Certains des composants Open Source par défaut inclus dans les clusters Google Dataproc, comme Apache Hadoop et Apache Spark, fournissent des interfaces Web. Ces interfaces peuvent être utilisées pour gérer et surveiller les ressources et les installations du cluster, telles que le gestionnaire de ressources YARN, le système de fichiers distribué Hadoop (HDFS, Hadoop Distributed File System), MapReduce et Spark. Avec la passerelle des composants, vous bénéficiez d'un accès sécurisé aux points de terminaison Web pour les composants facultatifs et par défaut de Dataproc.
Les clusters créés avec des versions d'image Dataproc compatibles peuvent permettre l'accès aux interfaces Web des composants sans recourir à des tunnels SSH ni modifier les règles de pare-feu pour autoriser le trafic entrant.
Remarques
- Les utilisateurs disposant de l'autorisation IAM dataproc.clusters.use peuvent accéder aux interfaces Web de composants. Consultez la page Rôles Dataproc.
- La passerelle des composants peut être utilisée pour accéder aux API REST, comme Apache Hadoop YARN et Apache Livy, ni aux serveurs d'historique.
- Lorsque la passerelle des composants est activée, Dataproc ajoute les services suivants au premier nœud maître du cluster :
- Apache Knox : Le certificat SSL de la passerelle Knox par défaut est valide pendant 13 mois à compter de la date de création du cluster. S'il expire, toutes les URL de l'interface Web de la passerelle des composants deviennent inactives. Pour obtenir un nouveau certificat, consultez la section Comment regénérer le certificat SSL de la passerelle des composants.
- Proxy d'inversion
- La passerelle des composants n'active pas l'accès direct aux interfaces
node:port, mais sert automatiquement de proxy pour un sous-ensemble spécifique de services. Si vous souhaitez accéder aux services sur les nœuds (node:port), utilisez un proxy SSH SOCKS.
Créer un cluster avec la passerelle des composants
Console
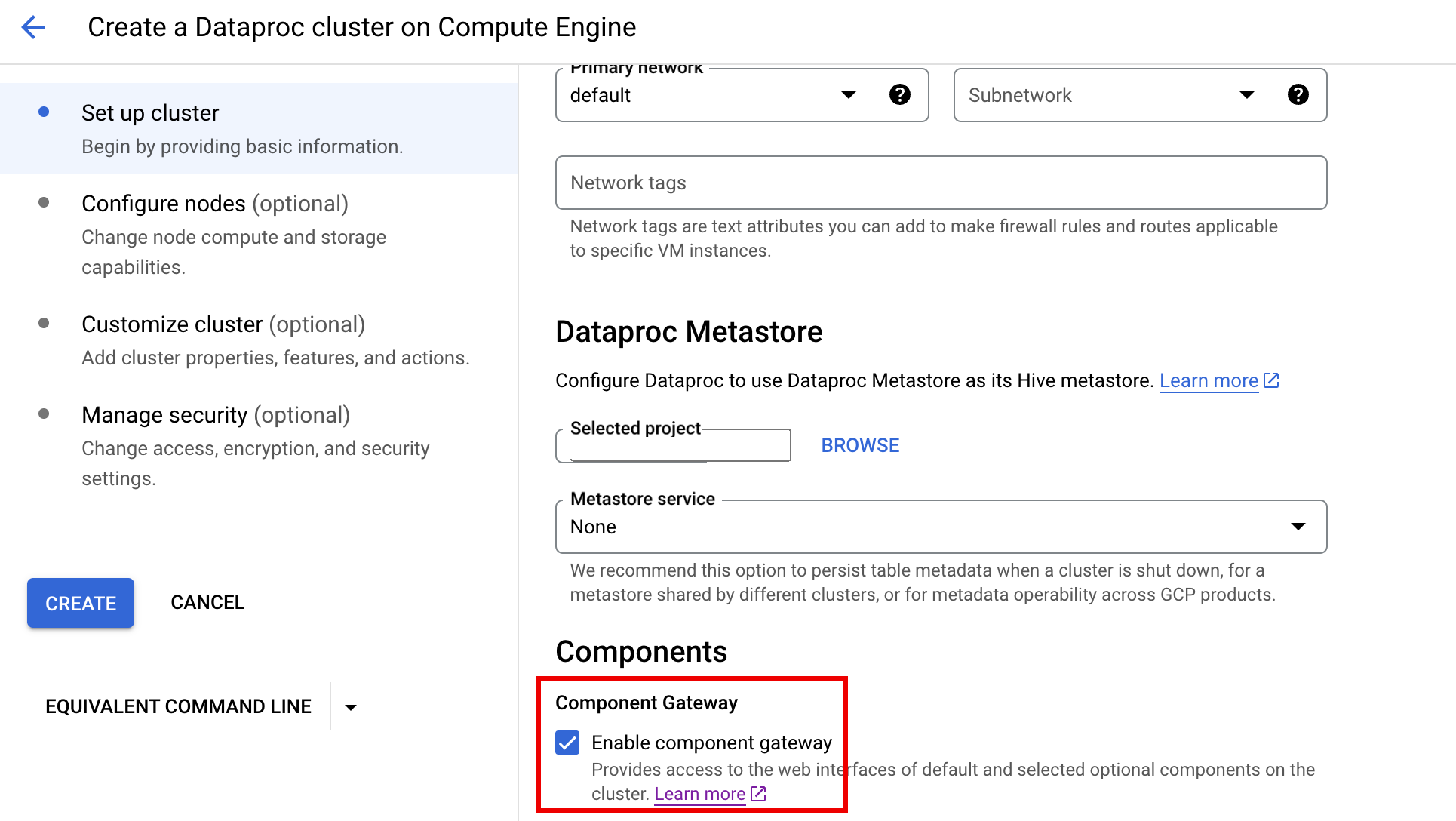
Pour activer la passerelle des composants à partir de la console Google Cloud, cochez la case "Component Gateway" (Passerelle des composants) dans la section "Components" (Composants) du panneau "Set up cluster" (Configurer un cluster) sur la page Dataproc Create a cluster (Créer un cluster).
Commande gcloud
Exécutez en local la commande gcloud CLI gcloud dataproc clusters create dans une fenêtre de terminal ou dans Cloud Shell.
gcloud dataproc clusters create cluster-name \ --enable-component-gateway \ --region=region \ other args ...
API REST
Définissez la propriété EndpointConfig.enableHttpPortAccess sur true dans le cadre d'une requête clusters.create.
Utiliser les URL de la passerelle des composants pour accéder aux interfaces Web
Lorsque la passerelle des composants est activée sur un cluster, vous pouvez vous connecter aux interfaces Web de composants exécutées sur le premier nœud maître du cluster en cliquant sur les liens fournis dans la console Google Cloud. La passerelle de composants définit également endpointConfig.httpPorts avec un mappage des noms de port et des URL. Vous pouvez aussi utiliser l'outil de ligne de commande gcloud ou l'API REST Dataproc pour consulter ces informations de mappage, puis copier et coller l'URL dans votre navigateur pour vous connecter à l'interface utilisateur du composant.
Console
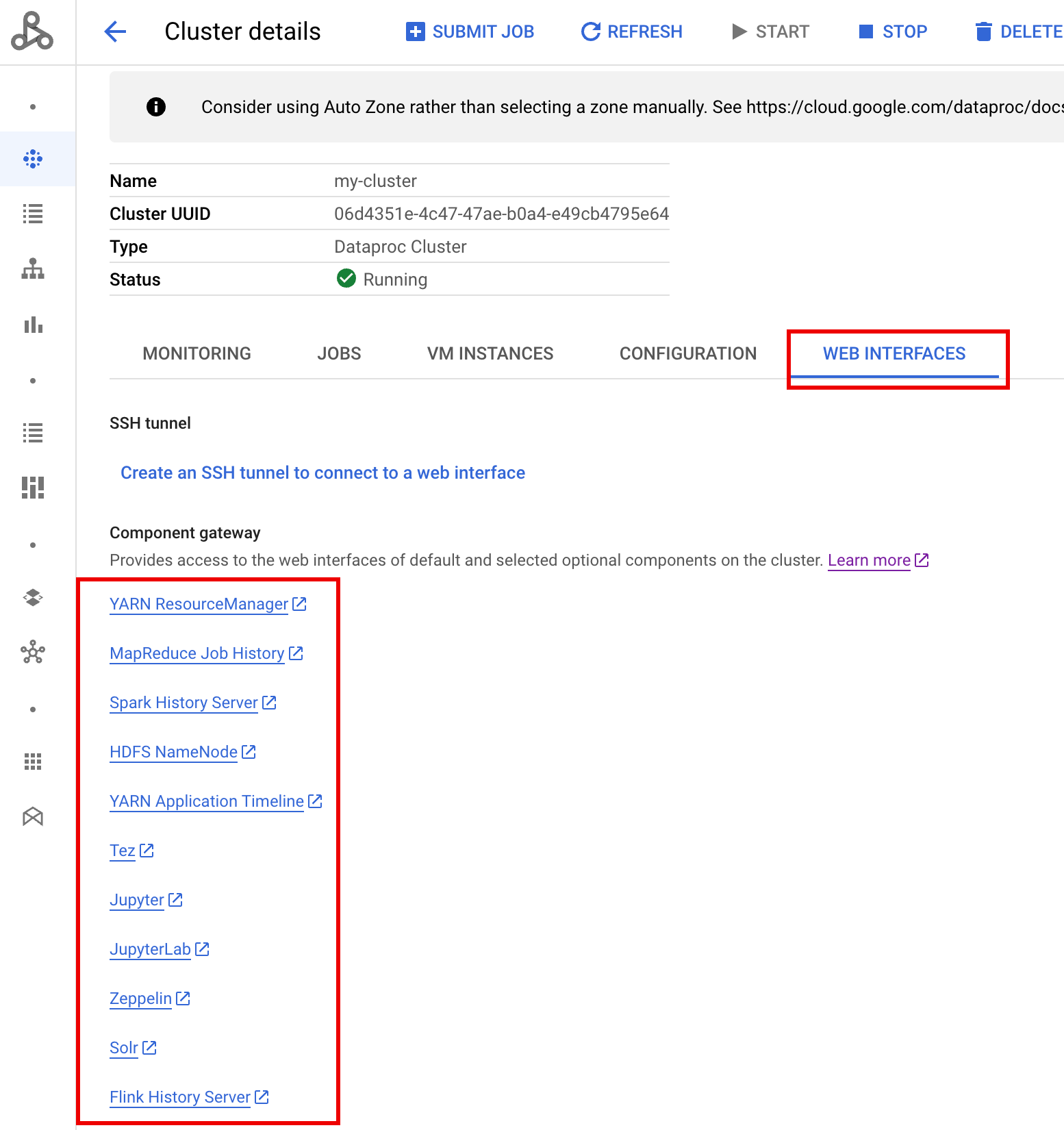
Accédez au formulaire Dataproc Clusters sur la console Google Cloud, puis sélectionnez votre cluster pour ouvrir le formulaire Cluster details (Détails du cluster). Cliquez sur l'onglet Web Interfaces (Interfaces Web) pour afficher la liste des liens de la passerelle des composants vers les interfaces Web des composants par défaut et facultatifs installés sur le cluster. Cliquez sur un lien pour ouvrir l'interface Web s'exécutant sur le nœud maître du cluster dans votre navigateur local.
Commande gcloud
Exécutez en local la commande gcloud CLI gcloud dataproc clusters describe dans une fenêtre de terminal ou dans Cloud Shell.
gcloud dataproc clusters describe cluster-name \ --region=region
Exemple de résultat
...
config:
endpointConfig:
enableHttpPortAccess: true
httpPorts:
HDFS NameNode:
https://584bbf70-7a12-4120-b25c-31784c94dbb4-dot-dataproc.google.com/hdfs/
MapReduce Job History:
https://584bbf70-7a12-4120-b25c-31784c94dbb4-dot-dataproc.google.com/jobhistory/
Spark HistoryServer:
https://584bbf70-7a12-4120-b25c-31784c94dbb4-dot-dataproc.google.com/sparkhistory/
YARN ResourceManager:
https://584bbf70-7a12-4120-b25c-31784c94dbb4-dot-dataproc.google.com/yarn/
YARN Application Timeline:
https://584bbf70-7a12-4120-b25c-31784c94dbb4-dot-dataproc.google.com/apphistory/
...
API REST
Appelez clusters.get pour obtenir le mappage endpointConfig.httpPorts des noms de port et des URL.Utiliser la passerelle des composants avec VPC-SC
La passerelle des composants est compatible avec VPC Service Controls.
Pour l'application du périmètre de service, les requêtes envoyées aux interfaces via la passerelle des composants sont traitées comme faisant partie de la surface de l'API Dataproc, et toutes les règles d'accès contrôlant les autorisations pour dataproc.googleapis.com contrôlent également l'accès aux interfaces utilisateur de la passerelle des composants.
La passerelle des composants accepte également les configurations VPC-SC basées sur la connectivité Google privée pour les clusters Dataproc sans adresses IP externes, mais vous devez configurer manuellement votre réseau afin d'autoriser l'accès de la VM maître Dataproc à *.dataproc.cloud.google.com via la plage d'adresses IP virtuelles Google restreinte 199.36.153.4/30 en procédant comme suit :
- Suivez les instructions pour configurer la connectivité Google privée pour toutes les API Google.
- Configurez le DNS avec Cloud DNS ou configurez-le en local sur le nœud maître Dataproc pour autoriser l'accès à
*.dataproc.cloud.google.com.
Configurer le DNS avec Cloud DNS
Créez une zone Cloud DNS qui mappe le trafic destiné à *.dataproc.cloud.google.com avec la plage d'adresses IP virtuelles d'API Google restreinte.
Créez une zone privée gérée pour votre réseau VPC.
gcloud dns managed-zones create ZONE_NAME \ --visibility=private \ --networks=https://www.googleapis.com/compute/v1/projects/PROJECT_ID/global/networks/NETWORK_NAME \ --description=DESCRIPTION \ --dns-name=dataproc.cloud.google.com \ --project=PROJECT_ID
ZONE_NAME est le nom de la zone que vous créez. Exemple :
vpc. Le nom de la zone sera utilisé à chacune des étapes suivantes.PROJECT_ID est l'ID du projet qui héberge votre réseau VPC.
NETWORK_NAME est le nom du réseau VPC.
DESCRIPTION est une description lisible et facultative de la zone gérée.
Lancez une transaction.
gcloud dns record-sets transaction start --zone=ZONE_NAME
- ZONE_NAME correspond au nom de votre zone.
Ajoutez des enregistrements DNS.
gcloud dns record-sets transaction add --name=*.dataproc.cloud.google.com. \ --type=A 199.36.153.4 199.36.153.5 199.36.153.6 199.36.153.7 \ --zone=ZONE_NAME \ --ttl=300- ZONE_NAME correspond au nom de votre zone.
gcloud dns record-sets transaction add --name=dataproc.cloud.google.com. \ --type=A 199.36.153.4 199.36.153.5 199.36.153.6 199.36.153.7 \ --zone=ZONE_NAME \ --ttl=300- ZONE_NAME correspond au nom de votre zone.
Exécutez la transaction.
gcloud dns record-sets transaction execute --zone=ZONE_NAME --project=PROJECT_ID
ZONE_NAME correspond au nom de votre zone.
PROJECT_ID est l'ID du projet qui héberge votre réseau VPC.
Configurer le DNS en local sur le nœud maître Dataproc avec une action d'initialisation
Vous pouvez configurer le DNS en local sur les nœuds maîtres Dataproc pour autoriser la connectivité privée à dataproc.cloud.google.com. Cette procédure est conçue à des fins de test et de développement à court terme. Son utilisation n'est pas recommandée dans les charges de travail de production.
Préparez l'action d'initialisation dans Cloud Storage.
cat <<EOF >component-gateway-vpc-sc-dns-init-action.sh #!/bin/bash readonly ROLE="$(/usr/share/google/get_metadata_value attributes/dataproc-role)" if [[ "${ROLE}" == 'Master' ]]; then readonly PROXY_ENDPOINT=$(grep "^dataproc.proxy.agent.endpoint=" \ "/etc/google-dataproc/dataproc.properties" | \ tail -n 1 | cut -d '=' -f 2- | sed -r 's/\\([#!=:])/\1/g') readonly HOSTNAME=$(echo ${PROXY_ENDPOINT} | \ sed -n -E 's;^https://([^/?#]*).*;\1;p') echo "199.36.153.4 ${HOSTNAME} # Component Gateway VPC-SC" >> "/etc/hosts" fi EOF gsutil cp component-gateway-vpc-sc-dns-init-action.sh gs://BUCKET/- BUCKET correspond à un bucket Cloud Storage accessible à partir du cluster Dataproc.
Créez un cluster Dataproc avec l'action d'initialisation préparée et la passerelle des composants activée.
gcloud dataproc clusters create cluster-name \ --region=region \ --initialization-actions=gs://BUCKET/component-gateway-vpc-sc-dns-init-action.sh \ --enable-component-gateway \ other args ...
- BUCKET correspond au bucket Cloud Storage utilisé à l'étape 1 ci-dessus.
De manière automatisée à l'aide des API HTTP via la passerelle des composants
La passerelle des composants est un proxy qui intègre Apache Knox. Les points de terminaison exposés par Apache Knox sont disponibles via https://component-gateway-base-url/component-path.
Pour vous authentifier de manière automatisée avec la passerelle des composants, transmettez l'en-tête Proxy-Authorization avec un jeton de support OAuth 2.0.
$ ACCESS_TOKEN="$(gcloud auth print-access-token)"
$ curl -H "Proxy-Authorization: Bearer ${ACCESS_TOKEN}" "https://xxxxxxxxxxxxxxx-dot-us-central1.dataproc.googleusercontent.com/yarn/jmx"
{
"beans" : [ {
"name" : "Hadoop:service=ResourceManager,name=RpcActivityForPort8031",
"modelerType" : "RpcActivityForPort8031",
"tag.port" : "8031",
"tag.Context" : "rpc",
"tag.NumOpenConnectionsPerUser" : "{\"yarn\":2}",
"tag.Hostname" : "demo-cluster-m",
"ReceivedBytes" : 1928581096,
"SentBytes" : 316939850,
"RpcQueueTimeNumOps" : 7230574,
"RpcQueueTimeAvgTime" : 0.09090909090909091,
"RpcProcessingTimeNumOps" : 7230574,
"RpcProcessingTimeAvgTime" : 0.045454545454545456,
...
La passerelle des composants supprime l'en-tête Proxy-Authorization avant de transférer les requêtes à Apache Knox.
Pour trouver l'URL de base de la passerelle des composants, exécutez la commande suivante : gcloud dataproc clusters describe :
$ gcloud dataproc clusters describe <var>cluster-name</var> \
--region=<var>region</var>
...
endpointConfig:
enableHttpPortAccess: true
httpPorts:
HDFS NameNode: https://xxxxxxxxxxxxxxx-dot-us-central1.dataproc.googleusercontent.com/hdfs/dfshealth.html
MapReduce Job History: https://xxxxxxxxxxxxxxx-dot-us-central1.dataproc.googleusercontent.com/jobhistory/
Spark History Server: https://xxxxxxxxxxxxxxx-dot-us-central1.dataproc.googleusercontent.com/sparkhistory/
Tez: https://xxxxxxxxxxxxxxx-dot-us-central1.dataproc.googleusercontent.com/apphistory/tez-ui/
YARN Application Timeline: https://xxxxxxxxxxxxxxx-dot-us-central1.dataproc.googleusercontent.com/apphistory/
YARN ResourceManager: https://xxxxxxxxxxxxxxx-dot-us-central1.dataproc.googleusercontent.com/yarn/
...
L'URL de base correspond aux portions de schéma et d'autorité des URL situées sous httpPorts. Dans cet exemple, il s'agit de https://xxxxxxxxxxxxxxx-dot-us-central1.dataproc.googleusercontent.com/.
Regénérer le certificat SSL de la passerelle des composants
Le certificat SSL par défaut de la passerelle des composants est valide pour:
5 ans à compter de la date de création du cluster Dataproc sur les clusters créés avec les versions d'images 2.0.93, 2.1.41, 2.2.7 et versions ultérieures.
13 mois à compter de la date de création du cluster Dataproc sur les clusters créés à l'aide de versions d'image antérieures.
Si le certificat expire, toutes les URL de l'interface Web de la passerelle des composants deviennent inactives.
Si votre organisation vous a fourni le certificat SSL, obtenez-en un nouveau, puis remplacez l'ancien certificat par le nouveau.
Si vous utilisez le certificat SSL autosigné par défaut, renouvelez-le comme suit:
Utilisez SSH pour vous connecter au nœud maître du cluster Dataproc avec le suffixe de nom
m-0.Recherchez
gateway.jksdans le chemin d'accès/var/lib/knox/security/keystores/gateway.jks.keytool -list -v -keystore /var/lib/knox/security/keystores/gateway.jks
Déplacez le fichier
gateway.jksvers un répertoire de sauvegarde.mv /var/lib/knox/security/keystores/gateway.jks /tmp/backup/gateway.jks
Créez un certificat autosigné en redémarrant le service Knox.
systemctl restart knox
Vérifiez l'état de la passerelle des composants et de Knox.
systemctl status google-dataproc-component-gateway systemctl status knox
Étape suivante
- Créez un cluster avec des composants Dataproc.