SQL を使用して Dataflow パイプラインを作成する
このクイックスタートでは、一般公開されている Pub/Sub トピックに対してクエリを実行する SQL 構文を記述する方法を学びます。SQL クエリが Dataflow パイプラインを実行し、そのパイプラインの結果が BigQuery テーブルに書き込まれます。
Dataflow SQL ジョブを実行するには、Google Cloud コンソール、ローカルマシンにインストールされた Google Cloud CLI、または Cloud Shell を使用します。この例では、Google Cloud コンソールに加えて、ローカルマシンまたは Cloud Shell のいずれかを使用する必要があります。
始める前に
- Google Cloud アカウントにログインします。Google Cloud を初めて使用する場合は、アカウントを作成して、実際のシナリオでの Google プロダクトのパフォーマンスを評価してください。新規のお客様には、ワークロードの実行、テスト、デプロイができる無料クレジット $300 分を差し上げます。
-
Google Cloud Console の [プロジェクト セレクタ] ページで、Google Cloud プロジェクトを選択または作成します。
-
Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager, and Google Cloud Data Catalog API を有効にします。
-
Google Cloud Console の [プロジェクト セレクタ] ページで、Google Cloud プロジェクトを選択または作成します。
-
Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Resource Manager, and Google Cloud Data Catalog API を有効にします。
gcloud CLI をインストールして初期化する
ご使用のオペレーティング システム用の gcloud CLI パッケージをダウンロードし、gcloud CLI をインストールして構成します。
ご使用のインターネット接続によっては、ダウンロードに時間がかかることがあります。
BigQuery データセットを作成する
このクイックスタートでは、Dataflow SQL パイプラインが BigQuery データセットを次のセクションで作成する BigQuery テーブルに公開します。
taxiridesという名前の BigQuery データセットを作成します。bq mk taxirides
パイプラインの実行
タクシー乗車に関する一般公開された Pub/Sub トピックのデータを使用して、1 分ごとの乗客数を計算する Dataflow SQL パイプラインを実行します。このコマンドは、データ出力を保存する
passengers_per_minuteという名前の BigQuery テーブルも作成します。gcloud dataflow sql query \ --job-name=dataflow-sql-quickstart \ --region=us-central1 \ --bigquery-dataset=taxirides \ --bigquery-table=passengers_per_minute \ 'SELECT TUMBLE_START("INTERVAL 60 SECOND") as period_start, SUM(passenger_count) AS pickup_count, FROM pubsub.topic.`pubsub-public-data`.`taxirides-realtime` WHERE ride_status = "pickup" GROUP BY TUMBLE(event_timestamp, "INTERVAL 60 SECOND")'Dataflow SQL ジョブの実行が開始されるまでに少し時間がかかることがあります。
以下は、Dataflow SQL パイプラインで使用される値に関する説明です。
dataflow-sql-quickstart: Dataflow ジョブの名前us-central1: ジョブを実行するリージョンtaxirides: シンクとして使用される BigQuery データセットの名前passengers_per_minute: BigQuery テーブルの名前taxirides-realtime: ソースとして使用される Pub/Sub トピックの名前
この SQL コマンドは、Pub/Sub トピック taxirides-realtime に対してクエリを実行し、60 秒ごとの乗客数を取得します。この一般公開トピックは、NYC Taxi & Limousine Commission のオープン データセットをベースとしています。
結果を見る
パイプラインが実行中であることを確認します。
コンソール
Google Cloud コンソールで、Dataflow の [ジョブ] ページに移動します。
ジョブのリストで、[dataflow-sql-quickstart] をクリックします。
[ジョブ情報] パネルで、[ジョブのステータス] 項目が [実行中] に設定されていることを確認します。
ジョブが開始するまでに数分かかることがあります。ジョブが開始されるまで、[ジョブ ステータス] は [キューに格納済み] に設定されています。
[ジョブグラフ] タブで、すべてのステップが実行されていることを確認します。
ジョブの開始後、ステップの実行が開始されるまでに数分かかる場合があります。
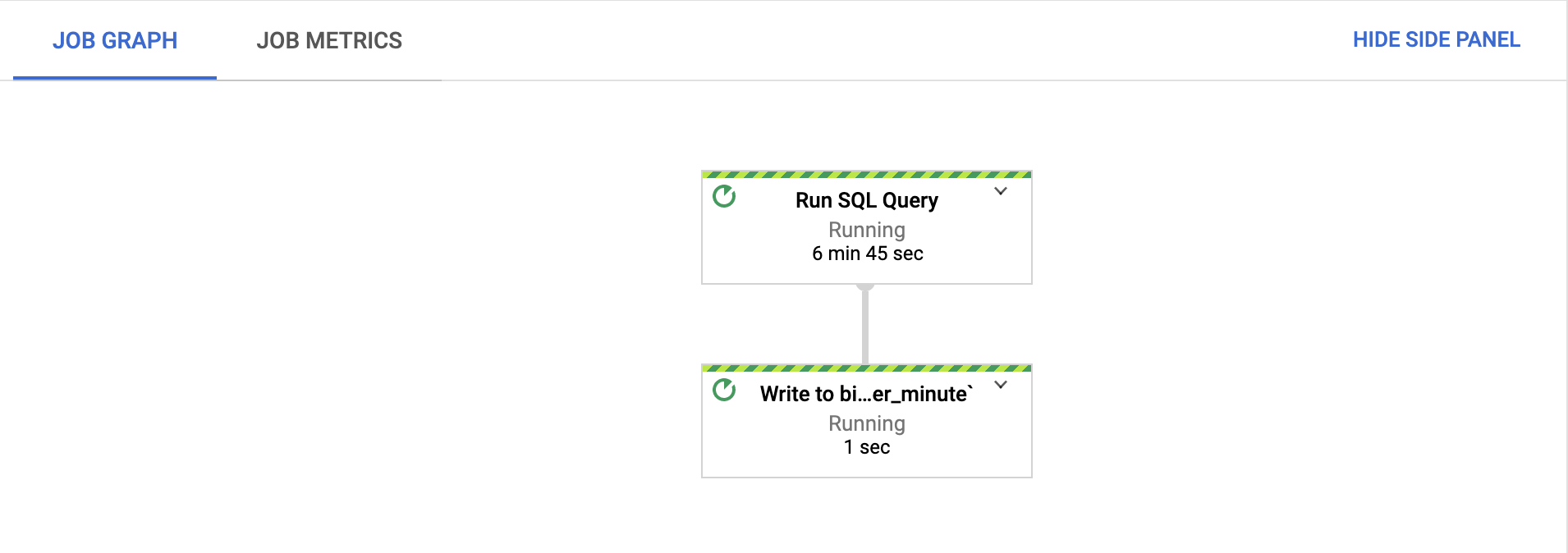
Google Cloud コンソールで [BigQuery] ページに移動します。
エディタで、次の SQL クエリを貼り付けて、[実行] をクリックします。
'SELECT * FROM taxirides.passengers_per_minute ORDER BY pickup_count DESC LIMIT 5'このクエリは、
passengers_per_minuteテーブルから最も混雑した時間帯を返します。
gcloud
プロジェクトで実行されている Dataflow ジョブのリストを取得します。
gcloud dataflow jobs listdataflow-sql-quickstartジョブの詳細を取得します。gcloud dataflow jobs describe JOB_IDJOB_IDを、プロジェクトのdataflow-sql-quickstartジョブのジョブ ID に置き換えます。passengers_per_minuteテーブルから最も混雑した時間帯を返します。bq query \ 'SELECT * FROM taxirides.passengers_per_minute ORDER BY pickup_count DESC LIMIT 5'
クリーンアップ
このページで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、次の操作を行います。
Dataflow ジョブをキャンセルするには、[ジョブ] ページに移動します。
ジョブのリストで、[dataflow-sql-quickstart] をクリックします。
[停止] > [キャンセル] > [ジョブの停止] をクリックします。
taxiridesデータセットを削除します。bq rm taxirides削除を確認するには、「
y」と入力します。
次のステップ
- Dataflow SQL の使用について学習する。
- Dataflow SQL の gcloud CLI について調べる。