Trino(이전의 Prestro)는 하나 이상의 이기종 데이터 소스에 분산된 큰 데이터 세트를 쿼리하도록 설계된 분산형 SQL 쿼리 엔진입니다. Trino는 커넥터를 통해 Hive, MySQL, Kafka 및 기타 데이터 소스를 쿼리할 수 있습니다. 이 튜토리얼에서는 다음을 수행하는 방법을 보여줍니다.
- Dataproc 클러스터에 Trino 서비스 설치
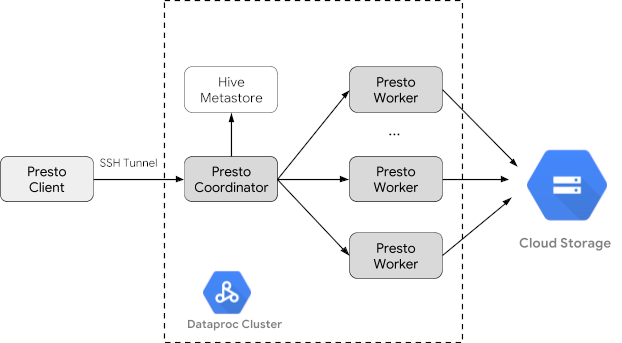
- 클러스터에 있는 Trino 서비스와 통신하는 로컬 머신에 설치된 Trino 클라이언트에서 공개 데이터 쿼리
- Trino 자바 JDBC 드라이버를 통해 클러스터에 있는 Trino 서비스와 통신하는 자바 애플리케이션에서 쿼리 실행
목표
- BigQuery에서 데이터를 추출합니다.
- 데이터를 Cloud Storage에 CSV 파일로 로드합니다.
- 데이터를 변환합니다.
- 데이터를 Hive 외부 테이블로 노출하여 Trino가 데이터를 쿼리할 수 있도록 합니다.
- 데이터를 CSV 형식에서 Parquet 형식으로 변환하여 더 빠르게 쿼리할 수 있도록 합니다.
비용
이 문서에서는 비용이 청구될 수 있는 다음과 같은 Google Cloud 구성요소를 사용합니다.
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용하세요.
시작하기 전에
Google Cloud 프로젝트 그리고 이 가이드에서 사용되는 데이터를 보관하기 위한 Cloud Storage 버킷을 아직 만들지 않았다면 만듭니다. 1. 프로젝트 설정- Google Cloud 계정에 로그인합니다. Google Cloud를 처음 사용하는 경우 계정을 만들고 Google 제품의 실제 성능을 평가해 보세요. 신규 고객에게는 워크로드를 실행, 테스트, 배포하는 데 사용할 수 있는 $300의 무료 크레딧이 제공됩니다.
-
Google Cloud Console의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
-
API Dataproc, Compute Engine, Cloud Storage, and BigQuery 사용 설정
- Google Cloud CLI를 설치합니다.
-
gcloud CLI를 초기화하려면 다음 명령어를 실행합니다.
gcloud init
-
Google Cloud Console의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
-
API Dataproc, Compute Engine, Cloud Storage, and BigQuery 사용 설정
- Google Cloud CLI를 설치합니다.
-
gcloud CLI를 초기화하려면 다음 명령어를 실행합니다.
gcloud init
- Google Cloud Console에서 Cloud Storage 버킷 페이지로 이동합니다.
- 버킷 만들기를 클릭합니다.
- 버킷 만들기 페이지에서 버킷 정보를 입력합니다. 다음 단계로 이동하려면 계속을 클릭합니다.
- 버킷 이름 지정에서 버킷 이름 지정 요구사항을 충족하는 이름을 입력합니다.
-
데이터를 저장할 위치 선택에서 다음을 수행합니다.
- 위치 유형 옵션을 선택합니다.
- 위치 옵션을 선택합니다.
- 데이터의 기본 스토리지 클래스 선택에서 스토리지 클래스를 선택합니다.
- 객체 액세스를 제어하는 방식 선택에서 액세스 제어 옵션을 선택합니다.
- 고급 설정(선택사항)에서 암호화 방법, 보관 정책 또는 버킷 라벨을 지정합니다.
- 만들기를 클릭합니다.
Dataproc 클러스터 만들기
optional-components 플래그(이미지 버전 2.1 이상에서 사용 가능)를 사용하여 Dataproc 클러스터를 만들고 Trino 선택적 구성요소를 클러스터에 설치하고 enable-component-gateway 플래그를 사용하여 구성요소 게이트웨이를 사용 설정하여 Google Cloud console에서 Trino 웹 UI에 액세스할 수 있도록 합니다.
- 환경 변수 설정
- PROJECT: 프로젝트 ID
- BUCKET_NAME: 시작하기 전에에서 만든 Cloud Storage 버킷의 이름
- REGION: 이 가이드에서 사용된 클러스터가 만들어질 리전(예: 'us-west1')
- WORKERS: 이 가이드에는 3~5개의 작업자가 권장됨
export PROJECT=project-id export WORKERS=number export REGION=region export BUCKET_NAME=bucket-name
- 로컬 머신에서 Google Cloud CLI를 실행하여 클러스터를 만듭니다.
gcloud beta dataproc clusters create trino-cluster \ --project=${PROJECT} \ --region=${REGION} \ --num-workers=${WORKERS} \ --scopes=cloud-platform \ --optional-components=TRINO \ --image-version=2.1 \ --enable-component-gateway
데이터 준비
bigquery-public-data chicago_taxi_trips 데이터세트를 Cloud Storage에 CSV 파일로 내보낸 후에 데이터를 참조할 Hive 외부 테이블을 만듭니다.
- 로컬 머신에서 다음 명령어를 실행하여 BigQuery의 택시 데이터를 헤더가 없는 CSV 파일로 시작하기 전에에서 만든 Cloud Storage 버킷에 가져옵니다.
bq --location=us extract --destination_format=CSV \ --field_delimiter=',' --print_header=false \ "bigquery-public-data:chicago_taxi_trips.taxi_trips" \ gs://${BUCKET_NAME}/chicago_taxi_trips/csv/shard-*.csv - Cloud Storage 버킷에서 CSV 및 Parquet 파일의 지원을 받는 Hive 외부 테이블을 만듭니다.
- Hive 외부 테이블
chicago_taxi_trips_csv를 만듭니다.gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_csv( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE location 'gs://${BUCKET_NAME}/chicago_taxi_trips/csv/';" - Hive 외부 테이블이 생성되었는지 확인합니다.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_csv;" - 같은 열이 있는 다른 Hive 외부 테이블
chicago_taxi_trips_parquet을 만듭니다. 하지만 이번에는 더 나은 쿼리 성능을 위해 데이터를 Parquet 형식으로 저장합니다.gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_parquet( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) STORED AS PARQUET location 'gs://${BUCKET_NAME}/chicago_taxi_trips/parquet/';" - 데이터를 Hive CSV 테이블에서 Hive Parquet 테이블로 로드합니다.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " INSERT OVERWRITE TABLE chicago_taxi_trips_parquet SELECT * FROM chicago_taxi_trips_csv;" - 데이터가 올바르게 로드되었는지 확인합니다.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_parquet;"
- Hive 외부 테이블
쿼리 실행
Trino CLI 또는 애플리케이션에서 로컬로 쿼리를 실행할 수 있습니다.
Trino CLI 쿼리
이 섹션에서는 Trino CLI를 사용하여 Hive Parquet 택시 데이터세트를 쿼리하는 방법을 보여줍니다.
- 로컬 머신에서 다음 명령어를 실행하여 클러스터의 마스터 노드로 SSH를 전송합니다. 명령어를 실행하는 동안 로컬 터미널이 응답을 중지합니다.
gcloud compute ssh trino-cluster-m
- 클러스터의 마스터 노드에 있는 SSH 터미널 창에서 마스터 노드에서 실행되는 Trino 서버에 연결되는 Trino CLI를 실행합니다.
trino --catalog hive --schema default
trino:default프롬프트에서 Trino가 Hive 테이블을 찾을 수 있는지 확인합니다.show tables;
Table ‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐ chicago_taxi_trips_csv chicago_taxi_trips_parquet (2 rows)
trino:default프롬프트에서 쿼리를 실행하고, Parquet 데이터와 CSV 데이터의 쿼리 성능을 비교합니다.- Parquet 데이터 쿼리
select count(*) from chicago_taxi_trips_parquet where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171735_00006_2sz8c, FINISHED, 3 nodes Splits: 308 total, 308 done (100.00%) 0:16 [113M rows, 297MB] [6.91M rows/s, 18.2MB/s] - CSV 데이터 쿼리
select count(*) from chicago_taxi_trips_csv where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171936_00009_2sz8c, FINISHED, 3 nodes Splits: 881 total, 881 done (100.00%) 0:47 [113M rows, 41.5GB] [2.42M rows/s, 911MB/s]
- Parquet 데이터 쿼리
자바 애플리케이션 쿼리
Trino 자바 JDBC 드라이버를 통해 자바 애플리케이션에서 쿼리를 실행하려면 다음 단계를 따르세요.
1. Trino Java JDBC 드라이버를 다운로드합니다.
1. Maven pom.xml에서 trino-jdbc 종속 항목을 추가합니다.
<dependency> <groupId>io.trino</groupId> <artifactId>trino-jdbc</artifactId> <version>376</version> </dependency>샘플 자바 코드
package dataproc.codelab.trino;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
public class TrinoQuery {
private static final String URL = "jdbc:trino://trino-cluster-m:8080/hive/default";
private static final String SOCKS_PROXY = "localhost:1080";
private static final String USER = "user";
private static final String QUERY =
"select count(*) as count from chicago_taxi_trips_parquet where trip_miles > 50";
public static void main(String[] args) {
try {
Properties properties = new Properties();
properties.setProperty("user", USER);
properties.setProperty("socksProxy", SOCKS_PROXY);
Connection connection = DriverManager.getConnection(URL, properties);
try (Statement stmt = connection.createStatement()) {
ResultSet rs = stmt.executeQuery(QUERY);
while (rs.next()) {
int count = rs.getInt("count");
System.out.println("The number of long trips: " + count);
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
로깅 및 모니터링
로깅
Trino 로그는 클러스터의 마스터 및 워커 노드의 /var/log/trino/에 있습니다.
웹 UI
로컬 브라우저의 클러스터 마스터 노드에서 실행되는 Trino 웹 UI를 열려면 구성요소 게이트웨이 URL 보기 및 액세스를 참조하세요.
모니터링
Trino는 런타임 테이블을 통해 클러스터 런타임 정보를 노출합니다.
Trino 세션(trino:default에 있음) 프롬프트에서 다음 쿼리를 실행하여 런타임 테이블 데이터를 봅니다.
select * FROM system.runtime.nodes;
삭제
튜토리얼을 완료한 후에는 만든 리소스를 삭제하여 할당량 사용을 중지하고 요금이 청구되지 않도록 할 수 있습니다. 다음 섹션은 이러한 리소스를 삭제하거나 사용 중지하는 방법을 설명합니다.
프로젝트 삭제
비용이 청구되지 않도록 하는 가장 쉬운 방법은 튜토리얼에서 만든 프로젝트를 삭제하는 것입니다.
프로젝트를 삭제하는 방법은 다음과 같습니다.
- Google Cloud 콘솔에서 리소스 관리 페이지로 이동합니다.
- 프로젝트 목록에서 삭제할 프로젝트를 선택하고 삭제를 클릭합니다.
- 대화상자에서 프로젝트 ID를 입력한 후 종료를 클릭하여 프로젝트를 삭제합니다.
클러스터 삭제
- 클러스터를 삭제하는 방법은 다음과 같습니다.
gcloud dataproc clusters delete --project=${PROJECT} trino-cluster \ --region=${REGION}
버킷 삭제
- 시작하기 전에에서 만든 Cloud Storage 버킷과 그 안에 저장된 데이터 파일을 삭제하는 방법은 다음과 같습니다.
gsutil -m rm -r gs://${BUCKET_NAME}