Max Ross
According to Wikipedia, the isolation level of a database management system "defines how/when the changes made by one operation become visible to other concurrent operations." The goal of this article is to explain query and transaction isolation in the Cloud Datastore used by App Engine. After reading this article you should have a better understanding of how concurrent reads and writes behave, both in and out of transactions.
Inside Transactions: Serializable
In order from strongest to weakest, the four isolation levels are Serializable, Repeatable Read, Read Committed, and Read Uncommitted. Datastore transactions satisfy the Serializable isolation level. Each transaction is completely isolated from all other datastore transactions and operations. Transactions on a given entity group are executed serially, one after another.
See the Isolation and Consistency section of the transaction documentation for more information, as well as the Wikipedia article on snapshot isolation.
Outside Transactions: Read Committed
Datastore operations outside transactions most closely resemble the Read Committed isolation level. Entities retrieved from the datastore by queries or gets will only see committed data. A retrieved entity will never have partially committed data (some from before a commit and some from after). The interaction between queries and transactions is a bit more subtle, though, and in order to understand it we need to look at the commit process in more depth.
The Commit Process
When a commit returns successfully, the transaction is guaranteed to be applied, but that does not mean the result of your write is immediately visible to readers. Applying a transaction consists of two milestones:
- Milestone A – the point at which changes to an entity have been applied
- Milestone B – the point at which changes to indices for that entity have been applied
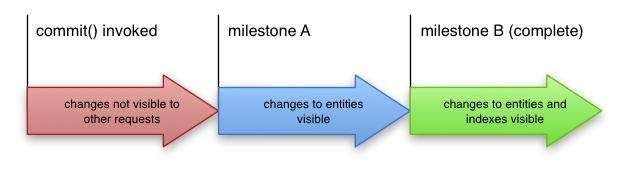
In Cloud Datastore, the transaction typically is completely applied within a few hundred milliseconds after the commit returns. However, even if it is not completely applied, subsequent reads, writes, and ancestor queries will always reflect the results of the commit, because these operations apply any outstanding modifications before executing. However, queries that span multiple entity groups cannot determine whether there are any outstanding modifications before executing and may return stale or partially applied results.
A request that looks up an updated entity by its key at a time after milestone A is guaranteed to see the latest version of that entity. However, if a concurrent request executes a query whose predicate (the WHERE clause, for you SQL/GQL fans out there) is not satisfied by the pre-update entity but is satisfied by the post-update entity, the entity will be part of the result set only if the query executes after the apply operation has reached milestone B.
In other words, during brief windows, it is possible for a result set not to include an entity whose properties, according to the result of a lookup by key, satisfy the query predicate. It is also possible for a result set to include an entity whose properties, again according to the result of a lookup by key, fail to satisfy the query predicate. A query cannot take into account transactions that are in between milestone A and milestone B when deciding which entities to return. It will be performed against stale data, but doing a get() operation on the returned keys will always get the latest version of that entity. This means that you could be either missing results that match your query or get results that do not match once you get the corresponding entity.
There are scenarios in which any pending modifications are guaranteed to be completely applied before the query executes, such as any ancestor queries in Cloud Datastore. In this case, query results will always be current and consistent.
Examples
We've provided a general explanation of how concurrent updates and queries interact, but if you're like me, you typically find it easier to get your head around these concepts by working through concrete examples. Let's walk through a few. We'll start with some simple examples and then finish up with the more interesting ones.
Let's say we have an application that stores Person entities. A Person has the following properties:
- Name
- Height
This application supports the following operations:
updatePerson()getTallPeople(), which returns all people over 72 inches tall.
We have 2 Person entities in the datastore:
- Adam, who is 68 inches tall.
- Bob, who is 73 inches tall.
Example 1 - Making Adam Taller
Suppose an application receives two requests at essentially the same time. The first request updates the height of Adam from 68 inches to 74 inches. A growth spurt! The second request calls getTallPeople(). What does getTallPeople() return?
The answer depends on the relationship between the two commit milestones triggered by Request 1 and the getTallPeople() query executed by Request 2. Suppose it looks like this:
- Request 1,
put() - Request 2,
getTallPeople() - Request 1,
put()-->commit() - Request 1,
put()-->commit()-->milestone A - Request 1,
put()-->commit()-->milestone B
In this scenario, getTallPeople() will only return Bob. Why? Because the
update to Adam that increases his height has not yet been committed, so
the change is not yet visible to the query we issue in Request 2.
Now suppose it looks like this:
- Request 1,
put() - Request 1,
put()-->commit() - Request 1,
put()-->commit()-->milestone A - Request 2,
getTallPeople() - Request 1,
put()-->commit()-->milestone B
In this scenario, the query executes before Request 1 reaches milestone B, so the updates to the Person indices have not yet been applied. As a result, getTallPeople() only returns Bob. This is an example of a result set that excludes an entity whose properties satisfy the query predicate.
Example 2 - Making Bob Shorter (Sorry, Bob)
In this example we'll have Request 1 do something different. Instead of
increasing Adam's height from 68 inches to 74 inches, it will reduce Bob's
height from 73 inches to 65 inches. Once again, what does
getTallPeople()
- Request 1,
put() - Request 2,
getTallPeople() - Request 1,
put()-->commit() - Request 1,
put()-->commit()-->milestone A - Request 1,
put()-->commit()-->milestone B
In this scenario, getTallPeople() will return only Bob. Why? Because
the update to Bob that decreases his height has not yet been committed,
so the change is not yet visible to the query we issue in Request 2.
Now suppose it looks like this:
- Request 1,
put() - Request 1,
put()-->commit() - Request 1,
put()-->commit()-->milestone A - Request 1,
put()-->commit()-->milestone B - Request 2,
getTallPeople()
In this scenario, getTallPeople() will return no one. Why? Because the
update to Bob that decreases his height has been committed by the time
we issue our query in Request 2.
Now suppose it looks like this:
- Request 1,
put() - Request 1,
put()-->commit() - Request 1,
put()-->commit()-->milestone A - Request 2,
getTallPeople() - Request 1,
put()-->commit()-->milestone B
In this scenario, the query executes before milestone B, so the updates
to the Person indices have not yet been applied. As a result,
getTallPeople() still returns Bob, but the height property of the Person
entity that comes back is the updated value: 65. This is an example of
a result set that includes an entity whose properties fail to satisfy
the query predicate.
Conclusion
As you can see from the above examples, the transaction isolation level of the Cloud Datastore is pretty close to Read Committed. There are, of course, meaningful differences, but now that you understand these differences and the reasons behind them, you should be in a better position to make intelligent, datastore-related design decisions in your applications.