Apache Spark 用の BigQuery コネクタを使用すると、データ サイエンティストは、BigQuery のシームレスでスケーラブルな SQL エンジンの能力と Apache Spark の機械学習機能を融合できます。このチュートリアルでは、Dataproc、BigQuery、Apache Spark ML を使用してデータセットで機械学習を実施する方法を示します。
目標
線形回帰を使用して次の 5 つの要素に基づく出生時体重のモデルを構築します。- 妊娠週
- 母親の年齢
- 父親の年齢
- 母親の妊娠中の体重増加
- アプガースコア
次のツールを使用します。
- Google Cloud プロジェクトに書き込まれる線形回帰入力テーブルを準備する BigQuery
- BigQuery でのデータのクエリと管理に使用する Python
- 生成された線形回帰テーブルにアクセスする Apache Spark
- モデルの構築と評価を行う Spark ML
- Spark ML 関数を呼び出す Dataproc PySpark ジョブ
費用
このドキュメントでは、Google Cloud の次の課金対象のコンポーネントを使用します。
- Compute Engine
- Dataproc
- BigQuery
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
始める前に
Dataproc クラスタには、Spark ML などの Spark コンポーネントがインストールされています。Dataproc クラスタをセットアップしてこの例で示すコードを実行するには、次のことを行う(またはすでに行っている)必要があります。
- Google Cloud アカウントにログインします。Google Cloud を初めて使用する場合は、アカウントを作成して、実際のシナリオでの Google プロダクトのパフォーマンスを評価してください。新規のお客様には、ワークロードの実行、テスト、デプロイができる無料クレジット $300 分を差し上げます。
-
Google Cloud Console の [プロジェクト セレクタ] ページで、Google Cloud プロジェクトを選択または作成します。
-
Dataproc, BigQuery, Compute Engine API を有効にします。
- Google Cloud CLI をインストールします。
-
gcloud CLI を初期化するには:
gcloud init
-
Google Cloud Console の [プロジェクト セレクタ] ページで、Google Cloud プロジェクトを選択または作成します。
-
Dataproc, BigQuery, Compute Engine API を有効にします。
- Google Cloud CLI をインストールします。
-
gcloud CLI を初期化するには:
gcloud init
- プロジェクト内で Dataproc クラスタを作成します。クラスタでは、Spark 2.0 以降の Dataproc バージョン(機械学習ライブラリが含まれているバージョン)が実行されている必要があります。
BigQuery natality データのサブセットを作成する
このセクションでは、プロジェクトにデータセットを作成し、そのデータセットにテーブルを作成して、公表されている出生率 BigQuery データセットから出生率データのサブセットをコピーします。このチュートリアルの後半では、このテーブルのサブセット データを使用して、母親の年齢、父親の年齢、妊娠週に基づいて出生体重を予測します。
データ サブセットは、Google Cloud Console を使用するか、ローカルマシンで Python スクリプトを実行して作成できます。
Console
プロジェクトにデータセットを作成します。
- BigQuery ウェブ UI に移動します。
- 左側のナビゲーション パネルでプロジェクト名をクリックし、続いて [データセットを作成] をクリックします。
- [データセットを作成] ダイアログで、次のように指定します。
- [データセット ID] に「natality_regression」と入力します。
- [データのロケーション] では、データセットのロケーションを選択できます。ロケーションのデフォルト値は、
US multi-regionです。データセットの作成後はロケーションを変更できません。 - [デフォルトのテーブルの有効期限] では、次のいずれかのオプションを選択します。
- [無期限](デフォルト): テーブルは手動で削除する必要があります。
- [日数]: テーブルは、作成日から指定した日数後に削除されます。
- [暗号化] では、次のいずれかのオプションを選択します。
- [Google が管理する鍵] (デフォルト)。
- [顧客管理の暗号鍵]: Cloud KMS 鍵でデータを保護するをご覧ください。
- [データセットを作成] をクリックします。
公表されている出生率データセットに対してクエリを実行し、クエリ結果をデータセット内の新しいテーブルに保存します。
- 次のクエリをクエリエディタにコピーして貼り付け、[実行] をクリックします。
SELECT weight_pounds, mother_age, father_age, gestation_weeks, weight_gain_pounds, apgar_5min FROM `bigquery-public-data.samples.natality` WHERE weight_pounds IS NOT NULL AND mother_age IS NOT NULL AND father_age IS NOT NULL AND gestation_weeks IS NOT NULL AND weight_gain_pounds IS NOT NULL AND apgar_5min IS NOT NULL
- 約 1 分後にクエリが完了したら、[結果の保存] をクリックし、続いて保存オプションを選択して、結果を「regression_input」BigQuery テーブルとしてプロジェクトの
natality_regressionデータセットに保存します。
- 次のクエリをクエリエディタにコピーして貼り付け、[実行] をクリックします。
Python
Python および Python 用 Google Cloud クライアント ライブラリ(コードの実行に必要)をインストールする方法については、Python 開発環境の設定をご覧ください。Python
virtualenvをインストールして使用することをおすすめします。下の
natality_tutorial.pyコードをローカルマシンのpythonシェルにコピーして貼り付けます。シェルで<return>キーを押してコードを実行し、デフォルトの Google Cloud プロジェクトに「natality_regression」BigQuery データセットを作成して、公表されているnatalityデータのサブセットを「regression_input」テーブルに設定します。natality_regressionデータセットとregression_inputテーブルの作成を確認します。
線形回帰を実行する
このセクションでは、Google Cloud Console を使用して Dataproc サービスにジョブを送信するか、ローカルのターミナルから gcloud コマンドを実行して PySpark 線形回帰を実行します。
Console
ローカルマシンの新しい
natality_sparkml.pyファイルに、次のコードをコピーして貼り付けます。"""Run a linear regression using Apache Spark ML. In the following PySpark (Spark Python API) code, we take the following actions: * Load a previously created linear regression (BigQuery) input table into our Cloud Dataproc Spark cluster as an RDD (Resilient Distributed Dataset) * Transform the RDD into a Spark Dataframe * Vectorize the features on which the model will be trained * Compute a linear regression using Spark ML """ from pyspark.context import SparkContext from pyspark.ml.linalg import Vectors from pyspark.ml.regression import LinearRegression from pyspark.sql.session import SparkSession # The imports, above, allow us to access SparkML features specific to linear # regression as well as the Vectors types. # Define a function that collects the features of interest # (mother_age, father_age, and gestation_weeks) into a vector. # Package the vector in a tuple containing the label (`weight_pounds`) for that # row. def vector_from_inputs(r): return (r["weight_pounds"], Vectors.dense(float(r["mother_age"]), float(r["father_age"]), float(r["gestation_weeks"]), float(r["weight_gain_pounds"]), float(r["apgar_5min"]))) sc = SparkContext() spark = SparkSession(sc) # Read the data from BigQuery as a Spark Dataframe. natality_data = spark.read.format("bigquery").option( "table", "natality_regression.regression_input").load() # Create a view so that Spark SQL queries can be run against the data. natality_data.createOrReplaceTempView("natality") # As a precaution, run a query in Spark SQL to ensure no NULL values exist. sql_query = """ SELECT * from natality where weight_pounds is not null and mother_age is not null and father_age is not null and gestation_weeks is not null """ clean_data = spark.sql(sql_query) # Create an input DataFrame for Spark ML using the above function. training_data = clean_data.rdd.map(vector_from_inputs).toDF(["label", "features"]) training_data.cache() # Construct a new LinearRegression object and fit the training data. lr = LinearRegression(maxIter=5, regParam=0.2, solver="normal") model = lr.fit(training_data) # Print the model summary. print("Coefficients:" + str(model.coefficients)) print("Intercept:" + str(model.intercept)) print("R^2:" + str(model.summary.r2)) model.summary.residuals.show()ローカルの
natality_sparkml.pyファイルをプロジェクトの Cloud Storage バケットにコピーします。gsutil cp natality_sparkml.py gs://bucket-name
Dataproc の [ジョブを送信] ページから回帰を実行します。
[メインの Python ファイル] フィールドで、
natality_sparkml.pyファイルのコピーが置かれている Cloud Storage バケットのgs://URI を挿入します。[ジョブタイプ] として
PySparkを選択します。gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jarを JAR ファイル フィールドに挿入します。これにより、実行時に spark-bigquery-connector を PySpark アプリケーションで使用できるようになり、BigQuery データを Spark DataFrame に読み込めます。[ジョブ ID]、[リージョン]、[クラスタ] フィールドに入力します。
[送信] をクリックして、クラスタでジョブを実行します。
ジョブが完了すると、線形回帰出力モデルの概要が Dataproc の [ジョブの詳細] ウィンドウに表示されます。
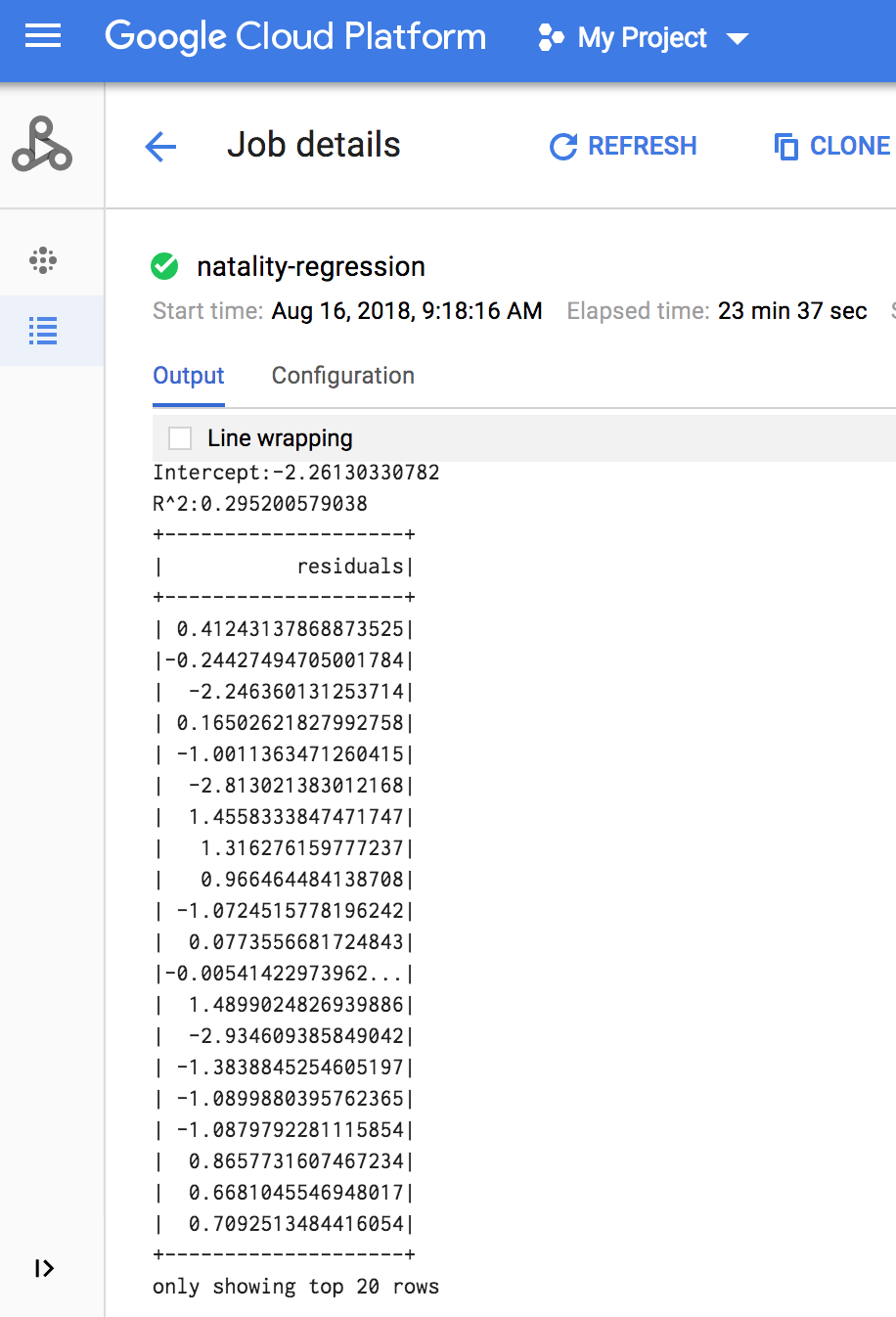
gcloud
ローカルマシンの新しい
natality_sparkml.pyファイルに、次のコードをコピーして貼り付けます。"""Run a linear regression using Apache Spark ML. In the following PySpark (Spark Python API) code, we take the following actions: * Load a previously created linear regression (BigQuery) input table into our Cloud Dataproc Spark cluster as an RDD (Resilient Distributed Dataset) * Transform the RDD into a Spark Dataframe * Vectorize the features on which the model will be trained * Compute a linear regression using Spark ML """ from pyspark.context import SparkContext from pyspark.ml.linalg import Vectors from pyspark.ml.regression import LinearRegression from pyspark.sql.session import SparkSession # The imports, above, allow us to access SparkML features specific to linear # regression as well as the Vectors types. # Define a function that collects the features of interest # (mother_age, father_age, and gestation_weeks) into a vector. # Package the vector in a tuple containing the label (`weight_pounds`) for that # row. def vector_from_inputs(r): return (r["weight_pounds"], Vectors.dense(float(r["mother_age"]), float(r["father_age"]), float(r["gestation_weeks"]), float(r["weight_gain_pounds"]), float(r["apgar_5min"]))) sc = SparkContext() spark = SparkSession(sc) # Read the data from BigQuery as a Spark Dataframe. natality_data = spark.read.format("bigquery").option( "table", "natality_regression.regression_input").load() # Create a view so that Spark SQL queries can be run against the data. natality_data.createOrReplaceTempView("natality") # As a precaution, run a query in Spark SQL to ensure no NULL values exist. sql_query = """ SELECT * from natality where weight_pounds is not null and mother_age is not null and father_age is not null and gestation_weeks is not null """ clean_data = spark.sql(sql_query) # Create an input DataFrame for Spark ML using the above function. training_data = clean_data.rdd.map(vector_from_inputs).toDF(["label", "features"]) training_data.cache() # Construct a new LinearRegression object and fit the training data. lr = LinearRegression(maxIter=5, regParam=0.2, solver="normal") model = lr.fit(training_data) # Print the model summary. print("Coefficients:" + str(model.coefficients)) print("Intercept:" + str(model.intercept)) print("R^2:" + str(model.summary.r2)) model.summary.residuals.show()ローカルの
natality_sparkml.pyファイルをプロジェクトの Cloud Storage バケットにコピーします。gsutil cp natality_sparkml.py gs://bucket-name
下に示すようにローカルマシンのターミナル ウィンドウから
gcloudコマンドを実行することにより、Pyspark ジョブを Dataproc サービスに送信します。- --jars フラグの値を指定することで、実行時に spark-bigquery-connector を PySpark jobv で使用できるようになり、BigQuery データを Spark DataFrame に読み込めます。
gcloud dataproc jobs submit pyspark \ gs://your-bucket/natality_sparkml.py \ --cluster=cluster-name \ --region=region \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_SCALA_VERSION-CONNECTOR_VERSION.jar
- --jars フラグの値を指定することで、実行時に spark-bigquery-connector を PySpark jobv で使用できるようになり、BigQuery データを Spark DataFrame に読み込めます。
ジョブが完了すると、線形回帰出力(モデル概要)がターミナル ウィンドウに表示されます。
<<< # Print the model summary. ... print "Coefficients:" + str(model.coefficients) Coefficients:[0.0166657454602,-0.00296751984046,0.235714392936,0.00213002070133,-0.00048577251587] <<< print "Intercept:" + str(model.intercept) Intercept:-2.26130330748 <<< print "R^2:" + str(model.summary.r2) R^2:0.295200579035 <<< model.summary.residuals.show() +--------------------+ | residuals| +--------------------+ | -0.7234737533344147| | -0.985466980630501| | -0.6669710598385468| | 1.4162434829714794| |-0.09373154375186754| |-0.15461747949235072| | 0.32659061654192545| | 1.5053877697929803| | -0.640142797263989| | 1.229530260294963| |-0.03776160295256...| | -0.5160734239126814| | -1.5165972740062887| | 1.3269085258245008| | 1.7604670124710626| | 1.2348130901905972| | 2.318660276655887| | 1.0936947030883175| | 1.0169768511417363| | -1.7744915698181583| +--------------------+ only showing top 20 rows.
クリーンアップ
チュートリアルが終了したら、作成したリソースをクリーンアップして、割り当ての使用を停止し、課金されないようにできます。次のセクションで、リソースを削除または無効にする方法を説明します。
プロジェクトの削除
課金をなくす最も簡単な方法は、チュートリアル用に作成したプロジェクトを削除することです。
プロジェクトを削除するには:
- Google Cloud コンソールで、[リソースの管理] ページに移動します。
- プロジェクト リストで、削除するプロジェクトを選択し、[削除] をクリックします。
- ダイアログでプロジェクト ID を入力し、[シャットダウン] をクリックしてプロジェクトを削除します。
Dataproc クラスタの削除
クラスタの削除をご覧ください。
次のステップ
- Spark ジョブ調整のヒントを見る。