Cloud Monitoring 可帮助您了解云应用的性能、正常运行时间和整体运行状况。Google Cloud 的运维套件从 Dataproc 集群收集并提取指标、事件和元数据(包括每个集群的 HDFS、YARN、作业和操作指标),以通过信息中心和图表生成数据分析(请参阅 Cloud Monitoring Dataproc 指标)。
使用 Cloud Monitoring 集群指标监控 Dataproc 集群的性能表现和运行状况。
如需了解费用,请参阅 Cloud Monitoring 价格。
如需了解指标数据保留,请参阅 Monitoring 配额和上限。
Dataproc 集群指标
Dataproc 会收集您可以在 Monitoring 中查看的集群资源指标。
查看集群指标
您可以通过 Google Cloud 控制台或使用 Monitoring API 检查 Monitoring。
控制台
-
创建集群后,请转到 Google Cloud 控制台中的 Monitoring 以查看集群监控数据。
出现 Monitoring 控制台后,您可以在项目中的虚拟机上安装 Monitoring 代理,作为额外的设置步骤。您无需在 Dataproc 集群中的虚拟机上安装代理,因为创建 Dataproc 集群时系统会为您执行此步骤。
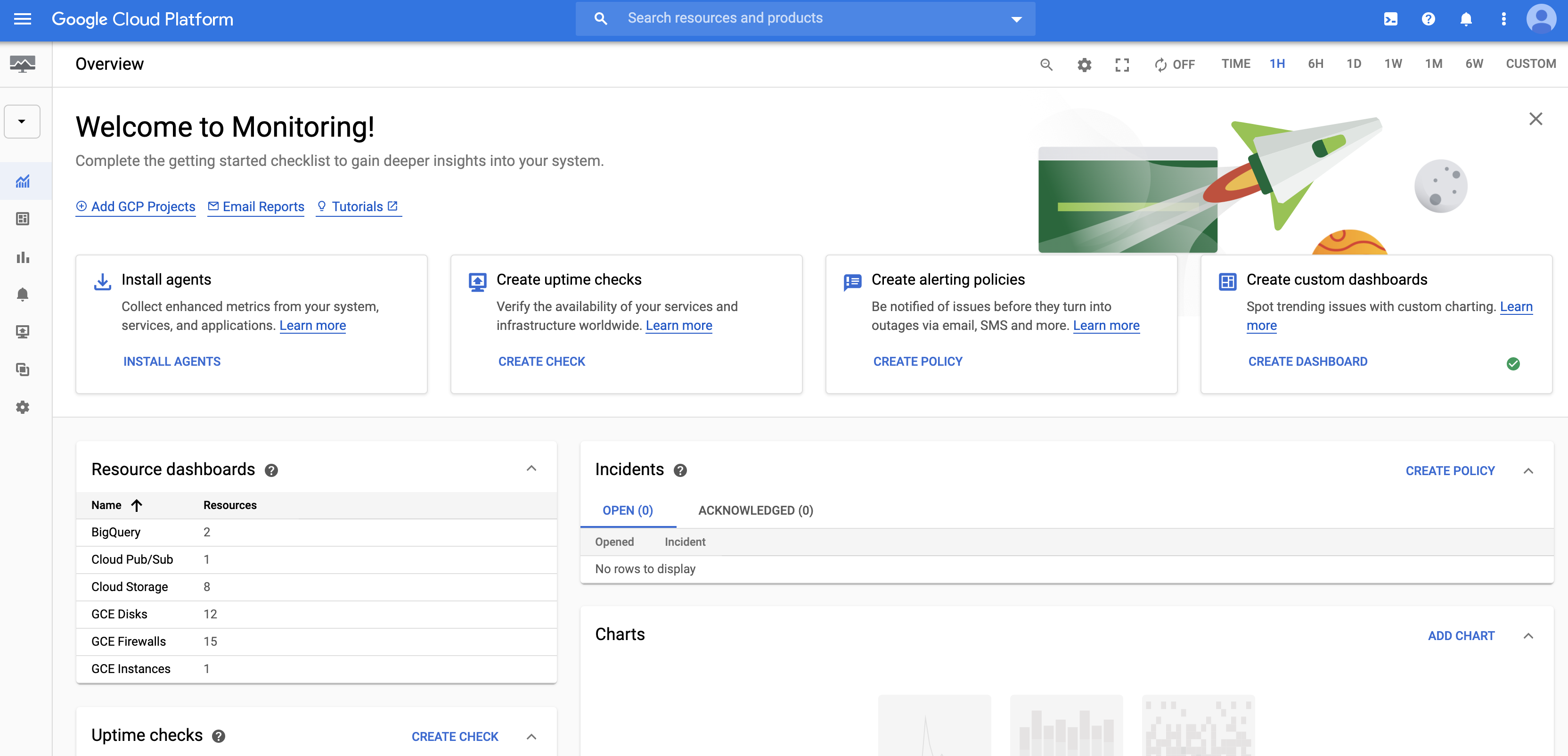
- 选择 Metrics Explorer,在“查找资源类型和指标”下拉列表中,选择“Cloud Dataproc 集群”资源(或在框中输入“cloud_pubsub_cluster”)。
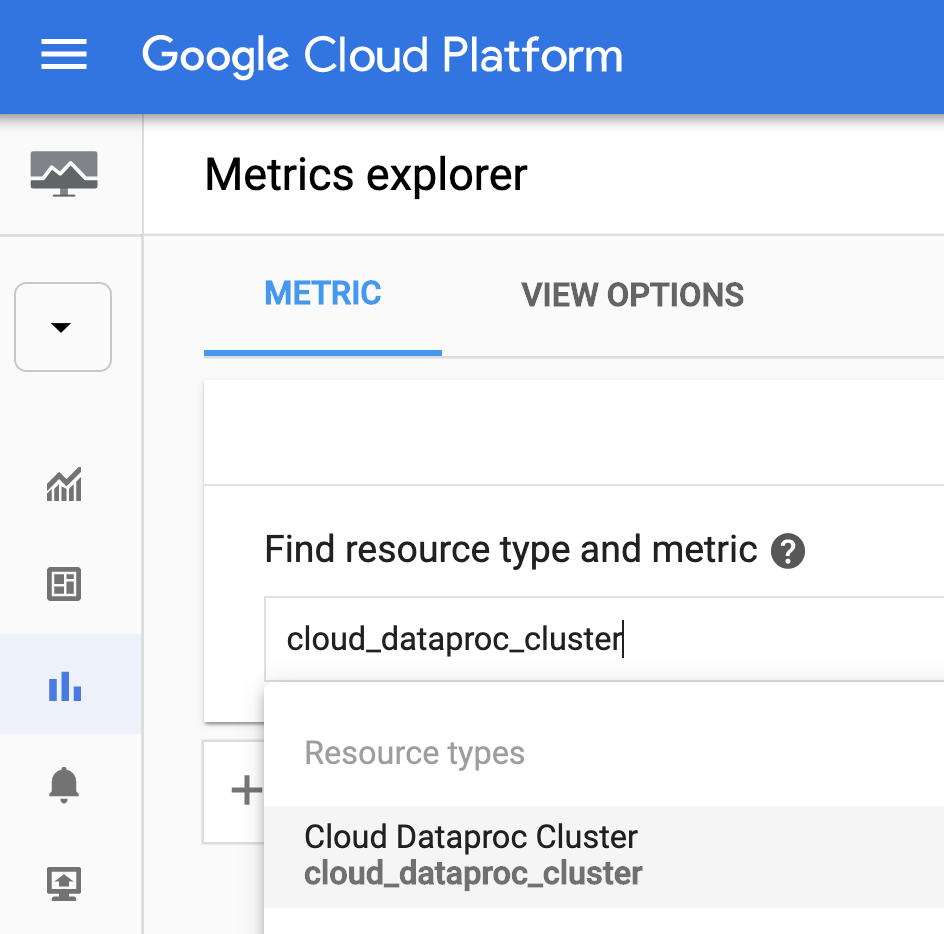
- 再次点击输入框,然后从下拉列表中选择一个指标。
在下一个屏幕截图中,已选择“YARN memory size”。将鼠标悬停在指标名称上可显示指标的相关信息。
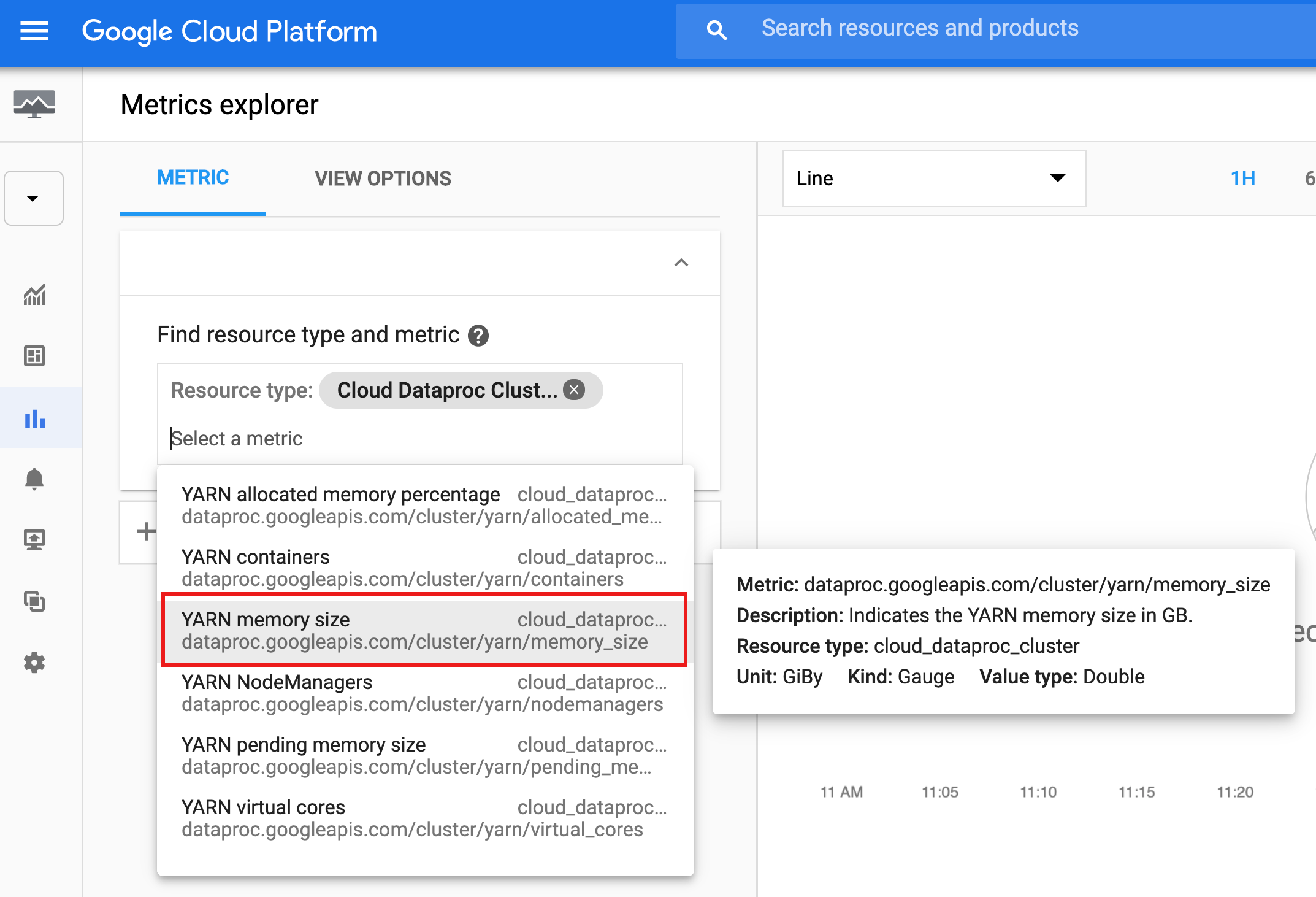
您可以选择过滤条件,按指标标签分组,执行聚合,以及选择图表查看选项(请参阅 Monitoring 文档)。
API
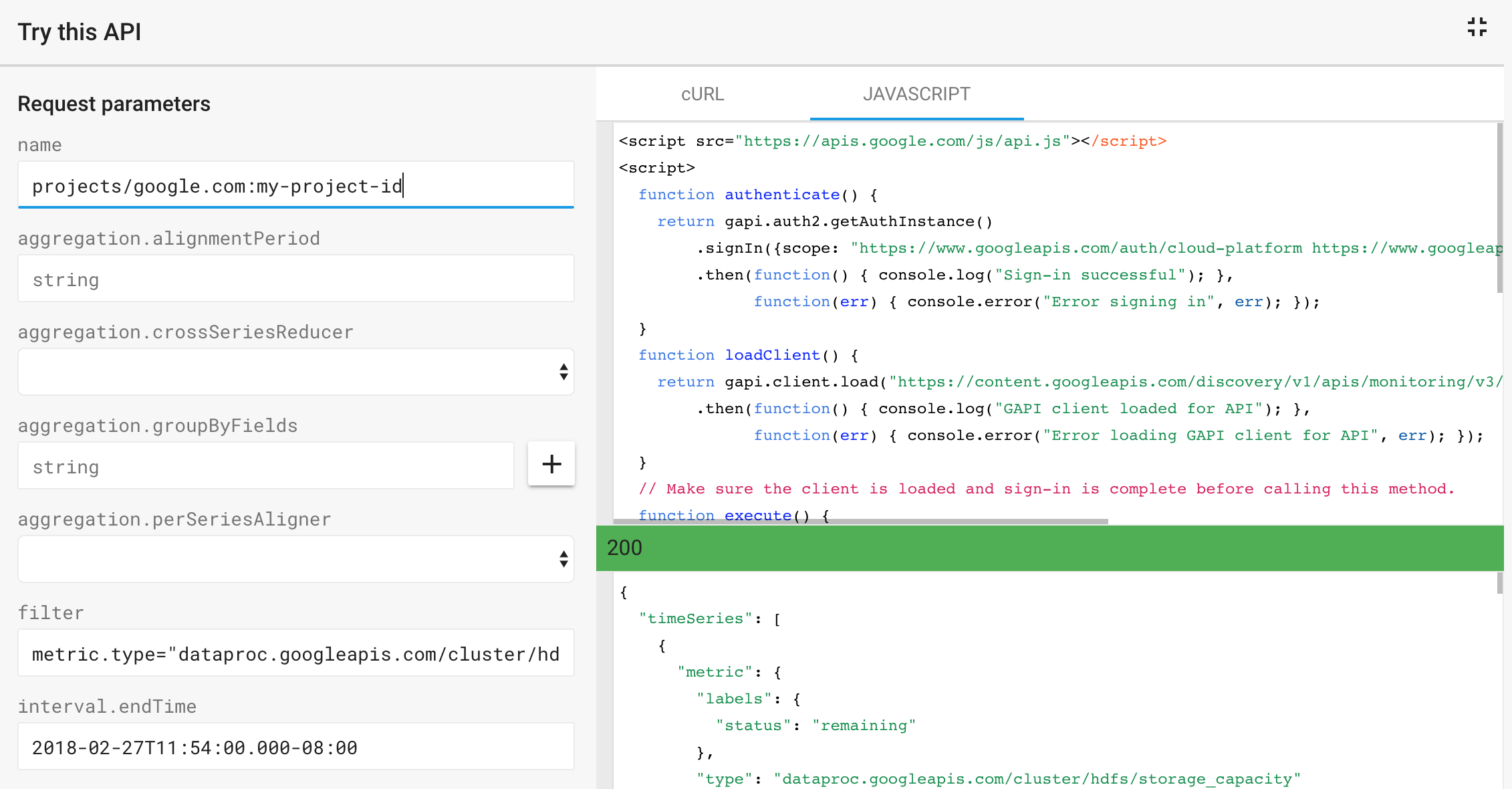
您可以使用 Monitoring timeSeries.list API 来捕获和列出由 filter 表达式定义的指标。使用 API 页面上的试用此 API 模板发送 API 请求并显示响应。
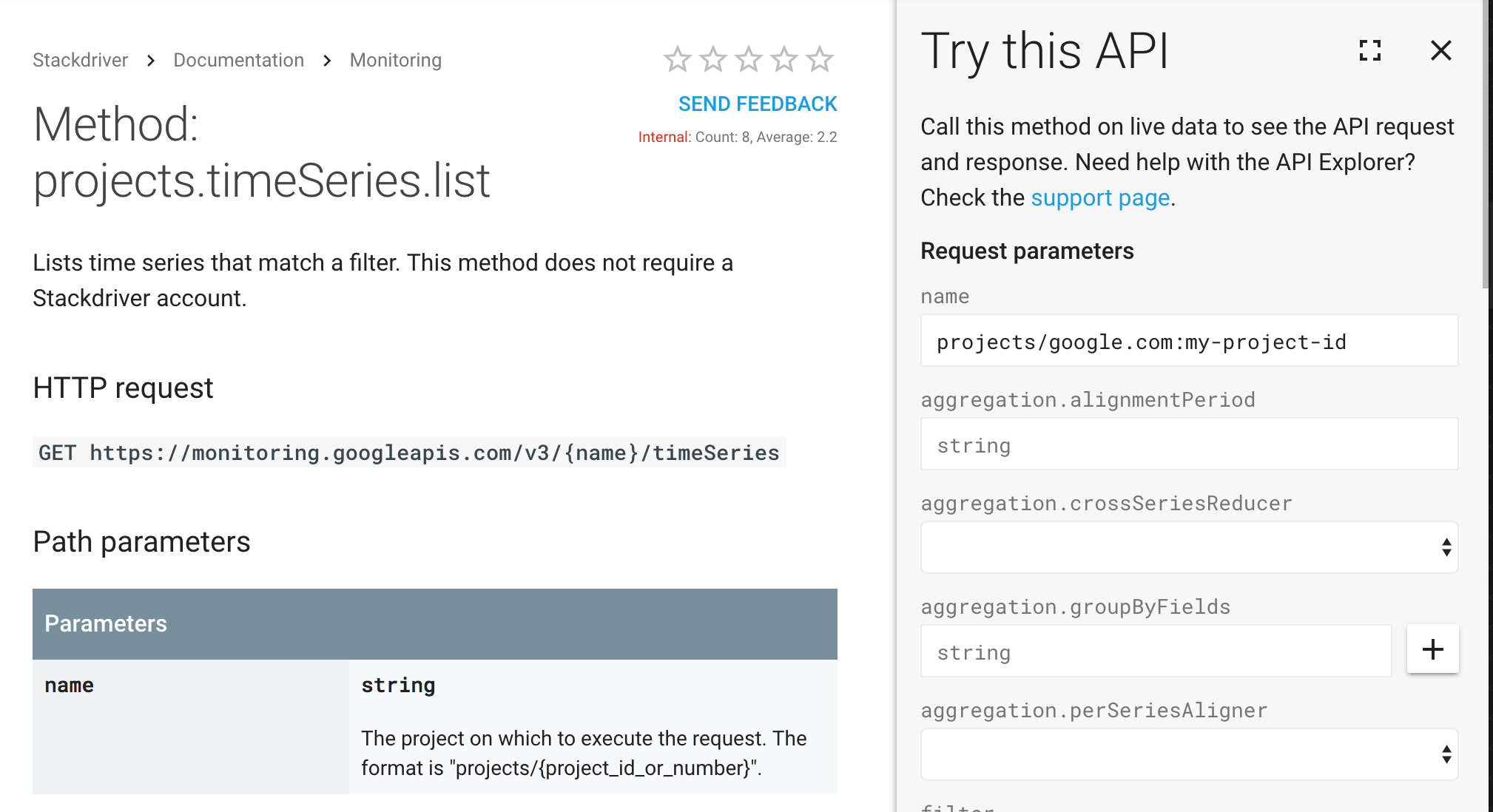
示例:下面大致介绍了模板化请求以及针对以下 Monitoring timeSeries.list 参数返回的 JSON 响应:
- name: projects/example-project-id
- filter: metric.type="dataproc.googleapis.com/cluster/hdfs/storage_capacity"
- interval.endTime: 2018-02-27T11:54:00.000-08:00
- interval.startTime: 2018-02-20T00:00:00.000-08:00
OSS 指标
您可以让 Dataproc 收集集群 OSS 组件指标以在 Monitoring 中查看。Dataproc OSS 指标采用以下格式收集:
custom.googleapis.com/OSS_COMPONENT/METRIC。
OSS 指标示例:
custom.googleapis.com/spark/driver/DAGScheduler/job/allJobs custom.googleapis.com/hiveserver2/memory/MaxNonHeapMemory
可用的 OSS 指标
您可以让 Dataproc 收集下表中列出的 OSS 指标。如果在启用关联的指标来源后 Dataproc 默认收集指标,则默认收集列将标记为“y”。如果您替换指标来源的默认指标集合,则可以为指标来源列出的任何指标以及所有 Spark 指标启用收集功能(请参阅启用 OSS 指标收集)。
Hadoop 指标
HDFS 指标
| 指标 | Metrics Explorer 名称 | 默认收集 |
|---|---|---|
| hdfs:NameNode:FSNamesystem:CapacityTotalGB | dfs/FSNamesystem/CapacityTotalGB | y |
| hdfs:NameNode:FSNamesystem:CapacityUsedGB | dfs/FSNamesystem/CapacityUsedGB | y |
| hdfs:NameNode:FSNamesystem:CapacityRemainingGB | dfs/FSNamesystem/CapacityRemainingGB | y |
| hdfs:NameNode:FSNamesystem:FilesTotal | dfs/FSNamesystem/FilesTotal | y |
| hdfs:NameNode:FSNamesystem:MissingBlocks | dfs/FSNamesystem/MissingBlocks | n |
| hdfs:NameNode:FSNamesystem:ExpiredHeartats | dfs/FSNamesystem/ExpiredHeartats | n |
| hdfs:NameNode:FSNamesystem:TransactionSinceLastCheckpoint | dfs/FSNamesystem/TransactionSinceLastCheckpoint | n |
| hdfs:NameNode:FSNamesystem:TransactionSinceLastLogRoll | dfs/FSNamesystem/TransactionSinceLastLogRoll | n |
| hdfs:NameNode:FSNamesystem:LastWriterTransactionId | dfs/FSNamesystem/LastWriterTransactionId | n |
| hdfs:NameNode:FSNamesystem:CapacityTotal | dfs/FSNamesystem/CapacityTotal | n |
| hdfs:NameNode:FSNamesystem:CapacityUsed | dfs/FSNamesystem/CapacityUsed | n |
| hdfs:NameNode:FSNamesystem:CapacityRemaining | dfs/FSNamesystem/CapacityRemaining | n |
| hdfs:NameNode:FSNamesystem:CapacityUsedNonDFS | dfs/FSNamesystem/CapacityUsedNonDFS | n |
| hdfs:NameNode:FSNamesystem:TotalLoad | dfs/FSNamesystem/TotalLoad | n |
| hdfs:NameNode:FSNamesystem:SnapshottableDirectories | dfs/FSNamesystem/SnapshottableDirectories | n |
| hdfs:NameNode:FSNamesystem:Snapshots | dfs/FSNamesystem/Snapshots | n |
| hdfs:NameNode:FSNamesystem:BlocksTotal | dfs/FSNamesystem/BlocksTotal | n |
| hdfs:NameNode:FSNamesystem:PendingReplicationBlocks | dfs/FSNamesystem/PendingReplicationBlocks | n |
| hdfs:NameNode:FSNamesystem:UnderReplicatedBlocks | dfs/FSNamesystem/UnderReplicatedBlocks | n |
| hdfs:NameNode:FSNamesystem:CorruptBlocks | dfs/FSNamesystem/CorruptBlocks | n |
| hdfs:NameNode:FSNamesystem:ScheduleReplicationBlocks | dfs/FSNamesystem/ScheduleReplicationBlocks | n |
| hdfs:NameNode:FSNamesystem:PendingDeletionBlocks | dfs/FSNamesystem/PendingDeletionBlocks | n |
| hdfs:NameNode:FSNamesystem:ExlapseBlocks | dfs/FSNamesystem/ExoverBlocks | n |
| hdfs:NameNode:FSNamesystem:PostponedMisduplicatetedBlocks | dfs/FSNamesystem/PostponedMiscopytedBlocks | n |
| hdfs:NameNode:FSNamesystem:PendingDataNodeMessageCourt | dfs/FSNamesystem/PendingDataNodeMessageCourt | n |
| hdfs:NameNode:FSNamesystem:MillisSinceLastLoadedEdits | dfs/FSNamesystem/MillisSinceLastLoadedEdits | n |
| hdfs:NameNode:FSNamesystem:BlockCapacity | dfs/FSNamesystem/BlockCapacity | n |
| hdfs:NameNode:FSNamesystem:StaleDataNodes | dfs/FSNamesystem/StaleDataNodes | n |
| hdfs:NameNode:FSNamesystem:TotalFiles | dfs/FSNamesystem/TotalFiles | n |
| hdfs:NameNode:JvmMetrics:MemHeapUsedM | dfs/jvm/MemHeapUsedM | n |
| hdfs:NameNode:JvmMetrics:MemHeapCommittedM | dfs/jvm/MemHeapCommittedM | n |
| hdfs:NameNode:JvmMetrics:MemHeapMaxM | dfs/jvm/MemHeapMaxM | n |
| hdfs:NameNode:JvmMetrics:MemMaxM | dfs/jvm/MemMaxM | n |
YARN 指标
| 指标 | Metrics Explorer 名称 | 默认收集 |
|---|---|---|
| yarn:ResourceManager:ClusterMetrics:NumActiveNMs | yarn/ClusterMetrics/NumActiveNM | y |
| yarn:ResourceManager:ClusterMetrics:NumDecommissionedNM | yarn/ClusterMetrics/NumDecommissionedNM | n |
| yarn:ResourceManager:ClusterMetrics:NumLostNMs | yarn/ClusterMetrics/NumLostNMs | n |
| yarn:ResourceManager:ClusterMetrics:NumUnhealthyNM | yarn/ClusterMetrics/NumUnhealthyNM | n |
| yarn:ResourceManager:ClusterMetrics:NumRebootedNMs | yarn/ClusterMetrics/NumRebootedNM | n |
| yarn:ResourceManager:QueueMetrics:running_0 | yarn/QueueMetrics/running_0 | y |
| yarn:ResourceManager:QueueMetrics:running_60 | yarn/QueueMetrics/running_60 | y |
| yarn:ResourceManager:QueueMetrics:running_300 | yarn/QueueMetrics/running_300 | y |
| yarn:ResourceManager:QueueMetrics:running_1440 | yarn/QueueMetrics/running_1440 | y |
| yarn:ResourceManager:QueueMetrics:AppsSubmitted | yarn/QueueMetrics/AppsSubmitted | y |
| yarn:ResourceManager:QueueMetrics:AvailableMB | yarn/QueueMetrics/AvailableMB | y |
| yarn:ResourceManager:QueueMetrics:PendingContainers | yarn/QueueMetrics/PendingContainers | y |
| yarn:ResourceManager:QueueMetrics:AppsRunning | yarn/QueueMetrics/AppsRunning | n |
| yarn:ResourceManager:QueueMetrics:AppsPending | yarn/QueueMetrics/AppsPending | n |
| yarn:ResourceManager:QueueMetrics:AppsCompleted | yarn/QueueMetrics/AppsCompleted | n |
| yarn:ResourceManager:QueueMetrics:AppsKilled | yarn/QueueMetrics/AppsKilled | n |
| yarn:ResourceManager:QueueMetrics:AppsFailed | yarn/QueueMetrics/AppsFailed | n |
| yarn:ResourceManager:QueueMetrics:AlassignedMB | yarn/QueueMetrics/AlassignedMB | n |
| yarn:ResourceManager:QueueMetrics:AlassignedVCores | yarn/QueueMetrics/AlassignedVCores | n |
| yarn:ResourceManager:QueueMetrics:AlassignedContainers | yarn/QueueMetrics/AlassignedContainers | n |
| yarn:ResourceManager:QueueMetrics:AggregateContainersAlassigned | yarn/QueueMetrics/AggregateContainersAlassigned | n |
| yarn:ResourceManager:QueueMetrics:AggregateContainersReleased | yarn/QueueMetrics/AggregateContainersReleased | n |
| yarn:ResourceManager:QueueMetrics:AvailableVCores | yarn/QueueMetrics/AvailableVCores | n |
| yarn:ResourceManager:QueueMetrics:PendingMB | yarn/QueueMetrics/PendingMB | n |
| yarn:ResourceManager:QueueMetrics:PendingVCores | yarn/QueueMetrics/PendingVCores | n |
| yarn:ResourceManager:QueueMetrics:reservedMB | yarn/QueueMetrics/reservedMB | n |
| yarn:ResourceManager:QueueMetrics:reservedVCores | yarn/QueueMetrics/reservedVCores | n |
| yarn:ResourceManager:QueueMetrics:reservedContainers | yarn/QueueMetrics/reservedContainers | n |
| yarn:ResourceManager:QueueMetrics:ActiveUsers | yarn/QueueMetrics/ActiveUsers | n |
| yarn:ResourceManager:QueueMetrics:ActiveApplications | yarn/QueueMetrics/ActiveApplications | n |
| yarn:ResourceManager:QueueMetrics:FairShareMB | yarn/QueueMetrics/FairShareMB | n |
| yarn:ResourceManager:QueueMetrics:FairShareVCores | yarn/QueueMetrics/FairShareVCores | n |
| yarn:ResourceManager:QueueMetrics:MinShareMB | yarn/QueueMetrics/MinShareMB | n |
| yarn:ResourceManager:QueueMetrics:MinShareVCores | yarn/QueueMetrics/MinShareVCores | n |
| yarn:ResourceManager:QueueMetrics:MaxShareMB | yarn/QueueMetrics/MaxShareMB | n |
| yarn:ResourceManager:QueueMetrics:MaxShareVCores | yarn/QueueMetrics/MaxShareVCores | n |
| yarn:ResourceManager:JvmMetrics:MemHeapUsedM | yarn/jvm/MemHeapUsedM | n |
| yarn:ResourceManager:JvmMetrics:MemHeapCommittedM | yarn/jvm/MemHeapCommittedM | n |
| yarn:ResourceManager:JvmMetrics:MemHeapMaxM | yarn/jvm/MemHeapMaxM | n |
| yarn:ResourceManager:JvmMetrics:MemMaxM | yarn/jvm/MemMaxM | n |
Spark 指标
Spark 驱动程序指标
| 指标 | Metrics Explorer 名称 | 默认收集 |
|---|---|---|
| spark:driver:BlockManager:disk.diskSpaceUsed_MB | spark/driver/BlockManager/disk/diskSpaceUsed_MB | y |
| spark:driver:BlockManager:memory.maxMem_MB | spark/driver/BlockManager/memory/maxMem_MB | y |
| spark:driver:BlockManager:memory.memUsed_MB | spark/driver/BlockManager/memory/memUsed_MB | y |
| spark:driver:DAGScheduler:job.allJob | spark/driver/DAGScheduler/job/allJob | y |
| spark:driver:DAGScheduler:stage.failedStages | spark/driver/DAGScheduler/stage/failedStages | y |
| spark:driver:DAGScheduler:stage.waitingStages | spark/driver/DAGScheduler/stage/waitingStages | y |
Spark 执行器指标
| 指标 | Metrics Explorer 名称 | 默认收集 |
|---|---|---|
| spark:executor:executor:bytesRead | spark/executor/bytesRead | y |
| spark:executor:executor:bytesWriter | spark/executor/bytesWriter | y |
| spark:executor:executor:cpuTime | spark/executor/cpuTime | y |
| Spark:executor:executor:diskBytesSpilled | spark/executor/diskBytesSpilled 已启动 | y |
| spark:executor:executor:recordsRead | spark/executor/recordsRead | y |
| spark:executor:executor:recordsWriter | Spark/执行程序/录制内容 | y |
| spark:executor:executor:runTime | Spark/执行程序/运行时 | y |
| spark:executor:executor:shuffleRecordsRead | spark/executor/shuffleRecordsRead | y |
| spark:executor:executor:shuffleRecordsWriter | spark/executor/shuffleRecordsWriter | y |
Spark 历史记录服务器指标
Dataproc 会收集以下 Spark 历史记录服务 JVM 内存指标:
| 指标 | Metrics Explorer 名称 | 默认收集 |
|---|---|---|
| sparkHistoryServer:JVM:Memory:HeapMemoryUsage.comsubmitted | sparkHistoryServer/memory/CommittedHeapMemory | y |
| sparkHistoryServer:JVM:Memory:HeapMemoryUsage.used | sparkHistoryServer/memory/UsedHeapMemory | y |
| sparkHistoryServer:JVM:Memory:HeapMemoryUsage.max | sparkHistoryServer/memory/MaxHeapMemory | y |
| sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.comsubmitted | sparkHistoryServer/memory/CommittedNonHeapMemory | y |
| sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.used | sparkHistoryServer/memory/UsedNonHeapMemory | y |
| sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.max | sparkHistoryServer/memory/MaxNonHeapMemory | y |
HiveServer 2 指标
| 指标 | Metrics Explorer 名称 | 默认收集 |
|---|---|---|
| hiveserver2:JVM:Memory:HeapMemoryUsage.comsubmitted | hiveserver2/memory/CommittedHeapMemory | y |
| hiveserver2:JVM:Memory:HeapMemoryUsage.used | hiveserver2/memory/UsedHeapMemory | y |
| hiveserver2:JVM:Memory:HeapMemoryUsage.max | hiveserver2/memory/MaxHeapMemory | y |
| hiveserver2:JVM:Memory:NonHeapMemoryUsage.comsubmitted | hiveserver2/memory/CommittedNonHeapMemory | y |
| hiveserver2:JVM:Memory:NonHeapMemoryUsage.used | hiveserver2/memory/UsedNonHeapMemory | y |
| hiveserver2:JVM:Memory:NonHeapMemoryUsage.max | hiveserver2/memory/MaxNonHeapMemory | y |
Hive Metastore 指标
| 指标 | Metrics Explorer 名称 | 默认收集 |
|---|---|---|
| hivemetastore:API:GetDatabase:Mean | hivemetastore/get_database/mean | y |
| hivemetastore:API:CreateDatabase:Mean | hivemetastore/create_database/mean | y |
| hivemetastore:API:DropDatabase:Mean | hivemetastore/drop_database/mean | y |
| hivemetastore:API:AlterDatabase:Mean | hivemetastore/alter_database/mean | y |
| hivemetastore:API:GetAllDatabases:Mean | hivemetastore/get_all_databases/mean | y |
| hivemetastore:API:CreateTable:Mean | hivemetastore/create_table/mean | y |
| hivemetastore:API:DropTable:Mean | hivemetastore/drop_table/mean | y |
| hivemetastore:API:AlterTable:均值 | hivemetastore/alter_table/mean | y |
| hivemetastore:API:GetTable:Mean | hivemetastore/get_table/mean | y |
| hivemetastore:API:GetAllTables:Mean | hivemetastore/get_all_tables/mean | y |
| hivemetastore:API:AddPartitionsReq:Mean | hivemetastore/add_partitions_req/mean | y |
| hivemetastore:API:DropPartition:Mean | hivemetastore/drop_partition/mean | y |
| hivemetastore:API:AlterPartition:平均值 | hivemetastore/alter_partition/mean | y |
| hivemetastore:API:GetPartition:Mean | hivemetastore/get_partition/mean | y |
| hivemetastore:API:GetPartitionNames:Mean | hivemetastore/get_partition_name/mean | y |
| hivemetastore:API:GetPartitionsPs:Mean | hivemetastore/get_partitions_ps/mean | y |
| hivemetastore:API:GetPartitionsPsWithAuth:Mean | hivemetastore/get_partitions_ps_with_auth/mean | y |
Hive Metastore 指标测量
| 统计测量 | 示例指标 | 指标名称示例 |
|---|---|---|
| 最大值 | hivemetastore:API:GetDatabase:Max | hivemetastore/get_database/max |
| 最小值 | hivemetastore:API:GetDatabase:Min | hivemetastore/get_database/min |
| 平均值 | hivemetastore:API:GetDatabase:Mean | hivemetastore/get_database/mean |
| 计数 | hivemetastore:API:GetDatabase:Count | hivemetastore/get_database/count |
| 第 50 百分位 | hivemetastore:API:GetDatabase:50thPercentile | hivemetastore/get_database/median |
| 第 75 个百分位 | hivemetastore:API:GetDatabase:75Percentile | hivemetastore/get_database/75th_percentile |
| 第 95 百分位 | hivemetastore:API:GetDatabase:95thPercentile | hivemetastore/get_database/95% |
| 第 98 百分位 | hivemetastore:API:GetDatabase:98thPercentile | hivemetastore/get_database/98th_percentile |
| 第 99 百分位 | hivemetastore:API:GetDatabase:99thPercentile | hivemetastore/get_database/99th_percentile |
| 第 999 百分位 | hivemetastore:API:GetDatabase:999thPercentile | hivemetastore/get_database/999th_percentile |
| 标准差 | hivemetastore:API:GetDatabase:StdDev | hivemetastore/get_database/stddev |
| 15 分钟费率 | hivemetastore:API:GetDatabase:FifevenMinuteRate | hivemetastore/get_database/15min_rate |
| 5 分钟费率 | hivemetastore:API:GetDatabase:FiveMinuteRate | hivemetastore/get_database/5min_rate |
| 一分钟费率 | hivemetastore:API:GetDatabase:OneMinuteRate | hivemetastore/get_database/1min_rate |
| 平均费率 | hivemetastore:API:GetDatabase:MeanRate | hivemetastore/get_database/mean_rate |
Dataproc 监控代理指标
默认情况下,Dataproc 会收集以下 Dataproc 监控代理默认指标,这些指标以 agent.googleapis.com 前缀发布:
CPU
agent.googleapis.com/cpu/load_15m
agent.googleapis.com/cpu/load_1m
agent.googleapis.com/cpu/load_5m
agent.googleapis.com/cpu/usage_time*
agent.googleapis.com/cpu/utilization*
磁盘
agent.googleapis.com/disk/bytes_used
agent.googleapis.com/disk/io_time
agent.googleapis.com/disk/merged_operations
agent.googleapis.com/disk/operation_count
agent.googleapis.com/disk/operation_time
agent.googleapis.com/disk/pending_operations
agent.googleapis.com/disk/percent_used
交换
agent.googleapis.com/swap/bytes_used
agent.googleapis.com/swap/io
agent.googleapis.com/swap/percent_used
内存
agent.googleapis.com/memory/bytes_used
agent.googleapis.com/memory/percent_used
进程 - (遵循少量属性的配额政策)
agent.googleapis.com/processes/count_by_state
agent.googleapis.com/processes/cpu_time
agent.googleapis.com/processes/disk/read_bytes_count
agent.googleapis.com/processes/disk/write_bytes_count
agent.googleapis.com/processes/fork_countes.fork_countes
接口
agent.googleapis.com/interface/errors
agent.googleapis.com/interface/packets
agent.googleapis.com/interface/traffic
网络
agent.googleapis.com/network/tcp_connections
启用 OSS 指标收集
创建 Dataproc 集群时,您可以使用 gcloud CLI 或 Dataproc API 通过以下两种方式启用 OSS 指标收集(您可以使用一种或两种收集方法):
- 允许仅从一个或多个 OSS 指标来源中收集默认指标
- 允许仅从一个或多个 OSS 指标来源收集(“替换”)指标
gcloud 命令
默认指标收集
使用 gcloud dataproc clusters create --metric-sources 标志允许从一个或多个指标来源收集默认可用的 OSS 指标。
gcloud dataproc clusters create cluster-name \ --metric-sources=METRIC_SOURCE(s) \ ... other flags
备注:
--metric-sources:若要启用默认指标收集,则必须提供。指定以下一个或多个指标来源:spark、hdfs、yarn、spark-history-server、hiveserver2、hivemetastore和monitoring-agent-defaults。指标来源名称不区分大小写(例如“yarn”或“YARN”均可)。
覆盖指标收集
(可选)添加 --metric-overrides 或 --metric-overrides-file 标志,以允许从一个或多个指标来源收集一个或多个可用的 OSS 指标。
-
任何可用的 OSS 指标和所有 Spark 指标都可以作为指标替换列出。替换指标值区分大小写,并且必须视情况以驼峰式大小写格式提供。
示例
sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.committedhiveserver2:JVM:Memory:NonHeapMemoryUsage.usedyarn:ResourceManager:JvmMetrics:MemHeapMaxM
-
系统只会从指定指标来源收集指定的替换指标。例如,如果一个或多个
spark:executive指标列为指标替换值,则不会收集其他SPARK指标。来自其他指标来源的 OSS 默认指标集合不会受到影响。例如,如果同时启用了SPARK和YARN指标来源,并且仅为 Spark 指标提供了替换值,则会收集所有默认的 YARN 指标。 -
必须启用指定指标覆盖的来源。例如,如果一个或多个
spark:driver指标作为指标替换值提供,则必须启用spark指标来源 (--metric-sources=spark)。
替换指标列表
gcloud dataproc clusters create cluster-name \ --metric-sources=METRIC_SOURCE(s) \ --metric-overrides=LIST_OF_METRIC_OVERRIDES \ ... other flags
备注:
--metric-sources:若要启用默认指标收集,则必须提供。指定以下一个或多个指标来源:spark、hdfs、yarn、spark-history-server、hiveserver2、hivemetastore和monitoring-agent-defaults。指标来源名称不区分大小写,例如“yarn”或“YARN”是可接受的。--metric-overrides:按以下格式提供指标列表:METRIC_SOURCE:INSTANCE:GROUP:METRIC
示例:
--metric-overrides=sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.committed- 此标记可替代
--metric-overrides-file标志,且不能与其配合使用。
替换指标文件
gcloud dataproc clusters create cluster-name \ --metric-sources=METRIC-SOURCE(s) \ --metric-overrides-file=METRIC_OVERRIDES_FILENAME \ ... other flags
备注:
-
--metric-sources:若要启用默认指标收集,则必须提供。指定以下一个或多个指标来源:spark、hdfs、yarn、spark-history-server、hiveserver2、hivemetastore和monitoring-agent-defaults。指标来源名称不区分大小写,例如“yarn”或“YARN”是可接受的。 -
--metric-overrides-file:按照以下格式指定包含一个或多个指标的本地文件或 Cloud Storage 文件 (gs://bucket/filename):METRIC_SOURCE:INSTANCE:GROUP:METRIC
根据需要使用驼峰式格式。示例
--metric-overrides-file=gs://my-bucket/my-filename.txt--metric-overrides-file=./local-directory/local-filename.txt
- 此标记可替代
--metric-overrides标志,且不能与其配合使用。
REST API
在 clusters.create 请求中使用 DataprocMetricConfig 以启用 OSS 指标的收集。
构建 Monitoring 信息中心
您可以构建一个自定义 Monitoring 信息中心来显示所选 Cloud Dataproc 集群指标的图表。
从 Monitoring Dashboards Overview 页面中选择 + CREATE DASHBOARD。为信息中心提供一个名称,然后点击右上方菜单中的 Add Chart 以打开 Add Chart 窗口。选择“Cloud Dataproc Cluster”作为资源类型。 选择一个或多个指标以及指标和图表属性。然后保存该图表。
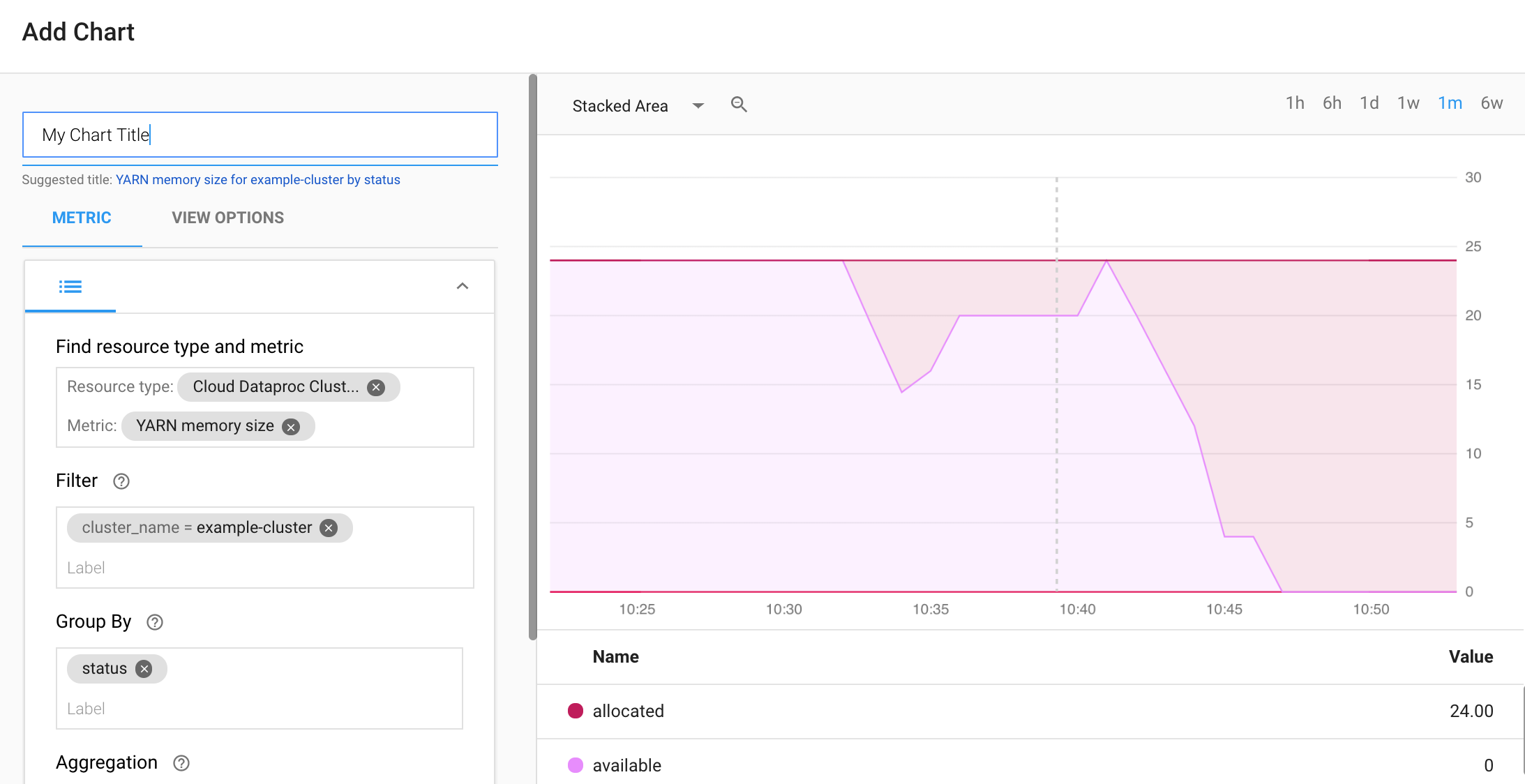
您可以将其他图表添加到信息中心。保存信息中心后,其标题会显示在 Monitoring Dashboards Overview 页面中。您可以在信息中心显示页面中查看、更新和删除信息中心图表。
后续步骤
- 请参阅 Cloud Monitoring 文档
- 了解如何创建 Dataproc 指标提醒