Nesta página, explicamos como consultar dados e gravar resultados de consulta com o Dataflow SQL.
O Dataflow SQL pode consultar as seguintes origens:
- Como fazer streaming de dados a partir de tópicos do Pub/Sub
- Dados de streaming e lote dos conjuntos de arquivos do Cloud Storage
- Dados em lote das tabelas do BigQuery
O Dataflow SQL pode gravar os resultados da consulta nos seguintes destinos:
Pub/Sub
Como consultar tópicos do Pub/Sub
Para consultar um tópico do Pub/Sub com o Dataflow SQL, conclua as seguintes etapas:
Adicionar o tópico do Pub/Sub como origem do Dataflow.
Atribuir um esquema ao tópico do Pub/Sub.
Usar o tópico Pub/Sub em uma consulta do Dataflow SQL.
Como adicionar um tópico do Pub/Sub
É possível adicionar um tópico do Pub/Sub como uma origem do Dataflow usando a IU da Web do BigQuery.
No Console do Google Cloud, acesse a página do BigQuery, onde é possível usar o Dataflow SQL.
No painel de navegação, clique na lista suspensa Adicionar dados e selecione Origens do Cloud Dataflow.
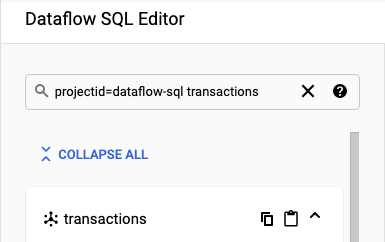
No painel Adicionar origem do Cloud Dataflow, selecione tópicos do Cloud Pub/Sub e pesquise o tópico.
A captura de tela a seguir mostra uma pesquisa pelo tópico do Pub/Sub
transactions: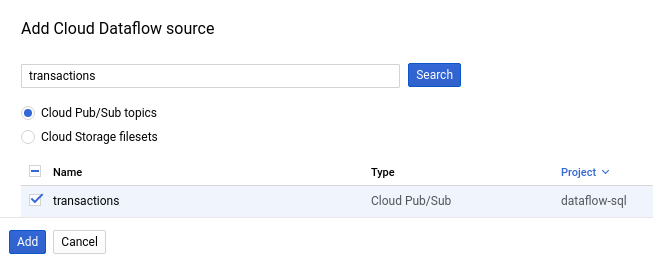
Clique em Add.
Depois de adicionar o tópico Pub/Sub como uma fonte do Dataflow, o tópico do Pub/Sub é exibido na seção Recursos do menu de navegação.
Para encontrar o tópico, expanda Origens do Cloud Dataflow e Tópicos do Cloud Pub/Sub.
Como atribuir um esquema de tópico do Pub/Sub
Esquemas de tópicos do Pub/Sub são compostos pelos seguintes campos:
Um campo
event_timestamp.Carimbos de data/hora de evento do Pub/Sub identificam quando as mensagens são publicadas. Os carimbos de data/hora são adicionados automaticamente às mensagens do Pub/Sub.
Um campo para cada par de chave-valor nas mensagens do Pub/Sub.
Por exemplo, o esquema da mensagem
{"k1":"v1", "k2":"v2"}inclui dois camposSTRING, denominadosk1ek2.
É possível atribuir um esquema a um tópico do Pub/Sub usando o Console do Cloud ou a CLI do Google Cloud.
Console
Para atribuir um esquema a um tópico do Pub/Sub, conclua as seguintes etapas:
Selecione o tópico no painel Recursos.
Na guia Esquema, clique em Editar esquema para abrir o painel lateral Esquema que exibe os campos de esquema.
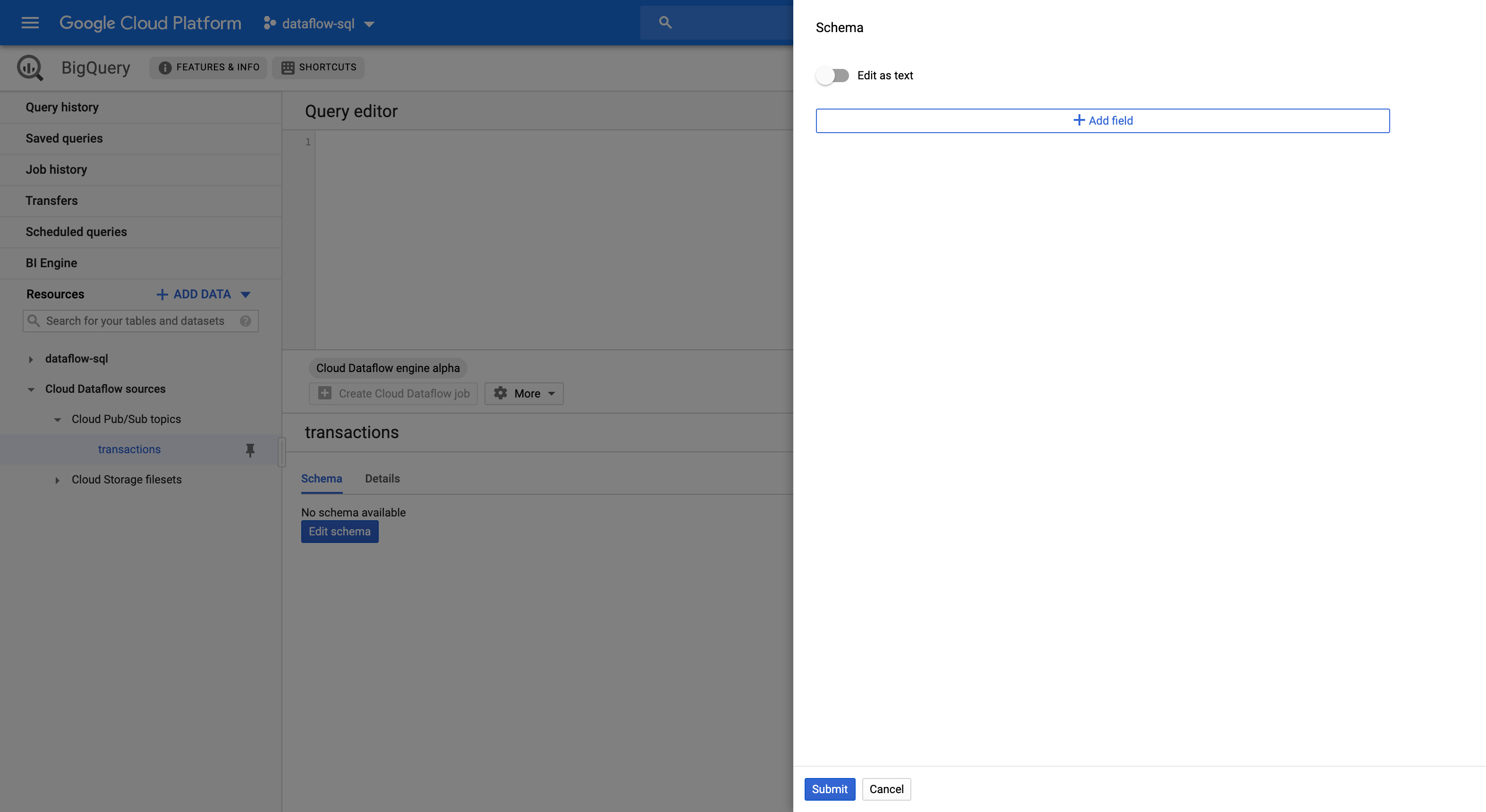
Clique em Adicionar campo para adicionar um campo ao esquema ou alternar o botão Editar como texto para copiar e colar todo o texto do esquema.
Por exemplo, veja a seguir o texto do esquema para um tópico do Pub/Sub com transações de vendas:
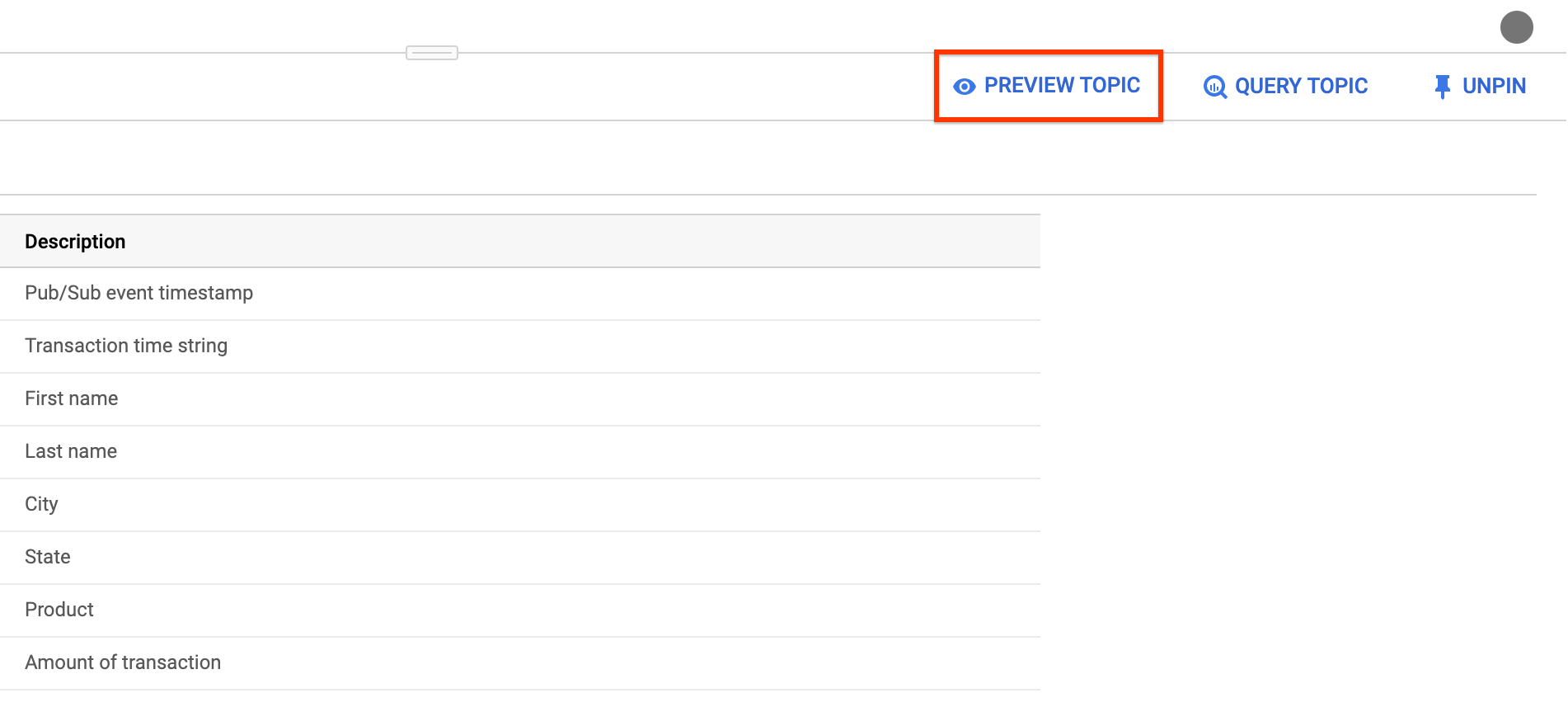
[ { "description": "Pub/Sub event timestamp", "name": "event_timestamp", "mode": "REQUIRED", "type": "TIMESTAMP" }, { "description": "Transaction time string", "name": "tr_time_str", "mode": "NULLABLE", "type": "STRING" }, { "description": "First name", "name": "first_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "Last name", "name": "last_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "City", "name": "city", "mode": "NULLABLE", "type": "STRING" }, { "description": "State", "name": "state", "mode": "NULLABLE", "type": "STRING" }, { "description": "Product", "name": "product", "mode": "NULLABLE", "type": "STRING" }, { "description": "Amount of transaction", "name": "amount", "mode": "NULLABLE", "type": "FLOAT64" } ]Clique em Enviar.
(Opcional) Clique em Visualizar tópico para examinar o conteúdo de suas mensagens e confirmar se elas correspondem ao esquema que você definiu.
gcloud
Para atribuir um esquema a um tópico do Pub/Sub, conclua as seguintes etapas:
Crie um arquivo JSON com o texto do esquema.
Por exemplo, veja a seguir o texto do esquema para um tópico do Pub/Sub com transações de vendas:
[ { "description": "Pub/Sub event timestamp", "column": "event_timestamp", "mode": "REQUIRED", "type": "TIMESTAMP" }, { "description": "Transaction time string", "column": "tr_time_str", "mode": "NULLABLE", "type": "STRING" }, { "description": "First name", "column": "first_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "Last name", "column": "last_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "City", "column": "city", "mode": "NULLABLE", "type": "STRING" }, { "description": "State", "column": "state", "mode": "NULLABLE", "type": "STRING" }, { "description": "Product", "column": "product", "mode": "NULLABLE", "type": "STRING" }, { "description": "Amount of transaction", "column": "amount", "mode": "NULLABLE", "type": "FLOAT64" } ]Atribua o esquema ao tópico do Pub/Sub usando o comando
gcloud data-catalog entries.gcloud data-catalog entries update \ --lookup-entry='pubsub.topic.`PROJECT_ID`.`TOPIC_NAME`' \ --schema-from-file=FILE_PATH
Substitua:
PROJECT_ID: ID do projetoTOPIC_NAME: o nome do tópico do Pub/SubFILE_PATH: o caminho do arquivo JSON com o texto do esquema.
(Opcional) Para verificar se o esquema é atribuído com êxito ao tópico do Pub/Sub, execute o seguinte comando:
gcloud data-catalog entries lookup \ 'pubsub.topic.`PROJECT_ID`.`TOPIC_NAME`'
Como usar um tópico do Pub/Sub
Para se referir a um Pub/Sub em uma consulta do Dataflow SQL, use os seguintes identificadores:
pubsub.topic.`PROJECT_ID`.`TOPIC_NAME`
Substitua:
PROJECT_ID: ID do projetoTOPIC_NAME: o nome do tópico do Pub/Sub
Por exemplo, a consulta a seguir seleciona
daily.transactions do tópico Dataflow no projeto dataflow-sql:
SELECT *
FROM pubsub.topic.`dataflow-sql`.`daily.transactions`
Como gravar em tópicos do Pub/Sub
É possível gravar os resultados da consulta em um tópico do Pub/Sub usando o Console do Cloud ou a CLI do Google Cloud.
Console
Para gravar resultados de consulta em um tópico do Pub/Sub, execute a consulta com o Dataflow SQL:
No Console do Cloud, acesse a página do BigQuery, onde é possível usar o Dataflow SQL.
Digite a consulta do Dataflow SQL no editor de consultas.
Clique em Criar job do Cloud Dataflow para abrir um painel de opções de job.
Na seção Destino do painel, selecione Tipo de saída > Tópico do Cloud Pub/Sub.
Clique em Selecionar um tópico do Cloud Pub/Sub e escolha um tópico.
Clique em Criar.
gcloud
Para gravar os resultados da consulta em um tópico do Pub/Sub, use a
sinalização --pubsub-topic do
comando
gcloud dataflow sql query.
gcloud dataflow sql query \ --job-name=JOB_NAME \ --region=REGION \ --pubsub-project=PROJECT_ID \ --pubsub-topic=TOPIC_NAME \ 'QUERY'
Substitua:
JOB_NAME: um nome de job de sua escolhaREGION: o endpoint regional (por exemplo,us-west1)PROJECT_ID: ID do projetoTOPIC_NAME: o nome do tópico do Pub/SubQUERY: a consulta SQL do Dataflow.
O esquema dos tópicos do Pub/Sub de destino precisa corresponder ao esquema dos resultados da consulta. Se um tópico do Pub/Sub de destino não tiver um esquema, um esquema que corresponda aos resultados da consulta será atribuído automaticamente.
Cloud Storage
Como consultar conjuntos de arquivos do Cloud Storage
Para consultar um conjunto de arquivos do Cloud Storage com o Dataflow SQL, conclua as seguintes etapas:
Crie um conjunto de arquivos do Data Catalog para o Dataflow SQL.
Adicione o conjunto de arquivos do Cloud Storage como origem do Dataflow.
Use o conjunto de arquivos do Cloud Storage em uma consulta SQL do Dataflow.
Como criar conjuntos de arquivos do Cloud Storage
Para criar um conjunto de arquivos do Cloud Storage, consulte Como criar grupos de entrada e conjuntos de arquivos.
O conjunto de arquivos do Cloud Storage precisa ter um esquema e conter apenas arquivos CSV sem linhas de cabeçalho.
Como adicionar conjuntos de arquivos do Cloud Storage
Para adicionar um conjunto de arquivos do Cloud Storage como uma origem do Dataflow, use o Dataflow SQL:
No Console do Cloud, acesse a página do BigQuery, onde é possível usar o Dataflow SQL.
No painel de navegação, clique na lista suspensa Adicionar dados e selecione Origens do Cloud Dataflow.
No painel Adicionar origem do Cloud Dataflow, selecione Conjuntos de arquivos do Cloud Storage e pesquise o tópico.
Clique em Adicionar.
Depois de adicionar o conjunto de arquivos do Cloud Storage como uma origem do Dataflow, ele aparecerá na seção Recursos do menu de navegação.
Para encontrar o conjunto de arquivos, expanda Origens do Cloud Dataflow e Tópicos do Cloud Storage.
Como usar um conjunto de arquivos do Cloud Storage
Para se referir a uma tabela do Cloud Storage em uma consulta do Dataflow SQL, use os seguintes identificadores:
datacatalog.entry.`PROJECT_ID`.REGION.`ENTRY_GROUP`.`FILESET_NAME`
Substitua:
PROJECT_ID: ID do projetoREGION: o endpoint regional (por exemplo,us-west1)ENTRY_GROUP: o grupo de entrada do conjunto de arquivos do Cloud StorageFILESET_NAME: o nome do conjunto de arquivos do Cloud Storage.
Por exemplo, a consulta a seguir seleciona o conjunto de arquivos
daily.registrations do Cloud Storage no projeto dataflow-sql e no grupo de entrada my-fileset-group:
SELECT *
FROM datacatalog.entry.`dataflow-sql`.`us-central1`.`my-fileset-group`.`daily.registrations`
BigQuery
Como consultar tabelas do BigQuery
Para consultar uma tabela do BigQuery com o Dataflow SQL, conclua as seguintes etapas:
Crie uma tabela do BigQuery para o Dataflow SQL.
Use a tabela do BigQuery em uma consulta do Dataflow SQL.
Não é preciso adicionar uma tabela do BigQuery como uma origem do Dataflow.
Como criar uma tabela do BigQuery
Para criar uma tabela do BigQuery para o Dataflow SQL, consulte Como criar uma tabela vazia com uma definição de esquema.
Como usar uma tabela do BigQuery em uma consulta
Para se referir a uma tabela do BigQuery em uma consulta do Dataflow SQL, use os seguintes identificadores:
bigquery.table.`PROJECT_ID`.`DATASET_NAME`.`TABLE_NAME`
Os identificadores devem seguir a estrutura léxica do Dataflow SQL. Use acento grave entre identificadores com caracteres que não sejam letras, números ou sublinhados.
Por exemplo, a consulta a seguir seleciona us_state_salesregions da tabela do
BigQuery no conjunto de dados dataflow_sql_dataset e no
projeto dataflow-sql:
SELECT *
FROM bigquery.table.`dataflow-sql`.dataflow_sql_dataset.us_state_salesregions
Como gravar em uma tabela do BigQuery
É possível gravar os resultados da consulta em uma consulta do Dataflow SQL com o Console do Cloud ou com a CLI do Google Cloud.
Console
Para gravar resultados de consulta em uma consulta do Dataflow SQL, execute a consulta com o Dataflow SQL:
No Console do Cloud, acesse a página do BigQuery, onde é possível usar o Dataflow SQL.
Digite a consulta do Dataflow SQL no editor de consultas.
Clique em Criar job do Cloud Dataflow para abrir um painel de opções de job.
Na seção Destino do painel, selecione Tipo de saída > BigQuery.
Clique em Código do conjunto de dados e selecione um Conjunto de dados carregado ou Criar novo conjunto de dados.
No campo Nome da tabela, insira uma tabela de destino.
(Opcional) Escolha como carregar dados em uma tabela do BigQuery.
- Gravar se vazio: (Padrão) grava os dados somente se a tabela estiver vazia.
- Anexar à tabela: anexa os dados no final da tabela.
- Substituir tabela: apaga todos os dados atuais em uma tabela antes de gravar os novos dados.
Clique em Criar.
gcloud
Para gravar os resultados da consulta em uma tabela do BigQuery, use a
sinalização --bigquery-table do
comando
gcloud dataflow sql query:
gcloud dataflow sql query \ --job-name=JOB_NAME \ --region=REGION \ --bigquery-dataset=DATASET_NAME \ --bigquery-table=TABLE_NAME \ 'QUERY'
Substitua:
JOB_NAME: um nome de job de sua escolhaREGION: o endpoint regional (por exemplo,us-west1)DATASET_NAME: nome do conjunto de dados do BigQuery.TABLE_NAME: o nome da tabela do BigQueryQUERY: a consulta SQL do Dataflow.
Para escolher como gravar dados em uma tabela do BigQuery, use a sinalização --bigquery-write-disposition e os seguintes valores:
write-empty: (Padrão) grava os dados apenas se a tabela estiver vazia.write-append: anexa os dados no final da tabela.write-truncate: apaga todos os dados da tabela antes de gravar os novos.
gcloud dataflow sql query \ --job-name=JOB_NAME \ --region=REGION \ --bigquery-dataset=DATASET_NAME \ --bigquery-table=TABLE_NAME \ --bigquery-write-disposition=WRITE_MODE 'QUERY'
Substitua WRITE_MODE pelo valor de disposição de gravação do BigQuery.
O esquema da tabela de destino do BigQuery deve corresponder ao esquema dos resultados da consulta. Se uma tabela de destino do BigQuery não tiver um esquema, um esquema que corresponda aos resultados da consulta será atribuído automaticamente.