Cloud Profiler は、本番環境のアプリケーションから CPU 使用率やメモリ割り当てなどの情報を継続的に収集する、オーバーヘッドの少ないプロファイラです。詳細については、プロファイリングのコンセプトをご覧ください。パイプライン パフォーマンスのトラブルシューティングやモニタリングを行うには、Cloud Profiler と Dataflow のインテグレーションを使用して、パイプライン コードで最も多くのリソースを消費する部分を特定します。
Dataflow パイプラインの構築または実行に関するヒントやデバッグ戦略については、パイプラインのトラブルシューティングとデバッグをご覧ください。
始める前に
プロファイリングのコンセプトを理解し、Profiler のインターフェースの操作を習得します。Profiler インターフェースの使い方については、分析するプロファイルを選択するをご覧ください。
ジョブを開始する前に、プロジェクトで Cloud Profiler API を有効にする必要があります。これは、初めて Profiler ページにアクセスするときに自動的に有効になります。Google Cloud CLI gcloud コマンドライン ツールまたは Google Cloud コンソールを使用して Cloud Profiler API を有効にすることもできます。
Cloud Profiler を使用するには、プロジェクトに十分な割り当てが必要です。また、Dataflow ジョブのワーカー サービス アカウントには、Profiler に対する適切な権限が必要です。たとえば、プロファイルを作成するには、ワーカー サービス アカウントに cloudprofiler.profiles.create 権限が必要です。この権限は、Cloud Profiler エージェント(roles/cloudprofiler.agent)IAM ロールに含まれています。詳しくは、IAM によるアクセス制御をご覧ください。
Dataflow パイプラインに対して Cloud Profiler を有効にする
Cloud Profiler は、Apache Beam SDK for Java および Python バージョン 2.33.0 以降で作成された Dataflow パイプラインで使用できます。Python パイプラインでは Dataflow Runner v2 を使用する必要があります。Cloud Profiler はパイプラインの起動時に有効にできます。平均化された CPU とメモリのオーバーヘッドは、パイプラインで 1% 未満と予想されます。
Java
CPU プロファイリングを有効にするには、次のオプションを使用してパイプラインを開始します。
--dataflowServiceOptions=enable_google_cloud_profiler
ヒープ プロファイリングを有効にするには、次のオプションを使用してパイプラインを開始します。ヒープ プロファイリングでは Java 11 以降が必要です。
--dataflowServiceOptions=enable_google_cloud_profiler
--dataflowServiceOptions=enable_google_cloud_heap_sampling
Python
Cloud Profiler を使用するには、Dataflow Runner v2 で Python パイプラインを実行する必要があります。
CPU プロファイリングを有効にするには、次のオプションを使用してパイプラインを開始します。Python では、ヒープ プロファイリングがまだサポートされていません。
--dataflow_service_options=enable_google_cloud_profiler
Go
CPU とヒープのプロファイルを有効にするには、次のオプションを使用してパイプラインを開始します。
--dataflow_service_options=enable_google_cloud_profiler
パイプラインを Dataflow テンプレートからデプロイし、Cloud Profiler を有効にする場合は、enable_google_cloud_profiler フラグと enable_google_cloud_heap_sampling フラグを追加のテストとして指定します。
コンソール
Google 提供のテンプレートを使用する場合は、Dataflow の [テンプレートからジョブを作成] ページの [追加テスト] フィールドでフラグを指定できます。
gcloud
Google Cloud CLI を使用してテンプレートを実行する場合、gcloud
dataflow jobs run または gcloud dataflow flex-template run を使用します。テンプレートの種類に応じて --additional-experiments オプションを使用してフラグを指定します。
API
REST API を使用してテンプレートを実行する場合は、テンプレートの種類に応じて、ランタイム環境 RuntimeEnvironment または FlexTemplateRuntimeEnvironment の additionalExperiments フィールドを使用してフラグを指定します。
プロファイリング データを表示する
Cloud Profiler が有効になっている場合は、ジョブページに Profiler ページへのリンクが表示されます。
![[Profiler] ページへのリンクが表示された [ジョブ] ページ。](https://cloud.google.com/static/dataflow/images/profiler-link.png?hl=ja)
Profiler ページでは、Dataflow パイプラインのプロファイリング データも確認できます。Service はジョブ名、Version はジョブ ID です。

Cloud Profiler を使用する
[Profiler] ページには、ワーカーで実行されている各フレームの統計情報を表示するフレームグラフがあります。横方向を見ると、各フレームの実行にかかった時間(CPU 時間)を確認できます。縦方向を見ると、スタック トレースとコードが並行して実行されていることがわかります。スタック トレースの大部分は、ランナーのインフラストラクチャ コードが占めています。通常、デバッグの段階ではユーザーコードの実行が問題になります。これは、グラフの一番下のヒントの近くに表示されています。ユーザーコードは、ユーザーコードへの呼び出しのみを行うランナーコードを表すマーカー フレームを探すことで特定できます。Beam ParDo ランナーの場合、ユーザー指定の DoFn メソッド シグネチャを呼び出すため、動的なアダプタレイヤが作成されます。このレイヤは、invokeProcessElement という接尾辞の付いたフレームで確認識別できます。次の図は、マーカー フレームを探す方法を示しています。
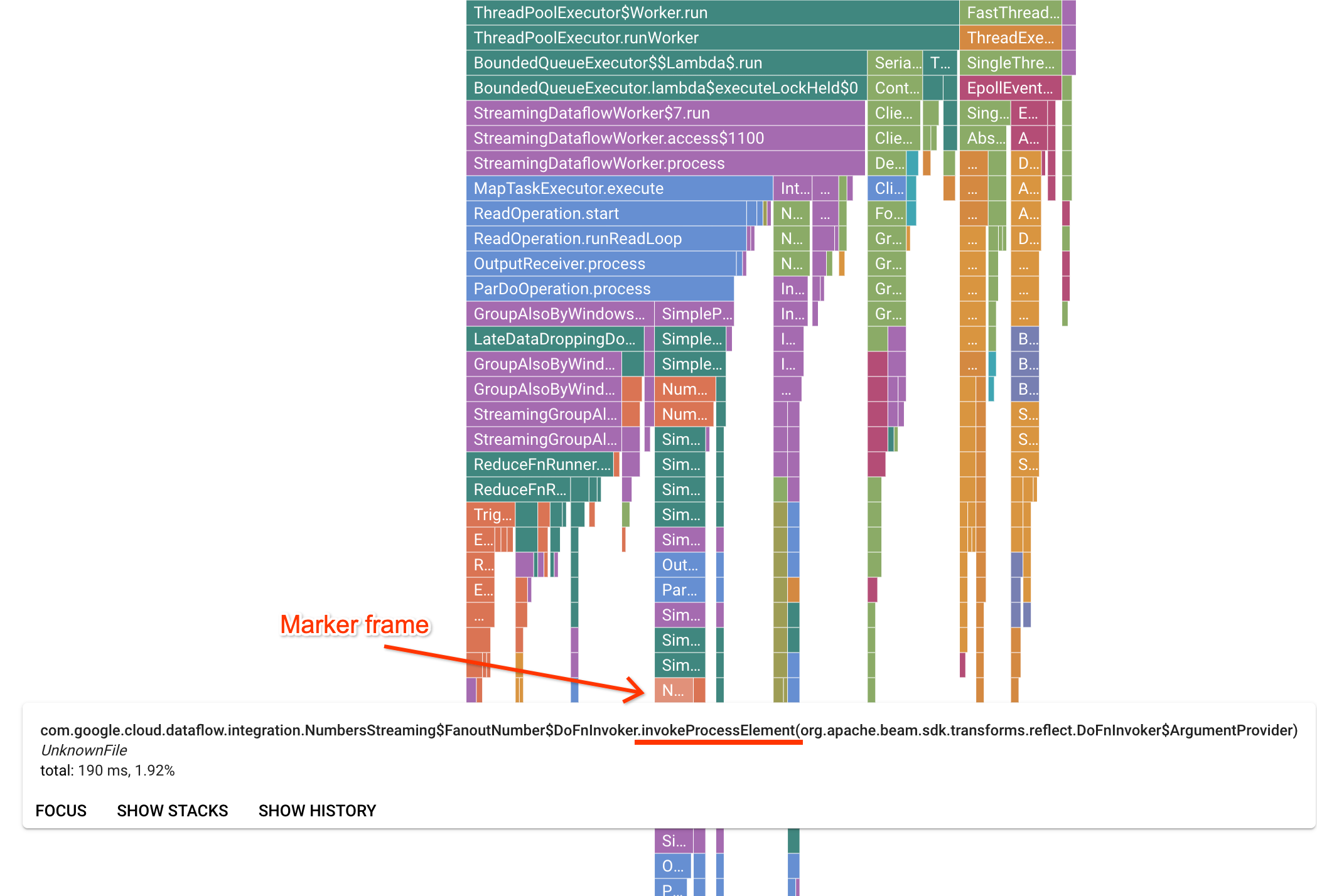
フレームグラフで関心のあるマーカー フレームをクリックすると、そのスタック トレースにフォーカスが異動し、長時間実行されているユーザーコードを確認できます。最も遅いオペレーションを見ると、ボトルネックになっている場所を特定し、最適化に適した部分を確認できます。次の例では、グローバル ウィンドウ処理が ByteArrayCoder で使用されていることがわかります。この場合、ArrayList オペレーションや HashMap オペレーションと比較して、コーダーが CPU 時間を大量に消費しているため、このコーダーは最適化に適している可能性があります。
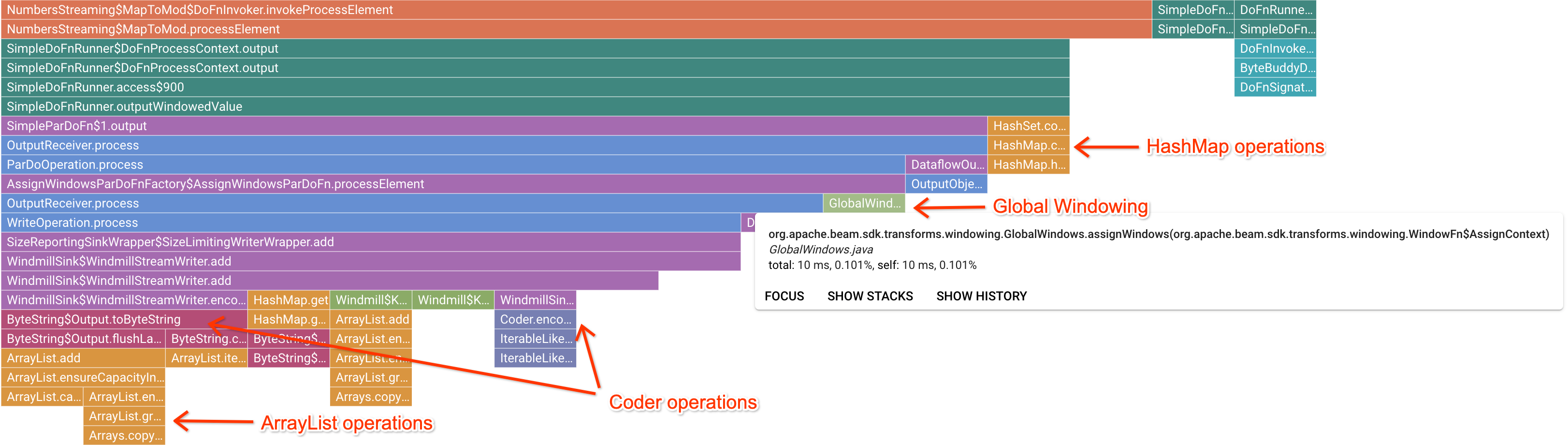
Cloud Profiler のトラブルシューティング
Cloud Profiler を有効にしても、パイプラインでプロファイリング データが生成されない場合は、次のいずれかの状況が考えられます。
パイプラインで古いバージョンの Apache Beam SDK が使用されている。Cloud Profiler を使用するには、Apache Beam SDK バージョン 2.33.0 以降を使用する必要があります。パイプラインの Apache Beam SDK バージョンはジョブページで確認できます。ジョブを Dataflow テンプレートから作成する場合は、テンプレートでサポートされる SDK バージョンを使用する必要があります。
プロジェクトで Cloud Profiler の割り当てが不足している。割り当ての使用状況は、プロジェクトの割り当てページで確認できます。Cloud Profiler の割り当てを超えると、
Failed to collect and upload profile whose profile type is WALLなどのエラーが発生する可能性があります。割り当てに達すると、Cloud Profiler サービスがプロファイリング データを拒否します。Cloud Profiler の割り当ての詳細については、割り当てと上限をご覧ください。
Cloud Profiler エージェントは、Dataflow ワーカーの起動時にインストールされます。Cloud Profiler によって生成されたログメッセージは、ログタイプ dataflow.googleapis.com/worker-startup で取得できます。
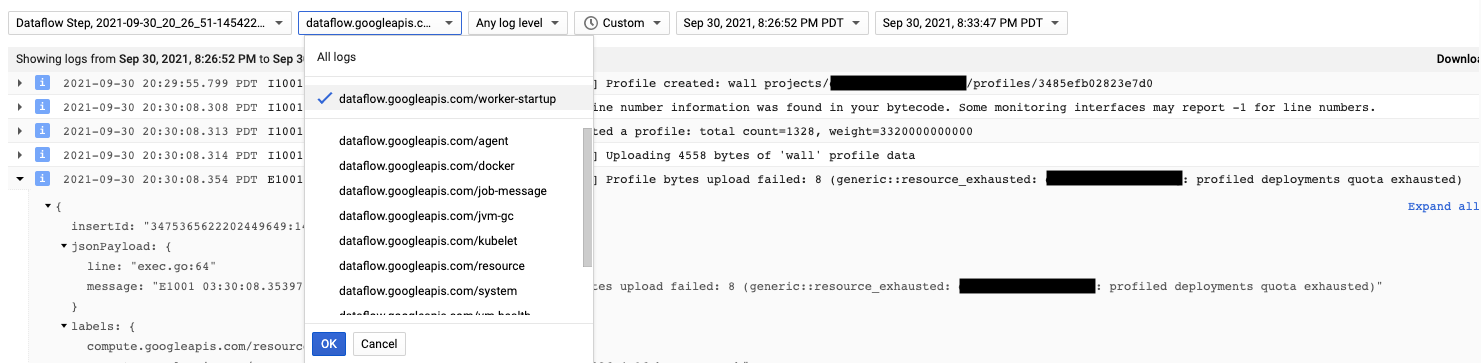
プロファイリング データがあっても、Cloud Profiler に出力が表示されないことがあります。Profiler に「There were
profiles collected for the specified time range, but none match the current
filters」のようなメッセージが表示されます。
この問題を解決するには、次のトラブルシューティング手順を試してください。
Profiler のタイムスパンと終了時刻にジョブの経過時間が含まれていることを確認します。
Profiler で正しいジョブが選択されていることを確認します。Service はジョブ名です。
job_nameパイプライン オプションの値が、Dataflow ジョブページのジョブ名と同じであることを確認します。Profiler エージェントの読み込み時に service-name 引数を指定した場合は、サービス名が正しく構成されていることを確認します。