Google Cloud ha ricevuto il titolo di Leader nel report 2023 Forrester Wave: Streaming Data Platforms. Ulteriori informazioni.
Dataflow
Elaborazione unificata dei dati in modalità flusso e batch serverless, veloce e conveniente.
I nuovi clienti ricevono 300 $ di crediti gratuiti da spendere su Dataflow.
Insight e attivazione in tempo reale con flussi di dati e machine learning
Servizio di elaborazione dati completamente gestito
Provisioning e gestione automatizzati delle risorse di elaborazione
Scalabilità automatica orizzontale e verticale delle risorse worker per massimizzare l'utilizzo delle risorse
Innovazione guidata dalla community del software open source con l'SDK Apache Beam

Vantaggi
Analizza rapidamente i flussi di dati
Dataflow velocizza e semplifica lo sviluppo di pipeline di dati in modalità flusso garantendo una latenza dei dati minore.
Semplifica operazioni e gestione
Puoi consentire ai team di concentrarsi sulla programmazione invece che sulla gestione dei cluster di server grazie all'approccio serverless di Dataflow, che elimina i problemi di sovraccarico operativo dai carichi di lavoro di data engineering.
Riduci il costo totale di proprietà
Grazie alla scalabilità automatica delle risorse e all'ottimizzazione dei costi per l'elaborazione batch, Dataflow offre una capacità praticamente illimitata per gestire i carichi di lavoro durante i picchi e i periodi di punta stagionali senza spendere troppo.
Funzionalità principali
Funzionalità principali
IA in tempo reale pronta all'uso
Abilitate tramite funzionalità ML pronte all'uso, tra cui la GPU NVIDIA e pattern pronti all'uso, le funzionalità di AI in tempo reale di Dataflow consentono reazioni in tempo reale con intelligenza quasi umana a grandi flussi di eventi.
I clienti possono creare soluzioni intelligenti che vanno dall'analisi predittiva e dal rilevamento di anomalie alla personalizzazione in tempo reale e ad altri casi d'uso di analisi avanzata.
Addestra, esegui il deployment e gestisci pipeline di machine learning (ML) complete, inclusa l'inferenza locale e remota con pipeline in modalità flusso e batch.
Scalabilità automatica delle risorse e ridistribuzione dinamica del lavoro
Riduci al minimo i tempi di latenza della pipeline, ottimizza l'utilizzo delle risorse e abbatti i costi di elaborazione per record di dati mediante la scalabilità automatica delle risorse sensibili ai dati. Gli input di dati vengono partizionati automaticamente e ridistribuiti costantemente per livellare l'utilizzo delle risorse dei worker e ridurre l'effetto dei "tasti di scelta rapida" sulle prestazioni della pipeline.
Monitoraggio e osservabilità
Osserva i dati in ogni passaggio di una pipeline Dataflow. Diagnostica i problemi e risolvili in modo efficace utilizzando dei campioni di dati effettivi. Confronta diverse esecuzioni del job per identificare facilmente i problemi.
Clienti
Impara dai clienti che utilizzano Dataflow









Documentazione
Documentazione
Serverless Data Processing with Dataflow: Foundations
Guida rapida di Dataflow mediante Python
Utilizzo di Dataflow SQL
Installazione dell'SDK Apache Beam
Machine learning con Apache Beam e TensorFlow
Tutorial sul conteggio di parole Dataflow tramite Java
Lab pratici: elaborazione dei dati con Google Cloud Dataflow
Lab pratici: elaborazione dei flussi con Pub/Sub e Dataflow
Risorse Dataflow
Non trovi ciò che stai cercando?
Casi d'uso
Casi d'uso
Analisi dei flussi
L'analisi dei flussi di Google rende i dati più organizzati, utili e accessibili fin dal momento in cui vengono generati. Basata su Dataflow insieme a Pub/Sub e BigQuery, la nostra soluzione per i flussi di dati fornisce le risorse necessarie per importare, elaborare e analizzare volumi variabili di dati in tempo reale per ottenere degli insight sull'attività in tempo reale. Questo provisioning astratto riduce la complessità e rende l'analisi dei flussi accessibile sia ai data analyst che ai data engineer.
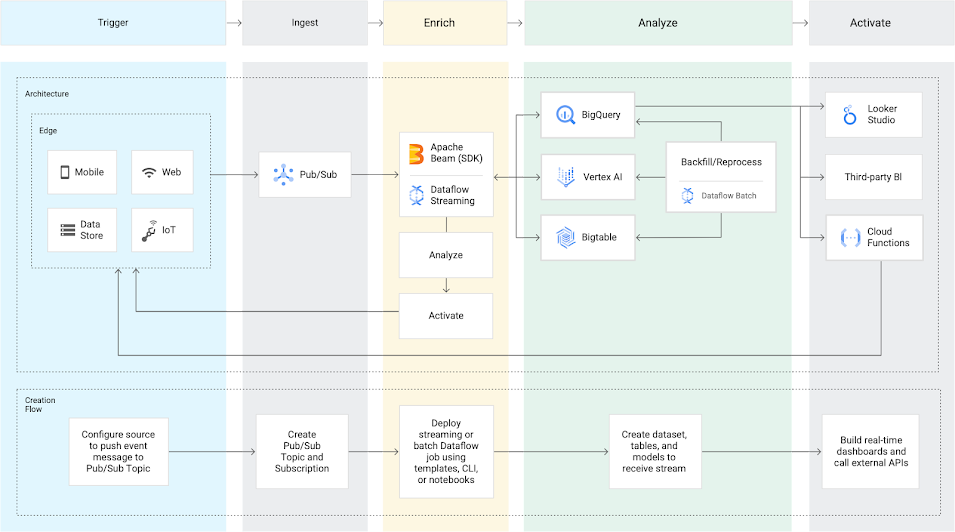
AI in tempo reale
Dataflow integra gli eventi di flusso nell'ambiente Vertex AI e TensorFlow Extended (TFX) di Google Cloud per consentire l'analisi predittiva, il rilevamento delle frodi, la personalizzazione in tempo reale e altri casi d'uso di analisi avanzata. TFX utilizza Dataflow e Apache Beam come motore di elaborazione di dati distribuiti al fine di gestire vari aspetti del ciclo di vita ML, tutti supportati con CI/CD per ML tramite pipeline Kubeflow.
Elaborazione dei dati di sensori e log
Ricava insight sull'attività dalla tua rete di dispositivi globale grazie a una piattaforma IoT intelligente.
Tutte le funzionalità
Tutte le funzionalità
| Dataflow ML | Esegui il deployment e gestisci facilmente le pipeline di machine learning (ML). Utilizza i modelli di machine learning per eseguire l'inferenza locale e remota con pipeline in modalità flusso e batch. Utilizza gli strumenti di elaborazione dati per preparare i dati per l'addestramento del modello e per elaborare i risultati dei modelli. |
| GPU Dataflow | Sistema di elaborazione dati ottimizzato per le prestazioni e i costi dell'utilizzo della GPU. Supporto per un'ampia gamma di GPU NVIDIA. |
| Scalabilità automatica verticale | Regola dinamicamente la capacità di calcolo allocata a ciascun worker in base all'utilizzo. La scalabilità automatica verticale si integra alla perfezione con la scalabilità automatica orizzontale per scalare senza problemi i worker per adattarsi al meglio alle esigenze della pipeline. |
| Scalabilità automatica orizzontale | La scalabilità automatica consente al servizio Dataflow di scegliere automaticamente il numero appropriato di istanze worker necessarie per eseguire il tuo job. Il servizio Dataflow può anche riallocare dinamicamente più o meno worker durante il runtime in base alle caratteristiche del tuo job. |
| Adattabilità | L'adattabilità crea pool di risorse specifiche per fase, ottimizzati per ciascuna fase per ridurre lo spreco di risorse. |
| Diagnostica smart | Una suite di funzionalità che comprendono 1) gestione delle pipeline di dati basata su SLO, 2) funzionalità di visualizzazione del job che offrono agli utenti un modo visivo per ispezionare il grafico del job e individuare i colli di bottiglia, 3) suggerimenti automatici per identificare e correggere i problemi di prestazioni e disponibilità. |
| Streaming Engine | Streaming Engine separa il computing dall'archiviazione dello stato e trasferisce parte dell'esecuzione delle pipeline dalle VM worker al servizio Dataflow backend, migliorando notevolmente la scalabilità automatica e la latenza dei dati. |
| Dataflow Shuffle | Dataflow Shuffle, basato su servizi, trasferisce l'operazione di shuffle, usata per il raggruppamento e l'unione dei dati, dalle VM worker al servizio Dataflow backend per le pipeline batch. Le pipeline batch possono essere facilmente scalate, senza necessità di tuning, in centinaia di terabyte. |
| Dataflow SQL | Dataflow SQL ti permette di sfruttare le tue competenze su SQL per sviluppare pipeline di Dataflow in modalità flusso direttamente dall'interfaccia utente web di BigQuery. Puoi unire flussi di dati di Pub/Sub a file di Cloud Storage o tabelle di BigQuery, scrivere i risultati in BigQuery e creare dashboard in tempo reale con Fogli Google o altri strumenti di business intelligence. |
| Pianificazione flessibile delle risorse (FlexRS) | Dataflow FlexRS riduce i costi di elaborazione batch grazie a tecniche di pianificazione avanzate, al servizio Dataflow Shuffle e a una combinazione di istanze di macchine virtuali prerilasciabili e VM standard. |
| modelli Dataflow | Con i modelli Dataflow puoi condividere facilmente le tue pipeline con i membri del team e dell'intera organizzazione oppure sfruttare i numerosi modelli forniti da Google per implementare attività di elaborazione dati semplici ma utili. Sono inclusi i modelli Change Data Capture per i casi d'uso sull'analisi dei flussi di dati. Con i modelli flessibili, puoi creare un modello da qualsiasi pipeline Dataflow. |
| Integrazione con Notebooks | Crea in modo iterativo pipeline complete con Vertex AI Notebooks ed esegui il deployment con l'esecutore di Dataflow. Genera pipeline Apache Beam dettagliate ispezionando i grafici delle pipeline in un flusso di lavoro Read–Eval–Print Loop (REPL). Disponibile tramite Vertex AI di Google, Notebooks ti consente di scrivere pipeline in un ambiente intuitivo con i più recenti framework di data science e machine learning. |
| Change Data Capture in tempo reale | Sincronizza o replica i dati in modo affidabile e con una latenza minima tra le origini dati eterogenee per ottimizzare l'analisi dei flussi di dati. I modelli Dataflow estensibili si integrano con Datastream per replicare i dati da Cloud Storage in BigQuery, PostgreSQL o Cloud Spanner. Il connettore Debezium di Apache Beam offre un'opzione open source per importare le modifiche dei dati da MySQL, PostgreSQL, SQL Server e Db2. |
| Monitoraggio incorporato | La funzionalità di monitoraggio incorporato di Dataflow ti consente di accedere direttamente alle metriche dei job per facilitare la risoluzione dei problemi relativi alle pipeline in modalità batch e flusso. Puoi accedere ai grafici di monitoraggio con visibilità a livello sia di fase che di worker e impostare avvisi per condizioni come dati inattivi ed elevata latenza di sistema. |
| Chiavi di crittografia gestite dal cliente | Puoi creare una pipeline in modalità batch o flusso protetta con una chiave di crittografia gestita dal cliente (CMEK) o accedere a dati protetti tramite CMEK in origini e sink. |
| Controlli di servizio VPC di Dataflow | L'integrazione di Dataflow con i Controlli di servizio VPC aumenta la sicurezza dell'ambiente di elaborazione dati migliorando la tua capacità di ridurre il rischio di esfiltrazione di dati. |
| IP privati | La disattivazione degli IP pubblici assicura una maggiore protezione dell'infrastruttura di elaborazione dati. Evitando di utilizzare indirizzi IP pubblici per i worker di Dataflow, riduci anche il numero di indirizzi IP pubblici conteggiati nella tua quota di progetto Google Cloud. |
Prezzi
Prezzi
I job di Dataflow vengono fatturati al secondo, sulla base dell'utilizzo effettivo dei worker in modalità batch o flusso di Dataflow. Ulteriori risorse, come Cloud Storage o Pub/Sub, vengono fatturate in base al prezzo del servizio corrispondente.
Partner
Esplora le soluzioni dei partner
I partner Google Cloud hanno sviluppato integrazioni con Dataflow che consentono di eseguire in modo rapido e semplice attività avanzate di elaborazione dati di qualsiasi dimensione.




I prodotti di AI Cloud sono conformi alle nostre norme relative allo SLA. Possono offrire garanzie di latenza o disponibilità diverse rispetto ad altri servizi Google Cloud.
Fai il prossimo passo
Inizia a creare su Google Cloud con 300 $ di crediti gratuiti e oltre 20 prodotti Always Free.
Hai bisogno di aiuto per iniziare?
Contatta il team di venditaCollabora con un partner di fiducia
Trova un partnerContinua la navigazione
Visualizza tutti i prodotti












