Guide de démarrage rapide avec SQL
Dans ce guide de démarrage rapide, vous allez découvrir comment utiliser la syntaxe SQL pour interroger un sujet Pub/Sub accessible publiquement. La requête SQL exécute un pipeline Dataflow et les résultats du pipeline sont écrits dans une table BigQuery.
Pour exécuter une tâche Dataflow SQL, vous pouvez utiliser Google Cloud Console, Google Cloud CLI installée sur une machine locale ou Cloud Shell. En plus de Cloud Console, cet exemple nécessite l'utilisation d'un ordinateur local ou de Cloud Shell.
Avant de commencer
- Connectez-vous à votre compte Google Cloud. Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $ de crédits gratuits pour exécuter, tester et déployer des charges de travail.
-
Dans Google Cloud Console, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
-
Vérifiez que la facturation est activée pour votre projet Google Cloud.
-
Activer les API Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager, et Google Cloud Data Catalog .
-
Dans Google Cloud Console, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
-
Vérifiez que la facturation est activée pour votre projet Google Cloud.
-
Activer les API Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager, et Google Cloud Data Catalog .
Installer et initialiser gcloud CLI
Téléchargez le package
gcloudCLI correspondant à votre système d'exploitation, puis installez et configurezgcloudCLI.Selon votre connexion Internet, le téléchargement peut prendre un certain temps.
Créer un ensemble de données BigQuery
Dans ce guide de démarrage rapide, le pipeline Dataflow SQL publie un ensemble de données BigQuery dans une table BigQuery que vous allez créer dans la section suivante.
Créez un ensemble de données BigQuery nommé
taxirides:bq mk taxirides
Exécuter le pipeline
Exécutez un pipeline Dataflow SQL qui calcule le nombre de passagers par minute sur la base de données concernant des courses en taxi, provenant d'un sujet Pub/Sub accessible publiquement. Cette commande crée également une table BigQuery nommée
passengers_per_minutepour stocker les données produites en sortie.gcloud dataflow sql query \ --job-name=dataflow-sql-quickstart \ --region=us-central1 \ --bigquery-dataset=taxirides \ --bigquery-table=passengers_per_minute \ 'SELECT TUMBLE_START("INTERVAL 60 SECOND") as period_start, SUM(passenger_count) AS pickup_count, FROM pubsub.topic.`pubsub-public-data`.`taxirides-realtime` WHERE ride_status = "pickup" GROUP BY TUMBLE(event_timestamp, "INTERVAL 60 SECOND")'Le démarrage de la tâche Dataflow SQL peut prendre un certain temps.
Les éléments suivants décrivent les valeurs utilisées dans le pipeline Dataflow SQL :
dataflow-sql-quickstart: nom de la tâche Dataflowus-central1: région dans laquelle la tâche est exécutéetaxirides: nom de l'ensemble de données BigQuery utilisé en tant que récepteurpassengers_per_minute: nom de la table BigQuerytaxirides-realtime: nom du sujet Pub/Sub utilisé comme source
La commande SQL interroge le sujet Pub/Sub taxirides-realtime pour connaître le nombre total de passagers pris en charge toutes les 60 secondes. Ce sujet public est basé sur l'ensemble de données ouvert de la NYC Taxi & Limousine Commission.
Afficher les résultats
Vérifiez que le pipeline est en cours d'exécution.
Console
Dans Cloud Console, accédez à la page Tâches Dataflow.
Dans la liste des tâches, cliquez sur dataflow-sql-quickstart.
Dans le panneau Informations sur la tâche, vérifiez que le champ État de la tâche est défini sur En cours d'exécution.
Le démarrage de la tâche peut prendre plusieurs minutes. L'état de la tâche est défini sur En file d'attente jusqu'à ce que la tâche démarre.
Dans l'onglet Graphique de tâche, vérifiez que chaque étape est exécutée.
Une fois la tâche démarrée, le lancement de l'exécution peut prendre plusieurs minutes.
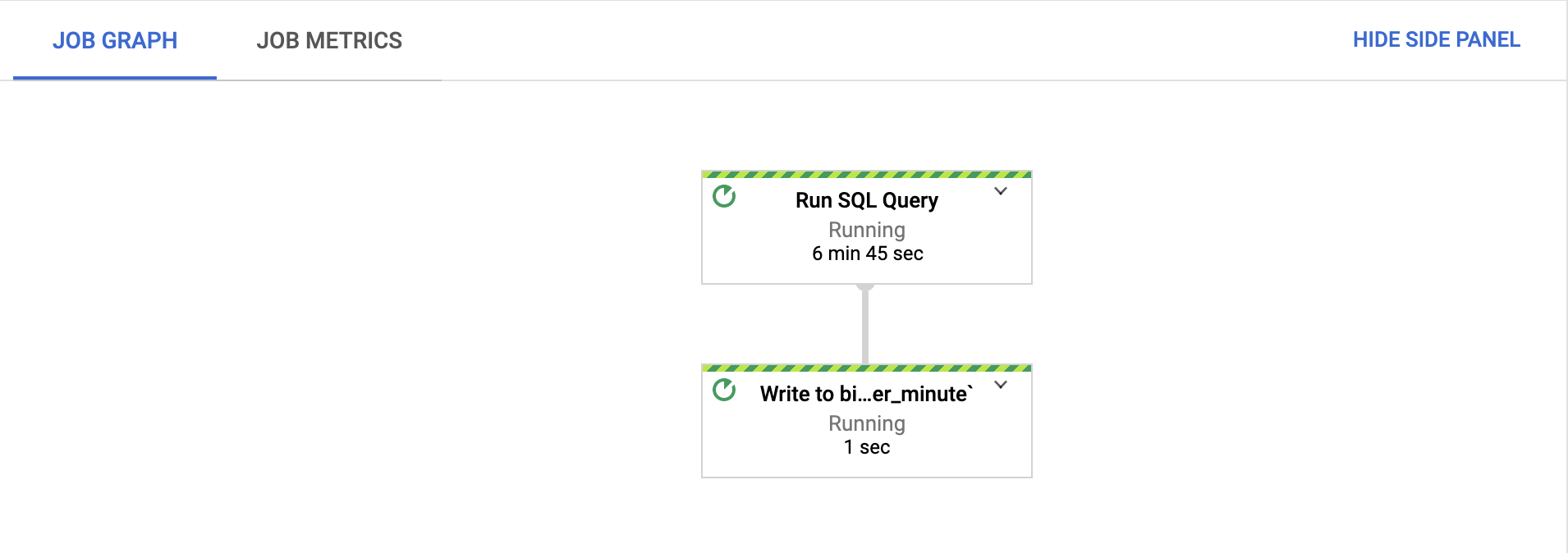
Dans Cloud Console, accédez à la page BigQuery.
Dans l'éditeur, collez la requête SQL suivante, puis cliquez sur Exécuter :
'SELECT * FROM taxirides.passengers_per_minute ORDER BY pickup_count DESC LIMIT 5'Cette requête renvoie les intervalles les plus chargés de la table
passengers_per_minute.
gcloud
Obtenez la liste des tâches Dataflow en cours d'exécution dans votre projet :
gcloud dataflow jobs listObtenez plus d'informations sur la tâche
dataflow-sql-quickstart:gcloud dataflow jobs describe JOB_IDRemplacez
JOB_IDpar l'ID de la tâchedataflow-sql-quickstartdans votre projet.Renvoie les intervalles les plus chargés de la table
passengers_per_minute.bq query \ 'SELECT * FROM taxirides.passengers_per_minute ORDER BY pickup_count DESC LIMIT 5'
Effectuer un nettoyage
Pour éviter que les ressources utilisées sur cette page soient facturées sur votre compte Google Cloud :
Pour annuler la tâche Dataflow, accédez à la page Tâches.
Dans la liste des tâches, cliquez sur dataflow-sql-quickstart.
Cliquez sur Arrêter > Annuler > Arrêter la tâche.
Supprimez l'ensemble de données
taxirides:bq rm taxiridesSaisissez
ypour confirmer la suppression.
Étape suivante
- En savoir plus sur l'utilisation de Dataflow SQL.
- Découvrez comment utiliser les sources et les destination des données dans les requêtes SQL Dataflow.
- Explorez
gcloudCLI pour Dataflow SQL.