Google Cloud は 2023 Forrester Wave: Streaming Data Platforms でリーダーに選出されました。詳細
Dataflow
サーバーレスかつ高速で、費用対効果の高い、統合されたストリーム データ処理とバッチデータ処理。
新規のお客様には、Dataflow で使用できる無料クレジット $300 分を差し上げます。
データ ストリーミングと機械学習によるリアルタイムの分析情報と有効活用
フルマネージドのデータ処理サービス
処理を実行するリソースの自動プロビジョニングと管理
リソース使用率を最大化する、ワーカー リソースの水平および垂直自動スケーリング
Apache Beam SDK による、OSS コミュニティ ドリブンのイノベーション

利点
高速なストリーミング データ分析
Dataflow を使用すると、データ転送のレイテンシを抑えた、高速で簡素化されたストリーミング データ パイプライン開発が可能になります。
操作と管理を簡素化する
Dataflow のサーバーレス アプローチにより、データ エンジニアリングのワークロードから運用上のオーバーヘッドが取り除かれるため、チームはサーバー クラスタの管理ではなく、プログラミングに専念できます。
総所有コストの低減
リソースの自動スケーリングとコスト最適化されたバッチ処理機能を組み合わせることにより、Dataflow で実質無制限の容量を利用できます。過剰な費用をかけずに、時季変動したり急変動したりするワークロードを管理できます。
主な機能
主な機能
すぐに使えるリアルタイム AI
NVIDIA GPU やすぐに使用できるパターンなど、すぐに使える ML 機能によって実現される Dataflow のリアルタイム AI 機能により、大量のイベントに対する人間に近い知性によるリアルタイムの応答が可能になります。
お客様は、予測分析や異常検出から、リアルタイム パーソナライズなどの高度な分析のユースケースまで、インテリジェントなソリューションを構築できます。
バッチ パイプラインとストリーミング パイプラインを使用したローカルおよびリモートの推論など、完全な機械学習(ML)パイプラインをトレーニング、デプロイ、管理します。
リソースの自動スケーリングと動的作業再調整
データアウェア リソースの自動スケーリングにより、パイプラインのレイテンシの最小化、リソース使用率の最大化、データレコードあたりの処理コストの削減を実現します。データ入力は、自動的にパーティション分割され、常にリバランスされることで、ワーカー リソース使用率が均等化され、パイプラインのパフォーマンスに対する「ホットキー」の影響が軽減されます。
モニタリングとオブザーバビリティ
Dataflow パイプラインの各ステップでデータを監視します。実際のデータのサンプルを使用して問題を診断し、効果的にトラブルシューティングを行います。ジョブの異なる実行を比較して、問題を簡単に特定します。
導入事例
Dataflow を利用しているお客様









ドキュメント
ドキュメント
Python を用いた Dataflow のクイックスタート
Apache Beam と TensorFlow による機械学習
Java を使用した Dataflow 単語数カウント チュートリアル
ハンズオンラボ: Google Cloud Dataflow によるデータ処理
ハンズオンラボ: Pub/Sub と Dataflow を使用したストリーム処理
お探しのものが見つからない場合
ユースケース
ユースケース
ストリーム分析
Google Cloud のストリーム分析は、データを生成された瞬間から整理され、便利で使いやすいものにします。Dataflow、Pub/Sub、BigQuery 上に構築されたストリーミング ソリューションにより、変動するリアルタイムのデータ ボリュームの取り込み、処理、分析に必要なリソースをプロビジョニングして、リアルタイムにビジネス分析情報を取得できるようになります。プロビジョニングが抽象化されて複雑さが軽減されるため、データ アナリストとデータ エンジニアのいずれもストリーム分析にアクセスできます。
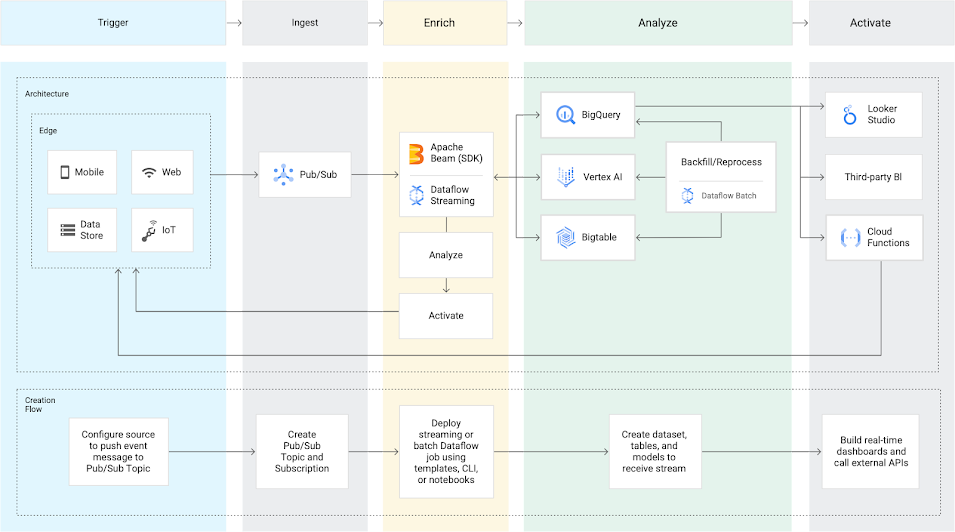
リアルタイム AI
Dataflow により、Google Cloud の Vertex AI と TensorFlow Extended(TFX)にストリーミング イベントが送信されます。これにより、予測分析、不正行為検出、リアルタイム パーソナライズなどの高度な分析ユースケースが可能となります。TFX は、分散データ処理エンジンとして Dataflow と Apache Beam を使用し、ML ライフサイクルの複数の段階を実現します。これらはすべて Kubeflow パイプラインを通じて、ML の CI / CD でサポートされています。
すべての機能
すべての機能
| Dataflow ML | 機械学習(ML)パイプラインを簡単にデプロイして管理できます。ML モデルを使用して、バッチ パイプラインとストリーミング パイプラインでローカルとリモートの推論を行います。データ処理ツールを使用して、モデルのトレーニング用のデータを準備し、モデルの結果を処理します。 |
| Dataflow GPU | GPU 使用のパフォーマンスとコストのために最適化されたデータ処理システム。幅広い NVIDIA GPU をサポート。 |
| 垂直自動スケーリング | 各ワーカーに割り振られたコンピューティング容量を、使用率に基づいて動的に調整します。垂直自動スケーリングは水平自動スケーリングと連携し、パイプラインのニーズに最適なワーカーをシームレスにスケールします。 |
| 水平自動スケーリング | 水平自動スケーリングを有効にすると、Dataflow サービスはジョブの実行に必要な適切な数のワーカー インスタンスを自動的に選択します。また、Dataflow サービスは、実行時にジョブの特性を考慮して、より多くのワーカーまたは少数のワーカーを動的に再割り当てします。 |
| Right Fitting | Right fitting を行うと、ステージごとに最適化されたリソースプールが作成され、リソースの無駄を削減できます。 |
| スマート診断 | 一連の機能には、以下のようなものがあります。1)SLO ベースのデータ パイプライン管理、2)視覚的にジョブグラフを調べてボトルネックを特定するためのジョブ可視化機能、3)パフォーマンスや可用性の問題を特定して調整する自動レコメンデーション機能。 |
| Streaming Engine | Streaming Engine は、コンピューティングとステート ストレージを分離し、パイプライン実行の一部をワーカー VM から Dataflow サービス バックエンドに移動させることで、自動スケーリングとデータ転送のレイテンシを大幅に改善します。 |
| Dataflow Shuffle | サービスベースの Dataflow Shuffle は、データのグルーピングや結合で使用されるシャッフル オペレーションを、ワーカー VM からバッチ パイプラインの Dataflow サービス バックエンドに移行します。バッチ パイプラインにより、数百 TB までシームレスにスケーリングされます。チューニングは必要ありません。 |
| Dataflow SQL | Dataflow SQL では、SQL スキルを使用して BigQuery ウェブ UI から直接ストリーミング Dataflow パイプラインを開発できます。Pub/Sub からのストリーミング データを Cloud Storage のファイルまたは BigQuery のテーブルに結合し、結果を BigQuery に書き込み、Google スプレッドシートまたは他の BI ツールを使用してリアルタイムのダッシュボードを構築できます。 |
| 柔軟なリソース スケジューリング(FlexRS) | Dataflow FlexRS は、高度なスケジューリング技術、Dataflow Shuffle サービス、プリエンプティブル仮想マシン(VM)インスタンスと通常の VM の組み合わせを使用することで、バッチ処理コストを削減します。 |
| Dataflow テンプレート | Dataflow テンプレートで、パイプラインをチームメンバーや組織全体で簡単に共有できます。また、Google が提供する多くのテンプレートを利用して、シンプルながら便利なデータ処理タスクを実装することもできます。これには、ストリーミング分析のユースケースのための変更データ キャプチャ テンプレートが含まれます。Flex テンプレートでは、任意の Dataflow パイプラインからテンプレートを作成できます。 |
| Notebooks との統合 | Vertex AI Notebooks でパイプラインを一からイテレーションを経て構築し、Dataflow ランナーでデプロイします。 Apache Beam パイプラインを段階的に作成するには、パイプラインのグラフを「入力、評価、出力」ループ(REPL)のワークフローで検査します。Google の Vertex AI を通じて利用できる Notebooks を使用すると、最新のデータ サイエンスと機械学習フレームワークを備えた直感的な環境でパイプラインを記述できます。 |
| リアルタイムの変更データ キャプチャ | ストリーミング分析を強化するために、異種混合データソース全体でデータを確実に同期または複製し、レイテンシを最小限に抑えます。拡張可能な Dataflow テンプレートは Datastream と統合され、Cloud Storage から BigQuery、PostgreSQL、または Spanner にデータを複製します。Apache Beam の Debezium コネクタは、MySQL、PostgreSQL、SQL Server、Db2 からデータ変更を取り込むためのオープンソース オプションを提供します。 |
| インライン モニタリング | Dataflow のインライン モニタリングでジョブの指標に直接アクセスして、バッチ パイプラインとストリーミング パイプラインのトラブルシューティングに役立てることができます。モニタリング グラフにアクセスして、ステップレベルとワーカーレベルの両方で状況を把握し、古いデータや大きなシステム レイテンシなどの条件でアラートを設定できます。 |
| 顧客管理の暗号鍵 | 顧客管理の暗号鍵(CMEK)で保護されたバッチまたはストリーミング パイプラインを作成できます。また、ソースとシンクで CMEK で保護されたデータにアクセスできます。 |
| Dataflow VPC Service Controls | Dataflow の VPC Service Controls と統合することで、データ流出リスクが軽減され、データ処理環境のセキュリティが強化されます。 |
| プライベート IP | パブリック IP をオフにすると、データ処理インフラストラクチャのセキュリティを強化できます。Dataflow ワーカーにパブリック IP アドレスを使用しないことで、Google Cloud プロジェクトの割り当てに対して消費されるパブリック IP アドレスの数も削減できます。 |
料金
料金
Dataflow ジョブは、Dataflow バッチまたはストリーミング ワーカーの実際の使用量に基づき、秒単位で課金されます。他のリソース(Cloud Storage や Pub/Sub など)では、該当するサービスの料金に応じて、サービスごとに課金されます。
パートナー
パートナー ソリューションを探す
Google Cloud のパートナーが Dataflow との統合機能を開発しており、さまざまな規模での強力なデータ処理タスクが迅速かつ容易に行えるようになっています。




Cloud AI プロダクトは、Google の SLA ポリシーに準拠しています。これらの SLA ポリシーで保証されているレイテンシや可用性は、他の Google Cloud サービスと異なる場合があります。
開始にあたりサポートが必要な場合
お問い合わせ信頼できるパートナーと連携する
パートナーを探すもっと見る
すべてのプロダクトを見る












