以下示例通过 Ranger 和 Solr 组件创建和使用已启用 Kerberos 的 Dataproc 集群,以控制用户对 Hadoop、YARN 和 HIVE 资源的访问权限。
备注:
您可以通过组件网关访问 Ranger 网页界面。
在包含 Kerberos 集群的 Ranger 中,Dataproc 通过删除 Kerberos 用户的领域和实例将 Kerberos 用户映射到系统用户。例如,Kerberos 主账号
user1/cluster-m@MY.REALM被映射到系统user1,且系统定义了 Ranger 政策以允许或拒绝user1的权限。
创建集群。
- 以下
gcloud命令可以在本地终端窗口中运行,也可以从项目的 Cloud Shell 中运行。gcloud dataproc clusters create cluster-name \ --region=region \ --optional-components=SOLR,RANGER \ --enable-component-gateway \ --properties="dataproc:ranger.kms.key.uri=projects/project-id/locations/global/keyRings/keyring/cryptoKeys/key,dataproc:ranger.admin.password.uri=gs://bucket/admin-password.encrypted" \ --kerberos-root-principal-password-uri=gs://bucket/kerberos-root-principal-password.encrypted \ --kerberos-kms-key=projects/project-id/locations/global/keyRings/keyring/cryptoKeys/key
- 以下
集群运行后,前往 Google Cloud 控制台上的 Dataproc 集群页面,然后选择集群名称以打开集群详情页面。点击网页界面标签页以显示组件网关链接列表,这些链接指向安装在集群上的默认组件和可选组件的网页界面。点击 Ranger 链接。

通过输入“admin”用户名和 Ranger 管理员密码登录到 Ranger。
Ranger 管理界面会在本地浏览器中打开。
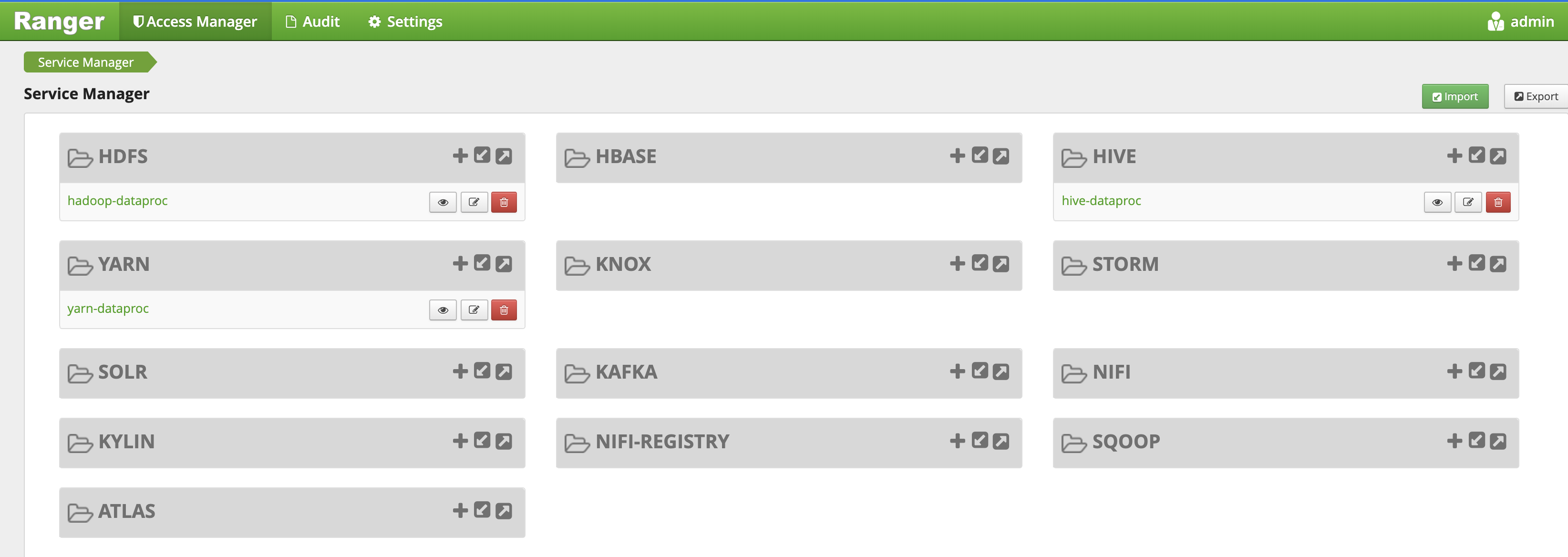
YARN 访问政策
此示例创建了一个 Ranger 政策,以允许和拒绝用户访问 YARN root.default 队列。
从 Ranger 管理界面中选择
yarn-dataproc。
在 yarn-dataproc 政策页面上,点击添加新政策。 在创建政策页面上,输入或选择以下字段:
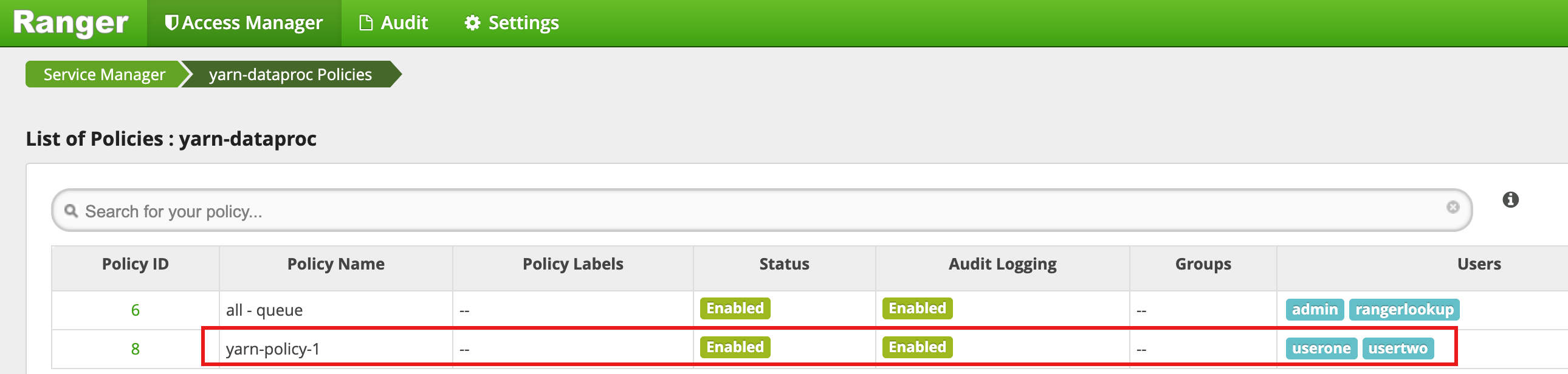
Policy Name:“yarn-policy-1”Queue:“root.default”Audit Logging:“是”Allow Conditions:Select User:“userone”Permissions:“全选”(授予所有权限)
Deny Conditions:Select User:“usertwo”Permissions:“全选”(拒绝所有权限)

点击添加以保存政策。该政策列在 yarn-dataproc 政策页面上:
在主 SSH 会话窗口中以 userone 身份运行 Hadoop mapreduce 作业:
userone@example-cluster-m:~$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduced-examples. jar pi 5 10
- Ranger 界面显示允许
userone提交作业。
- Ranger 界面显示允许
从虚拟机的主 SSH 会话窗口以
usertwo身份运行 Hadoop mapreduce 作业:usertwo@example-cluster-m:~$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduced-examples. jar pi 5 10
- Ranger 界面显示,系统已拒绝
usertwo提交作业。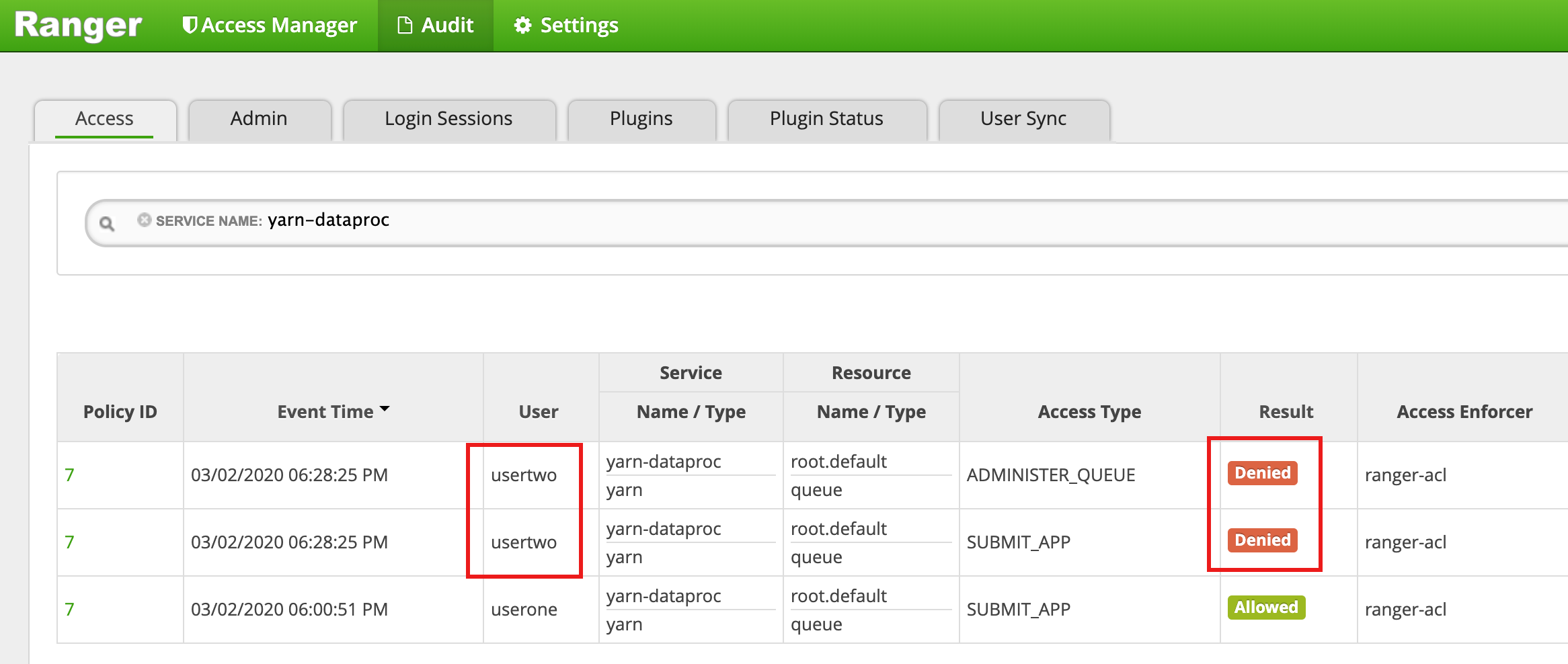
- Ranger 界面显示,系统已拒绝
HDFS 访问政策
此示例创建了一个 Ranger 政策,以允许和拒绝用户对 HDFS /tmp 目录的访问。
从 Ranger 管理界面中选择
hadoop-dataproc。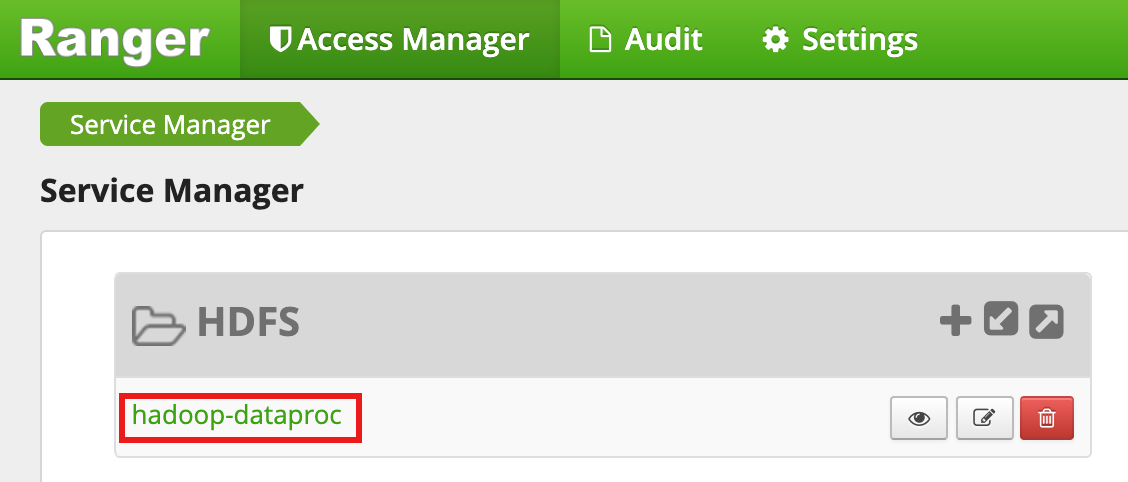
在 hadoop-dataproc 政策页面上,点击添加新政策。 在创建政策页面上,输入或选择以下字段:
Policy Name:“hadoop-policy-1”Resource Path:“/tmp”Audit Logging:“是”Allow Conditions:Select User:“userone”Permissions:“全选”(授予所有权限)
Deny Conditions:Select User:“usertwo”Permissions:“全选”(拒绝所有权限)
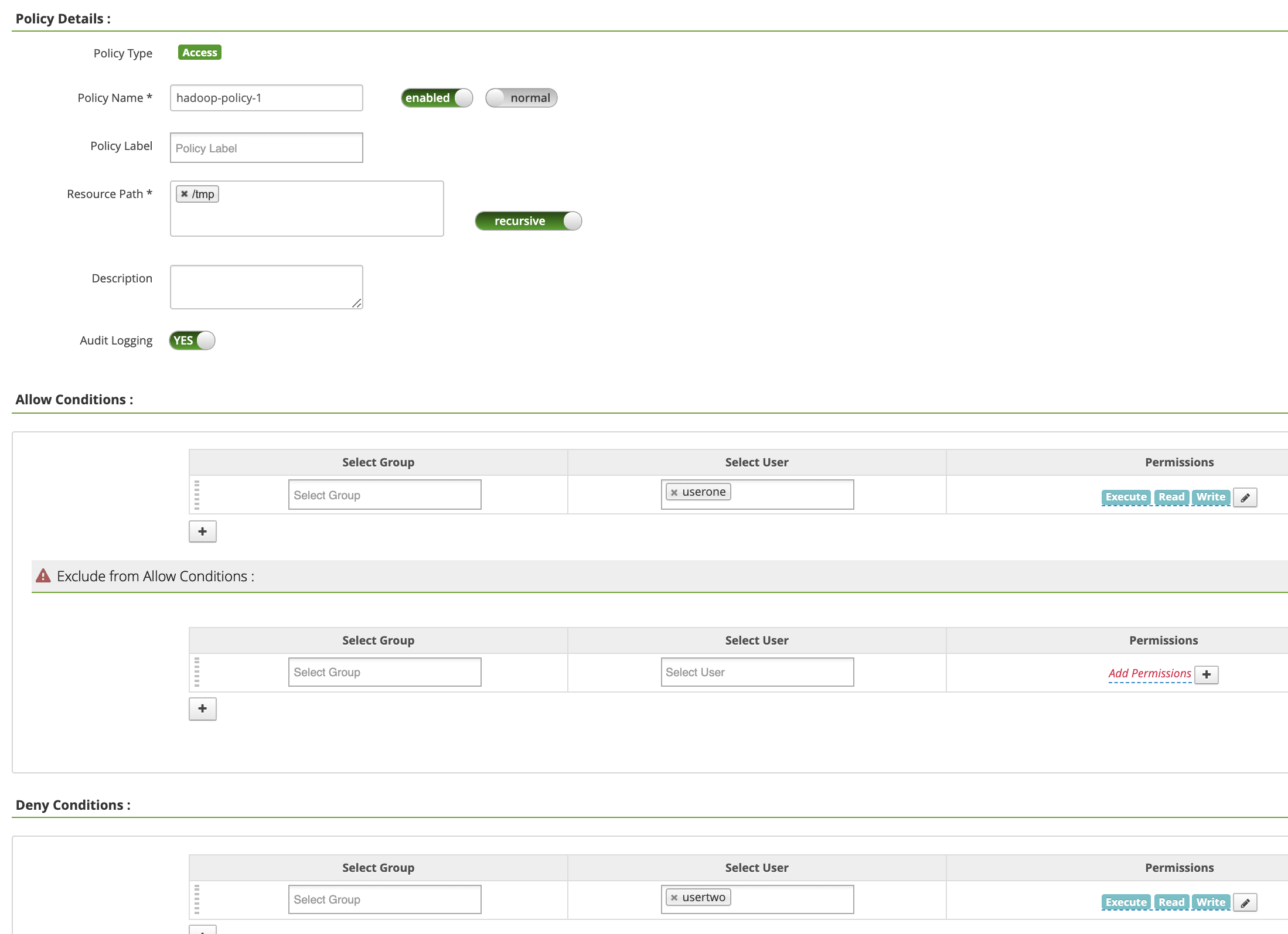
点击添加以保存政策。该政策列在 hadoop-dataproc 政策页面上:
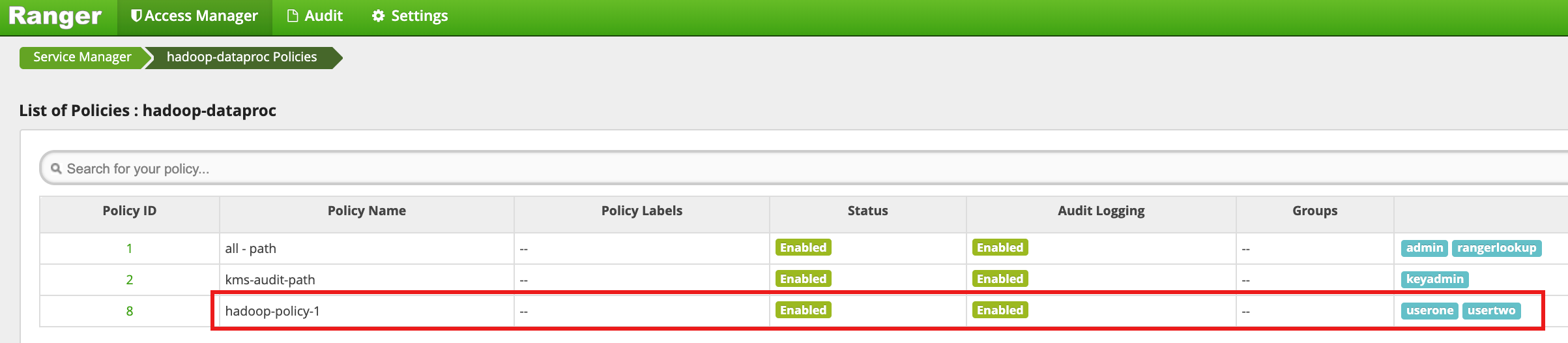
以 userone 身份访问 HDFS
/tmp目录:userone@example-cluster-m:~$ hadoop fs -ls /tmp
- Ranger 界面显示,系统允许
userone访问 HDFS /tmp 目录。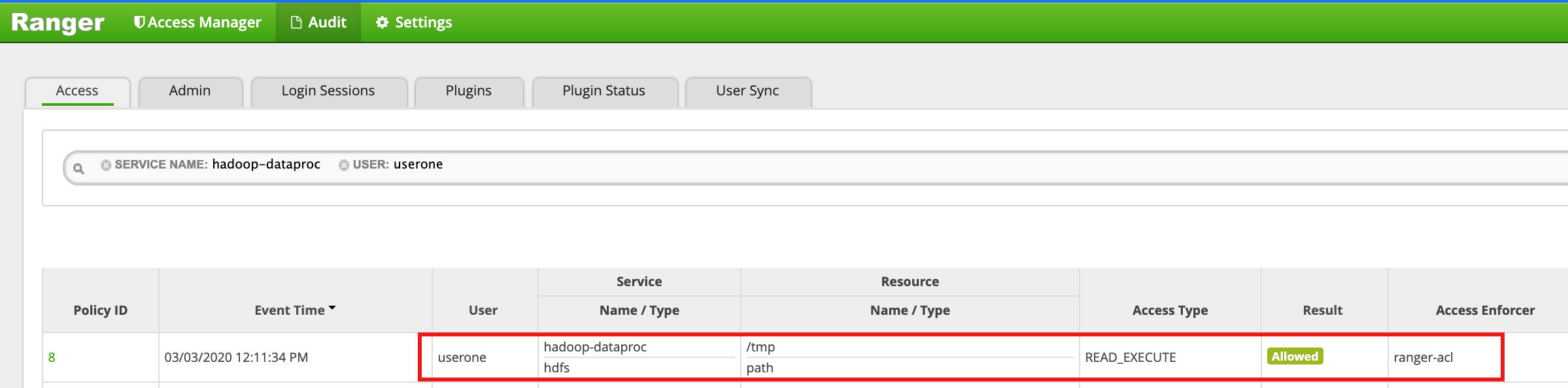
- Ranger 界面显示,系统允许
以
usertwo身份访问 HDFS/tmp目录:usertwo@example-cluster-m:~$ hadoop fs -ls /tmp
- Ranger 界面显示
usertwo被拒绝访问 HDFS /tmp 目录。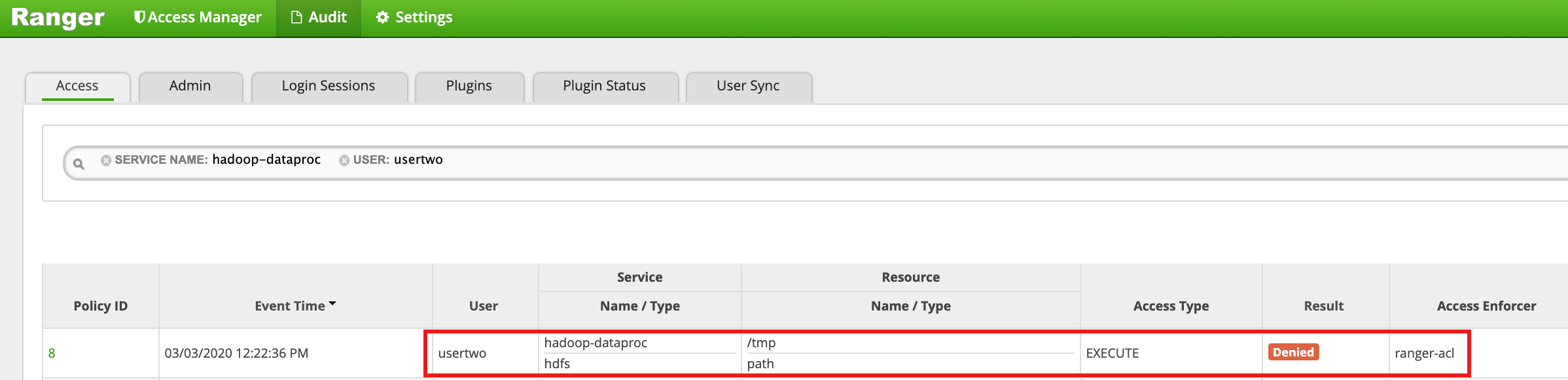
- Ranger 界面显示
Hive 访问政策
此示例创建了一个 Ranger 政策,以允许和拒绝用户访问 Hive 表。
在主实例上使用 Hive CLI 创建一个小型的
employee表。hive> CREATE TABLE IF NOT EXISTS employee (eid int, name String); INSERT INTO employee VALUES (1 , 'bob') , (2 , 'alice'), (3 , 'john');
从 Ranger 管理界面中选择
hive-dataproc。
在 hive-dataproc 政策页面上,点击添加新政策。 在创建政策页面上,输入或选择以下字段:
Policy Name:“hive-policy-1”database:“默认”table:“员工”Hive Column:“*”Audit Logging:“是”Allow Conditions:Select User:“userone”Permissions:“全选”(授予所有权限)
Deny Conditions:Select User:“usertwo”Permissions:“全选”(拒绝所有权限)
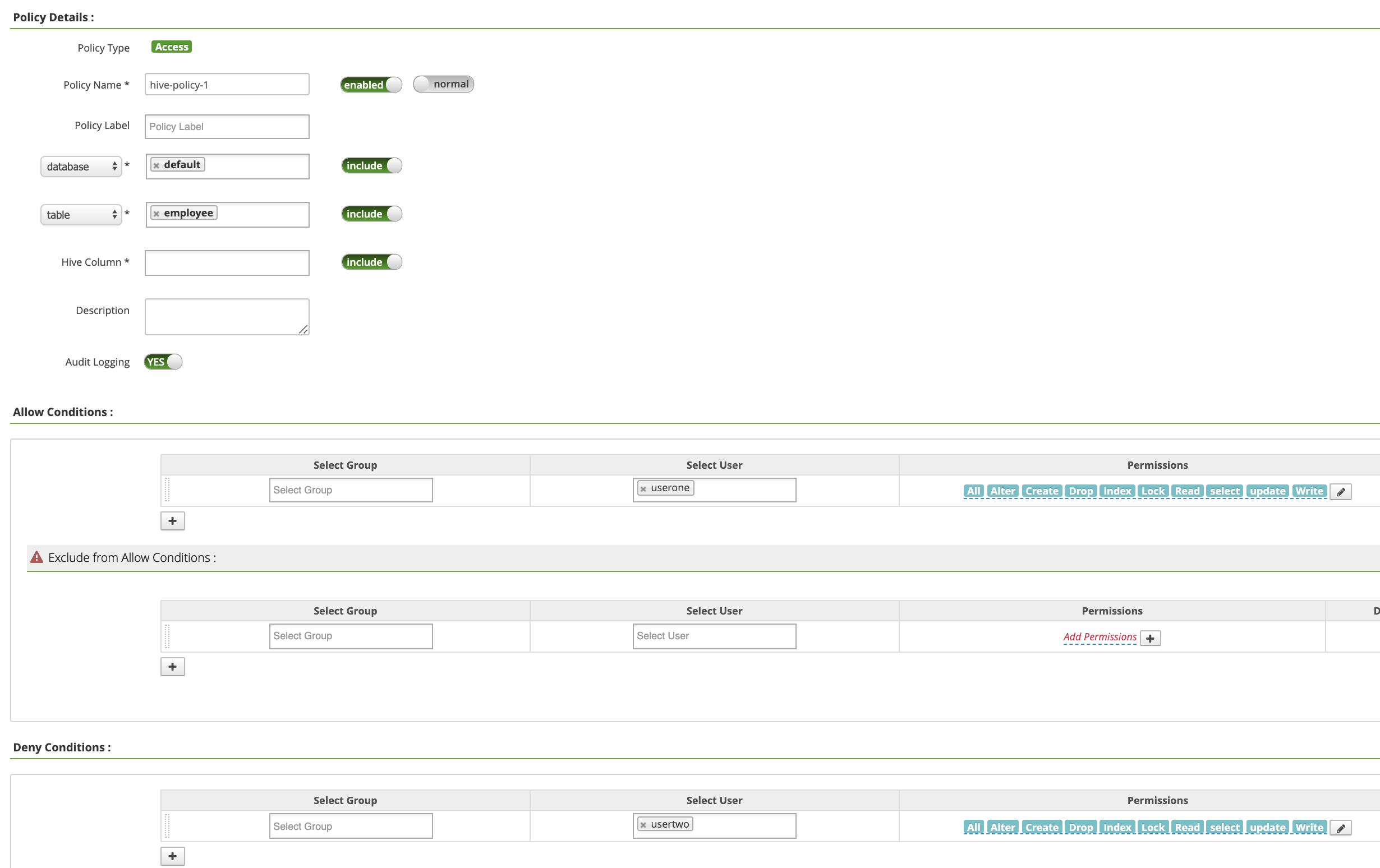
点击添加以保存政策。该政策列在 hive-dataproc 政策页面上:
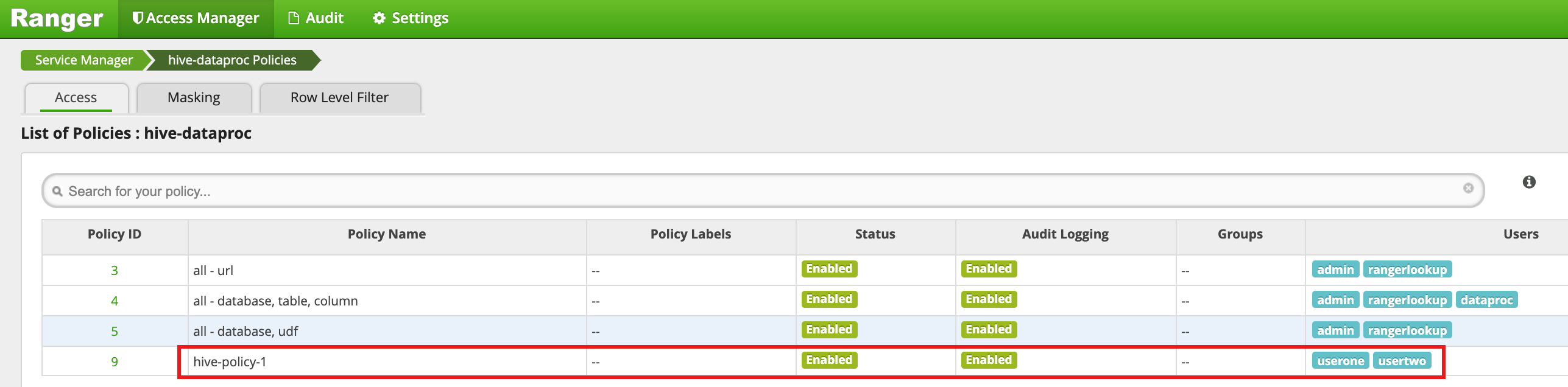
在虚拟机的主 SSH 会话中以 userone 身份针对 Hive 员工表运行查询:
userone@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- userone 查询成功:
Connected to: Apache Hive (version 2.3.6) Driver: Hive JDBC (version 2.3.6) Transaction isolation: TRANSACTION_REPEATABLE_READ +---------------+----------------+ | employee.eid | employee.name | +---------------+----------------+ | 1 | bob | | 2 | alice | | 3 | john | +---------------+----------------+ 3 rows selected (2.033 seconds)
- userone 查询成功:
在虚拟机的主 SSH 会话中以 usertwo 身份针对 Hive 员工表运行查询:
usertwo@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- 拒绝 usertwo 访问该表:
Error: Could not open client transport with JDBC Uri: ... Permission denied: user=usertwo, access=EXECUTE, inode="/tmp/hive"
- 拒绝 usertwo 访问该表:
精细 Hive 访问
Ranger 支持在 Hive 上使用遮罩和行级过滤条件。此示例是通过添加遮罩和过滤条件政策基于上一个 hive-policy-1 构建的。
从 Ranger 管理界面中选择
hive-dataproc,然后选择遮罩标签,点击添加新政策。
在创建政策页面中,输入或选择以下字段来创建一个政策用来掩盖(取消)员工姓名列:
Policy Name:“hive-masking 政策”database:“默认”table:“员工”Hive Column:“姓名”Audit Logging:“是”Mask Conditions:Select User:“userone”Access Types:“选择”(添加/修改权限)Select Masking Option:“取消”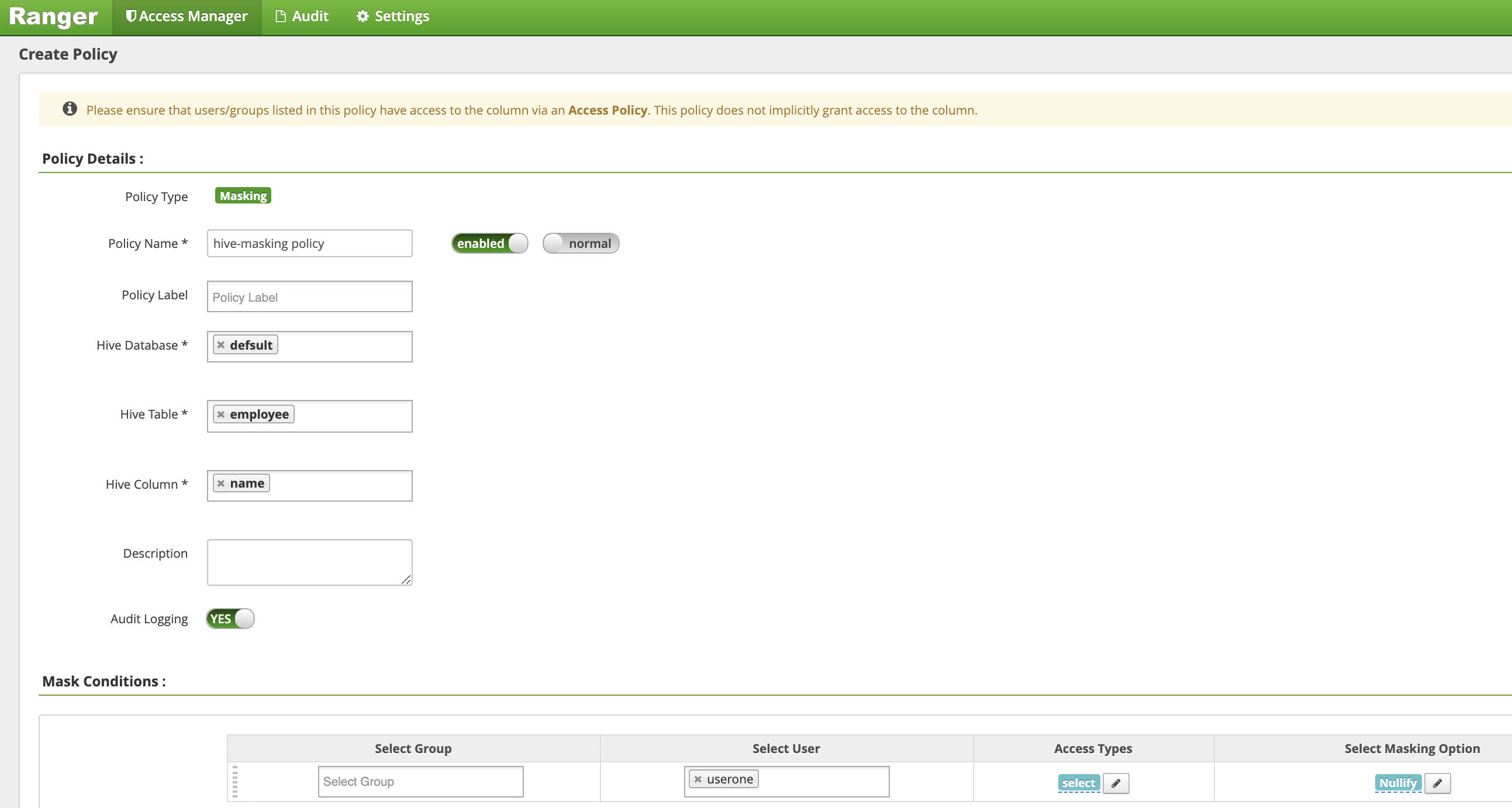
点击添加以保存政策。
从 Ranger 管理界面中选择
hive-dataproc,然后选择行级过滤条件标签,点击添加新政策。
在创建政策页面中,输入或选择以下字段来创建一个政策用来过滤(返回)
eid不等于1的行:Policy Name:“hive-filter 政策”Hive Database:“默认”Hive Table:“员工”Audit Logging:“是”Mask Conditions:Select User:“userone”Access Types:“选择”(添加/修改权限)Row Level Filter:“eid != 1”过滤条件表达式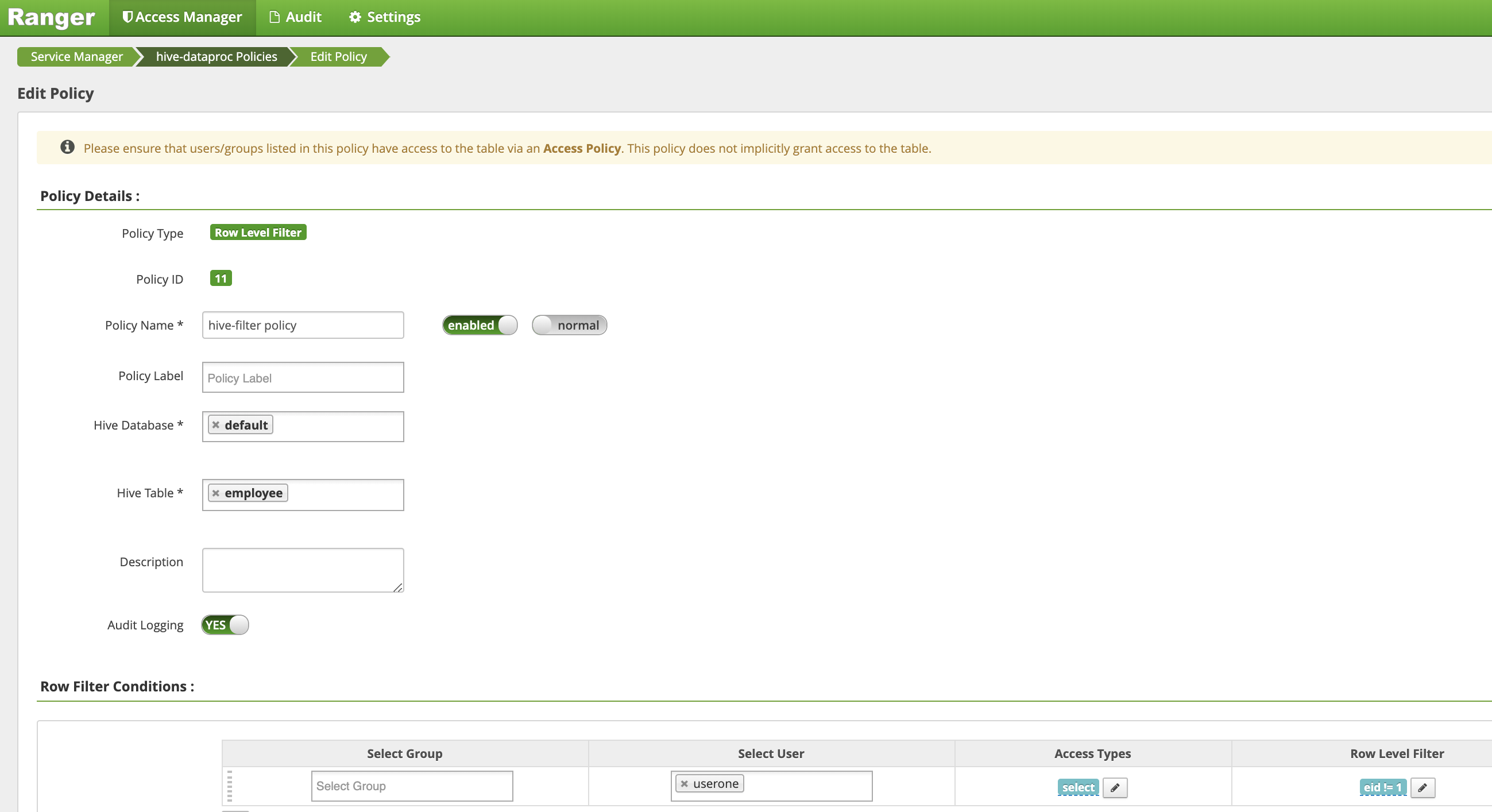
点击添加以保存政策。
在虚拟机的主 SSH 会话中以 userone 身份针对 Hive 员工表运行上一查询:
userone@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- 查询将返回遮盖了的名称列以及从结果中滤除的 bob (eid=1):
Transaction isolation: TRANSACTION_REPEATABLE_READ +---------------+----------------+ | employee.eid | employee.name | +---------------+----------------+ | 2 | NULL | | 3 | NULL | +---------------+----------------+ 2 rows selected (0.47 seconds)
- 查询将返回遮盖了的名称列以及从结果中滤除的 bob (eid=1):