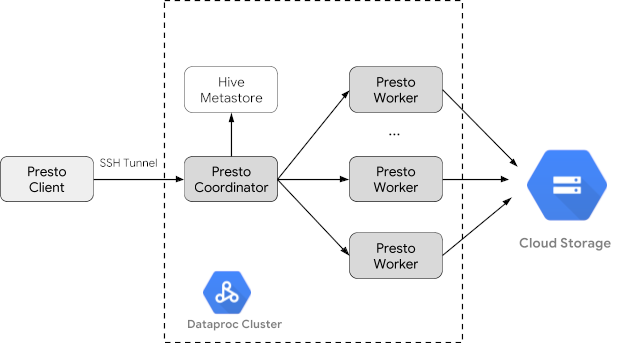
Trino(以前称为 Presto)是一个分布式 SQL 查询引擎,旨在查询分布在一个或多个异构数据源上的大型数据集。Trino 可以通过连接器查询 Hive、MySQL、Kafka 和其他数据源。本教程将介绍如何执行以下操作:
- 在 Dataproc 集群上安装 Trino 服务
- 从与集群上的 Trino 服务通信的本地机器上安装的 Trino 客户端查询公共数据
- 在通过 Trino Java JDBC 驱动程序与集群上的 Trino 服务通信的 Java 应用中运行查询。
目标
- 从 BigQuery 中提取数据
- 以 CSV 文件的形式将数据加载到 Cloud Storage 中
- 转换数据:
- 将数据公开为 Hive 外部表,以便 Trino 查询数据
- 将 CSV 格式的数据转换为 Parquet 格式,以加快查询速度
费用
在本文档中,您将使用 Google Cloud 的以下收费组件:
准备工作
创建 Google Cloud 项目和 Cloud Storage 存储桶以保存本教程中使用的数据(如果您尚未执行此操作)。1. 设置项目- 登录您的 Google Cloud 账号。如果您是 Google Cloud 新手,请创建一个账号来评估我们的产品在实际场景中的表现。新客户还可获享 $300 赠金,用于运行、测试和部署工作负载。
-
在 Google Cloud Console 中的项目选择器页面上,选择或创建一个 Google Cloud 项目。
-
启用 Dataproc, Compute Engine, Cloud Storage, and BigQuery API。
- 安装 Google Cloud CLI。
-
如需初始化 gcloud CLI,请运行以下命令:
gcloud init
-
在 Google Cloud Console 中的项目选择器页面上,选择或创建一个 Google Cloud 项目。
-
启用 Dataproc, Compute Engine, Cloud Storage, and BigQuery API。
- 安装 Google Cloud CLI。
-
如需初始化 gcloud CLI,请运行以下命令:
gcloud init
创建 Dataproc 集群
使用 optional-components 标志(适用于映像版本 2.1 及更高版本)创建 Dataproc 集群,以在集群上安装 Trino 可选组件,并使用 enable-component-gateway 标志启用组件网关,以允许从 Google Cloud 控制台访问 Trino 网页界面。
- 设置环境变量:
- PROJECT:您的项目 ID
- BUCKET_NAME::您在准备工作中创建的 Cloud Storage 存储桶的名称
- REGION:将在其中创建此教程所使用集群的区域,例如“us-west1”
- WORKERS:此教程推荐配备 3 到 5 个工作器
export PROJECT=project-id export WORKERS=number export REGION=region export BUCKET_NAME=bucket-name
- 在本地机器上运行 Google Cloud CLI 以创建集群。
gcloud beta dataproc clusters create trino-cluster \ --project=${PROJECT} \ --region=${REGION} \ --num-workers=${WORKERS} \ --scopes=cloud-platform \ --optional-components=TRINO \ --image-version=2.1 \ --enable-component-gateway
准备数据
将 bigquery-public-data chicago_taxi_trips 数据集作为 CSV 文件导出到 Cloud Storage,然后创建 Hive 外部表来引用数据。
- 在本地机器上,运行以下命令,以 CSV 文件(不含标题)形式将出租车数据从 BigQuery 导入您在准备工作中创建的 Cloud Storage 存储桶。
bq --location=us extract --destination_format=CSV \ --field_delimiter=',' --print_header=false \ "bigquery-public-data:chicago_taxi_trips.taxi_trips" \ gs://${BUCKET_NAME}/chicago_taxi_trips/csv/shard-*.csv - 创建由 Cloud Storage 存储桶中的 CSV 和 Parquet 文件支持的 Hive 外部表。
- 创建 Hive 外部表
chicago_taxi_trips_csv。gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_csv( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE location 'gs://${BUCKET_NAME}/chicago_taxi_trips/csv/';" - 验证 Hive 外部表的创建过程。
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_csv;" - 创建另一个具有相同列的 Hive 外部表
chicago_taxi_trips_parquet,但以 Parquet 格式存储数据可提高查询性能。gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_parquet( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) STORED AS PARQUET location 'gs://${BUCKET_NAME}/chicago_taxi_trips/parquet/';" - 将 Hive CSV 表中的数据加载到 Hive Parquet 表中。
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " INSERT OVERWRITE TABLE chicago_taxi_trips_parquet SELECT * FROM chicago_taxi_trips_csv;" - 验证数据是否已正确加载。
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_parquet;"
- 创建 Hive 外部表
运行查询
您可以在本地通过 Trino CLI 或从应用运行查询。
Trino CLI 查询
本部分介绍如何使用 Trino CLI 查询 Hive Parquet 出租车数据集。
- 在本地机器上运行以下命令,以通过 SSH 连接到集群的主节点。在执行命令期间,本地终端将停止响应。
gcloud compute ssh trino-cluster-m
- 在集群主节点上的 SSH 终端窗口中,运行 Trino CLI,以连接到在主节点上运行的 Trino 服务器。
trino --catalog hive --schema default
- 在
trino:default提示符处,验证 Trino 能否找到 Hive 表。show tables;
Table ‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐ chicago_taxi_trips_csv chicago_taxi_trips_parquet (2 rows)
- 从
trino:default提示符运行查询,并比较查询 Parquet 与 CSV 数据的性能。- Parquet 数据查询
select count(*) from chicago_taxi_trips_parquet where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171735_00006_2sz8c, FINISHED, 3 nodes Splits: 308 total, 308 done (100.00%) 0:16 [113M rows, 297MB] [6.91M rows/s, 18.2MB/s] - CSV 数据查询
select count(*) from chicago_taxi_trips_csv where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171936_00009_2sz8c, FINISHED, 3 nodes Splits: 881 total, 881 done (100.00%) 0:47 [113M rows, 41.5GB] [2.42M rows/s, 911MB/s]
- Parquet 数据查询
Java 应用查询
要通过 Trino Java JDBC 驱动程序从 Java 应用运行查询,请执行以下操作:
1. 下载 Trino Java JDBC 驱动程序。1. 在 Maven pom.xml 中添加 trino-jdbc 依赖项。
<dependency> <groupId>io.trino</groupId> <artifactId>trino-jdbc</artifactId> <version>376</version> </dependency>Java 代码示例
package dataproc.codelab.trino;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
public class TrinoQuery {
private static final String URL = "jdbc:trino://trino-cluster-m:8080/hive/default";
private static final String SOCKS_PROXY = "localhost:1080";
private static final String USER = "user";
private static final String QUERY =
"select count(*) as count from chicago_taxi_trips_parquet where trip_miles > 50";
public static void main(String[] args) {
try {
Properties properties = new Properties();
properties.setProperty("user", USER);
properties.setProperty("socksProxy", SOCKS_PROXY);
Connection connection = DriverManager.getConnection(URL, properties);
try (Statement stmt = connection.createStatement()) {
ResultSet rs = stmt.executeQuery(QUERY);
while (rs.next()) {
int count = rs.getInt("count");
System.out.println("The number of long trips: " + count);
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
日志记录和监控
日志记录
Trino 日志位于集群主节点和工作器节点上的 /var/log/trino/ 中。
网页界面
请参阅查看和访问组件网关网址,以在本地浏览器中打开集群的主节点上运行的 Trino 网页界面。
监控
Trino 通过运行时表公开集群运行时信息。在 Trino 会话(通过 trino:default)提示符中,运行以下查询以查看运行时表数据:
select * FROM system.runtime.nodes;
清理
完成本教程后,您可以清理您创建的资源,让它们停止使用配额,以免产生费用。以下部分介绍如何删除或关闭这些资源。
删除项目
若要避免产生费用,最简单的方法是删除您为本教程创建的项目。
如需删除项目,请执行以下操作:
- 在 Google Cloud 控制台中,进入管理资源页面。
- 在项目列表中,选择要删除的项目,然后点击删除。
- 在对话框中输入项目 ID,然后点击关闭以删除项目。
删除集群
- 如需删除您的集群,请输入以下命令:
gcloud dataproc clusters delete --project=${PROJECT} trino-cluster \ --region=${REGION}
删除存储桶
- 如需删除您在准备工作中创建的 Cloud Storage 存储桶(包括存储在存储桶中的数据文件),请输入以下命令:
gsutil -m rm -r gs://${BUCKET_NAME}