Le Connecteur BigQuery pour Apache Spark permet aux data scientists d'associer la puissance du moteur SQL évolutif de BigQuery aux capacités de machine learning d'Apache Spark. Dans ce tutoriel, vous apprendrez à utiliser Dataproc, BigQuery et Apache Spark ML pour effectuer des opérations de machine learning sur un ensemble de données.
Objectifs
Utilisez la régression linéaire pour créer un modèle de poids de naissance en fonction des cinq facteurs suivants :- Semaines de gestation
- âge de la mère
- âge du père
- prise de poids de la mère pendant la grossesse
- Score Apgar
Utilisez les outils suivants:
- BigQuery, pour préparer la table d'entrée de régression linéaire, qui est écrite dans votre projet Google Cloud
- Python, pour interroger et gérer des données dans BigQuery
- Apache Spark, pour accéder à la table de régression linéaire qui en résulte
- Spark ML pour créer et évaluer le modèle
- Tâche Dataproc PySpark, pour appeler des fonctions Spark ML
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
- Compute Engine
- Dataproc
- BigQuery
Obtenez une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Avant de commencer
Les composants Spark, y compris Spark ML, sont installés sur un cluster Dataproc. Pour configurer un cluster Dataproc et exécuter le code dans cet exemple, vous devez effectuer (ou faire en sorte que s'effectuent) les opérations suivantes :
- Connectez-vous à votre compte Google Cloud. Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $ de crédits gratuits pour exécuter, tester et déployer des charges de travail.
-
Dans Google Cloud Console, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
-
Activer les API Dataproc, BigQuery, Compute Engine.
- Installez Google Cloud CLI.
-
Pour initialiser gcloudCLI, exécutez la commande suivante :
gcloud init
-
Dans Google Cloud Console, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
-
Activer les API Dataproc, BigQuery, Compute Engine.
- Installez Google Cloud CLI.
-
Pour initialiser gcloudCLI, exécutez la commande suivante :
gcloud init
- Créez un cluster Dataproc dans votre projet. Le cluster doit exécuter une version Dataproc avec Spark 2.0 ou une version ultérieure (y compris les bibliothèques de machine learning).
Créer un sous-ensemble de données natality BigQuery
Dans cette section, vous créez un ensemble de données dans votre projet, puis une table dans cet ensemble de données. Copiez un sous-ensemble de données dans la table regroupant des données de taux de natalité, issues de l'ensemble de données publiques natality BigQuery. Dans la suite de ce tutoriel, vous utiliserez les données du sous-ensemble de cette table pour prédire le poids de naissance en fonction de l'âge de la mère, de l'âge du père et du nombre de semaines de gestation.
Vous pouvez créer le sous-ensemble de données à l'aide de la console Google Cloud ou en exécutant un script Python sur votre ordinateur local.
Console
Créez un ensemble de données dans votre projet.
- Accédez à l'interface utilisateur Web de BigQuery.
- Dans le volet de navigation de gauche, cliquez sur le nom de votre projet, puis sur CREATE DATASET (Créer un ensemble de données).
- Dans la boîte de dialogue Créer un ensemble de données :
- Dans le champ Dataset ID (ID de l'ensemble de données), saisissez "natality_regression".
- Dans le champ Emplacement des données, sélectionnez un emplacement pour l'ensemble de données. La valeur par défaut est
US multi-region. Une fois l'ensemble de données créé, l'emplacement ne peut plus être modifié. - Pour Expiration de la table par défaut, choisissez l'une des options suivantes :
- Jamais (par défaut) : vous devez supprimer la table manuellement.
- Nombre de jours : la table est supprimée une fois le nombre de jours spécifié écoulé, à compter de sa date de création.
- Pour Chiffrement, choisissez l'une des options suivantes :
- Clé gérée par Google (par défaut)
- Clé gérée par le client : consultez la page Protéger des données avec des clés Cloud KMS
- Cliquez sur Créer un ensemble de données.
Exécutez une requête sur l'ensemble de données public "natality", puis enregistrez les résultats de la requête dans une nouvelle table de l'ensemble de données.
- Copiez et collez la requête suivante dans l'éditeur de requête, puis cliquez sur "Exécuter".
SELECT weight_pounds, mother_age, father_age, gestation_weeks, weight_gain_pounds, apgar_5min FROM `bigquery-public-data.samples.natality` WHERE weight_pounds IS NOT NULL AND mother_age IS NOT NULL AND father_age IS NOT NULL AND gestation_weeks IS NOT NULL AND weight_gain_pounds IS NOT NULL AND apgar_5min IS NOT NULL
- Une fois la requête exécutée (après environ 1 minute), cliquez sur ENREGISTRER LES RÉSULTATS, puis sélectionnez les options d'enregistrement pour enregistrer les résultats en tant que table BigQuery "regression_input" dans l'ensemble de données
natality_regressionde votre projet.
- Copiez et collez la requête suivante dans l'éditeur de requête, puis cliquez sur "Exécuter".
Python
Consultez la page Configurer un environnement de développement Python pour obtenir des instructions sur l'installation de Python et de la bibliothèque cliente Google Cloud pour Python (nécessaire à l'exécution du code). Il est recommandé d'installer et d'utiliser un environnement
virtualenvPython.Copiez et collez le code
natality_tutorial.pyci-dessous dans une interface systèmepythonsur votre machine locale. Appuyez sur la touche<return>dans l'interface système pour exécuter le code permettant de créer un ensemble de données BigQuery "natality_regression" dans votre projet Google Cloud par défaut avec une table "regression_input", laquelle est remplie avec un sous-ensemble de donnéesnatalitypubliques.Confirmez la création de l'ensemble de données
natality_regressionet de la tableregression_input.
Exécuter une régression linéaire
Dans cette section, vous allez exécuter une régression linéaire PySpark en envoyant la tâche au service Dataproc à l'aide de la console Google Cloud ou en exécutant la commande gcloud à partir d'un terminal local.
Console
Copiez et collez le code suivant dans un nouveau fichier
natality_sparkml.pysur votre ordinateur local."""Run a linear regression using Apache Spark ML. In the following PySpark (Spark Python API) code, we take the following actions: * Load a previously created linear regression (BigQuery) input table into our Cloud Dataproc Spark cluster as an RDD (Resilient Distributed Dataset) * Transform the RDD into a Spark Dataframe * Vectorize the features on which the model will be trained * Compute a linear regression using Spark ML """ from pyspark.context import SparkContext from pyspark.ml.linalg import Vectors from pyspark.ml.regression import LinearRegression from pyspark.sql.session import SparkSession # The imports, above, allow us to access SparkML features specific to linear # regression as well as the Vectors types. # Define a function that collects the features of interest # (mother_age, father_age, and gestation_weeks) into a vector. # Package the vector in a tuple containing the label (`weight_pounds`) for that # row. def vector_from_inputs(r): return (r["weight_pounds"], Vectors.dense(float(r["mother_age"]), float(r["father_age"]), float(r["gestation_weeks"]), float(r["weight_gain_pounds"]), float(r["apgar_5min"]))) sc = SparkContext() spark = SparkSession(sc) # Read the data from BigQuery as a Spark Dataframe. natality_data = spark.read.format("bigquery").option( "table", "natality_regression.regression_input").load() # Create a view so that Spark SQL queries can be run against the data. natality_data.createOrReplaceTempView("natality") # As a precaution, run a query in Spark SQL to ensure no NULL values exist. sql_query = """ SELECT * from natality where weight_pounds is not null and mother_age is not null and father_age is not null and gestation_weeks is not null """ clean_data = spark.sql(sql_query) # Create an input DataFrame for Spark ML using the above function. training_data = clean_data.rdd.map(vector_from_inputs).toDF(["label", "features"]) training_data.cache() # Construct a new LinearRegression object and fit the training data. lr = LinearRegression(maxIter=5, regParam=0.2, solver="normal") model = lr.fit(training_data) # Print the model summary. print("Coefficients:" + str(model.coefficients)) print("Intercept:" + str(model.intercept)) print("R^2:" + str(model.summary.r2)) model.summary.residuals.show()Copiez le fichier
natality_sparkml.pylocal dans un bucket Cloud Storage de votre projet.gsutil cp natality_sparkml.py gs://bucket-name
Exécutez la régression depuis la page Dataproc Envoyer une tâche.
Dans le champ Fichier Python principal, insérez l'URI
gs://du bucket Cloud Storage dans lequel se trouve votre copie du fichiernatality_sparkml.py.Sélectionnez
PySparkcomme type de tâche.Insérez
gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jardans le champ Fichiers JAR. Cela met ainsi le connecteur spark-bigquery à la disposition de l'application PySpark au moment de l'exécution, de sorte qu'elle puisse lire les données BigQuery dans un DataFrame Spark.Renseignez les champs ID de tâche, Région et Cluster.
Cliquez sur Envoyer pour exécuter la tâche sur votre cluster.
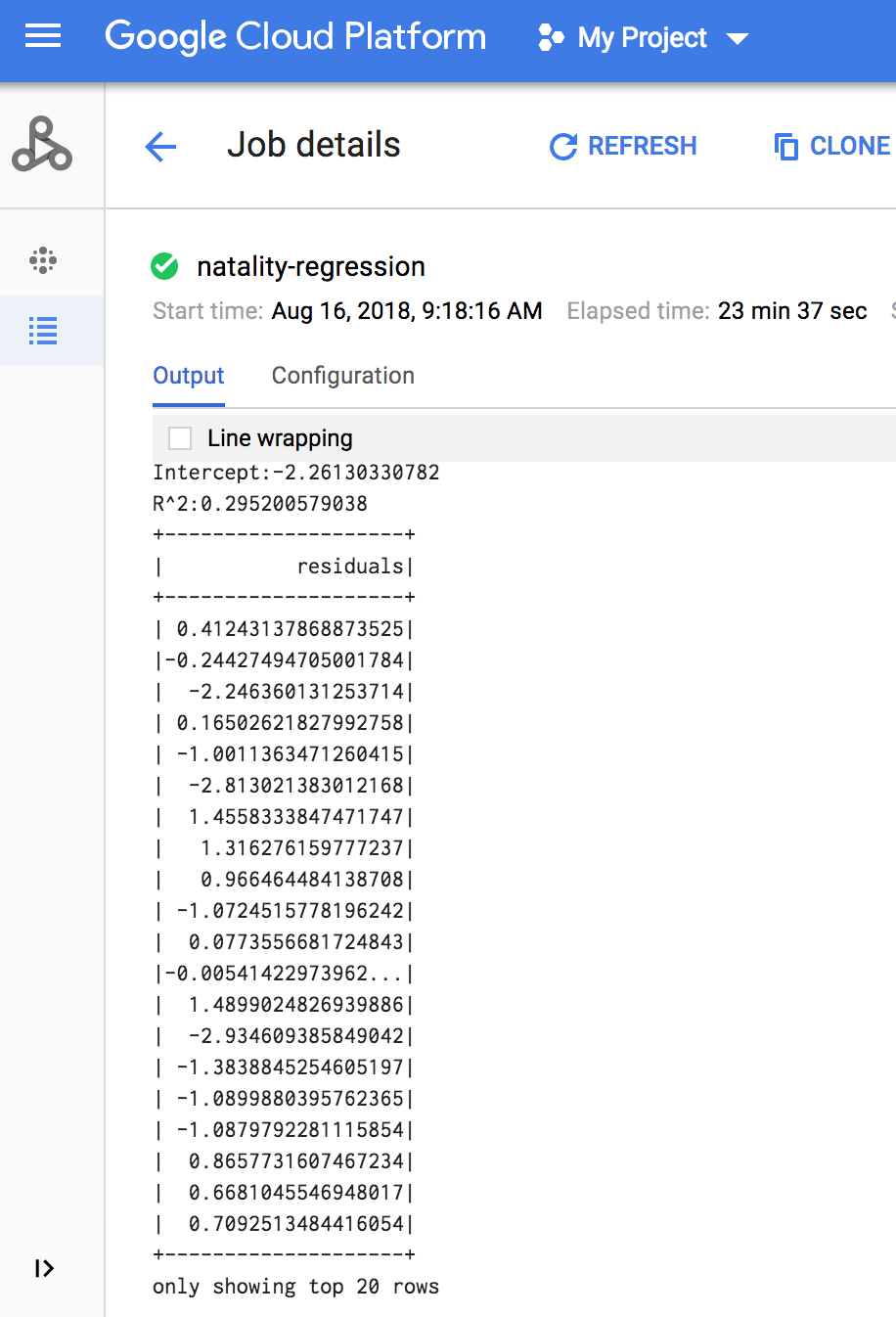
Une fois la tâche terminée, le résumé du modèle de sortie de régression linéaire s'affiche dans la fenêtre "Détails de la tâche Dataproc".
gcloud
Copiez et collez le code suivant dans un nouveau fichier
natality_sparkml.pysur votre ordinateur local."""Run a linear regression using Apache Spark ML. In the following PySpark (Spark Python API) code, we take the following actions: * Load a previously created linear regression (BigQuery) input table into our Cloud Dataproc Spark cluster as an RDD (Resilient Distributed Dataset) * Transform the RDD into a Spark Dataframe * Vectorize the features on which the model will be trained * Compute a linear regression using Spark ML """ from pyspark.context import SparkContext from pyspark.ml.linalg import Vectors from pyspark.ml.regression import LinearRegression from pyspark.sql.session import SparkSession # The imports, above, allow us to access SparkML features specific to linear # regression as well as the Vectors types. # Define a function that collects the features of interest # (mother_age, father_age, and gestation_weeks) into a vector. # Package the vector in a tuple containing the label (`weight_pounds`) for that # row. def vector_from_inputs(r): return (r["weight_pounds"], Vectors.dense(float(r["mother_age"]), float(r["father_age"]), float(r["gestation_weeks"]), float(r["weight_gain_pounds"]), float(r["apgar_5min"]))) sc = SparkContext() spark = SparkSession(sc) # Read the data from BigQuery as a Spark Dataframe. natality_data = spark.read.format("bigquery").option( "table", "natality_regression.regression_input").load() # Create a view so that Spark SQL queries can be run against the data. natality_data.createOrReplaceTempView("natality") # As a precaution, run a query in Spark SQL to ensure no NULL values exist. sql_query = """ SELECT * from natality where weight_pounds is not null and mother_age is not null and father_age is not null and gestation_weeks is not null """ clean_data = spark.sql(sql_query) # Create an input DataFrame for Spark ML using the above function. training_data = clean_data.rdd.map(vector_from_inputs).toDF(["label", "features"]) training_data.cache() # Construct a new LinearRegression object and fit the training data. lr = LinearRegression(maxIter=5, regParam=0.2, solver="normal") model = lr.fit(training_data) # Print the model summary. print("Coefficients:" + str(model.coefficients)) print("Intercept:" + str(model.intercept)) print("R^2:" + str(model.summary.r2)) model.summary.residuals.show()Copiez le fichier
natality_sparkml.pylocal dans un bucket Cloud Storage de votre projet.gsutil cp natality_sparkml.py gs://bucket-name
Envoyez la tâche Pyspark au service Dataproc en exécutant la commande
gcloud, illustrée ci-dessous, à partir d'une fenêtre de terminal sur votre machine locale.- La valeur de l'indicateur --jars met le connecteur spark-bigquery à la disposition de la tâche PySpark au moment de l'exécution pour lui permettre de lire les données BigQuery dans un DataFrame Spark.
gcloud dataproc jobs submit pyspark \ gs://your-bucket/natality_sparkml.py \ --cluster=cluster-name \ --region=region \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_SCALA_VERSION-CONNECTOR_VERSION.jar
- La valeur de l'indicateur --jars met le connecteur spark-bigquery à la disposition de la tâche PySpark au moment de l'exécution pour lui permettre de lire les données BigQuery dans un DataFrame Spark.
Les résultats de la régression linéaire (résumé du modèle) s'affichent dans la fenêtre du terminal une fois la tâche terminée.
<<< # Print the model summary. ... print "Coefficients:" + str(model.coefficients) Coefficients:[0.0166657454602,-0.00296751984046,0.235714392936,0.00213002070133,-0.00048577251587] <<< print "Intercept:" + str(model.intercept) Intercept:-2.26130330748 <<< print "R^2:" + str(model.summary.r2) R^2:0.295200579035 <<< model.summary.residuals.show() +--------------------+ | residuals| +--------------------+ | -0.7234737533344147| | -0.985466980630501| | -0.6669710598385468| | 1.4162434829714794| |-0.09373154375186754| |-0.15461747949235072| | 0.32659061654192545| | 1.5053877697929803| | -0.640142797263989| | 1.229530260294963| |-0.03776160295256...| | -0.5160734239126814| | -1.5165972740062887| | 1.3269085258245008| | 1.7604670124710626| | 1.2348130901905972| | 2.318660276655887| | 1.0936947030883175| | 1.0169768511417363| | -1.7744915698181583| +--------------------+ only showing top 20 rows.
Effectuer un nettoyage
Une fois le tutoriel terminé, vous pouvez procéder au nettoyage des ressources que vous avez créées afin qu'elles ne soient plus comptabilisées dans votre quota et qu'elles ne vous soient plus facturées. Dans les sections suivantes, nous allons voir comment supprimer ou désactiver ces ressources.
Supprimer le projet
Le moyen le plus simple d'empêcher la facturation est de supprimer le projet que vous avez créé pour ce tutoriel.
Pour supprimer le projet :
- Dans la console Google Cloud, accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
Supprimer le cluster Dataproc
Consultez la section Supprimer un cluster.
Étapes suivantes
- Consultez les conseils d'optimisation des tâches Spark.