Guía de inicio rápido para SQL
En esta guía de inicio rápido, aprenderás a escribir la sintaxis de SQL para consultar un tema de Pub/Sub disponible públicamente. La consulta en SQL ejecuta una canalización de Dataflow, y los resultados de la canalización se escriben en una tabla de BigQuery.
Para ejecutar un trabajo de Dataflow SQL, puedes usar Google Cloud CLI, el SDK de Cloud instalado en una máquina local o Cloud Shell. Además de Cloud Console, en este ejemplo se requiere que uses una máquina local o Cloud Shell.
Antes de comenzar
- Accede a tu cuenta de Google Cloud. Si eres nuevo en Google Cloud, crea una cuenta para evaluar el rendimiento de nuestros productos en situaciones reales. Los clientes nuevos también obtienen $300 en créditos gratuitos para ejecutar, probar y, además, implementar cargas de trabajo.
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
-
Habilita las API de Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager, y Google Cloud Data Catalog .
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud.
-
Habilita las API de Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager, y Google Cloud Data Catalog .
Instala y, luego, inicializa la CLI de gcloud
Descarga el paquete de la CLI
gcloudpara tu sistema operativo y, luego, instala y configura la CLI degcloud.Según tu conexión a Internet, la descarga puede tardar un poco.
Cree un conjunto de datos de BigQuery
En esta guía de inicio rápido, la canalización de Dataflow SQL publica un conjunto de datos de BigQuery en una tabla de BigQuery que crearás en la siguiente sección.
Crea un conjunto de datos de BigQuery llamado
taxirides:bq mk taxirides
Ejecuta la canalización
Ejecuta una canalización de Dataflow SQL que calcule la cantidad de pasajeros por minuto mediante los datos de un tema de Pub/Sub disponible de forma pública sobre viajes en taxi. Mediante este comando, también se crea una tabla de BigQuery llamada
passengers_per_minuteen la que se almacenará el resultado de los datos.gcloud dataflow sql query \ --job-name=dataflow-sql-quickstart \ --region=us-central1 \ --bigquery-dataset=taxirides \ --bigquery-table=passengers_per_minute \ 'SELECT TUMBLE_START("INTERVAL 60 SECOND") as period_start, SUM(passenger_count) AS pickup_count, FROM pubsub.topic.`pubsub-public-data`.`taxirides-realtime` WHERE ride_status = "pickup" GROUP BY TUMBLE(event_timestamp, "INTERVAL 60 SECOND")'El trabajo de Dataflow SQL puede tardar un tiempo en comenzar a ejecutarse.
A continuación, se describen los valores que se usan en la canalización de Dataflow SQL:
dataflow-sql-quickstart: Es el nombre del trabajo de Dataflow.us-central1: Es la región en la que se ejecuta el trabajo.taxirides: Es el nombre del conjunto de datos de BigQuery que se usa como receptor.passengers_per_minute: Es el nombre de la tabla de BigQuery.taxirides-realtime: Es el nombre del tema de Pub/Sub que se usa como fuente.
El comando de SQL consulta el tema de Pub/Sub taxirides-realtime sobre la cantidad total de pasajeros que se recogen cada 60 segundos. Este tema público se basa en el conjunto de datos abierto de la Comisión de Taxis y Limusinas de la Ciudad de Nueva York.
Observa los resultados.
Verifica que la canalización se esté ejecutando.
Console
En Cloud Console, ve a la página de Jobs.
En la lista de trabajos, haz clic en dataflow-sql-quickstart.
En el panel Información del trabajo, confirma que el campo Estado del trabajo esté configurado como En ejecución.
El trabajo puede tardar varios minutos en iniciarse. El Estado del trabajo se establece en En cola hasta que se inicia el trabajo.
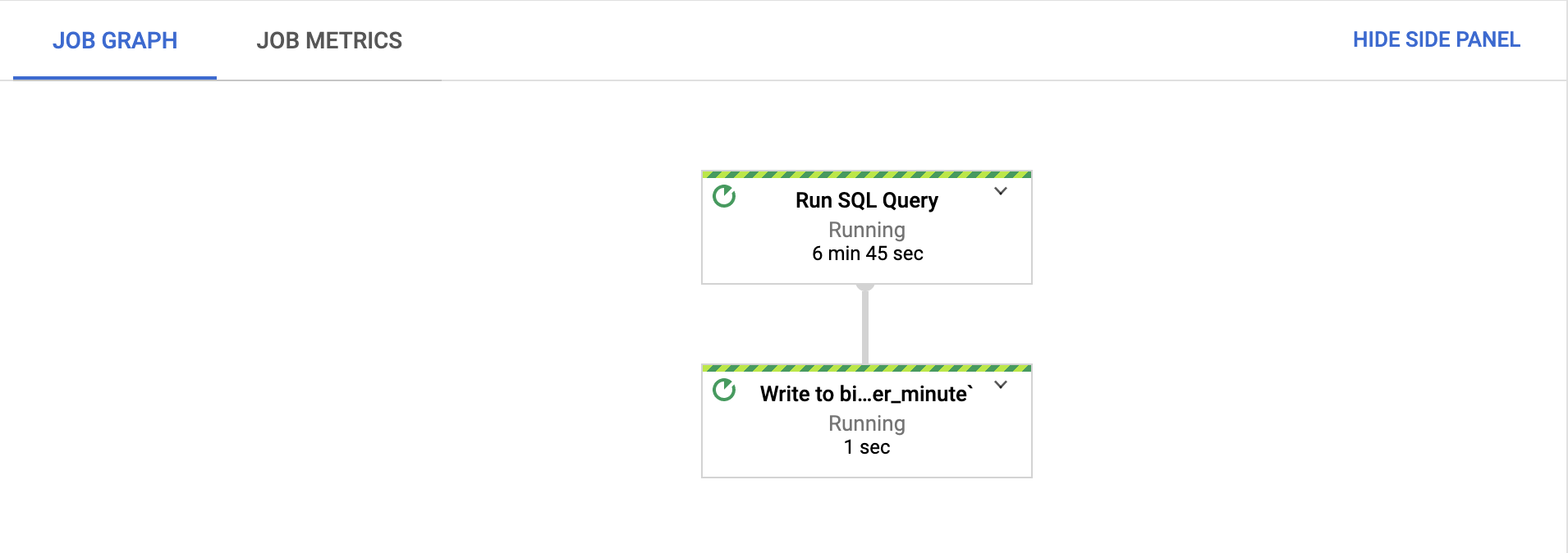
En la pestaña Job graph, confirma que cada paso se esté ejecutando.
Después de que se inicia el trabajo, los pasos pueden tardar varios minutos en comenzar a ejecutarse.
En Cloud Console, ve a la página BigQuery.
En el Editor, pega la siguiente consulta de SQL y haz clic en Ejecutar:
'SELECT * FROM taxirides.passengers_per_minute ORDER BY pickup_count DESC LIMIT 5'Esta consulta muestra los intervalos más activos de la tabla
passengers_per_minute.
gcloud
Obtén la lista de los trabajos de Dataflow que se ejecutan en tu proyecto:
gcloud dataflow jobs listObtén más información sobre el trabajo
dataflow-sql-quickstart:gcloud dataflow jobs describe JOB_IDReemplaza
JOB_IDpor el ID del trabajodataflow-sql-quickstartdel proyecto.Muestra los intervalos más activos de la tabla
passengers_per_minute.bq query \ 'SELECT * FROM taxirides.passengers_per_minute ORDER BY pickup_count DESC LIMIT 5'
Limpia
Sigue estos pasos para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos que usaste en esta página.
Para cancelar el trabajo de Dataflow, ve a la página Trabajos.
En la lista de trabajos, haz clic en dataflow-sql-quickstart.
Haz clic en Detener > Cancelar > Detener trabajo.
Borra el conjunto de datos
taxiridesbq rm taxiridesPara confirmar la eliminación, escribe
y.
¿Qué sigue?
- Obtén más información sobre cómo usar Dataflow SQL.
- Lee sobre el uso de fuentes de datos y destinos en consultas de Dataflow SQL.
- Explora la CLI de
gcloudpara Dataflow SQL.