Os snapshots do Dataflow salvam o estado de um pipeline de streaming, o que permite iniciar uma nova versão do job do Dataflow sem perder o estado. Os snapshots são úteis para backup e recuperação, testes e reversão de atualizações para pipelines de streaming, bem como outros cenários semelhantes.
É possível criar um snapshot do Dataflow usando qualquer job de streaming em execução. Observe que qualquer novo job criado a partir de um snapshot usa o Streaming Engine. Também é possível usar um snapshot do Dataflow para migrar seu pipeline atual para o Streaming Engine mais eficiente e escalonável, com o mínimo de tempo de inatividade.
Este guia explica como criar snapshots, gerenciar snapshots e criar jobs a partir de snapshots.
Antes de começar
- Faça login na sua conta do Google Cloud. Se você começou a usar o Google Cloud agora, crie uma conta para avaliar o desempenho de nossos produtos em situações reais. Clientes novos também recebem US$ 300 em créditos para executar, testar e implantar cargas de trabalho.
-
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud.
-
Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
-
Ative as APIs Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Datastore e Cloud Resource Manager.
-
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud.
-
Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
-
Ative as APIs Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Datastore e Cloud Resource Manager.
Criar um snapshot
Console
- No Console do Google Cloud, acesse a página
Jobs do Dataflow.
Uma lista de jobs do Dataflow é exibida junto com o status deles. Se você não vir nenhum job de streaming, precisará executar um novo. Para ver um exemplo de um job de streaming, consulte o Guia de início rápido sobre como usar modelos.
- Selecione um job.
- Na barra de menu da página Detalhes do job, clique em Criar snapshot.
- Na caixa de diálogo Criar um snapshot, selecione uma das seguintes
opções:
- Sem origens de dados: selecione essa opção para criar um snapshot somente do estado do job do Dataflow.
- Com origens de dados: selecione essa opção para criar um snapshot do estado do job do Dataflow junto com um snapshot da origem do Pub/Sub.
- Clique em Criar.
gcloud
Criar um snapshot:
gcloud dataflow snapshots create \
--job-id=JOB_ID \
--snapshot-ttl=DURATION \
--snapshot-sources=true \
--region=REGION
Substitua:
JOB_ID: o ID do job de streamingDURATION: o período (em dias) antes de o snapshot expirar. Depois disso, não é possível criar mais jobs a partir do snapshot. A sinalizaçãosnapshot-ttlé opcional. Portanto, se não for especificada, o snapshot expira em sete dias. Especifique o valor no seguinte formato:5d. A duração máxima que pode ser especificada é de 30 dias (30d).REGION: a região em que o job está em execução.
A sinalização snapshot-sources especifica se o snapshot das
origens do Pub/Sub será capturado junto com o snapshot
do Dataflow. Se for true, as origens do Pub/Sub serão
coletadas automaticamente e os IDs de snapshots do Pub/Sub serão
mostrados na resposta de saída. Depois de executar o comando
create
, verifique o status do snapshot executando o comando
list
ou o
describe
.
Os itens a seguir se aplicam ao criar snapshots do Dataflow:
- Os snapshots do Dataflow estão sujeitos a uma cobrança do uso do disco.
- Os snapshots são criados na mesma região do job.
- Se o local do worker for diferente da região do job, a criação do snapshot falhará. Consulte o guia Regiões do Dataflow.
- Só é possível tirar snapshots dos jobs que não são do Streaming Engine se tiverem sido iniciados ou atualizados após 1º de fevereiro de 2021.
- Os snapshots do Pub/Sub criados com snapshots do Dataflow são gerenciados pelo serviço do Pub/Sub e estão sujeitos a cobrança.
- Um snapshot do Pub/Sub expira em até sete dias a partir do momento
da criação. A vida útil exata é determinada na criação pelo backlog
existente na assinatura de origem. Especificamente, o ciclo de vida do snapshot do
Pub/Sub é
7 days - (age of oldest unacked message in the subscription). Por exemplo, pense em uma assinatura em que a mensagem descompactada mais antiga tem três dias de idade. Se um snapshot do Pub/Sub for criado com base nessa assinatura, o snapshot, que sempre captura esse backlog de três dias enquanto o snapshot existir, expirará em 4 dias. Consulte a Referência de snapshots do Pub/Sub. - Durante a operação de snapshot, o job do Dataflow é pausado e retomado depois que o snapshot está pronto. O tempo necessário depende do tamanho do estado do pipeline. Por exemplo, o tempo necessário para tirar snapshots em jobs do Streaming Engine geralmente é menor do que jobs que não são do Streaming Engine.
- É possível cancelar o job enquanto um snapshot está em andamento.
- Não é possível atualizar ou drenar o job enquanto um snapshot está em andamento. Aguarde até que o job seja retomado do processo de snapshot antes de atualizar ou drenar o job.
Usar a página de snapshots
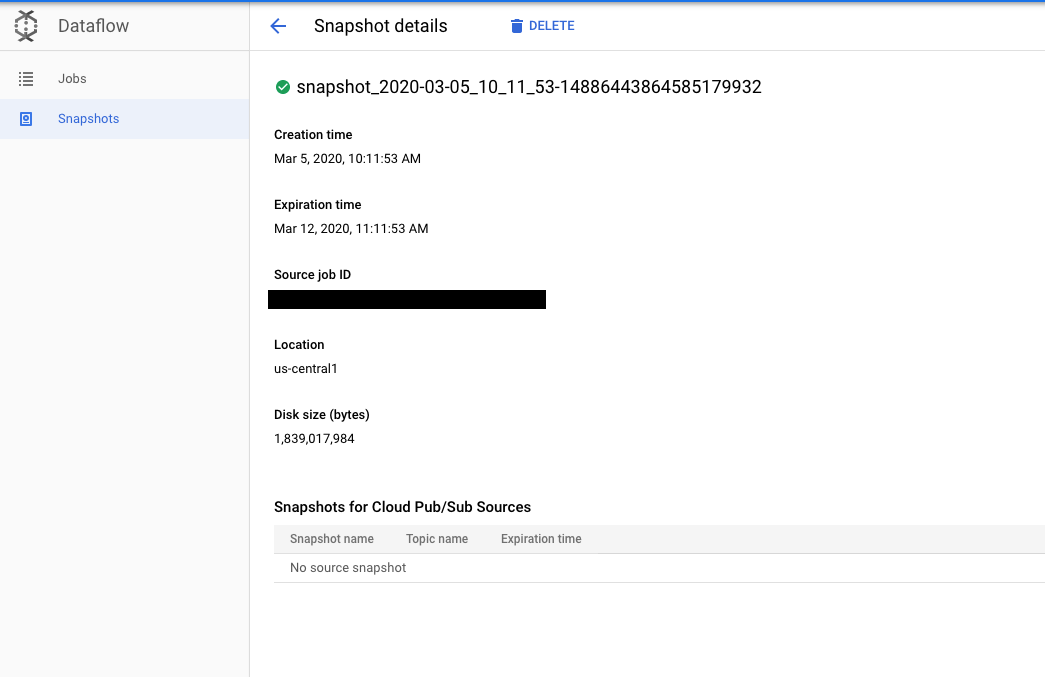
Depois de criar um snapshot, é possível usar a página Snapshots no Console do Google Cloud para ver e gerenciar os snapshots do projeto.
Clique em um snapshot abre a página Detalhes do snapshot. É possível visualizar metadados adicionais sobre o snapshot, um link para o job de origem e outros snapshots do Pub/Sub.
Excluir um snapshot
A exclusão de um snapshot é uma forma de interromper o processo de snapshot e retomar o job. Além disso, excluir os snapshots do Dataflow não excluem automaticamente os snapshots associados do Pub/Sub.
Console
- No Console do Google Cloud, acesse a página Snapshots do Dataflow.
- Selecione o snapshot e clique em Excluir.
- Na caixa de diálogo Excluir snapshot, clique em Excluir para confirmar.
gcloud
Excluir um snapshot:
gcloud dataflow snapshots delete SNAPSHOT_ID \
--region=REGION
Substitua:
SNAPSHOT_ID: o ID do snapshotREGION: a região em que o snapshot existe
Para mais informações, consulte a
referência do comando
delete.
Criar um job de um snapshot
Depois de criar um snapshot, você pode restaurar o estado do job do Dataflow criando um novo job a partir desse snapshot.
Java
Para criar um novo job a partir de um snapshot, use as
sinalizações
--createFromSnapshot e --enableStreamingEngine.
- No shell ou no terminal, crie um novo job a partir de um snapshot. Por exemplo:
mvn -Pdataflow-runner compile exec:java \ -Dexec.mainClass=MAIN_CLASS \ -Dexec.args="--project=PROJECT_ID \ --stagingLocation=gs://STORAGE_BUCKET/staging/ \ --inputFile=gs://apache-beam-samples/shakespeare/* \ --output=gs://STORAGE_BUCKET/output \ --runner=DataflowRunner \ --enableStreamingEngine \ --createFromSnapshot=SNAPSHOT_ID \ --region=REGION"Substitua:
MAIN_CLASSouMODULE: para pipelines Java, o local da classe principal que contém o código do pipeline. Para pipelines em Python, o local do módulo que contém o código do pipeline. Por exemplo, ao usar o exemplo do Wordcount, o valor éorg.apache.beam.examples.WordCount.PROJECT_ID: o ID do projeto do Google CloudSTORAGE_BUCKET: o bucket do Cloud Storage que você usa para recursos de job temporários e a saída finalSNAPSHOT_ID: o ID do snapshot do qual você quer criar um novo job.REGION: o local em que você quer executar o novo job do Dataflow.
Python
Os snapshots do Dataflow exigem o SDK do Apache Beam para Python, versão 2.29.0 ou posterior.
Para criar um novo job a partir de um snapshot, use as
sinalizações
--createFromSnapshot e --enableStreamingEngine.
- No shell ou no terminal, crie um novo job a partir de um snapshot. Exemplo:
python -m MODULE \ --project PROJECT_ID \ --temp_location gs://STORAGE_BUCKET/tmp/ \ --input gs://apache-beam-samples/shakespeare/* \ --output gs://STORAGE_BUCKET/output \ --runner DataflowRunner \ --enable_streaming_engine \ --create_from_snapshot=SNAPSHOT_ID \ --region REGION \ --streamingSubstitua:
MAIN_CLASSouMODULE: para pipelines Java, o local da classe principal que contém o código do pipeline. Para pipelines em Python, o local do módulo que contém o código do pipeline. Por exemplo, ao usar o exemplo do Wordcount, o valor éorg.apache.beam.examples.WordCount.PROJECT_ID: o ID do projeto do Google CloudSTORAGE_BUCKET: o bucket do Cloud Storage que você usa para recursos de job temporários e a saída finalSNAPSHOT_ID: o ID do snapshot do qual você quer criar um novo job.REGION: o local em que você quer executar o novo job do Dataflow.
Os itens a seguir se aplicam ao criar jobs a partir de snapshots do Dataflow:
- Os jobs criados a partir de snapshots precisam ser executados na mesma região em que o snapshot está armazenado.
Se um snapshot do Dataflow incluir snapshots de origens do Pub/Sub, os jobs criados a partir de um snapshot do Dataflow automaticamente
seekesses snapshots como origens. Você precisa especificar os mesmos tópicos do Pub/Sub usados pelo job de origem ao criar jobs a partir desse snapshot do Dataflow.Se um snapshot do Dataflow não incluir snapshots de origens do Pub/Sub e o job de origem usar uma origem do Pub/Sub, especifique um tópico do Pub/Sub ao criar jobs a partir desse snapshot do Dataflow.
Novos jobs criados a partir de um snapshot ainda estão sujeitos a uma verificação de compatibilidade de atualização.
Limitações conhecidas
As seguintes limitações se aplicam aos snapshots do Dataflow:
- Não é possível criar jobs a partir de snapshots usando modelos ou o editor do SQL do Dataflow.
- O prazo de validade do snapshot só pode ser definido pela CLI do Google Cloud.
- Os snapshots do Dataflow são compatíveis apenas com snapshots de origem do Pub/Sub.
- Os snapshots do coletor não são compatíveis. Por exemplo, não é possível criar um snapshot do BigQuery ao criar um snapshot do Dataflow.
Solução de problemas
Nesta seção, veja instruções para solucionar problemas comuns encontrados ao interagir com snapshots do Dataflow.
Antes de entrar em contato com o suporte, verifique se você descartou todos os problemas relacionados às limitações conhecidas e às seções de solução de problemas abaixo.
A solicitação de criação do snapshot foi rejeitada
Depois que uma solicitação de criação do snapshot é enviada, seja pelo Console do Google Cloud ou pela CLI gcloud, o serviço Dataflow realiza uma verificação de pré-condição e retorna todas as mensagens de erro. A solicitação de criação de snapshot pode ser rejeitada por vários motivos especificados nas mensagens de erro, por exemplo, se um tipo de job não for compatível ou uma região não estiver disponível.
Se a solicitação for rejeitada porque o job é muito antigo, será necessário atualizar o job antes de solicitar um snapshot.
Falha ao criar o snapshot
A criação de snapshots pode falhar por vários motivos. Por exemplo, o job de origem foi cancelado ou o projeto não tem as permissões corretas para criar snapshots do Pub/Sub. Os registros job-message do job contêm mensagens de erro da criação do snapshot. Se a criação do snapshot falhar, o job de origem será retomado.
Falha ao criar um job com base no snapshot
Ao criar um job a partir de um snapshot, verifique se ele existe e não expirou. O novo job precisa ser executado no Streaming Engine.
Veja problemas comuns de criação de jobs no guia de solução de problemas do Dataflow. Em particular, novos jobs criados a partir de snapshots estão sujeitos a uma verificação de compatibilidade de atualização, em que o novo job precisa ser compatível com o job de origem gerado.
O job criado a partir do snapshot progride pouco
Os registros de jobs-message do job contêm mensagens de erro para a criação do job. Por exemplo, você pode ver que o job não consegue encontrar os snapshots do Pub/Sub. Nesse caso, verifique se os snapshots do Pub/Sub existem e não estão expirados. Os snapshots do Pub/Sub expiram assim que a mensagem mais antiga em um snapshot tiver mais de sete dias. Os snapshots expirados do Pub/Sub podem ser removidos automaticamente pelo serviço do Pub/Sub.
Para jobs criados a partir de snapshots do Dataflow que incluam snapshots de origem do Pub/Sub, o novo job pode ter grandes backlogs do Pub/Sub para processar. O escalonamento automático de streaming pode ajudar o novo job a limpar o backlog com mais rapidez.
O job de origem com snapshot já pode estar em um estado não íntegro antes da captura do snapshot. Entender por que o job de origem não está íntegro pode ajudar a resolver problemas do novo job. Veja dicas comuns sobre a depuração de jobs no guia de solução de problemas do Dataflow.