Questo tutorial mostra come utilizzare Dataflow SQL per unire un flusso di dati di Pub/Sub con i dati di una tabella BigQuery.
Obiettivi
In questo tutorial imparerai a:
- Scrivi una query SQL Dataflow che unisce i flussi di dati Pub/Sub ai dati della tabella BigQuery.
- Esegui il deployment di un job Dataflow dall'interfaccia utente SQL di Dataflow.
Costi
In questo documento vengono utilizzati i seguenti componenti fatturabili di Google Cloud:
- Dataflow
- Cloud Storage
- Pub/Sub
- Data Catalog
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il Calcolatore prezzi.
Prima di iniziare
- Accedi al tuo account Google Cloud. Se non conosci Google Cloud, crea un account per valutare le prestazioni dei nostri prodotti in scenari reali. I nuovi clienti ricevono anche 300 $di crediti gratuiti per l'esecuzione, il test e il deployment dei carichi di lavoro.
-
Nella pagina del selettore di progetti della console Google Cloud, seleziona o crea un progetto Google Cloud.
-
Assicurati che la fatturazione sia attivata per il tuo progetto Google Cloud.
-
Abilita le API Cloud Dataflow, Compute Engine, Logging, Cloud Storage, JSON di Cloud Storage, BigQuery, Cloud Pub/Sub, Cloud Resource Manager e Data Catalog. .
-
Crea un account di servizio:
-
Nella console Google Cloud, vai alla pagina Crea account di servizio.
Vai a Crea account di servizio - Seleziona il progetto.
-
Nel campo Nome account di servizio, inserisci un nome. La console Google Cloud compila il campo ID account di servizio in base a questo nome.
Nel campo Descrizione account di servizio, inserisci una descrizione. Ad esempio,
Service account for quickstart. - Fai clic su Crea e continua.
-
Concedi il ruolo Project > Owner all'account di servizio.
Per concedere il ruolo, trova l'elenco Seleziona un ruolo e scegli Project > Owner.
- Fai clic su Continua.
-
Fai clic su Fine per completare la creazione dell'account di servizio.
Non chiudere la finestra del browser. La utilizzerai nel passaggio successivo.
-
-
Crea una chiave dell'account di servizio:
- Nella console Google Cloud, fai clic sull'indirizzo email dell'account di servizio che hai creato.
- Fai clic su Chiavi.
- Fai clic su Aggiungi chiave, quindi su Crea nuova chiave.
- Fai clic su Crea. Un file della chiave JSON viene scaricato sul computer.
- Fai clic su Chiudi.
-
Imposta la variabile di ambiente
GOOGLE_APPLICATION_CREDENTIALSsul percorso del file JSON che contiene le tue credenziali. Questa variabile si applica solo alla sessione di shell attuale. Pertanto, se apri una nuova sessione, imposta di nuovo la variabile. -
Nella pagina del selettore di progetti della console Google Cloud, seleziona o crea un progetto Google Cloud.
-
Assicurati che la fatturazione sia attivata per il tuo progetto Google Cloud.
-
Abilita le API Cloud Dataflow, Compute Engine, Logging, Cloud Storage, JSON di Cloud Storage, BigQuery, Cloud Pub/Sub, Cloud Resource Manager e Data Catalog. .
-
Crea un account di servizio:
-
Nella console Google Cloud, vai alla pagina Crea account di servizio.
Vai a Crea account di servizio - Seleziona il progetto.
-
Nel campo Nome account di servizio, inserisci un nome. La console Google Cloud compila il campo ID account di servizio in base a questo nome.
Nel campo Descrizione account di servizio, inserisci una descrizione. Ad esempio,
Service account for quickstart. - Fai clic su Crea e continua.
-
Concedi il ruolo Project > Owner all'account di servizio.
Per concedere il ruolo, trova l'elenco Seleziona un ruolo e scegli Project > Owner.
- Fai clic su Continua.
-
Fai clic su Fine per completare la creazione dell'account di servizio.
Non chiudere la finestra del browser. La utilizzerai nel passaggio successivo.
-
-
Crea una chiave dell'account di servizio:
- Nella console Google Cloud, fai clic sull'indirizzo email dell'account di servizio che hai creato.
- Fai clic su Chiavi.
- Fai clic su Aggiungi chiave, quindi su Crea nuova chiave.
- Fai clic su Crea. Un file della chiave JSON viene scaricato sul computer.
- Fai clic su Chiudi.
-
Imposta la variabile di ambiente
GOOGLE_APPLICATION_CREDENTIALSsul percorso del file JSON che contiene le tue credenziali. Questa variabile si applica solo alla sessione di shell attuale. Pertanto, se apri una nuova sessione, imposta di nuovo la variabile. - Installa e inizializza gcloud CLI. Scegli una delle opzioni di installazione.
Potrebbe essere necessario impostare la proprietà
projectsul progetto che utilizzi per questa procedura dettagliata. - Vai all'interfaccia utente web di Dataflow SQL nella console Google Cloud. Viene aperto il progetto a cui hai eseguito l'accesso più di recente. Per passare a un altro progetto, fai clic sul nome del progetto nella parte superiore dell'interfaccia utente web di Dataflow SQL e cerca il progetto che vuoi utilizzare.
Vai all'interfaccia utente web di Dataflow SQL
Crea origini di esempio
Se vuoi seguire l'esempio fornito in questo tutorial, crea le seguenti origini e utilizzale nei passaggi del tutorial.
- Un argomento Pub/Sub denominato
transactions: un flusso di dati sulle transazioni che arriva tramite una sottoscrizione all'argomento Pub/Sub. I dati di ogni transazione includono informazioni quali il prodotto acquistato, il prezzo scontato e la città e la provincia in cui è avvenuto l'acquisto. Dopo aver creato l'argomento Pub/Sub, crei uno script che pubblica messaggi nell'argomento. Eseguirai questo script in una sezione successiva di questo tutorial. - Una tabella BigQuery denominata
us_state_salesregions: una tabella che fornisce una mappatura degli stati alle regioni di vendita. Prima di creare questa tabella, devi creare un set di dati BigQuery.
crea un set di dati e una tabella BigQuery
- Nella UI web di BigQuery, crea un set di dati BigQuery. Un set di dati BigQuery è un container di primo livello utilizzato per contenere le tabelle. Le tabelle BigQuery devono appartenere a un set di dati.
- Nel riquadro Explorer, apri le azioni relative al tuo progetto. Nel menu, fai clic su Crea set di dati. Nello screenshot seguente, l'ID progetto è
dataflow-sql.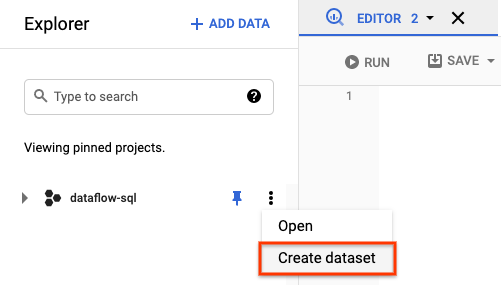
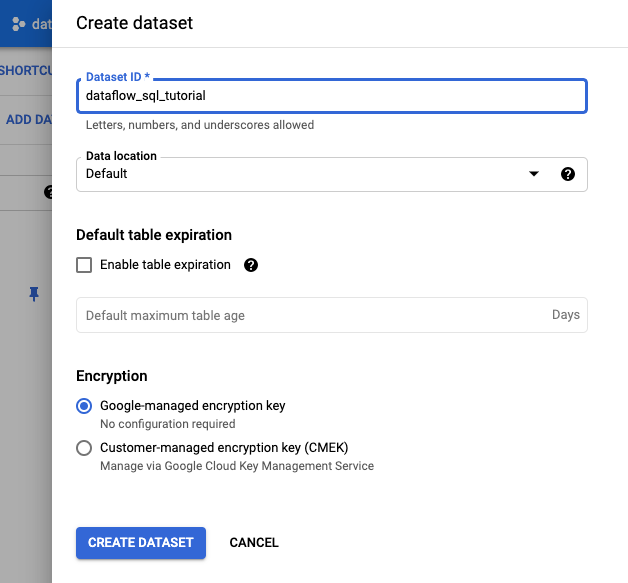
- Nel riquadro Crea set di dati che si apre, inserisci
dataflow_sql_tutorialin corrispondenza di ID set di dati. - Per Località dei dati, seleziona un'opzione dal menu.
- Fai clic su Crea set di dati.
- Nel riquadro Explorer, apri le azioni relative al tuo progetto. Nel menu, fai clic su Crea set di dati. Nello screenshot seguente, l'ID progetto è
- Crea una tabella BigQuery.
- Crea un file di testo e assegnagli il nome
us_state_salesregions.csv. - Copia e incolla i seguenti dati in
us_state_salesregions.csv. Nei passaggi successivi caricherai questi dati nella tabella BigQuery.state_id,state_code,state_name,sales_region 1,MO,Missouri,Region_1 2,SC,South Carolina,Region_1 3,IN,Indiana,Region_1 6,DE,Delaware,Region_2 15,VT,Vermont,Region_2 16,DC,District of Columbia,Region_2 19,CT,Connecticut,Region_2 20,ME,Maine,Region_2 35,PA,Pennsylvania,Region_2 38,NJ,New Jersey,Region_2 47,MA,Massachusetts,Region_2 54,RI,Rhode Island,Region_2 55,NY,New York,Region_2 60,MD,Maryland,Region_2 66,NH,New Hampshire,Region_2 4,CA,California,Region_3 8,AK,Alaska,Region_3 37,WA,Washington,Region_3 61,OR,Oregon,Region_3 33,HI,Hawaii,Region_4 59,AS,American Samoa,Region_4 65,GU,Guam,Region_4 5,IA,Iowa,Region_5 32,NV,Nevada,Region_5 11,PR,Puerto Rico,Region_6 17,CO,Colorado,Region_6 18,MS,Mississippi,Region_6 41,AL,Alabama,Region_6 42,AR,Arkansas,Region_6 43,FL,Florida,Region_6 44,NM,New Mexico,Region_6 46,GA,Georgia,Region_6 48,KS,Kansas,Region_6 52,AZ,Arizona,Region_6 56,TN,Tennessee,Region_6 58,TX,Texas,Region_6 63,LA,Louisiana,Region_6 7,ID,Idaho,Region_7 12,IL,Illinois,Region_7 13,ND,North Dakota,Region_7 31,MN,Minnesota,Region_7 34,MT,Montana,Region_7 36,SD,South Dakota,Region_7 50,MI,Michigan,Region_7 51,UT,Utah,Region_7 64,WY,Wyoming,Region_7 9,NE,Nebraska,Region_8 10,VA,Virginia,Region_8 14,OK,Oklahoma,Region_8 39,NC,North Carolina,Region_8 40,WV,West Virginia,Region_8 45,KY,Kentucky,Region_8 53,WI,Wisconsin,Region_8 57,OH,Ohio,Region_8 49,VI,United States Virgin Islands,Region_9 62,MP,Commonwealth of the Northern Mariana Islands,Region_9
- Nel riquadro Explorer dell'interfaccia utente di BigQuery, espandi il progetto per visualizzare il set di dati
dataflow_sql_tutorial. - Apri il menu Azioni per il set di dati
dataflow_sql_tutoriale fai clic su Apri. - Fai clic su Crea tabella.
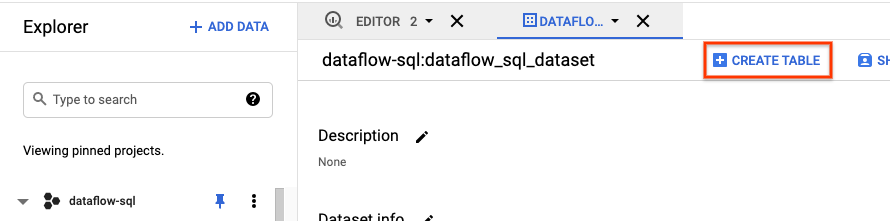
- Nel riquadro Crea tabella che viene visualizzato:
- Per Crea tabella da, seleziona Carica.

- In Seleziona file, fai clic su Sfoglia e scegli il
file
us_state_salesregions.csv. - In Tabella, inserisci
us_state_salesregions. - In Schema, seleziona Rilevamento automatico.
- Fai clic su Opzioni avanzate per espandere la sezione Opzioni avanzate.
- In Righe di intestazione da ignorare, inserisci
1e fai clic su Crea tabella.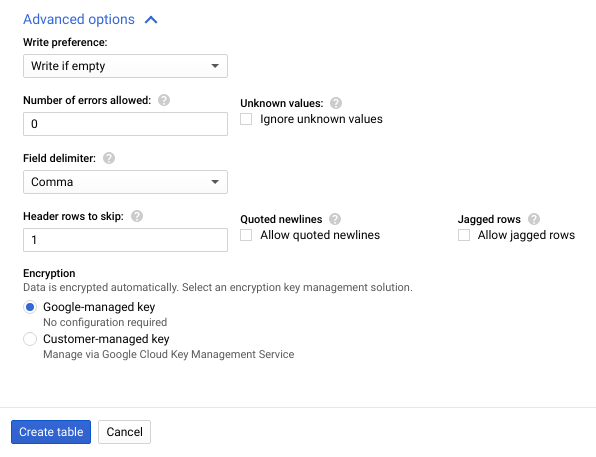
- Per Crea tabella da, seleziona Carica.
- Nel riquadro Explorer, fai clic su
us_state_salesregions. In Schema, puoi visualizzare lo schema generato automaticamente. In Anteprima puoi visualizzare i dati della tabella.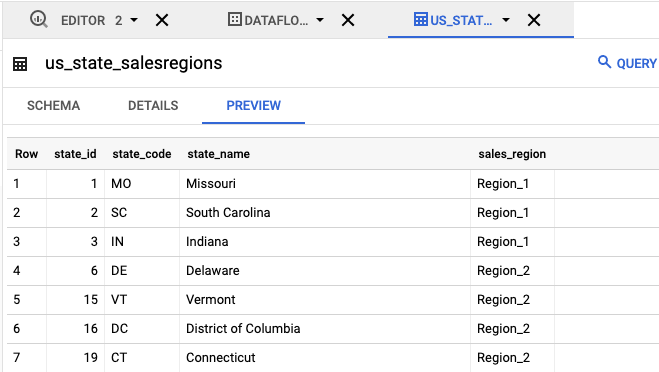
- Crea un file di testo e assegnagli il nome
Assegna uno schema all'argomento Pub/Sub
L'assegnazione di uno schema ti consente di eseguire query SQL sui dati dell'argomento Pub/Sub. Attualmente, Dataflow SQL prevede che i messaggi in argomenti Pub/Sub siano serializzati in formato JSON.
Per assegnare uno schema all'argomento Pub/Sub di esempio transactions:
Crea un file di testo e assegnagli il nome
transactions_schema.yaml. Copia e incolla il seguente testo dello schema intransactions_schema.yaml.- column: event_timestamp description: Pub/Sub event timestamp mode: REQUIRED type: TIMESTAMP - column: tr_time_str description: Transaction time string mode: NULLABLE type: STRING - column: first_name description: First name mode: NULLABLE type: STRING - column: last_name description: Last name mode: NULLABLE type: STRING - column: city description: City mode: NULLABLE type: STRING - column: state description: State mode: NULLABLE type: STRING - column: product description: Product mode: NULLABLE type: STRING - column: amount description: Amount of transaction mode: NULLABLE type: FLOATAssegna lo schema utilizzando Google Cloud CLI.
a. Aggiorna gcloud CLI con il comando seguente. Assicurati che la versione gcloud CLI sia 242.0.0 o successiva.
gcloud components update
b. Esegui il seguente comando in una finestra della riga di comando. Sostituisci project-id con l'ID progetto e path-to-file con il percorso del file
transactions_schema.yaml.gcloud data-catalog entries update \ --lookup-entry='pubsub.topic.`project-id`.transactions' \ --schema-from-file=path-to-file/transactions_schema.yamlPer saperne di più sui parametri del comando e sui formati consentiti dei file di schema, consulta la pagina della documentazione per l'aggiornamento delle voci gcloud data-catalog.
c. Verifica che lo schema sia stato assegnato correttamente all'argomento
transactionsPub/Sub. Sostituisci project-id con l'ID progetto.gcloud data-catalog entries lookup 'pubsub.topic.`project-id`.transactions'
Trova origini Pub/Sub
La UI SQL di Dataflow consente di trovare gli oggetti delle origini dati Pub/Sub per qualsiasi progetto a cui hai accesso, in modo da non dover ricordare i loro nomi completi.
Per l'esempio di questo tutorial, vai all'editor SQL di Dataflow e cerca l'argomento transactions Pub/Sub che hai creato:
Vai all'area di lavoro SQL.
Nel riquadro Editor SQL di Dataflow, cerca
projectid=project-id transactionsnella barra di ricerca. Sostituisci project-id con l'ID progetto.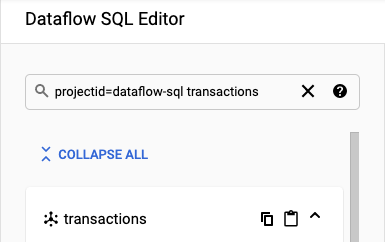
Visualizza lo schema
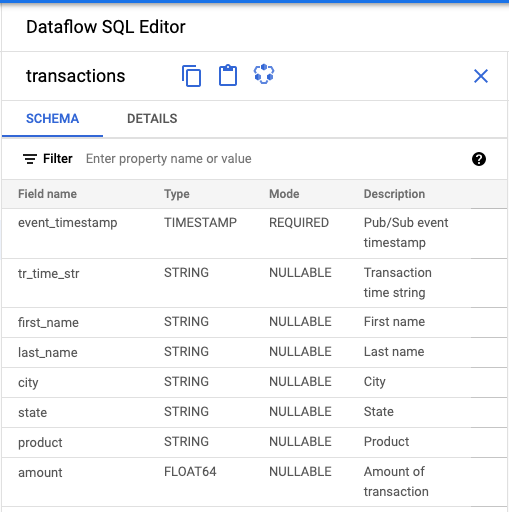
- Nel riquadro Editor SQL Dataflow dell'interfaccia utente di Dataflow SQL, fai clic su Transazioni o cerca un argomento Pub/Sub digitando
projectid=project-id system=cloud_pubsube seleziona l'argomento. In Schema, puoi visualizzare lo schema assegnato all'argomento Pub/Sub.
crea una query SQL
L'interfaccia utente SQL di Dataflow consente di creare query SQL per eseguire i job Dataflow.
La seguente query SQL è una query di arricchimento dei dati. Aggiunge un ulteriore campo,
sales_region, al flusso di eventi Pub/Sub (transactions),
utilizzando una tabella BigQuery (us_state_salesregions) che mappa gli stati
alle regioni di vendita.
Copia e incolla la seguente query SQL nell'Editor query. Sostituisci project-id con l'ID progetto.
SELECT tr.*, sr.sales_region FROM pubsub.topic.`project-id`.transactions as tr INNER JOIN bigquery.table.`project-id`.dataflow_sql_tutorial.us_state_salesregions AS sr ON tr.state = sr.state_code
Quando inserisci una query nell'interfaccia utente SQL di Dataflow, lo validator delle query verifica la sintassi delle query. Se la query è valida, viene visualizzato un segno di spunta verde. Se la query non è valida, viene visualizzata un'icona a forma di punto esclamativo rosso. Se la sintassi della query non è valida, fai clic sull'icona dello validator per ottenere informazioni sulle operazioni da correggere.
Il seguente screenshot mostra la query valida nell'Editor query. Lo strumento di convalida mostra un segno di spunta verde.

Crea un job Dataflow per eseguire la query SQL
Per eseguire la query SQL, crea un job Dataflow dall'interfaccia utente SQL di Dataflow.
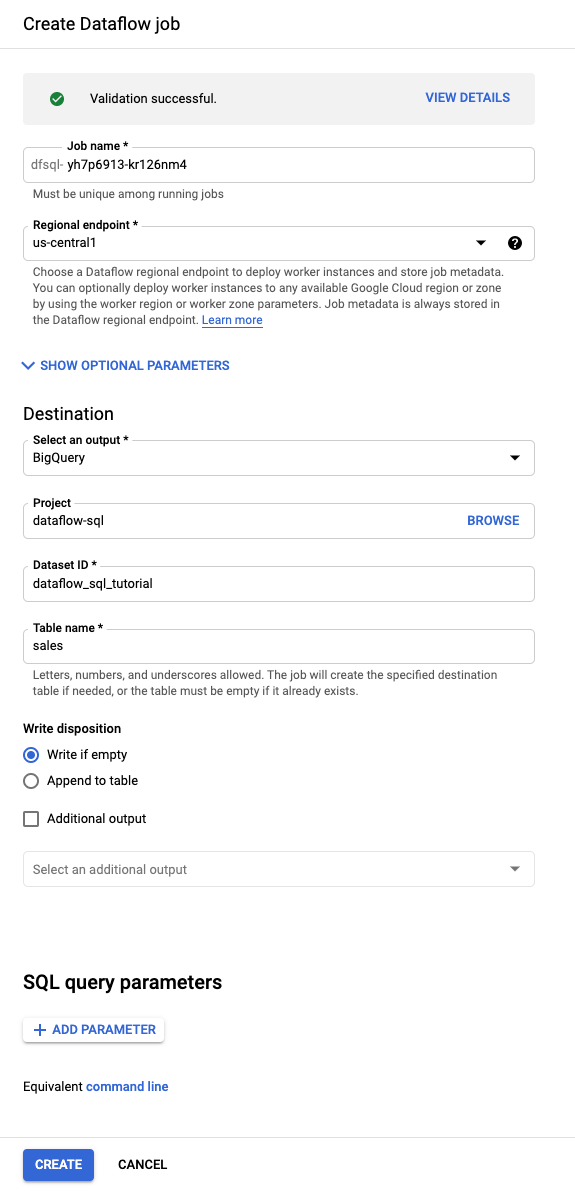
Nell'Editor query, fai clic su Crea job.
Nel riquadro Crea job Dataflow che si apre:
- In corrispondenza di Destinazione, seleziona BigQuery.
- In ID set di dati, seleziona
dataflow_sql_tutorial. - In Nome tabella, inserisci
sales.
(Facoltativo) Dataflow sceglie automaticamente le impostazioni ottimali per il job SQL di Dataflow, ma puoi espandere il menu Parametri facoltativi per specificare manualmente le seguenti opzioni della pipeline:
- Numero massimo di worker
- Zona
- Email dell'account di servizio
- Tipo di macchina
- Esperimenti aggiuntivi
- Configurazione degli indirizzi IP del worker
- Rete
- Subnet
Fai clic su Crea. L'esecuzione del job Dataflow richiede alcuni minuti.
Visualizza il job di Dataflow
Dataflow trasforma la tua query SQL in una pipeline Apache Beam. Fai clic su Visualizza job per aprire l'interfaccia utente web di Dataflow, dove puoi vedere una rappresentazione grafica della pipeline.
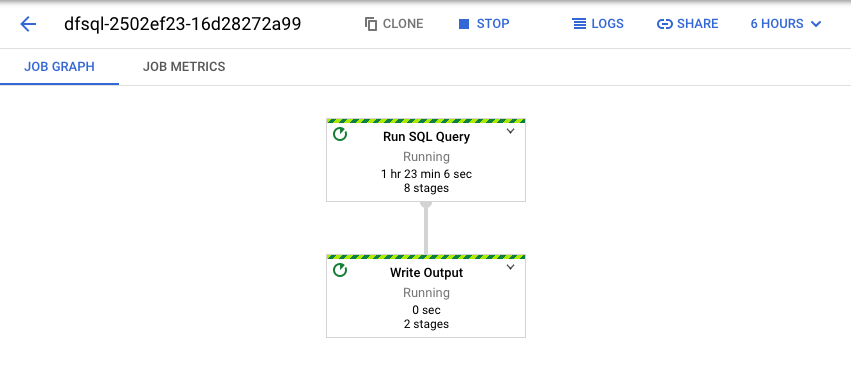
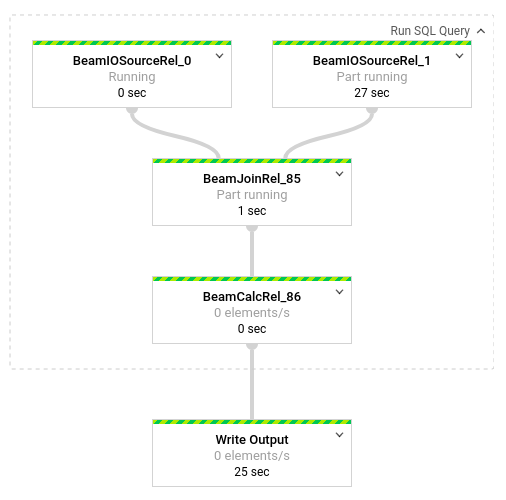
Per un'analisi delle trasformazioni avvenute nella pipeline, fai clic sulle caselle. Ad esempio, se fai clic sulla prima casella nella rappresentazione grafica, denominata Esegui query SQL, viene visualizzato un grafico che mostra le operazioni che avvengono dietro le quinte.
Le prime due caselle rappresentano i due input che hai unito: l'argomento Pub/Sub, transactions, e la tabella BigQuery, us_state_salesregions.
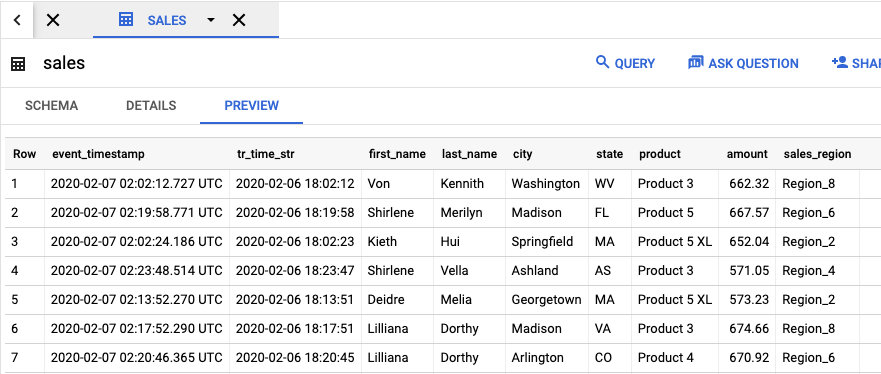
Per visualizzare la tabella di output contenente i risultati del job, vai alla UI di BigQuery.
Nel riquadro Explorer, nel progetto, fai clic sul set di dati dataflow_sql_tutorial che hai creato. Poi, fai clic sulla tabella di output sales. La scheda Anteprima mostra i contenuti della tabella di output.
Visualizza job passati e modifica le query
L'interfaccia utente di Dataflow archivia i job e le query precedenti nella pagina Job di Dataflow.
Puoi utilizzare l'elenco della cronologia dei job per visualizzare le query SQL precedenti. Ad esempio, vuoi modificare la query per aggregare le vendite per regione di vendita ogni 15 secondi. Utilizza la pagina Job per accedere al job in esecuzione avviato in precedenza nel tutorial, copiare la query SQL ed eseguire un altro job con una query modificata.
Nella pagina Job di Dataflow, fai clic sul job da modificare.
Nella pagina Dettagli job, nel riquadro Informazioni job, in Opzioni della pipeline, individua la query SQL. Trova la riga per queryString.
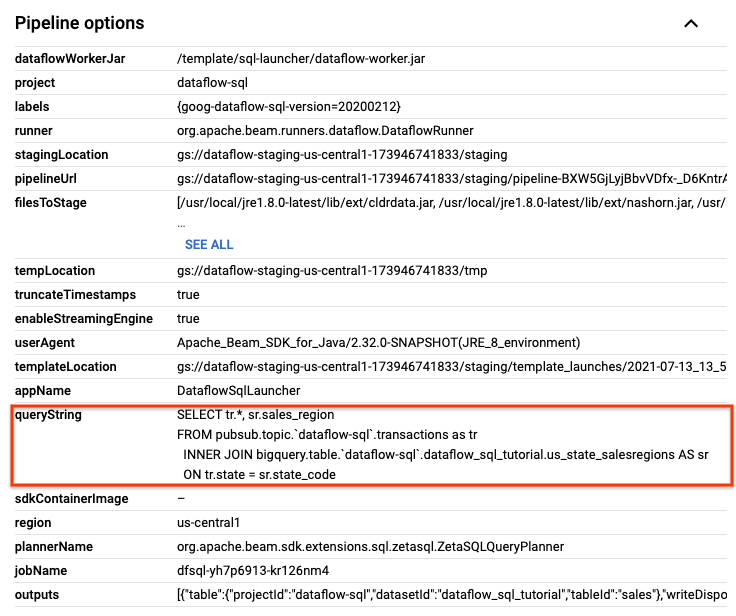
Copia e incolla la seguente query SQL nell'editor SQL di Dataflow nell'area di lavoro SQL per aggiungere finestre cadenti. Sostituisci project-id con l'ID progetto.
SELECT sr.sales_region, TUMBLE_START("INTERVAL 15 SECOND") AS period_start, SUM(tr.amount) as amount FROM pubsub.topic.`project-id`.transactions AS tr INNER JOIN bigquery.table.`project-id`.dataflow_sql_tutorial.us_state_salesregions AS sr ON tr.state = sr.state_code GROUP BY sr.sales_region, TUMBLE(tr.event_timestamp, "INTERVAL 15 SECOND")Fai clic su Crea job per creare un nuovo job con la query modificata.
Esegui la pulizia
Per evitare che al tuo account di fatturazione Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial:
Interrompi lo script di pubblicazione
transactions_injector.pyse è ancora in esecuzione.Arresta i job Dataflow in esecuzione. Vai all'interfaccia utente web di Dataflow nella console Google Cloud.
Vai all'interfaccia utente web di Dataflow
Per ogni job creato dopo questa procedura dettagliata, esegui questi passaggi:
Fai clic sul nome del job.
Nella pagina Dettagli job, fai clic su Arresta. Viene visualizzata la finestra di dialogo Arresta job con le opzioni su come arrestare il job.
Seleziona Annulla.
Fai clic su Interrompi job. Il servizio interrompe l'importazione e l'elaborazione dei dati il prima possibile. Poiché Annulla interrompe immediatamente l'elaborazione, potresti perdere i dati "in corso". L'arresto di un job potrebbe richiedere alcuni minuti.
Elimina il set di dati BigQuery. Vai all'interfaccia utente web di BigQuery nella console Google Cloud.
Vai all'interfaccia utente web di BigQuery
Nel riquadro Explorer, nella sezione Risorse, fai clic sul set di dati dataflow_sql_tutorial che hai creato.
Nel riquadro dei dettagli, fai clic su Elimina. Si apre una finestra di dialogo di conferma.
Nella finestra di dialogo Elimina set di dati, conferma il comando di eliminazione digitando
delete, quindi fai clic su Elimina.
Eliminare l'argomento Pub/Sub. Vai alla pagina degli argomenti Pub/Sub nella console Google Cloud.
Vai alla pagina degli argomenti Pub/Sub
Seleziona l'argomento
transactions.Fai clic su Elimina per eliminare definitivamente l'argomento. Si apre una finestra di dialogo di conferma.
Nella finestra di dialogo Elimina argomento, conferma il comando di eliminazione digitando
delete, quindi fai clic su Elimina.Vai alla pagina delle sottoscrizioni Pub/Sub.
Seleziona eventuali abbonamenti rimanenti a
transactions. Se i tuoi job non sono più in esecuzione, potrebbero non esserci abbonamenti.Fai clic su Elimina per eliminare definitivamente gli abbonamenti. Nella finestra di dialogo di conferma, fai clic su Elimina.
Elimina il bucket gestione temporanea di Dataflow in Cloud Storage. Vai alla pagina Bucket di Cloud Storage nella console Google Cloud.
Seleziona il bucket gestione temporanea Dataflow.
Fai clic su Elimina per eliminare definitivamente il bucket. Si apre una finestra di dialogo di conferma.
Nella finestra di dialogo Elimina bucket, conferma il comando di eliminazione digitando
DELETE, quindi fai clic su Elimina.
Passaggi successivi
- Consulta l'introduzione a Dataflow SQL.
- Scopri di più sulle nozioni di base della pipeline in modalità flusso.
- Esplora il riferimento SQL di Dataflow.
- Guarda la demo di analisi dei flussi di dati fornita a Cloud Next 2019.