既存の Dataproc クラスタにジョブを送信するには、いくつかの方法があります。たとえば、Dataproc API の jobs.submit を HTTP リクエストまたはプログラム リクエストで使用します。また、ローカル ターミナル ウィンドウまたは Cloud Shell で Google Cloud CLI の gcloud コマンドライン ツールを使用することも、ローカル ブラウザで Google Cloud Console を開いて送信することもできます。また、クラスタ内のマスター インスタンスに SSH で接続し、Dataproc サービスを使用せずにインスタンスから直接ジョブを実行することも可能です。
ジョブの送信方法
Console
ブラウザの Google Cloud コンソールで Dataproc の [ジョブを送信] ページを開きます。
Spark ジョブの例
サンプルの Spark ジョブを送信するには、[ジョブを送信] ページで次のようにフィールドに値を入力します。
- クラスタリストから [クラスタ] 名を選択します。
- [ジョブタイプ] を
Sparkに設定します。 - [メインクラスまたは JAR] を
org.apache.spark.examples.SparkPiに設定します。 - [引数] を唯一の引数
1000に設定します。 file:///usr/lib/spark/examples/jars/spark-examples.jarを [JAR ファイル] に追加します。file:///は、Hadoop LocalFileSystem スキームを表します。クラスタの作成時に、Dataproc により/usr/lib/spark/examples/jars/spark-examples.jarがクラスタのマスターノードにインストールされています。- あるいは、いずれかの jar の Cloud Storage パス(
gs://your-bucket/your-jarfile.jar)または Hadoop 分散ファイル システムのパス(hdfs://path-to-jar.jar)を指定することもできます。
[送信] をクリックしてジョブを開始します。ジョブが開始されると、ジョブのリストにジョブが追加されます。
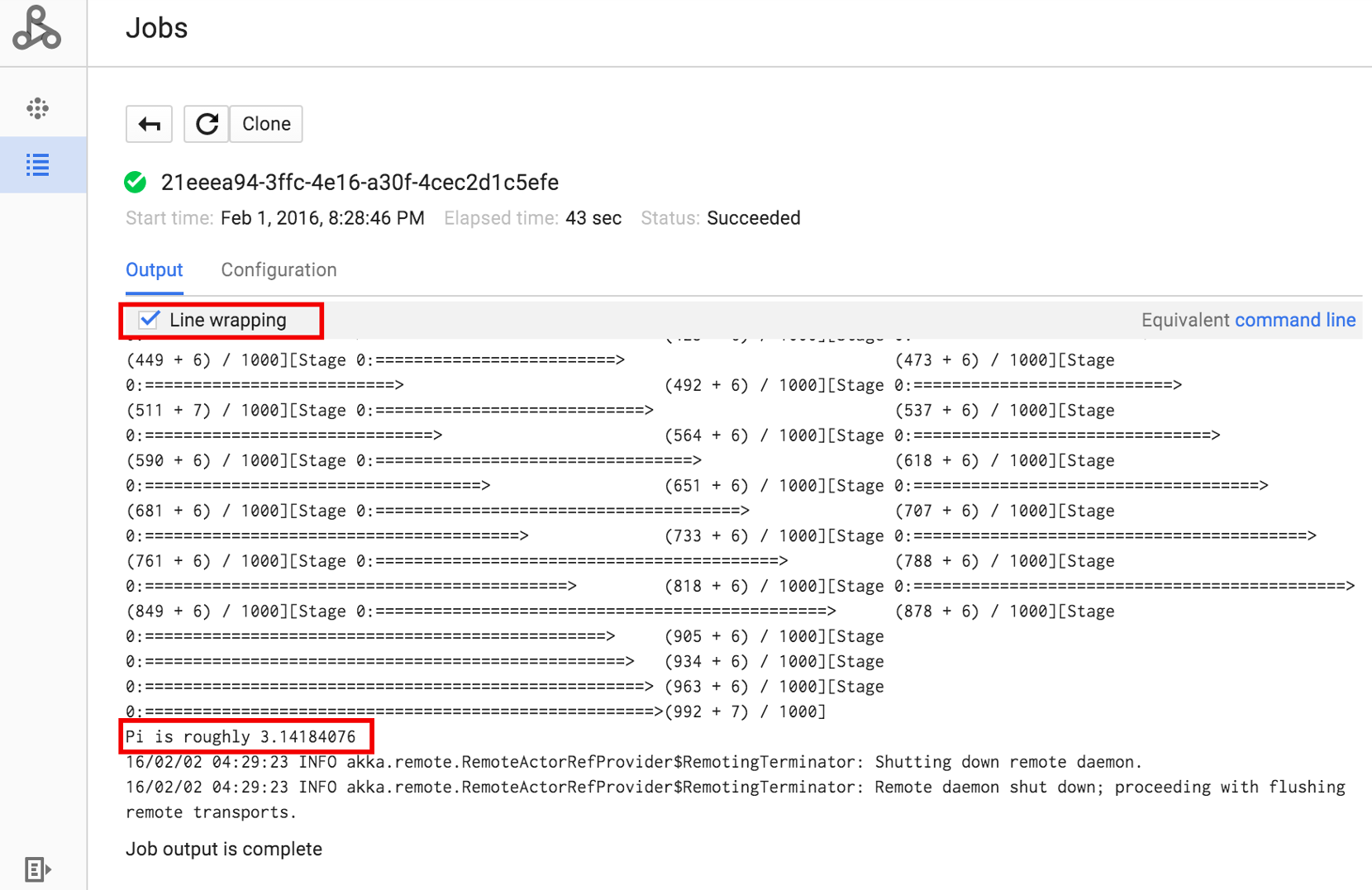
ジョブ ID をクリックして [ジョブ] ページを開くと、ジョブのドライバ出力が表示されます。このジョブはブラウザのウィンドウ幅を超える長い出力行を生成するため、pi の計算結果を表示するには [行の折り返し] チェックボックスをオンにして、すべての出力テキストがウィンドウ内に表示されるようにします。
コマンドラインからジョブのドライバ出力を表示するには、次のように gcloud dataproc jobs wait コマンドを使用します(詳細については、ジョブ出力を表示する - GCLOUD COMMAND をご覧ください)。プロジェクト ID をコピーして、--project フラグの値として貼り付け、ジョブ ID([ジョブ] リストに表示されています)をコピーして、最後の引数として貼り付けます。
gcloud dataproc jobs wait job-id \ --project=project-id \ --region=region
次に、上の手順で送信したサンプルの SparkPi ジョブのドライバ出力のスニペットを示します。
... 2015-06-25 23:27:23,810 INFO [dag-scheduler-event-loop] scheduler.DAGScheduler (Logging.scala:logInfo(59)) - Stage 0 (reduce at SparkPi.scala:35) finished in 21.169 s 2015-06-25 23:27:23,810 INFO [task-result-getter-3] cluster.YarnScheduler (Logging.scala:logInfo(59)) - Removed TaskSet 0.0, whose tasks have all completed, from pool 2015-06-25 23:27:23,819 INFO [main] scheduler.DAGScheduler (Logging.scala:logInfo(59)) - Job 0 finished: reduce at SparkPi.scala:35, took 21.674931 s Pi is roughly 3.14189648 ... Job [c556b47a-4b46-4a94-9ba2-2dcee31167b2] finished successfully. driverOutputUri: gs://sample-staging-bucket/google-cloud-dataproc-metainfo/cfeaa033-749e-48b9-... ...
gcloud
Dataproc クラスタにジョブを送信するには、ターミナル ウィンドウまたは Cloud Shell で gcloud CLI の gcloud dataproc jobs submit コマンドをローカルに実行します。
gcloud dataproc jobs submit job-command \ --cluster=cluster-name \ --region=region \ other dataproc-flags \ -- job-argsPySpark ジョブ送信の例
- Cloud Storage にある一般公開されている
hello-world.pyを一覧表示します。gsutil cat gs://dataproc-examples/pyspark/hello-world/hello-world.py
ファイルの一覧表示:#!/usr/bin/python import pyspark sc = pyspark.SparkContext() rdd = sc.parallelize(['Hello,', 'world!']) words = sorted(rdd.collect()) print(words)
- Pyspark ジョブを Dataproc に送信します。
gcloud dataproc jobs submit pyspark \ gs://dataproc-examples/pyspark/hello-world/hello-world.py \ --cluster=cluster-name \ --region=region
ターミナル出力:Waiting for job output... … ['Hello,', 'world!'] Job finished successfully.
- Dataproc クラスタ上のマスターノードにプリインストールされている SparkPi サンプルを実行します。
gcloud dataproc jobs submit spark \ --cluster=cluster-name \ --region=region \ --class=org.apache.spark.examples.SparkPi \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 1000
ターミナル出力:Job [54825071-ae28-4c5b-85a5-58fae6a597d6] submitted. Waiting for job output… … Pi is roughly 3.14177148 … Job finished successfully. …
REST
このセクションでは、Dataproc の jobs.submit API を使用して pi の近似値を計算する Spark ジョブを送信する方法を説明します。
リクエストのデータを使用する前に、次のように置き換えます。
- project-id: Google Cloud プロジェクト ID
- region: クラスタ リージョン
- clusterName: クラスタ名
HTTP メソッドと URL:
POST https://dataproc.googleapis.com/v1/projects/project-id/regions/region/jobs:submit
リクエストの本文(JSON):
{
"job": {
"placement": {
"clusterName": "cluster-name"
},
},
"sparkJob": {
"args": [
"1000"
],
"mainClass": "org.apache.spark.examples.SparkPi",
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
}
}
}
リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
{
"reference": {
"projectId": "project-id",
"jobId": "job-id"
},
"placement": {
"clusterName": "cluster-name",
"clusterUuid": "cluster-Uuid"
},
"sparkJob": {
"mainClass": "org.apache.spark.examples.SparkPi",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "2020-10-07T20:16:21.759Z"
},
"jobUuid": "job-Uuid"
}
Java
- クライアント ライブラリのインストール
- アプリケーションのデフォルト認証情報を設定します。
- コードを実行します。
Python
- クライアント ライブラリのインストール
- アプリケーションのデフォルト認証情報を設定します。
- コードを実行します。
Go
- クライアント ライブラリのインストール
- アプリケーションのデフォルト認証情報を設定します。
- コードを実行します。
Node.js
- クライアント ライブラリのインストール
- アプリケーションのデフォルト認証情報を設定します。
- コードを実行します。
クラスタに直接ジョブを送信する
Dataproc サービスを使用せずにクラスタで直接ジョブを実行する場合は、クラスタのマスターノードに SSH で接続し、マスターノードでジョブを実行します。
VM マスター インスタンスへの SSH 接続を確立した後、クラスタのマスターノード上のターミナル ウィンドウで次のコマンドを実行します。
- Spark シェルを開きます。
- 一般公開されている Cloud Storage ファイルにある Python で記述された(7 行の)「hello-world」ファイルの行数をカウントする簡単な Spark ジョブを実行します。
shell を終了します。
user@cluster-name-m:~$ spark-shell ... scala> sc.textFile("gs://dataproc-examples" + "/pyspark/hello-world/hello-world.py").count ... res0: Long = 7 scala> :quit
Dataproc で bash ジョブを実行する
使用するエンジンが最上位の Dataproc ジョブタイプとしてサポートされていないか、スクリプトから hadoop や spark-submit を使用するジョブの起動前に追加の調整や引数の計算が必要な場合は、bash スクリプトを Dataproc ジョブとして実行できます。
Pig の例
次のように hello.sh という bash スクリプトを Cloud Storage にコピーしたとします。
gsutil cp hello.sh gs://${BUCKET}/hello.sh
pig fs コマンドは Hadoop パスを使用するため、Cloud Storage から file:/// として指定された宛先にスクリプトをコピーし、HDFS ではなくローカル ファイル システムに配置します。後続の sh コマンドでは、ローカル ファイル システムが自動的に参照され、接頭辞の file:/// は必要ありません。
gcloud dataproc jobs submit pig --cluster=${CLUSTER} --region=${REGION} \
-e='fs -cp -f gs://${BUCKET}/hello.sh file:///tmp/hello.sh; sh chmod 750 /tmp/hello.sh; sh /tmp/hello.sh'
あるいは、--jars 引数を送信する Dataproc ジョブにより、ジョブの存続期間用に作成された一時ディレクトリにファイルがステージングされるため、Cloud Storage シェル スクリプトを --jars 引数として指定できます。
gcloud dataproc jobs submit pig --cluster=${CLUSTER} --region=${REGION} \
--jars=gs://${BUCKET}/hello.sh \
-e='sh chmod 750 ${PWD}/hello.sh; sh ${PWD}/hello.sh'
なお、--jars 引数はローカルのスクリプトを参照できます。
gcloud dataproc jobs submit pig --cluster=${CLUSTER} --region=${REGION} \
--jars=hello.sh \
-e='sh chmod 750 ${PWD}/hello.sh; sh ${PWD}/hello.sh'