Trino (anteriormente Presto) es un motor de consulta en SQL distribuido diseñado para consultar grandes conjuntos de datos distribuidos en una o más fuentes de datos heterogéneas. Trino puede consultar Hive, MySQL, Kafka y otras fuentes de datos a través de conectores. En este instructivo, se muestra cómo hacer lo siguiente:
- Instala el servicio de Trino en un clúster de Dataproc
- Consultar datos públicos de un cliente de Trino instalado en tu máquina local que se comunique con un servicio de Trino en el clúster
- Ejecuta consultas desde una aplicación de Java que se comunique con el servicio de Trino en tu clúster a través del controlador JDBC de Java de Trino.
Objetivos
- Extraer los datos de BigQuery
- Cargar los datos en Cloud Storage como archivos CSV
- Transformar los datos:
- Exponer los datos como una tabla externa de Hive para que Trino pueda consultar los datos
- Convertir los datos del formato CSV al formato Parquet para que las consultas sean más rápidas
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
Para generar una estimación de costos en función del uso previsto, usa la calculadora de precios.
Antes de comenzar
Si aún no lo hiciste, crea un proyecto de Google Cloud y un bucket de Cloud Storage para conservar los datos que se usan en este instructivo. 1. Configura tu proyecto- Accede a tu cuenta de Google Cloud. Si eres nuevo en Google Cloud, crea una cuenta para evaluar el rendimiento de nuestros productos en situaciones reales. Los clientes nuevos también obtienen $300 en créditos gratuitos para ejecutar, probar y, además, implementar cargas de trabajo.
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
-
Habilita las API de Dataproc, Compute Engine, Cloud Storage, and BigQuery.
- Instala Google Cloud CLI.
-
Para inicializar la CLI de gcloud, ejecuta el siguiente comando:
gcloud init
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
-
Habilita las API de Dataproc, Compute Engine, Cloud Storage, and BigQuery.
- Instala Google Cloud CLI.
-
Para inicializar la CLI de gcloud, ejecuta el siguiente comando:
gcloud init
- En la consola de Google Cloud, ve a la página Buckets de Cloud Storage.
- Haga clic en Crear bucket.
- En la página Crear un bucket, ingresa la información de tu bucket. Para ir al paso siguiente, haz clic en Continuar.
- En Nombre de tu bucket, ingresa un nombre que cumpla con los requisitos de nomenclatura de buckets.
-
En Elige dónde almacenar tus datos, haz lo siguiente:
- Selecciona una opción de Tipo de ubicación.
- Selecciona una opción de Ubicación.
- Para Elegir una clase de almacenamiento predeterminada para tus datos, selecciona una clase de almacenamiento.
- En Elige cómo controlar el acceso a los objetos, selecciona una opción de Control de acceso.
- Para la Configuración avanzada (opcional), especifica un método de encriptación, una política de retención o etiquetas de bucket.
- Haga clic en Crear.
Crea un clúster de Dataproc
Crea un clúster de Dataproc con la marca optional-components (disponible en la versión de imagen 2.1 y versiones posteriores) a fin de instalar el componente opcional de Trino en el clúster y la marca enable-component-gateway para habilitar la puerta de enlace de componentes a fin de que puedas acceder a la IU web de Trino desde Google Cloud Console.
- Configura las variables de entorno:
- PROJECT: El ID de tu proyecto
- BUCKET_NAME: El nombre del depósito de Cloud Storage que creaste en la sección Antes de comenzar
- REGION: La región donde se creará el clúster que se usa en este instructivo, por ejemplo, "us-west1"
- WORKERS: Se recomienda usar entre 3 y 5 trabajadores para las actividades de este instructivo.
export PROJECT=project-id export WORKERS=number export REGION=region export BUCKET_NAME=bucket-name
- Ejecuta Google Cloud CLI en tu máquina local para
crear el clúster.
gcloud beta dataproc clusters create trino-cluster \ --project=${PROJECT} \ --region=${REGION} \ --num-workers=${WORKERS} \ --scopes=cloud-platform \ --optional-components=TRINO \ --image-version=2.1 \ --enable-component-gateway
Prepara los datos
Exporta el conjunto de datos chicago_taxi_trips de bigquery-public-data a Cloud Storage como archivos CSV y, luego, crea una tabla externa de Hive para hacer referencia a los datos.
- En tu máquina local, ejecuta el siguiente comando para importar los datos de taxis de BigQuery como archivos CSV sin encabezados al bucket de Cloud Storage que creaste en la sección Antes de comenzar.
bq --location=us extract --destination_format=CSV \ --field_delimiter=',' --print_header=false \ "bigquery-public-data:chicago_taxi_trips.taxi_trips" \ gs://${BUCKET_NAME}/chicago_taxi_trips/csv/shard-*.csv - Crea tablas externas de Hive que estén respaldadas por los archivos CSV y Parquet de tu bucket de Cloud Storage.
- Crea la tabla externa de Hive
chicago_taxi_trips_csv.gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_csv( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE location 'gs://${BUCKET_NAME}/chicago_taxi_trips/csv/';" - Verifica la creación de la tabla externa de Hive.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_csv;" - Crea otra tabla externa de Hive
chicago_taxi_trips_parquetcon las mismas columnas, pero con datos almacenados en formato Parquet para mejorar el rendimiento de las consultas.gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_parquet( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) STORED AS PARQUET location 'gs://${BUCKET_NAME}/chicago_taxi_trips/parquet/';" - Carga los datos de la tabla CSV de Hive en la tabla de Parquet de Hive.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " INSERT OVERWRITE TABLE chicago_taxi_trips_parquet SELECT * FROM chicago_taxi_trips_csv;" - Verificar que los datos se hayan cargado correctamente
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_parquet;"
- Crea la tabla externa de Hive
Ejecuta consultas
Puedes ejecutar consultas de forma local desde la CLI de Trino o desde una aplicación.
Consultas de la CLI de Trino
En esta sección, se muestra cómo consultar el conjunto de datos de taxis de Parquet de Hive con la CLI de Trono.
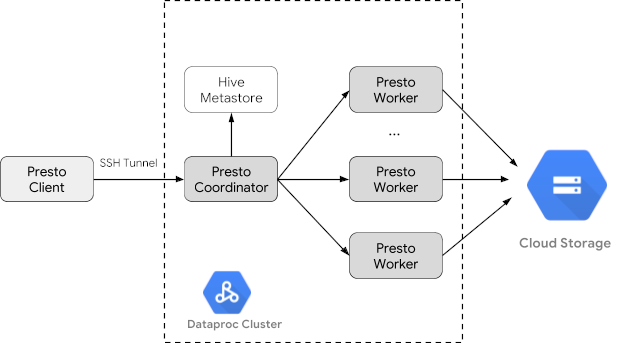
- Ejecuta el siguiente comando en tu máquina local para establecer una conexión SSH al nodo principal del clúster. La terminal local dejará de responder durante la ejecución del comando.
gcloud compute ssh trino-cluster-m
- En la ventana de la terminal SSH del nodo principal de tu clúster, ejecuta la
CLI de Trino, que se conecta al servidor de Trino que se ejecuta en el nodo
principal.
trino --catalog hive --schema default
- Cuando aparezca el mensaje
trino:default, verifica que Trino pueda encontrar las tablas de Hive.show tables;
Table ‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐ chicago_taxi_trips_csv chicago_taxi_trips_parquet (2 rows)
- Ejecuta consultas desde el mensaje
trino:defaulty compara el rendimiento de consultar datos de Parquet en comparación con CSV.- Consulta de datos de Parquet
select count(*) from chicago_taxi_trips_parquet where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171735_00006_2sz8c, FINISHED, 3 nodes Splits: 308 total, 308 done (100.00%) 0:16 [113M rows, 297MB] [6.91M rows/s, 18.2MB/s] - Consulta de datos CSV
select count(*) from chicago_taxi_trips_csv where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171936_00009_2sz8c, FINISHED, 3 nodes Splits: 881 total, 881 done (100.00%) 0:47 [113M rows, 41.5GB] [2.42M rows/s, 911MB/s]
- Consulta de datos de Parquet
Consultas de aplicaciones Java
Para ejecutar consultas desde una aplicación de Java a través del controlador JDBC de Java de Trino, sigue estos pasos:
1. Descarga el controlador JDBC de Java para Trono.
1. Agrega una dependencia trino-jdbc en Maven pom.xml.
<dependency> <groupId>io.trino</groupId> <artifactId>trino-jdbc</artifactId> <version>376</version> </dependency>Ejemplo de código Java
package dataproc.codelab.trino;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
public class TrinoQuery {
private static final String URL = "jdbc:trino://trino-cluster-m:8080/hive/default";
private static final String SOCKS_PROXY = "localhost:1080";
private static final String USER = "user";
private static final String QUERY =
"select count(*) as count from chicago_taxi_trips_parquet where trip_miles > 50";
public static void main(String[] args) {
try {
Properties properties = new Properties();
properties.setProperty("user", USER);
properties.setProperty("socksProxy", SOCKS_PROXY);
Connection connection = DriverManager.getConnection(URL, properties);
try (Statement stmt = connection.createStatement()) {
ResultSet rs = stmt.executeQuery(QUERY);
while (rs.next()) {
int count = rs.getInt("count");
System.out.println("The number of long trips: " + count);
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
Registros y supervisión
Logging
Los registros de Trino se encuentran en /var/log/trino/, en los nodos principales y trabajadores del clúster.
IU web
Consulta Visualiza las URLs de puerta de enlace de componentes y accede a ellas para abrir la IU web de Trino que se ejecuta en el nodo principal del clúster en tu navegador local.
Supervisión
Trino expone la información del entorno de ejecución del clúster a través de tablas de entorno de ejecución.
En una sesión de Trino (desde trino:default), ejecuta la siguiente consulta para ver los datos de la tabla de entorno de ejecución:
select * FROM system.runtime.nodes;
Limpia
Una vez que completes el instructivo, puedes limpiar los recursos que creaste para que dejen de usar la cuota y generar cargos. En las siguientes secciones, se describe cómo borrar o desactivar estos recursos.
Borra el proyecto
La manera más fácil de eliminar la facturación es borrar el proyecto que creaste para el instructivo.
Para borrar el proyecto, haga lo siguiente:
- En la consola de Google Cloud, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que quieres borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrar el proyecto.
Borre el clúster
- Para borrar tu clúster, haz lo siguiente:
gcloud dataproc clusters delete --project=${PROJECT} trino-cluster \ --region=${REGION}
Borra el bucket
- Para borrar el bucket de Cloud Storage que creaste en Antes de comenzar, incluidos los archivos de datos almacenados en el bucket, haz lo siguiente:
gsutil -m rm -r gs://${BUCKET_NAME}