Dataprep by Trifacta
An intelligent cloud data service to visually explore, clean, and prepare data for analysis and machine learning.
View documentation for this product.

Intelligent data preparation
What's new

Serverless simplicity
Dataprep is an integrated partner service operated by Trifacta and based on their industry-leading data preparation solution. Google works closely with Trifacta to provide a seamless user experience that removes the need for up-front software installation, separate licensing costs, or ongoing operational overhead. Dataprep is fully managed and scales on demand to meet your growing data preparation needs so you can stay focused on analysis.

Fast exploration and anomaly detection
Understand and explore data instantly with visual data distributions. Dataprep automatically detects schemas, data types, possible joins, and anomalies such as missing values, outliers, and duplicates so you get to skip the time-consuming work of assessing your data quality and go right to the exploration and analysis.
Easy and powerful data preparation
With each gesture in the UI, Dataprep automatically suggests and predicts your next ideal data transformation. Once you’ve defined your sequence of transformations, Dataprep uses Dataflow or BigQuery under the hood, enabling you to process structured or unstructured datasets of any size with the ease of clicks, not code.
Dataprep features
Starter, Professional, and Enterprise editions.
Predictive transformation
Dataprep uses a proprietary inference algorithm to interpret the data transformation intent of a user’s data selection. A ranked set of suggestions and patterns for the selections to match are automatically generated.
Rich transformations
Leverage hundreds of transformation functions to turn your data into the asset you want. With a click of a mouse, apply aggregation, pivot, unpivot, joins, union, extraction, calculation, comparison, condition, merge, regular expressions, and more.
Optimized processing throughput
Dataprep automatically selects the best underlying Google Cloud processing engine to transform the data as fast as possible. Based on the data locality and volume, Dataprep leverages BigQuery (in-place ELT transforms) to prepare the data, Dataflow, or for small volumes Dataprep's in-memory engine.
Active profiling
See and explore your data through interactive visual distributions of your data to assist in discovery, cleansing, and transformation. Visual representations help interpret large volumes of data, and Dataprep’s innovative profiling techniques visualize key statistical information in a dynamic, easy-to-consume format.
Data quality rules
Data quality rules suggest data quality indicators to monitor and remediate the accuracy, completeness, consistency, validity, and uniqueness of the data, ensuring that you have a comprehensive view of the cleanliness of your data.
Collaboration
In team environments, it can be helpful to be able to have multiple users work on the same assets or to create copies of good quality work to serve as templates for others. Dataprep enables users to collaborate on the same flow objects in real time or to create copies for others to use for independent work.
Comprehensive connectivity
In addition to BigQuery, Cloud Storage, Microsoft Excel, and Google Sheets standard connectivity, enrich your self-service analytics with hundreds of data sources such as Salesforce, Oracle, Microsoft SQL Server, MySQL, PostgreSQL, and many more.
Data pipeline orchestration
Schedule and automate your data preparation jobs by chaining them together in sequential and conditional order. Alert users of success or failure, and trigger external tasks (such as Cloud Functions). Leverage comprehensive APIs to integrate Dataprep as part of an enterprise’s end-to-end solution.
Enterprise-scale operationalization
Adopt a continuous deployment practice with recipe import/export across editions and versions, flow parameters, custom configuration for Dataflow or BigQuery, performance tuning, and advanced APIs to automate software development life cycles and monitoring.
Common data types
Transform structured or unstructured datasets stored in CSV, JSON, relational table formats, or SaaS application data of any size—megabytes to petabytes—with equal ease and simplicity.
Pattern matching
Utilize columnar pattern matching to identify data patterns of interest to you and to surface them in the interface for use in building your recipes. Additionally, in your recipe steps, you can apply regular expressions or Dataprep patterns to locate patterns and transform the matching data in your datasets.
Standardization
Group values by similarities based on spelling or language-independent pronunciation and create standardized clusters of consistent values.
Sampling
For performance optimization, Dataprep automatically generates one or more samples of the data for display and manipulation in the client application. However, you can easily change the size of samples, the scope of the sample, and the method by which the sample is created.
Advanced security
Expand on current security standards by providing individual data access control using a combination of Google IAM roles and BigQuery, Cloud Storage, and Google Sheets access rights to determine access.
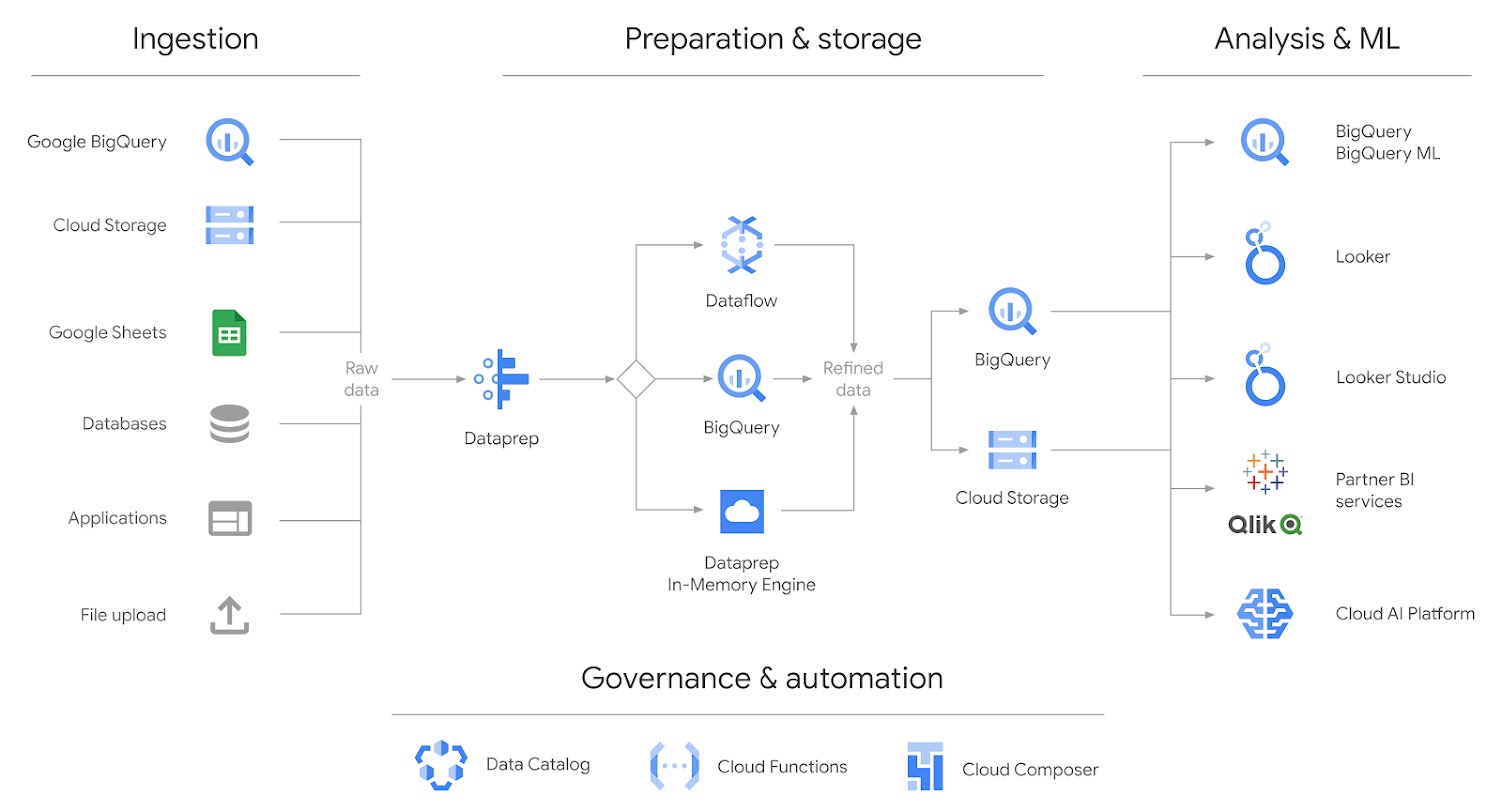
Dataprep ELT pipeline architecture

"Dataprep allows us to quickly explore new datasets, and its flexibility supports all our data transformation needs. Data preparation work at Merkle is now completed in minutes, not hours or days, accelerating our data preparation time by 90%."
Henry Culver, IT Architect, Merkle
Read storyOur customers






Resources
-
Get started with the Dataprep quickstart
-
Dataprep product announcements and updates
-
Engage with other Dataprep users on Stack Overflow
-
Dataprep by Trifacta FAQsLearn how Trifacta complies with security, privacy, and data protection.
-
Automate Dataprep pipelines on file arrival with Cloud Functions
-
Working with the Dataprep self-paced lab
-
ML automation with BigQuery ML, Dataprep, and Cloud Composer
-
Build a marketing data warehouse
-
How to stream IoT Core data to Dataprep


Pricing
View our pricing page in Google Cloud Marketplace.
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Start your next project, explore interactive tutorials, and manage your account.