Cloud Monitoring recopila métricas, eventos y metadatos de los productos de Google Cloud. Con Cloud Monitoring, también puedes configurar alertas de uso y paneles personalizados.
En este documento, se explica cómo usar las métricas, obtener información sobre el panel de métricas personalizadas y configurar alertas.
Recursos supervisados
Un recurso supervisado en Cloud Monitoring representa una entidad física o lógica, como una máquina virtual, una base de datos o una aplicación. Los recursos supervisados contienen un conjunto único de métricas que se pueden explorar, informar a través de un panel o usar para crear alertas. Cada recurso también tiene un conjunto de etiquetas de recursos, que son pares clave-valor que contienen información adicional sobre el recurso. Las etiquetas de recursos están disponibles para todas las métricas asociadas con el recurso.
Con la API de Cloud Monitoring, el rendimiento de Firestore en modo Datastore se supervisa con los siguientes recursos:
| Recursos | Descripción | Modo de base de datos compatible |
firestore.googleapis.com/Database (recomendada) | Tipo de recurso supervisado que proporciona desgloses de project, location* y database_id . La etiqueta database_id será (default) para las bases de datos creadas sin un nombre específico. | Todas las métricas admitidas en ambos modos,
excepto las siguientes que no son compatibles con Firestore en
modo Datastore:
|
datastore_request | Es el tipo de recurso supervisado para proyectos de Datastore y no proporciona un desglose de las bases de datos. |
Métricas
Firestore está disponible en dos modos diferentes: Firestore nativo y Firestore en modo Datastore. Para ver una comparación de funciones entre estos dos modos, consulta Elige entre los modos de bases de datos.
Para obtener una lista completa de las métricas de Firestore en modo Datastore, consulta Métricas de Firestore en modo Datastore.
Métricas del entorno de ejecución del servicio
Las métricas de serviceruntime proporcionan una descripción general de alto nivel del tráfico de un proyecto. Estas métricas están disponibles para la mayoría de las APIs de Google Cloud. El tipo de recurso supervisado consumed_api contiene estas métricas comunes. Estas métricas se toman como muestra cada 30 minutos, lo que suaviza los datos.
Una etiqueta de recurso importante para las métricas serviceruntime es method. Esta etiqueta representa el método de RPC subyacente al que se llamó. Es posible que el método del SDK al que llames no tenga el mismo nombre que el método de RPC subyacente. El motivo es que el SDK proporciona abstracción de API de alto nivel. Sin embargo, cuando intentas comprender cómo tu aplicación interactúa con Firestore, es importante comprender las métricas según el nombre del método de RPC.
Si necesitas saber cuál es el método de RPC subyacente para un método de SDK determinado, consulta la documentación de la API.
api/request_count
Esta métrica proporciona el recuento de solicitudes completadas en todos los protocolos(protocolo de solicitud, como HTTP, gRPC, etc.), el código de respuesta (código de respuesta HTTP), response_code_class (clase de código de respuesta, como 2xx, 4xx, etc.) y grpc_status_code (código de respuesta numérico de gRPC). Usa esta métrica para observar la solicitud general de la API y calcular la tasa de errores.
En la figura 1, se pueden ver las solicitudes que muestran un código 2xx agrupadas por servicio y método. Los códigos 2xx son códigos de estado HTTP que indican que la solicitud se completó correctamente.
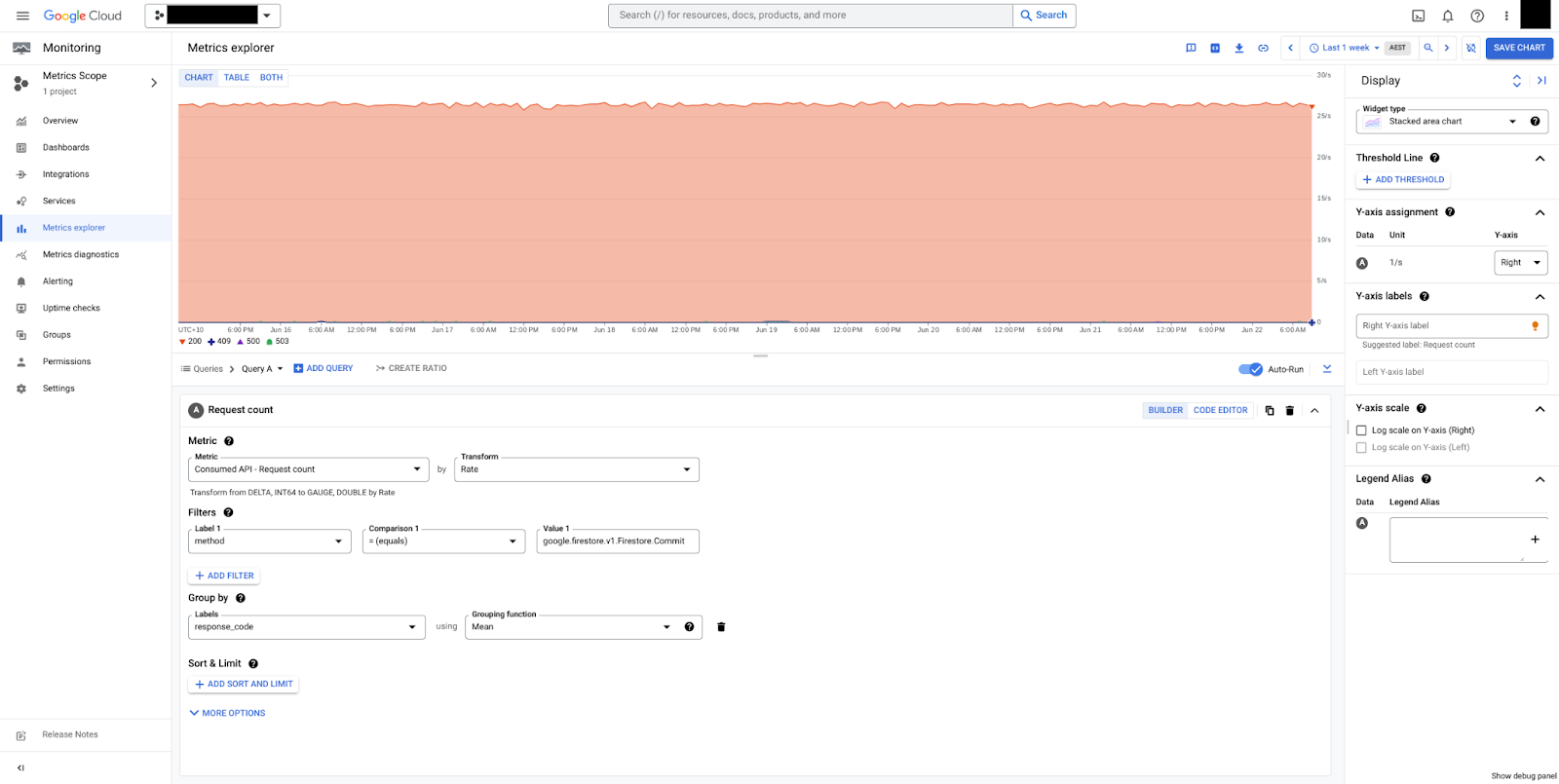
En la figura 2, se pueden ver los commits agrupados por response_code. En este ejemplo, solo vemos respuestas HTTP 200, lo que implica que la base de datos está en buen estado.
Usa las siguientes métricas del entorno de ejecución del servicio para supervisar tu base de datos.
api/request_count en el tipo de recurso datastore_request
La métrica api/request_count también está disponible en el tipo de recurso datastore_request con desgloses de api_method y response_code. En su lugar, usa esta métrica para aprovechar el período de muestreo más detallado, que ayuda a detectar los aumentos repentinos.
api/request_latencies
La métrica api/request_latencies proporciona distribuciones de latencia en todas las solicitudes completadas.
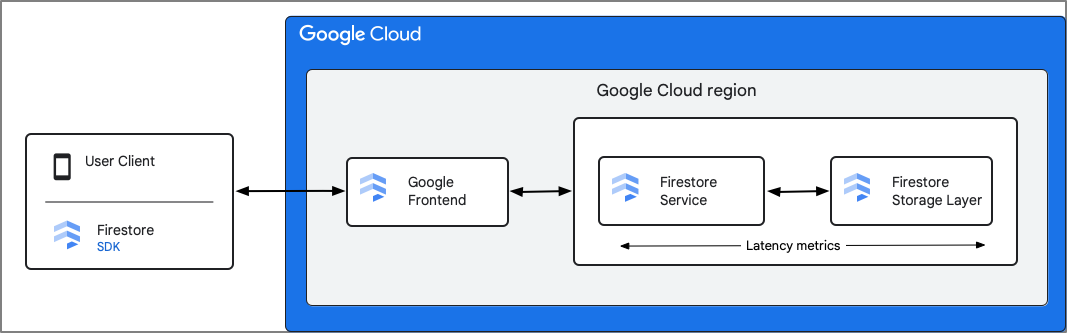
Firestore registra métricas del componente Servicio de Firestore. Las métricas de latencia incluyen el tiempo que transcurre desde que Firestore recibe la solicitud hasta que termina de enviar la respuesta, incluidas las interacciones con la capa de almacenamiento. Debido a esto, la latencia de ida y vuelta (rtt) entre el cliente y el servicio de Firestore no se incluye en estas métricas.
api/request_sizes y api/response_sizes
Las métricas api/request_sizes y api/response_sizes proporcionan estadísticas sobre los tamaños de la carga útil (en bytes), respectivamente. Estos pueden ser útiles para comprender las cargas de trabajo de escritura que envían grandes cantidades de datos o consultas demasiado amplias, y muestran cargas útiles grandes.
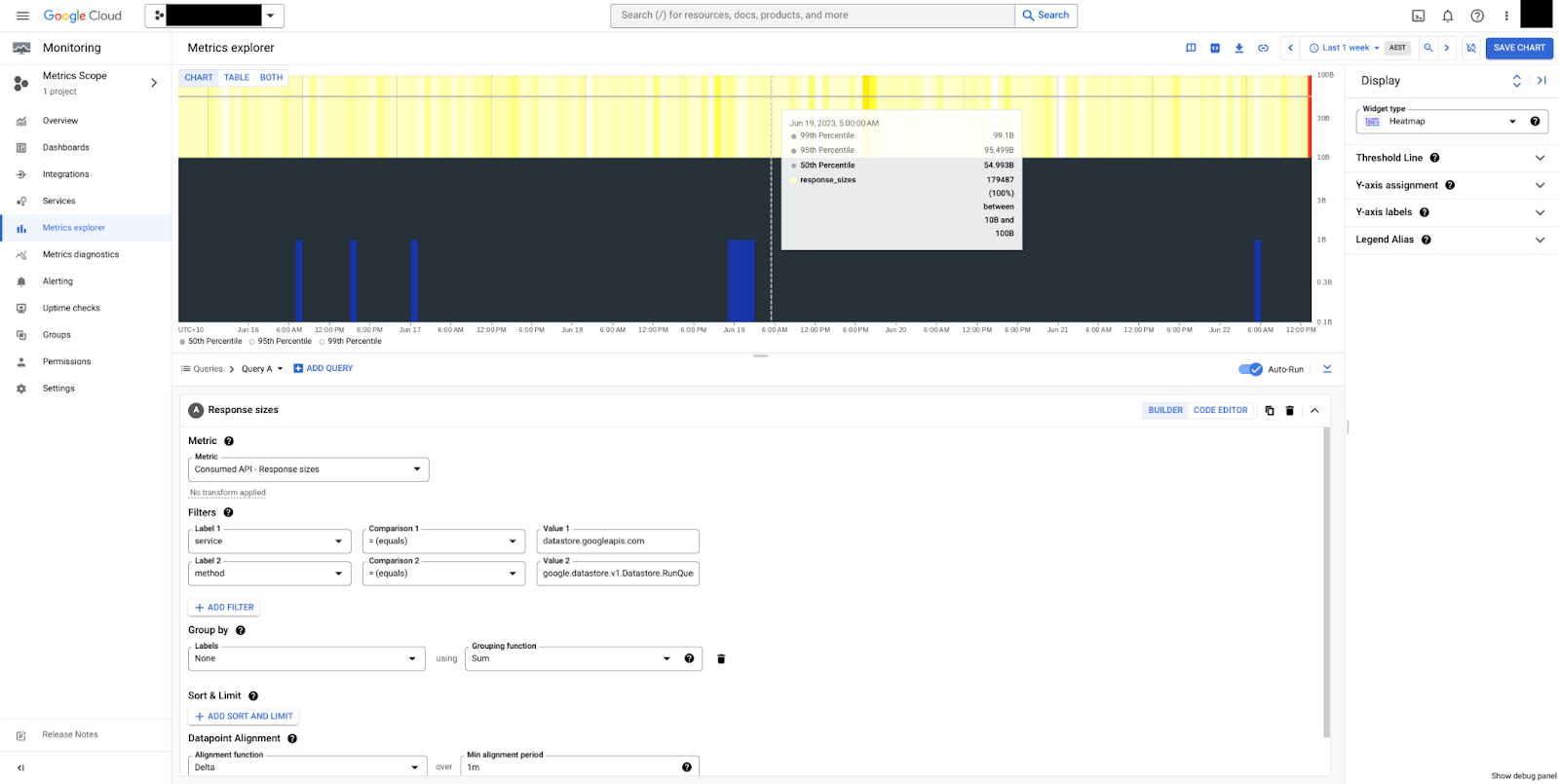
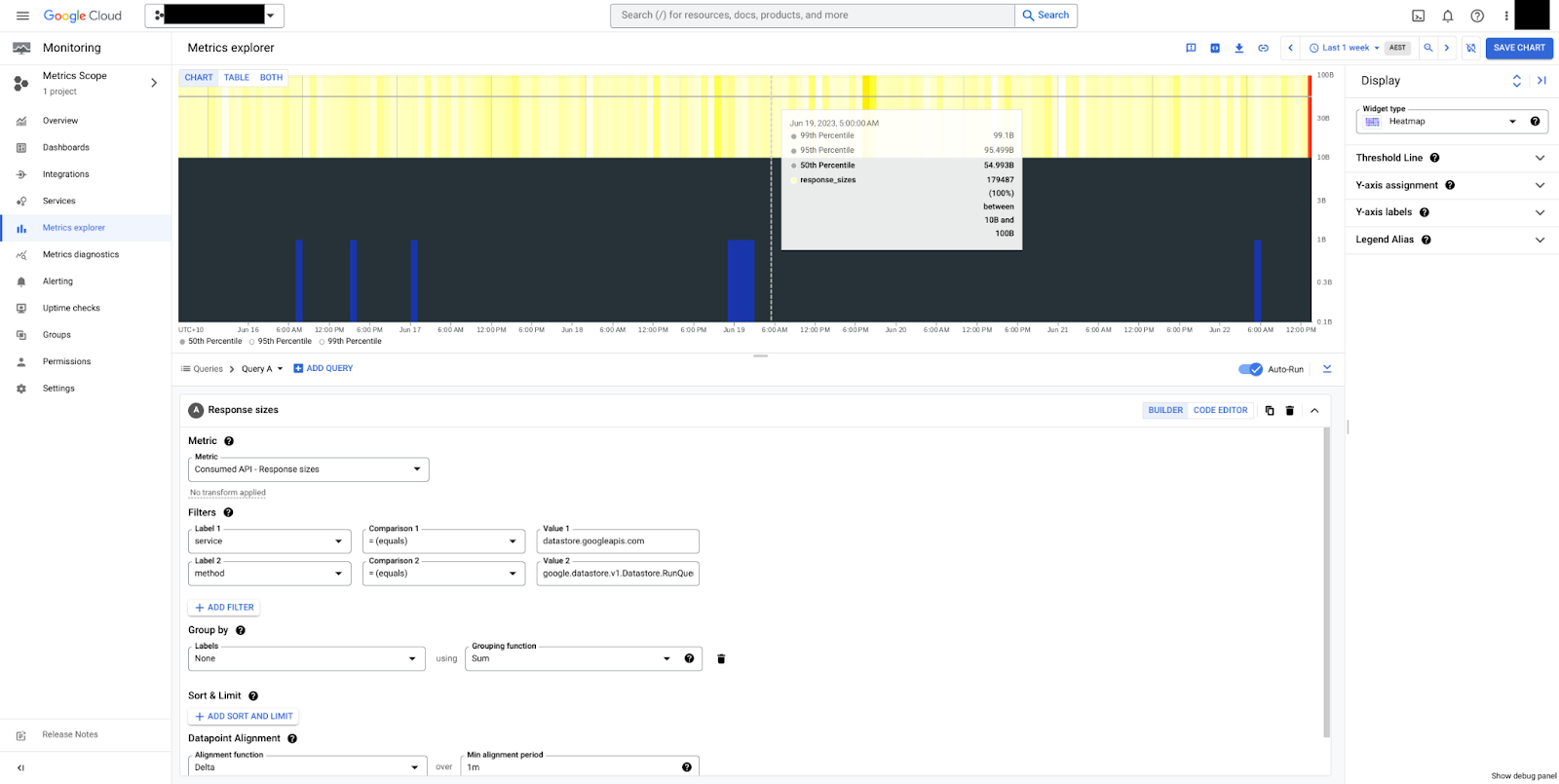
En la figura 5, se puede ver un mapa de calor para los tamaños de respuesta del método RunQuery.
Podemos ver que los tamaños son constantes, con una mediana de 50 bytes y, en general, entre 10 y 100 bytes. Ten en cuenta que los tamaños de carga útil siempre se miden en bytes sin comprimir, sin incluir las sobrecargas de control de transmisión.
Métricas de operación de entidades
Estas métricas proporcionan distribuciones en bytes de los tamaños de la carga útil para las operaciones de lectura (consultas y búsquedas) y las operaciones de escritura en una base de datos de Firestore. Los valores representan el tamaño total de la carga útil. Por ejemplo, cualquier resultado que devuelva una consulta.
Estas métricas son similares a las de api/request_sizes y api/response_sizes, con la diferencia principal de que las métricas de operaciones de entidad proporcionan un muestreo más detallado, pero desgloses menos detallados.
Por ejemplo, las métricas de operación de entidad usan el recurso supervisado datastore_request para que no haya desglose de servicios o métodos.
entity/read_sizes: Distribución de los tamaños de las entidades leídas, agrupadas por tipo.entity/write_sizes: Distribución de los tamaños de las entidades escritas, agrupadas por operaciones.
Métricas de índice
Las tasas de escritura de índices se pueden contrastar con la métrica document/write_ops_count para comprender la proporción de fanout de índices.
index/write_count: Es el recuento de operaciones de escritura en el índice.
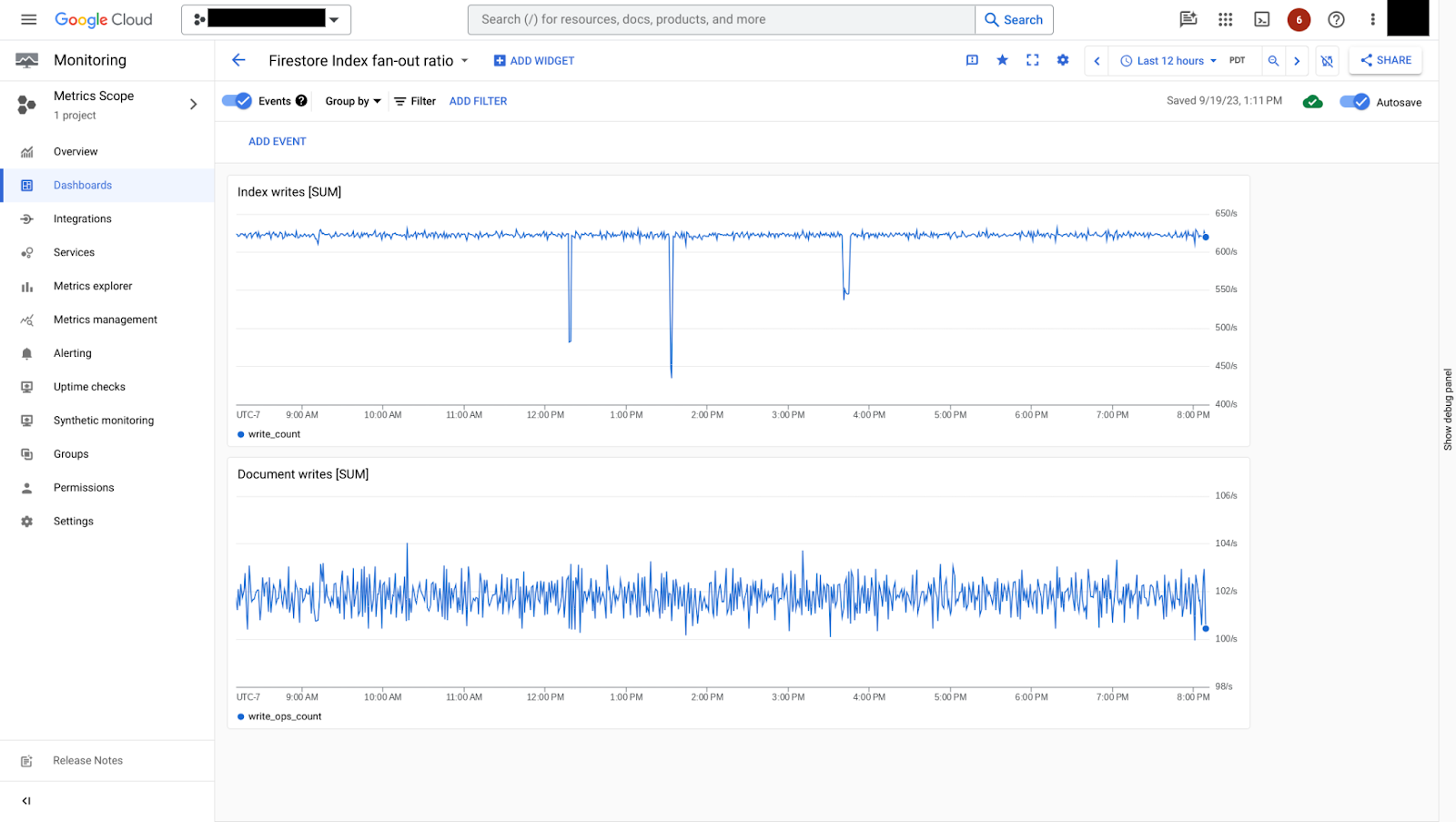
En la figura 7, puedes ver cómo se puede contrastar la tasa de escritura de índices con la tasa de escritura de documentos. En este ejemplo, por cada operación de escritura de documento, hay aproximadamente 6 operaciones de escritura de índice, lo que es una tasa de fanout de índice relativamente pequeña.
Métricas de TTL
Las métricas de TTL están disponibles para las bases de datos de Firestore nativo y Firestore en modo Datastore. Usa estas métricas para supervisar el efecto de la política de TTL aplicada.
entity/ttl_deletion_count: Es el recuento total de entidades borradas por los servicios de TTL.entity/ttl_expiration_to_deletion_delays: Es el tiempo transcurrido entre el vencimiento de una entidad con un TTL y el momento en que se borró.Si ves que las demoras en la eliminación del TTL tardan más de 24 horas, comunícate con el servicio de asistencia.
¿Qué sigue?
- Obtén información para usar el panel de Cloud Monitoring y ver las métricas.