Os registros de jobs e clusters do Dataproc podem ser visualizados, pesquisados, filtrados e arquivados no Cloud Logging.
Consulte os Preços de observabilidade do Google Cloud para entender seus custos.
Consulte Períodos de retenção dos registros para obter informações sobre retenção de registros.
Consulte Exclusões de registros para desativar todos os registros ou excluir registros do Logging.
Consulte Visão geral de roteamento e armazenamento para rotear registros do Logging para o Cloud Storage, BigQuery ou Pub/Sub.
Níveis de geração de registros de componentes
Defina os níveis de geração de registros do Spark, Hadoop, Flink e outros componentes do Dataproc com propriedades do cluster log4j específicas do componente, como hadoop-log4j, ao criar um cluster. Os níveis de geração de registros
de componentes baseados em cluster se aplicam aos daemons de serviço, como o YARN ResourceManager,
e aos jobs executados no cluster.
Se as propriedades do log4j não forem compatíveis com um componente, como o componente Presto,
escreva uma ação de inicialização
que edite o arquivo log4j.properties ou log4j2.properties do componente.
Níveis de geração de registros de componentes específicos do job: também é possível definir níveis de geração de registros de componentes ao enviar um job. Esses níveis são aplicados ao job e têm precedência em relação aos níveis de geração de registros definidos quando você criou o cluster. Consulte Propriedades de cluster x job para mais informações.
Níveis de geração de registros da versão dos componentes Spark e Hive:
Os componentes Spark 3.3.X e Hive 3.X usam as propriedades log4j2, enquanto as versões anteriores deles usam propriedades log4j (consulte Apache Log4j2).
Use um prefixo spark-log4j: para definir níveis de geração de registros do Spark em um cluster.
Exemplo: Imagem do Dataproc versão 2.0 com Spark 3.1 para definir
log4j.logger.org.apache.spark:gcloud dataproc clusters create ... \ --properties spark-log4j:log4j.logger.org.apache.spark=DEBUG
Exemplo: imagem do Dataproc versão 2.1 com Spark 3.3 para definir
logger.sparkRoot.level:gcloud dataproc clusters create ...\ --properties spark-log4j:logger.sparkRoot.level=debug
Níveis de registro do driver do job
O Dataproc usa um
nível de geração de registros
padrão de INFO para programas de driver de job. É possível alterar essa configuração para um ou mais pacotes com a sinalização --driver-log-levels gcloud dataproc jobs submit.
Exemplo:
Defina o nível de geração de registros DEBUG ao enviar um job do Spark que lê arquivos do Cloud Storage.
gcloud dataproc jobs submit spark ...\ --driver-log-levels org.apache.spark=DEBUG,com.google.cloud.hadoop.gcsio=DEBUG
Exemplo:
Defina o nível do logger root como WARN e com.example como INFO.
gcloud dataproc jobs submit hadoop ...\ --driver-log-levels root=WARN,com.example=INFO
Níveis de geração de registros do executor do Spark
Para configurar os níveis de geração de registros do executor do Spark:
Preparar um arquivo de configuração do log4j e fazer upload dele para o Cloud Storage
.Faça referência ao arquivo de configuração quando enviar o job.
Exemplo:
gcloud dataproc jobs submit spark ...\ --file gs://my-bucket/path/spark-log4j.properties \ --properties spark.executor.extraJavaOptions=-Dlog4j.configuration=file:spark-log4j.properties
O Spark faz o download do arquivo de propriedades do Cloud Storage para o diretório de trabalho local do job, mencionado como file:<name> em -Dlog4j.configuration.
Registros de jobs do Dataproc no Logging
Consulte Saída e registros do job do Dataproc para informações sobre como ativar os registros do driver do job do Dataproc no Logging.
Acessar os registros de jobs no Logging
Para acessar os registros de jobs do Dataproc, use a Análise de registros, o comando gcloud logging ou a API Logging.
Console
Os registros do driver do job do Dataproc e do YARN estão listados no recurso Job do Cloud Dataproc.
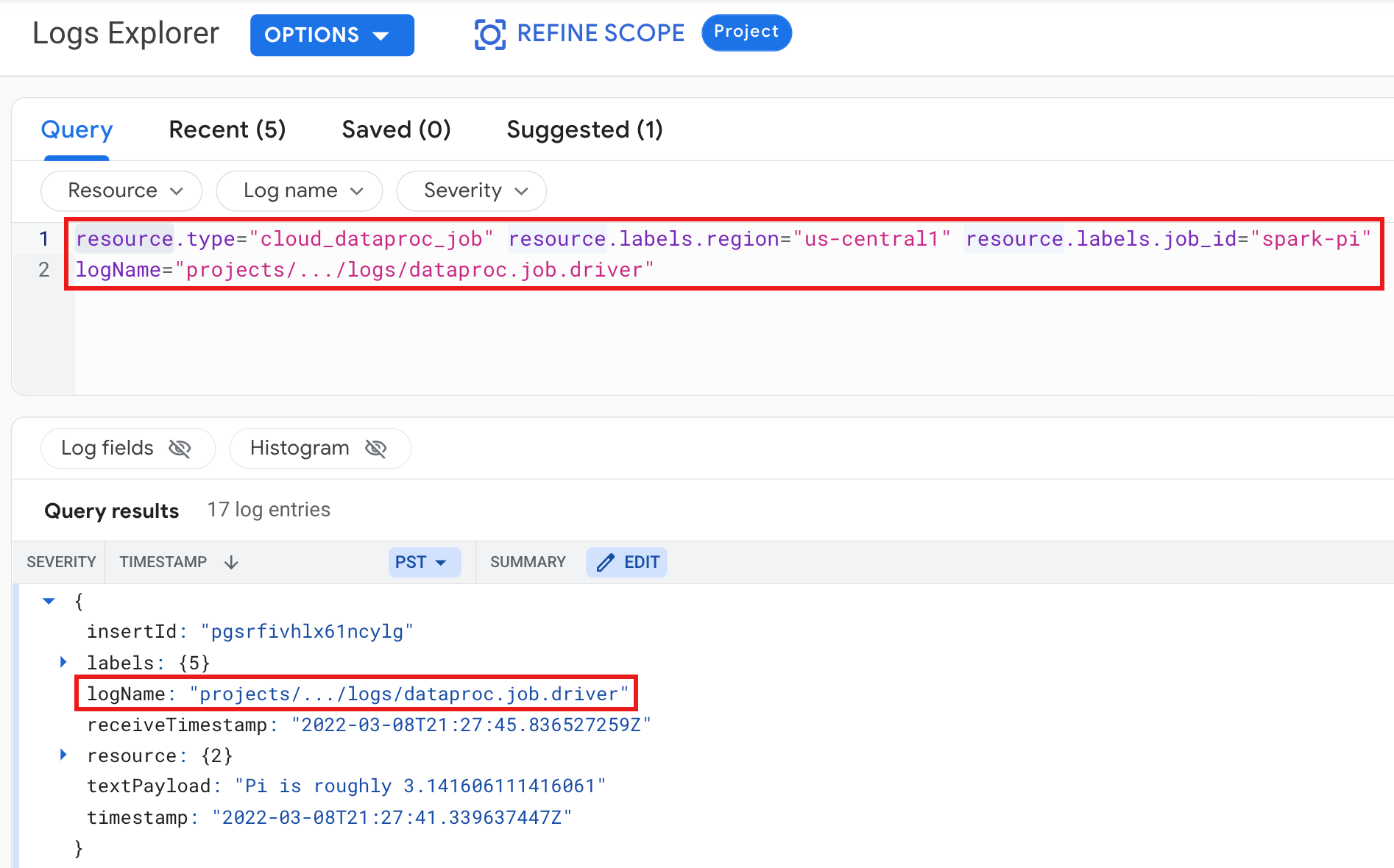
Exemplo: registro do driver do job depois de executar uma consulta da Análise de registros com as seguintes seleções:
- Recurso:
Cloud Dataproc Job - Nome do registro:
dataproc.job.driver
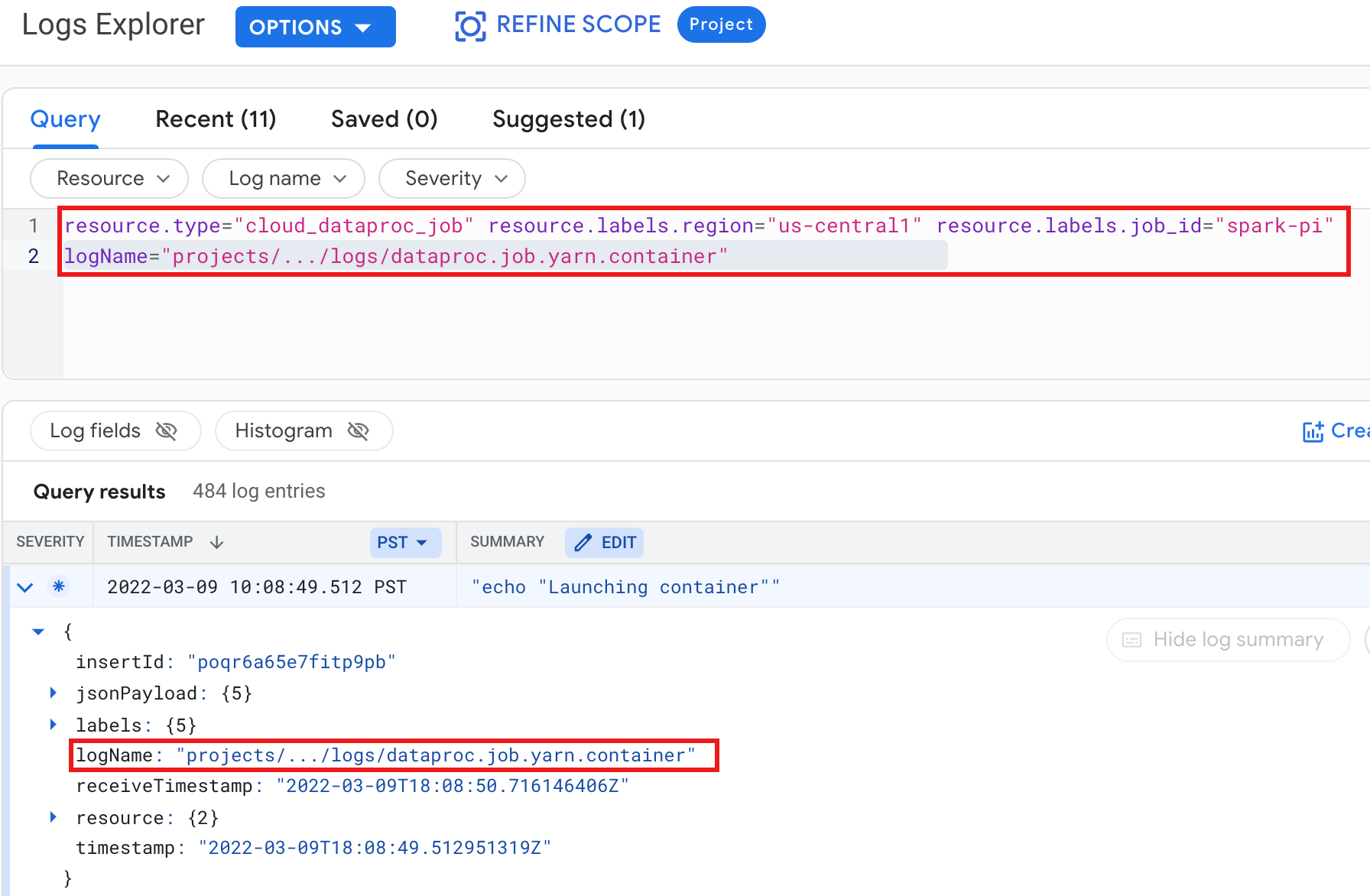
Exemplo: registro do contêiner YARN após executar uma consulta da Análise de registros com as seguintes seleções:
- Recurso:
Cloud Dataproc Job - Nome do registro:
dataproc.job.yarn.container
gcloud
Você pode ler as entradas de registro do job usando o comando gcloud logging read. Os argumentos de recursos precisam estar entre aspas ("..."). O comando a seguir usa rótulos de cluster para filtrar as entradas de registro retornadas.
gcloud logging read \ "resource.type=cloud_dataproc_job \ resource.labels.region=cluster-region \ resource.labels.job_id=my-job-id"
Exemplo de saída (parcial):
jsonPayload: class: org.apache.hadoop.hdfs.StateChange filename: hadoop-hdfs-namenode-test-dataproc-resize-cluster-20190410-38an-m-0.log ,,, logName: projects/project-id/logs/hadoop-hdfs-namenode --- jsonPayload: class: SecurityLogger.org.apache.hadoop.security.authorize.ServiceAuthorizationManager filename: cluster-name-dataproc-resize-cluster-20190410-38an-m-0.log ... logName: projects/google.com:hadoop-cloud-dev/logs/hadoop-hdfs-namenode
API REST
É possível usar a API REST do Logging para listar entradas de registro (consulte entries.list).
Registros de cluster do Dataproc no Logging
O Dataproc exporta os seguintes registros de cluster do Apache Hadoop, Spark, Hive, Zookeeper e outros do Dataproc para o Cloud Logging.
| Tipo de registro | Nome do registro | Descrição |
|---|---|---|
| Registros do daemon principal | hasoop-hdfs hadoop-hdfs-namenode hadoop-hdfs-secondary namenode hadoop-hdfs-zkfc hadoop-yarn-resourcemanager hadoop-yarn-timelineserver hive-metastore hive-server2 mapred-mapred-historyserver zookeeper |
Nó do diário HDFS namenode Namenode secundário do HDFS Controlador de failover do Zookeeper Gerenciador de recursos YaRN Servidor da linha do tempo YaN Metastore do Hive Servidor do Hive2 Servidor do histórico de jobs do MapReduce Servidor do Zookeeper |
| Registros de daemon de worker |
hasoop-hdfs-datanode hadoop-yarn-nodemanager |
Nó de dados HDFS Gerenciador de nós do YARN |
| Registros do sistema |
escalonador automático google.dataproc.agent google.dataproc.startup |
Registro do escalonador automático do Dataproc Registro do agente do Dataproc Registro do script de inicialização do Dataproc + registro da ação de inicialização |
Acessar registros do cluster no Cloud Logging
É possível acessar os registros de cluster do Dataproc usando a Análise de registros, o comando gcloud logging ou a API Logging.
Console
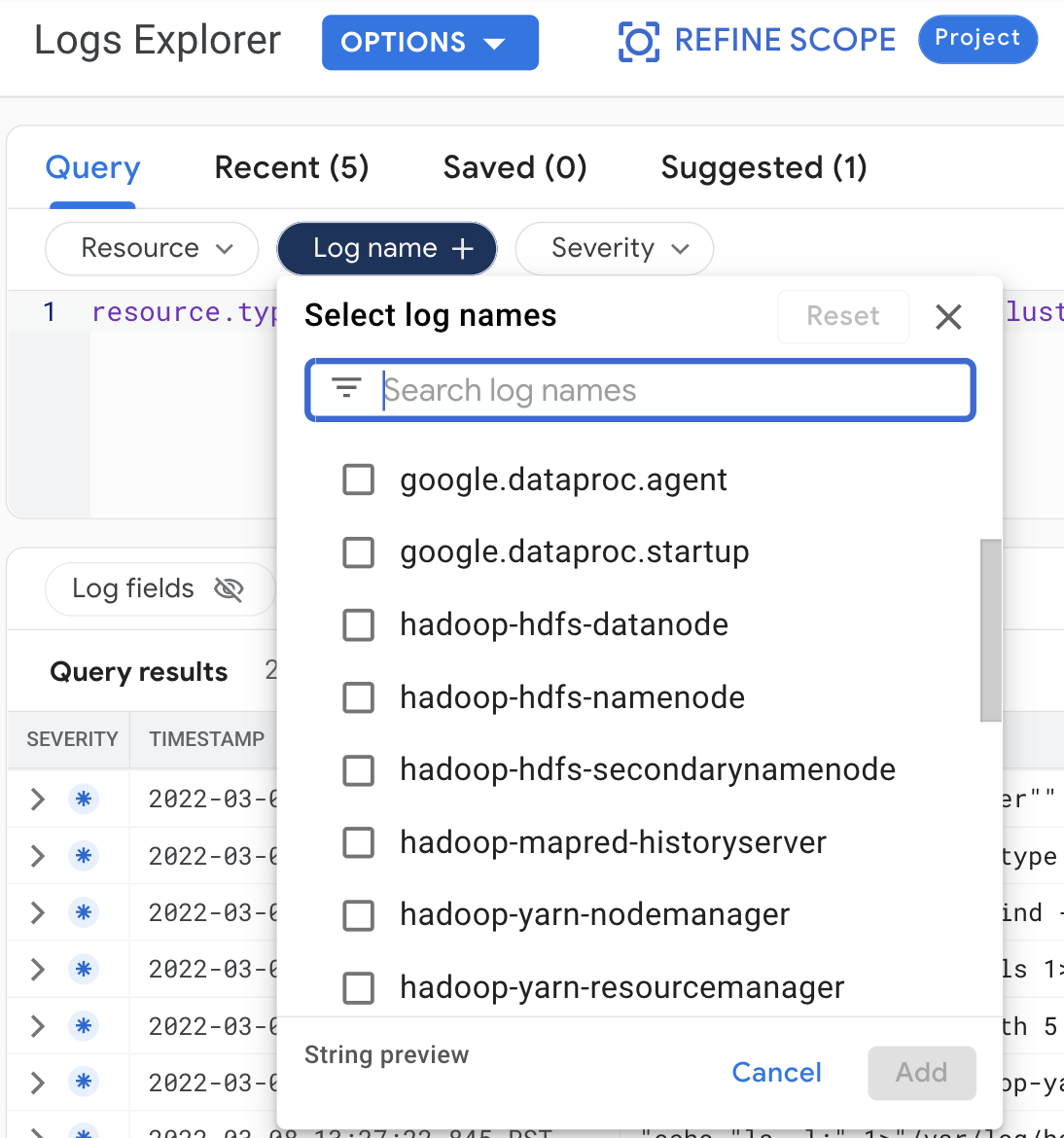
Faça as seguintes seleções de consulta para ver os registros do cluster na Análise de registros:
- Recurso:
Cloud Dataproc Cluster - Nome do registro:log name
gcloud
É possível ler entradas de registro do cluster usando o comando gcloud logging read. Os argumentos de recursos precisam estar entre aspas ("..."). O comando a seguir usa rótulos de cluster para filtrar as entradas de registro retornadas.
gcloud logging read <<'EOF' "resource.type=cloud_dataproc_cluster resource.labels.region=cluster-region resource.labels.cluster_name=cluster-name resource.labels.cluster_uuid=cluster-uuid" EOF
Exemplo de saída (parcial):
jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-cluster-name-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager --- jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-component-gateway-cluster-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager
API REST
É possível usar a API REST do Logging para listar entradas de registro (consulte entries.list).
Permissões
Para gravar registros no Logging, a conta de serviço de VM do Dataproc precisa ter o papel logging.logWriter do IAM. A conta de serviço padrão do Dataproc tem esse papel. Se você usar uma conta de serviço personalizada, precisará atribuir esse papel à conta de serviço.
Como proteger os registros
Por padrão, os registros no Logging são criptografados em repouso. É possível ativar chaves de criptografia gerenciadas pelo cliente (CMEK) para criptografar os registros. Para mais informações sobre o suporte a CMEK, consulte Gerenciar as chaves que protegem os dados do roteador de registros e Gerenciar as chaves que protegem os dados de armazenamento do Logging.
A seguir
- Conheça a Observabilidade do Google Cloud