestore, é
importante entender as métricas com base no nome do método de RPC.
Se você precisar saber qual é o método RPC subjacente para um determinado método do SDK, consulte a documentação da API.
api/request_count
Essa métrica fornece a contagem de solicitações concluídas, em todo o protocolo(protocolo de solicitação, como HTTP, gRPC etc.),
código de resposta (código de resposta HTTP), response_code_class (classe de código de resposta, como 2xx, 4xx etc.) e grpc_status_code (código de resposta gRPC numérico). Use essa métrica para
observar a solicitação geral da API e calcular a taxa de erros.
Na Figura 1, é possível ver as solicitações que retornam um código 2xx agrupadas por serviço e método. Os códigos 2xx são códigos de status HTTP que indicam que a solicitação foi concluída.
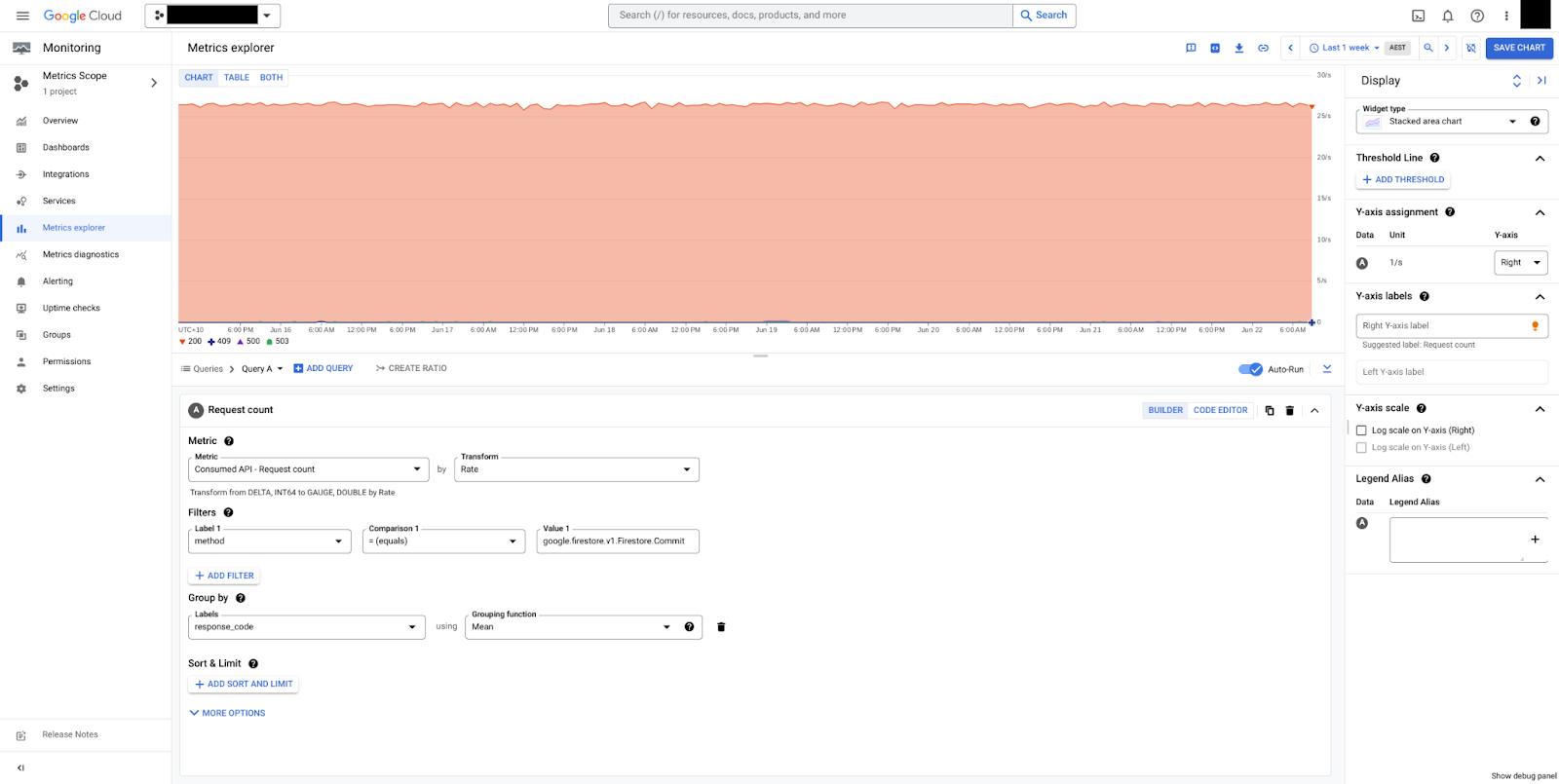
Na Figura 2, é possível ver as confirmações agrupadas por response_code. Neste exemplo, só aparecem respostas HTTP 200, o que implica que o banco de dados está em bom estado.
Use as seguintes métricas de execução do serviço para monitorar seu banco de dados.
api/request_count no tipo de recurso datastore_request
A métrica api/request_count também está disponível no tipo de recurso datastore_request
com detalhamentos api_method e response_code. Use essa métrica
para aproveitar o período de amostragem mais preciso, que ajuda a detectar
picos.

api/request_latencies
A métrica api/request_latencies fornece distribuições de latência em todas as solicitações concluídas.
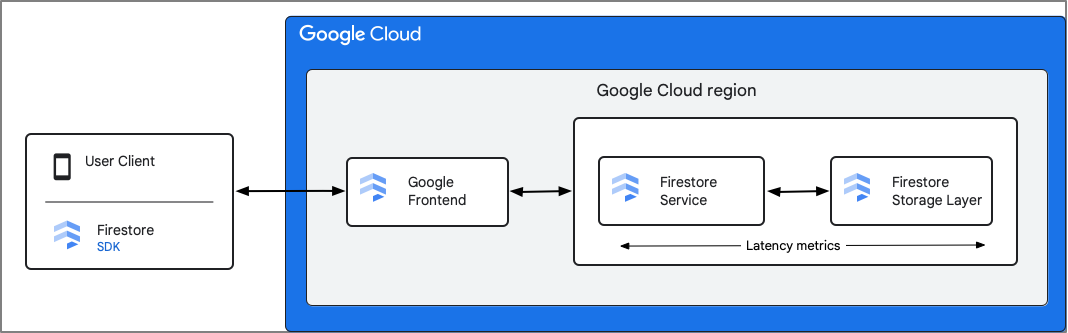
O Firestore registra métricas do componente Serviço do Firestore. As métricas de latência incluem o tempo que o Firestore leva para receber a solicitação até o momento em que ele termina de enviar a resposta, incluindo interações com a camada de armazenamento. Por isso, a latência de ida e volta (rtt, na sigla em inglês) entre o cliente e o serviço do Firestore não está incluída nessas métricas.
api/request_sizes e api/response_sizes
As métricas api/request_sizes e api/response_sizes fornecem insights sobre os tamanhos de payload (em bytes). Elas podem ser úteis para entender
cargas de trabalho de gravação que enviam grandes quantidades de dados ou consultas muito amplas
e retornam payloads grandes.
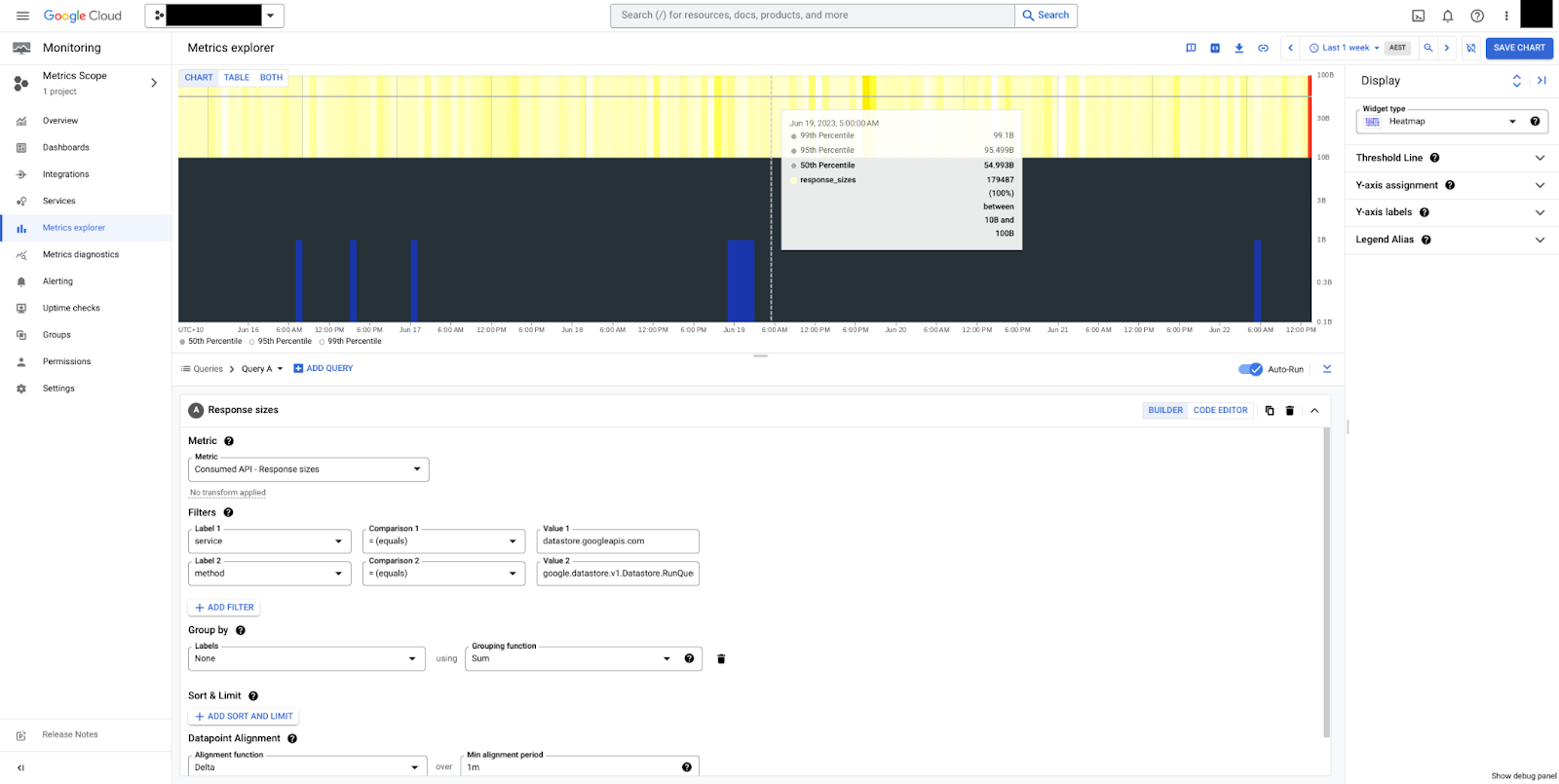
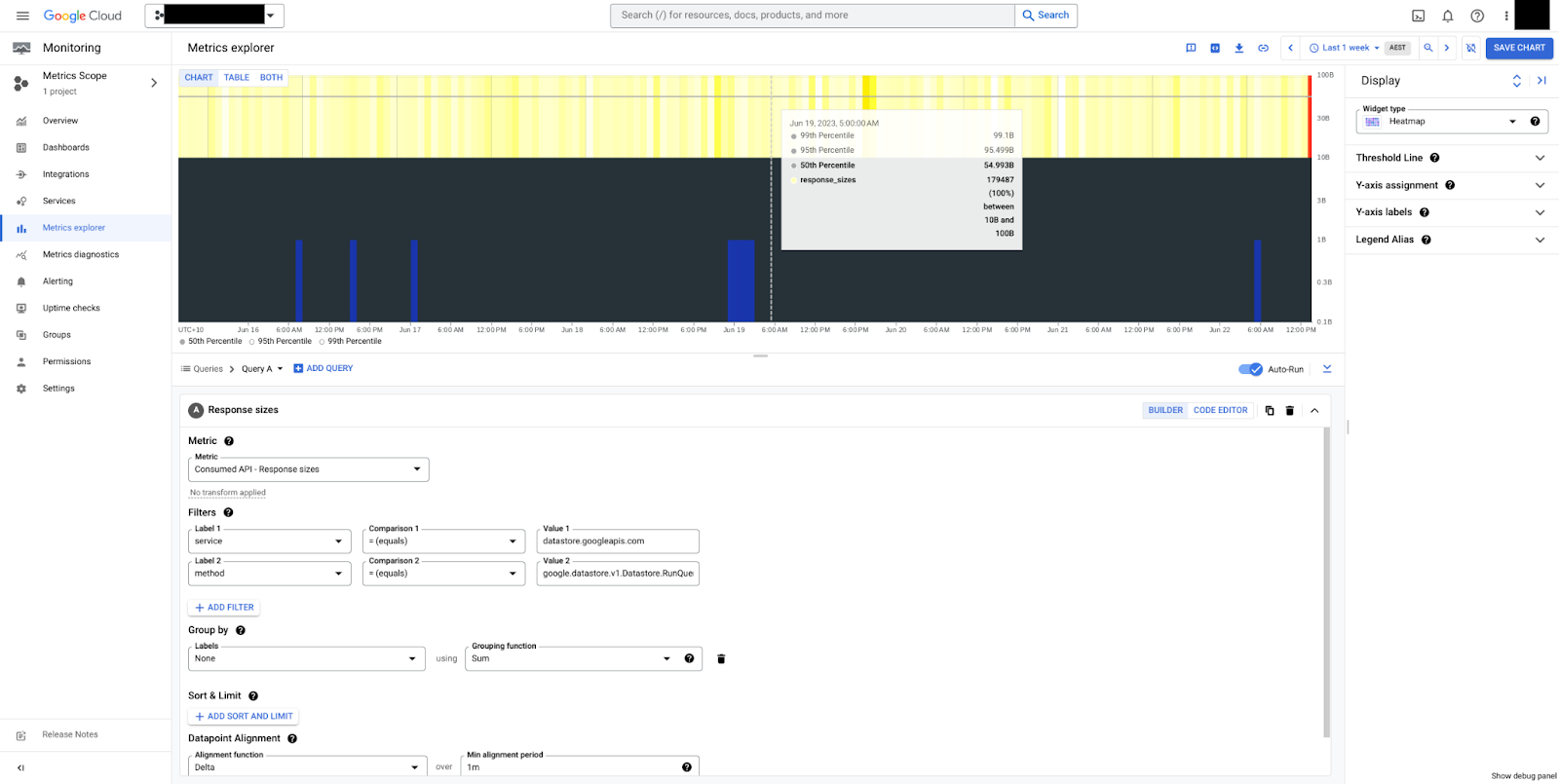
Na Figura 5, é possível ver um mapa de calor para os tamanhos de resposta do método RunQuery.
Os tamanhos são estáveis, com uma média de 50 bytes e um total de 10 a 100 bytes. Os tamanhos de payload são sempre medidos em bytes
não compactados, sem sobrecargas de controle de transmissão.
Métricas de operação de entidade
Essas métricas fornecem distribuições em bytes de tamanhos de payload para leituras (pesquisas e consultas) e gravações em um banco de dados do Firestore. Os valores representam
o tamanho total do payload. Por exemplo, qualquer resultado retornado por uma consulta.
Essas métricas são semelhantes às api/request_sizes e api/response_sizes,
mas a principal diferença é que as métricas de operação de entidade fornecem uma amostragem mais detalhada, mas menos detalhada.
Por exemplo, as métricas de operação de entidade usam o recurso monitorado datastore_request
para que não haja uma falha de serviço ou método.
entity/read_sizes: distribuição dos tamanhos das entidades lidas, agrupadas por tipo.entity/write_sizes: distribuição de tamanhos de entidades gravadas, agrupadas por operações.
Métricas de índice
As taxas de gravação de índice podem ser comparadas com a métrica document/write_ops_count
para entender a proporção de fanout
de índice.
index/write_count: contagem de gravações de índice.
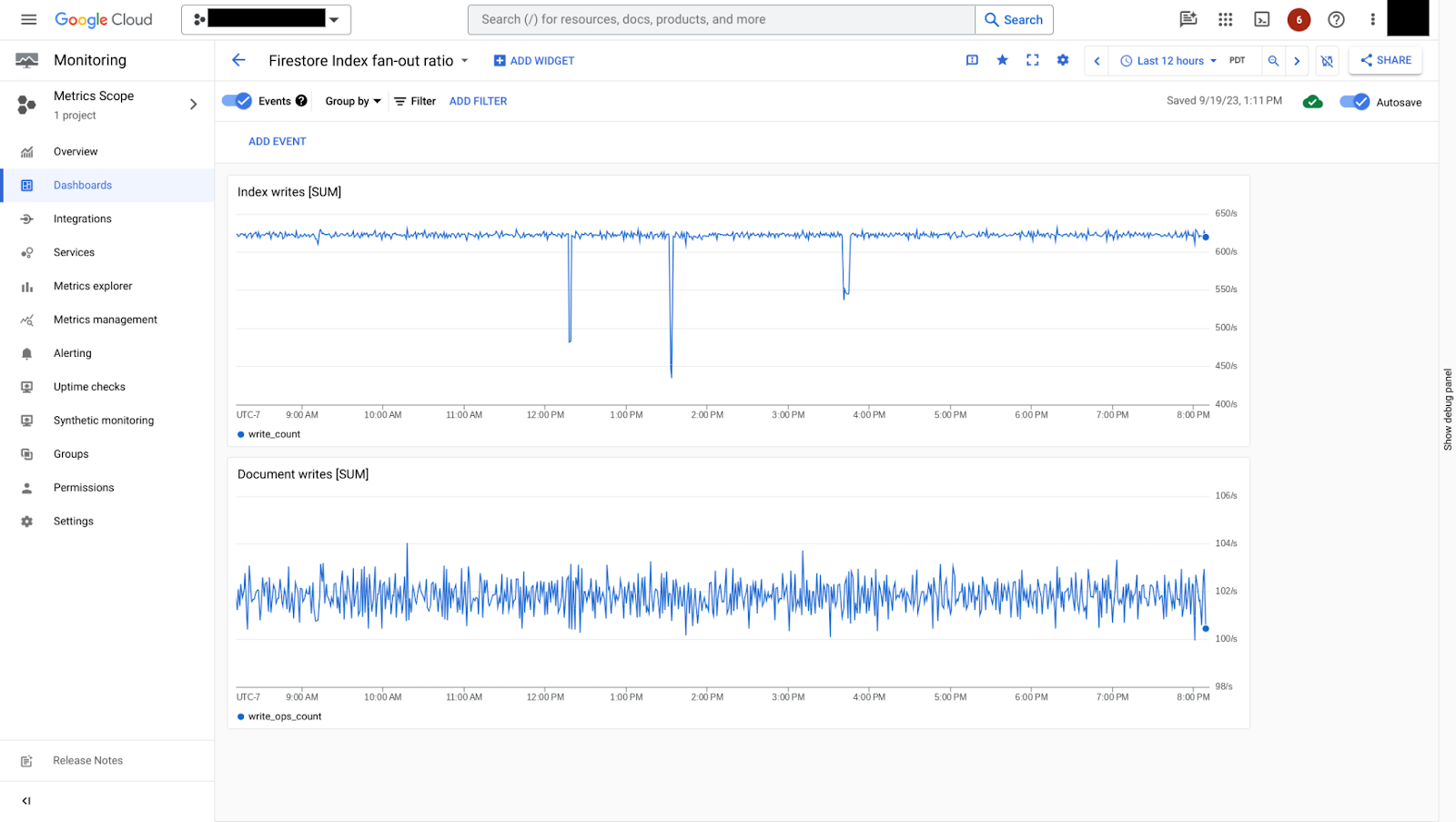
Na Figura 7, é possível ver como a taxa de gravação de índice pode ser contrastada com a taxa de gravação de documento. Nesse exemplo, para cada gravação de documento, há aproximadamente 6 gravações de índice, o que é uma taxa de fanout de índice relativamente pequena.
Métricas de TTL
As métricas de TTL estão disponíveis para o Firestore Nativo e para o Firestore em bancos de dados no modo Datastore. Use essas métricas para monitorar o efeito da política de TTL aplicada.
entity/ttl_deletion_count: contagem total de entidades excluídas pelos serviços de TTL.entity/ttl_expiration_to_deletion_delays: tempo decorrido entre a expiração de uma entidade com um TTL e o momento em que ela foi excluída.Se os atrasos na exclusão do TTL estiverem demorando mais de 24 horas, entre em contato com o suporte.
O que vem a seguir
- Saiba como usar o painel do Cloud Monitoring para conferir as métricas.