Utilisez l'exécuteur interactif Apache Beam avec les notebooks JupyterLab pour effectuer les tâches suivantes :
- Développer des pipelines de manière itérative
- Inspecter le graphique du pipeline
- Analyser une
PCollectionsindividuelle dans un workflow REPL (read-eval-print-loop).
Ces notebooks Apache Beam sont disponibles via des notebooks gérés par l'utilisateur Vertex AI Workbench, un service qui héberge des machines virtuelles de notebooks préinstallées avec les derniers frameworks de science des données. et de machine learning.
Ce guide se concentre sur la fonctionnalité introduite par les notebooks Apache Beam, mais n'explique pas comment créer un notebook. Pour plus d'informations sur Apache Beam, consultez le guide de programmation d'Apache Beam.
Compatibilité et limites
- Les notebooks Apache Beam ne sont compatibles qu'avec Python.
- Les segments de pipeline Apache Beam exécutés dans ces notebooks s'exécutent dans un environnement de test, et non sur un exécuteur de production Apache Beam. Pour lancer les notebooks sur le service Dataflow, exportez les pipelines créés dans votre notebook Apache Beam. Pour en savoir plus, consultez la section Lancer des tâches Dataflow à partir d'un pipeline créé dans votre notebook.
Avant de commencer
- Connectez-vous à votre compte Google Cloud. Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $ de crédits gratuits pour exécuter, tester et déployer des charges de travail.
-
Dans Google Cloud Console, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
-
Vérifiez que la facturation est activée pour votre projet Google Cloud.
-
Activer les API Compute Engine and Notebooks.
-
Dans Google Cloud Console, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
-
Vérifiez que la facturation est activée pour votre projet Google Cloud.
-
Activer les API Compute Engine and Notebooks.
Avant de créer votre instance de notebook Apache Beam, activez des API supplémentaires pour les pipelines utilisant d'autres services, tels que Pub/Sub.
Si elle n'est pas spécifiée, l'instance de notebook est exécutée par le compte de service Compute Engine par défaut avec le rôle d'éditeur de projet IAM. Si les limites du rôle du compte de service sont explicitement définies dans le projet, assurez-vous qu'il dispose des autorisations suffisantes pour exécuter vos notebooks. Par exemple, la lecture d'un sujet Pub/Sub crée implicitement un abonnement, et votre compte de service nécessite un rôle d'éditeur Pub/Sub IAM. En revanche, la lecture d'un abonnement Pub/Sub ne nécessite qu'un rôle d'abonné Pub/Sub IAM.
Une fois que vous avez terminé ce guide, supprimez les ressources créées pour éviter une facturation continue. Pour plus d'informations, consultez la section Nettoyer.
Lancer une instance de notebook Apache Beam
Dans la console Google Cloud, accédez à la page Workbench de Dataflow.
Vérifiez que vous êtes bien dans l'onglet Notebooks gérés par l'utilisateur.
Dans la barre d'outils, cliquez sur Créer.
Dans la section Environnement, sous Environnement, sélectionnez Apache Beam.
Facultatif : Si vous souhaitez exécuter des notebooks sur un GPU, dans la section Type de machine, sélectionnez un type de machine compatible avec les GPU, puis sélectionnez Installer le pilote de GPU NVIDIA automatiquement pour moi. Pour en savoir plus, consultez la page Plates-formes de GPU.
Dans la section Mise en réseau, sélectionnez un sous-réseau pour la VM de notebook.
Facultatif : Si vous souhaitez configurer une instance de notebook personnalisée, consultez la section Créer une instance de notebook gérée par l'utilisateur avec des propriétés spécifiques.
Cliquez sur Créer. Dataflow Workbench crée une instance de notebook Apache Beam.
Une fois l'instance de notebook créée, le lien Ouvrir JupyterLab devient actif. Cliquez sur Ouvrir JupyterLab.
Facultatif : installer les dépendances
Les dépendances de connecteur Apache Beam et Google Cloud sont déjà installées sur les notebooks Apache Beam. Si votre pipeline contient des connecteurs ou des PTransforms personnalisés qui dépendent de bibliothèques tierces, installez-les après avoir créé une instance de notebook. Pour en savoir plus, consultez la section Installer les dépendances dans la documentation sur les notebooks gérés par l'utilisateur.
Premiers pas avec les notebooks Apache Beam
Après avoir ouvert une instance de notebooks gérés par l'utilisateur, des exemples de notebooks sont disponibles dans le dossier Exemples. Les notebooks suivants sont disponibles:
- Word Count
- Nombre de mots en flux continu
- Données en flux continu sur les courses en taxi à New York
- Apache Beam SQL dans les notebooks avec comparaisons aux pipelines
- Apache Beam SQL dans les notebooks avec l'exécuteur Dataflow
- Apache Beam SQL dans les notebooks
- Nombre de mots Dataflow
- Flink interactif à grande échelle
- RunInference
- Utiliser des GPU avec Apache Beam
- Visualiser des données
Vous trouverez des tutoriels supplémentaires expliquant les bases d'Apache Beam dans le dossier Tutoriels. Les tutoriels suivants sont disponibles:
- Opérations de base
- Opérations au niveau des éléments
- Agrégations
- Windows
- Opérations d'E/S
- Flux
- Exercices finaux
Ces notebooks incluent du texte explicatif et des blocs de code commentés pour vous aider à comprendre les concepts d'Apache Beam et l'utilisation de l'API. Les tutoriels fournissent également des exercices pratiques pour vous entraîner à maîtriser les concepts abordés.
Les sections suivantes utilisent l'exemple de code du notebook "Nombre de mots en flux continu". Les extraits de code de ce guide et ceux du notebook "Nombre de mots en flux continu" peuvent présenter des écarts mineurs.
Créer une instance de notebook
Accédez à Fichier > Nouveau > Notebook, puis sélectionnez un noyau Apache Beam 2.22 ou version ultérieure.
Les notebooks Apache Beam sont créés par rapport à la branche principale du SDK Apache Beam. Cela signifie que la dernière version du noyau affichée dans l'interface utilisateur des notebooks peut être antérieure à la version la plus récente du SDK.
Apache Beam est installé sur votre instance de notebook. Par conséquent, incluez les modules interactive_runner et interactive_beam dans votre notebook.
import apache_beam as beam
from apache_beam.runners.interactive.interactive_runner import InteractiveRunner
import apache_beam.runners.interactive.interactive_beam as ib
Si votre notebook utilise d'autres API Google, ajoutez les instructions d'importation suivantes :
from apache_beam.options import pipeline_options
from apache_beam.options.pipeline_options import GoogleCloudOptions
import google.auth
Définir les options d'interactivité
La ligne suivante définit la durée pendant laquelle InteractiveRunner enregistre les données d'une source illimitée. Dans cet exemple, la durée est définie sur 10 minutes.
ib.options.recording_duration = '10m'
Vous pouvez également modifier la taille limite d'enregistrement (en octets) d'une source illimitée en utilisant la propriété recording_size_limit.
# Set the recording size limit to 1 GB.
ib.options.recording_size_limit = 1e9
Pour voir d'autres options interactives, consultez la classe interactive_beam.options.
Créer votre pipeline
Initialisez le pipeline à l'aide d'un objet InteractiveRunner.
options = pipeline_options.PipelineOptions()
# Set the pipeline mode to stream the data from Pub/Sub.
options.view_as(pipeline_options.StandardOptions).streaming = True
# Set the project to the default project in your current Google Cloud environment.
# The project is used to create a subscription to the Pub/Sub topic.
_, options.view_as(GoogleCloudOptions).project = google.auth.default()
p = beam.Pipeline(InteractiveRunner(), options=options)
Lire et visualiser les données
L'exemple suivant montre un pipeline Apache Beam qui crée un abonnement au sujet Pub/Sub donné et effectue des lectures à partir de l'abonnement.
words = p
| "read" >> beam.io.ReadFromPubSub(topic="projects/pubsub-public-data/topics/shakespeare-kinglear")
Le pipeline compte les mots par fenêtres à partir de la source. Il crée un fenêtrage fixe, chaque fenêtre ayant une durée de 10 secondes.
windowed_words = (words
| "window" >> beam.WindowInto(beam.window.FixedWindows(10)))
Une fois les données fenêtrées, les mots sont comptés par fenêtre.
windowed_word_counts = (windowed_words
| "count" >> beam.combiners.Count.PerElement())
La méthode show() permet de visualiser la PCollection obtenue dans le notebook.
ib.show(windowed_word_counts, include_window_info=True)
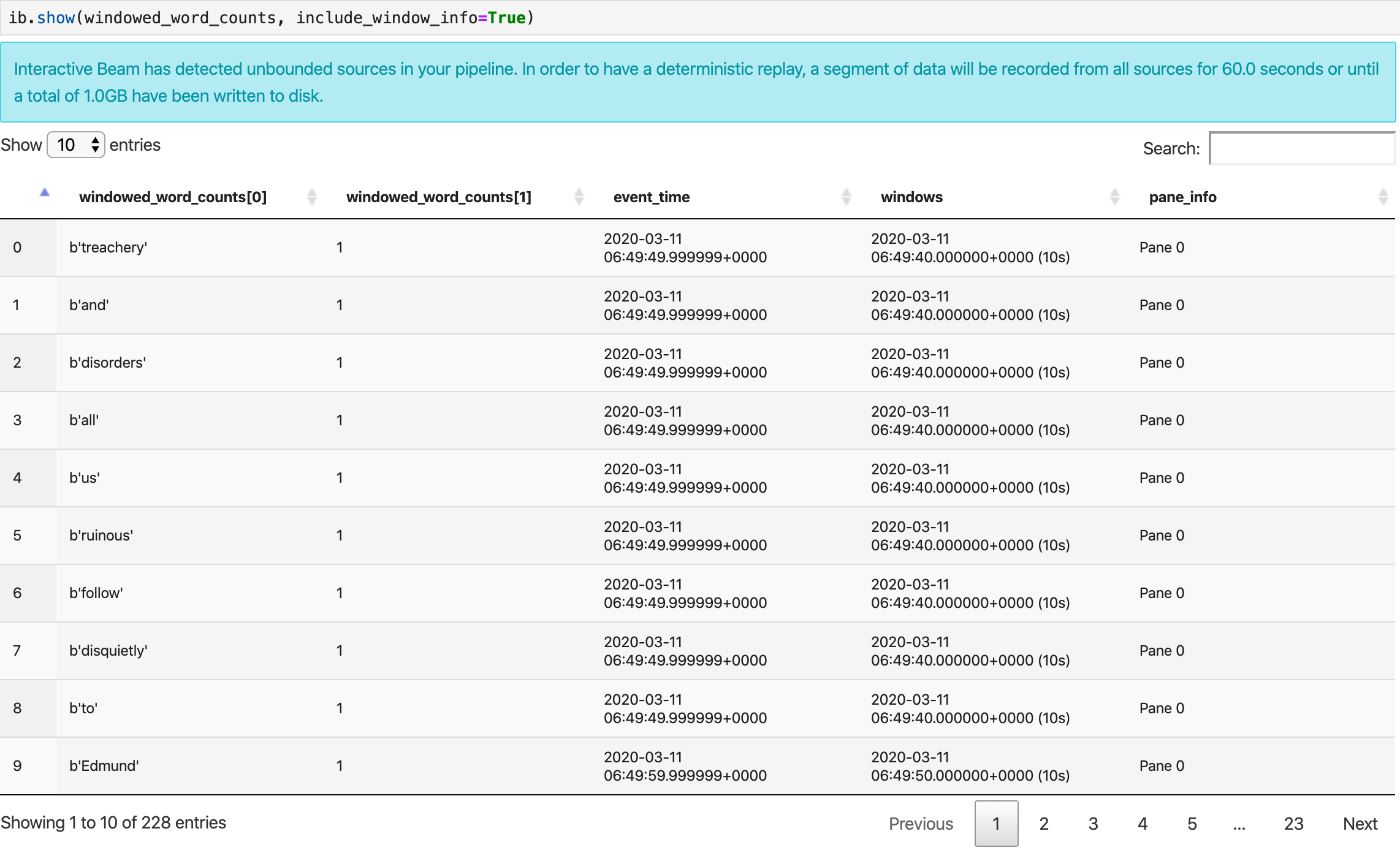
Vous pouvez réduire le champ d'application de l'ensemble de résultats à partir de show() en définissant deux paramètres facultatifs : n et duration.
- Définissez
nde sorte que l'ensemble de résultats affiche au maximumnéléments, par exemple 20. Sinn'est pas défini, le comportement par défaut consiste à répertorier les éléments les plus récents capturés jusqu'à la fin de l'enregistrement source. - Définissez
durationpour limiter l'ensemble de résultats à un nombre spécifié de secondes de données à compter du début de l'enregistrement source. Sidurationn'est pas défini, le comportement par défaut consiste à répertorier tous les éléments jusqu'à la fin de l'enregistrement.
Si les deux paramètres facultatifs sont définis, show() s'arrête chaque fois qu'un seuil est atteint. Dans l'exemple suivant, show() renvoie au maximum 20 éléments calculés sur la base des 30 premières secondes de données provenant des sources enregistrées.
ib.show(windowed_word_counts, include_window_info=True, n=20, duration=30)
Pour afficher les visualisations de vos données, transmettez visualize_data=True à la méthode show(). Vous pouvez appliquer plusieurs filtres à vos visualisations. La visualisation suivante vous permet de filtrer par libellé et par axe :
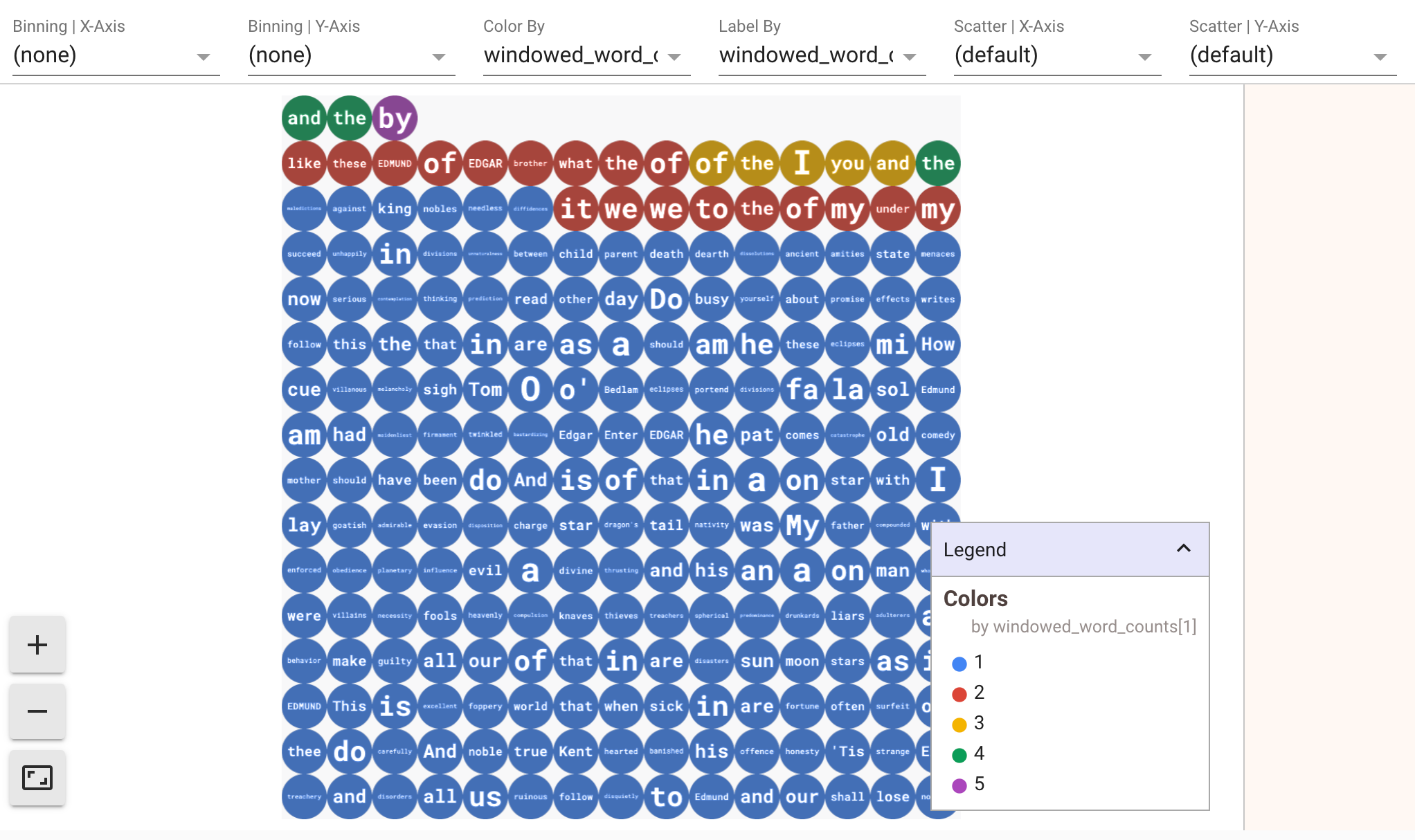
Pour garantir la répétabilité lors du prototypage de pipelines de traitement par flux, les appels de méthode show() réutilisent les données capturées par défaut. Pour modifier ce comportement et faire en sorte que la méthode show() extraie toujours de nouvelles données, définissez interactive_beam.options.enable_capture_replay = False. En outre, si vous ajoutez une deuxième source illimitée à votre notebook, les données de la source illimitée précédente sont supprimées.
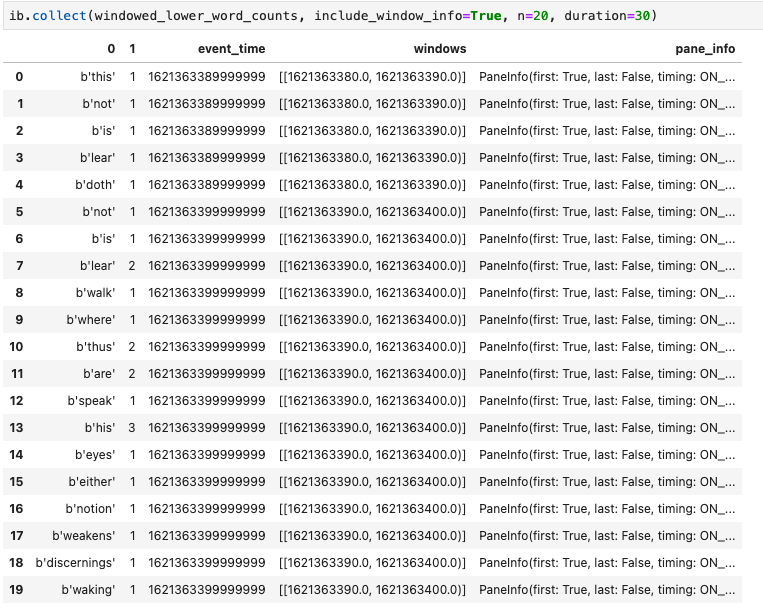
Un DataFrame Pandas est une autre visualisation utile dans les notebooks Apache Beam. L'exemple suivant convertit d'abord les mots en minuscules, puis calcule la fréquence de chaque mot.
windowed_lower_word_counts = (windowed_words
| beam.Map(lambda word: word.lower())
| "count" >> beam.combiners.Count.PerElement())
La méthode collect() fournit le résultat dans un DataFrame pandas.
ib.collect(windowed_lower_word_counts, include_window_info=True)
La modification et la réexécution d'une cellule sont courantes dans le développement de notebook. Lorsque vous modifiez et réexécutez une cellule dans un notebook Apache Beam, la cellule n'annule pas l'action prévue du code dans la cellule d'origine. Par exemple, si une cellule ajoute un PTransform à un pipeline, la réexécution de cette cellule ajoute un PTransform supplémentaire au pipeline. Si vous souhaitez effacer l'état, redémarrez le noyau et réexécutez les cellules.
Visualiser les données via l'outil d'inspection interactif de Beam
Il est possible que cela vous prenne beaucoup de temps d'examiner les données d'une PCollection en appelant constamment show() et collect(), en particulier lorsque le résultat prend beaucoup d'espace sur votre écran et complexifie la navigation sur le notebook. Vous pouvez également avoir besoin de comparer plusieurs PCollections côte à côte pour vérifier si une transformation fonctionne comme prévu. Par exemple, lorsqu'une PCollection subit une transformation et produit l'autre. Pour ces cas d'utilisation, l'outil d'inspection interactif de Beam est une solution plus pratique.
L'outil d'inspection interactif de Beam est fourni sous la forme d'une extension JupyterLab apache-beam-jupyterlab-sidepanel préinstallée dans le notebook Apache Beam. Avec l'extension, vous pouvez examiner de manière interactive l'état des pipelines et des données associés à chaque PCollection sans appeler explicitement show() ou collect().
Il existe trois façons d'ouvrir l'outil d'inspection :
Cliquez sur
Interactive Beamdans la barre de menu supérieure de JupyterLab. Dans la liste déroulante, localisezOpen Inspector, puis cliquez dessus pour ouvrir l'outil d'inspection.
Utilisez la page du lanceur d'applications. Si aucune page du lanceur d'applications ne s'ouvre, cliquez sur
File->New Launcherpour l'ouvrir. Sur la page du lanceur d'applications, localisezInteractive Beamet cliquez surOpen Inspectorpour ouvrir l'outil d'inspection.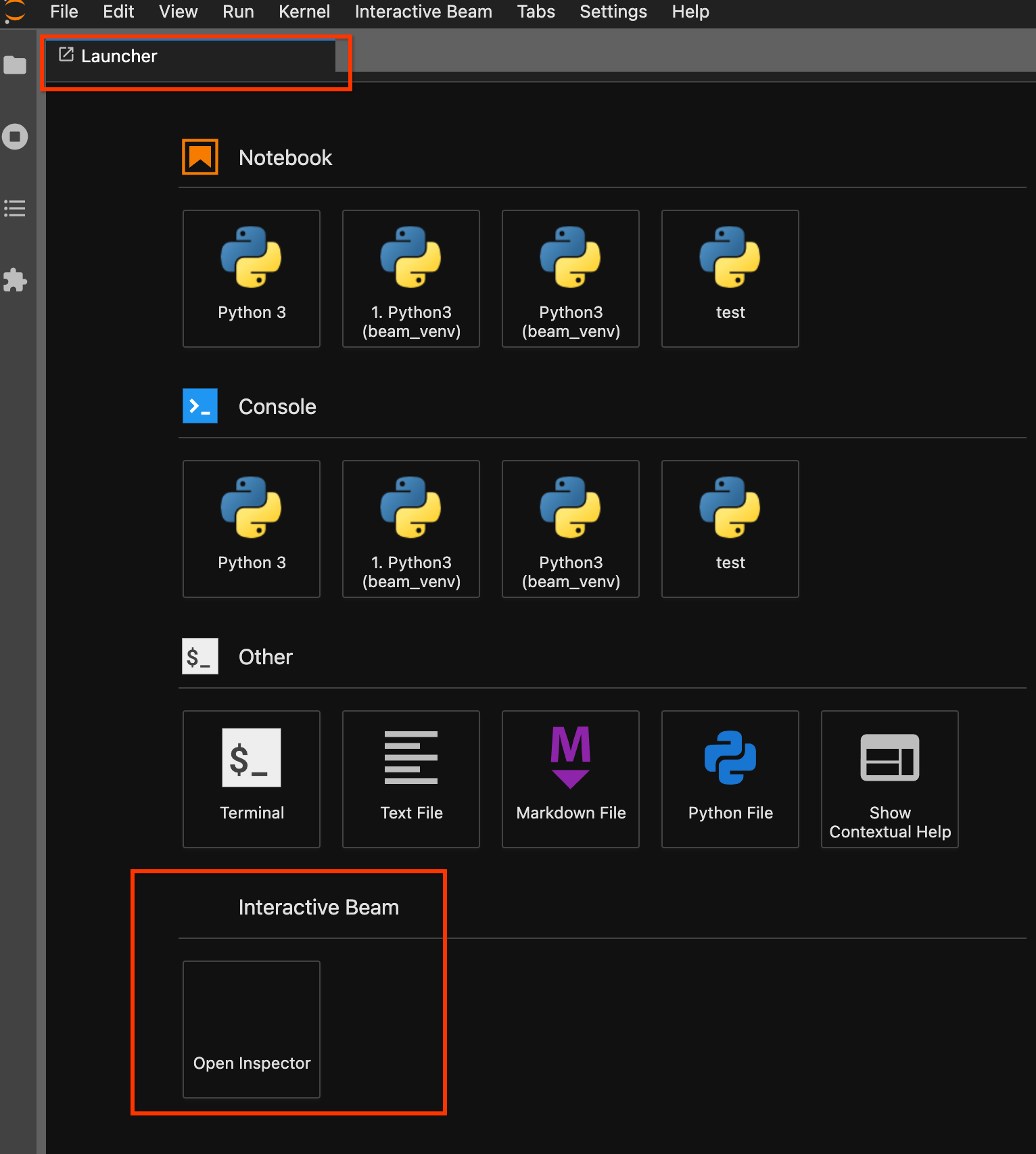
Utilisez la palette de commandes. Dans la barre de menu JupyterLab, cliquez sur
View>Activate Command Palette. Dans la boîte de dialogue, recherchezInteractive Beampour répertorier toutes les options de l'extension. Cliquez surOpen Inspectorpour ouvrir l'outil d'inspection.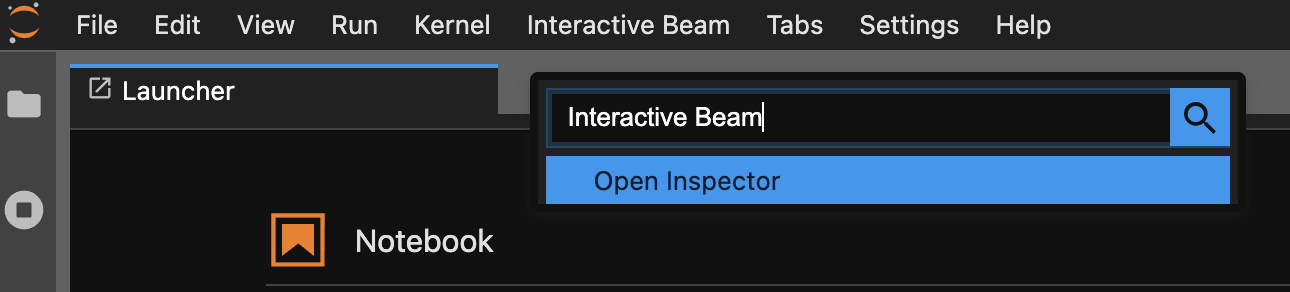
Lorsque l'outil d'inspection est sur le point de se lancer :
Si un seul notebook est ouvert, l'outil d'inspection s'y connecte automatiquement.
Si aucun notebook n'est ouvert, une boîte de dialogue vous permet de sélectionner un noyau.
Si plusieurs notebooks sont ouverts, une boîte de dialogue vous permet de sélectionner la session de notebook.
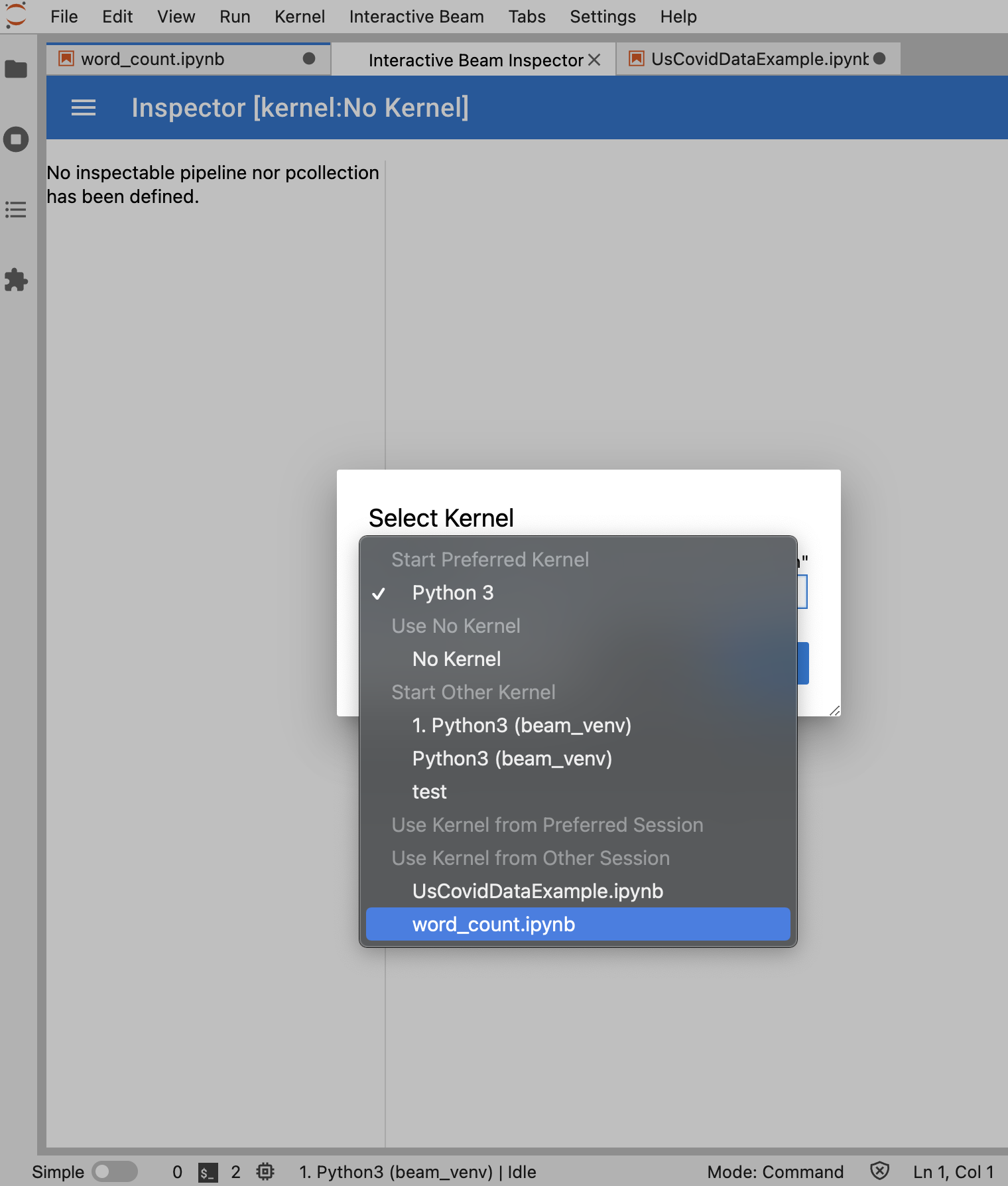
Il est recommandé d'ouvrir au moins un notebook et de sélectionner un noyau pour celui-ci avant d'ouvrir l'outil d'inspection. Si vous ouvrez un outil d'inspection avec un noyau avant d'ouvrir un notebook, vous devrez sélectionner Interactive Beam Inspector Session dans Use
Kernel from Preferred Session pour ouvrir un notebook et vous y connecter. Un outil d'inspection et un notebook sont connectés lorsqu'ils partagent la même session, et non des sessions différentes créées à partir du même noyau. Sélectionner le même noyau dans Start Preferred Kernel crée une session indépendante des sessions existantes de notebooks ou d'outils d'inspection ouverts.
Vous pouvez ouvrir plusieurs outils d'inspection pour un notebook ouvert et les organiser en effectuant librement un glisser-déposer de leurs onglets dans l'espace de travail.
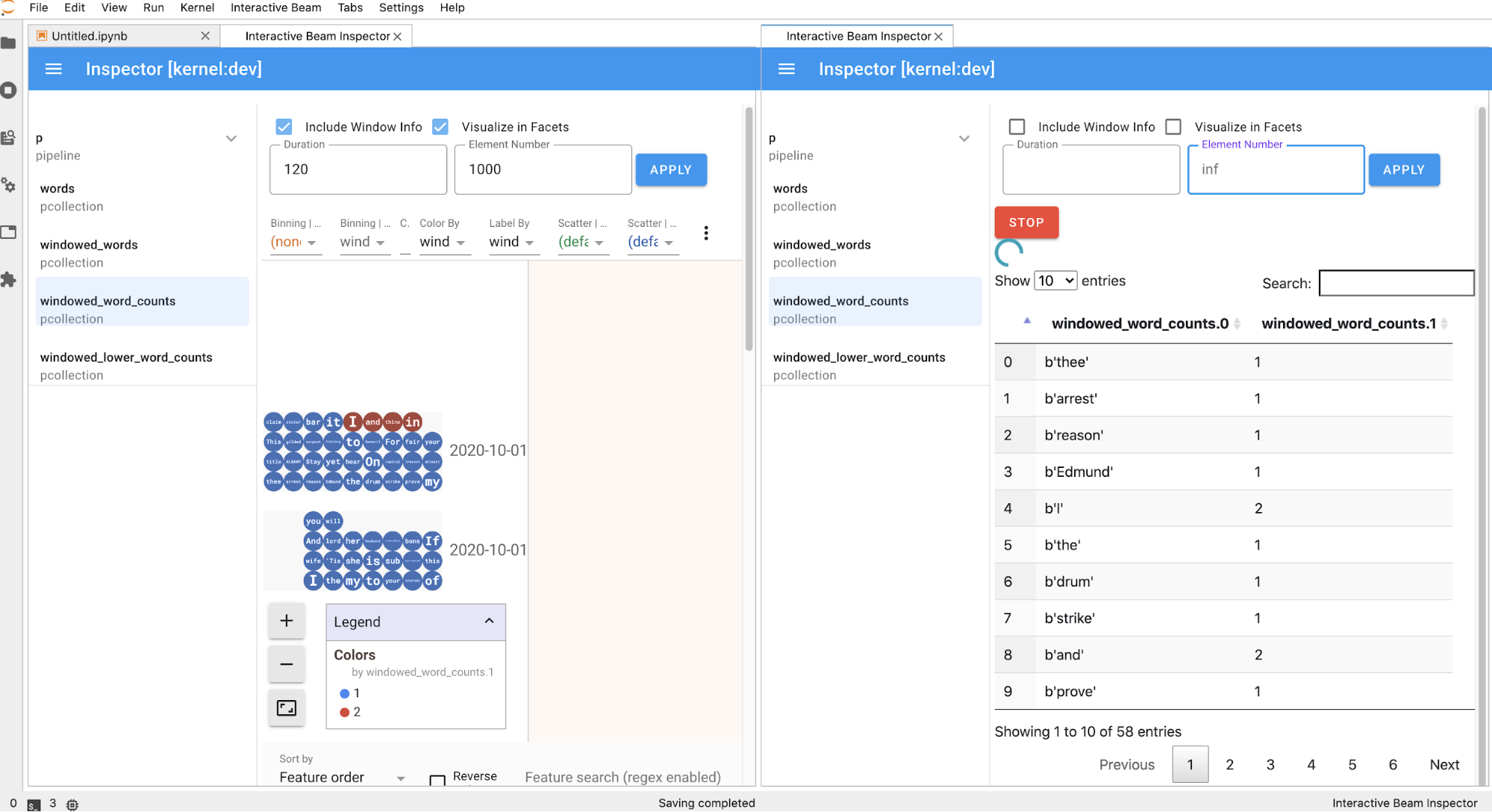
La page de l'outil d'inspection s'actualise automatiquement lorsque vous exécutez des cellules dans le notebook. La page répertorie les pipelines et la PCollections définis dans le notebook connecté. Les fichiers PCollections sont organisés par pipelines auxquels ils appartiennent. Vous pouvez les réduire en cliquant sur le pipeline d'en-tête.
Lorsque vous cliquez sur les éléments de la liste des pipelines et des PCollections, l'outil d'inspection affiche les visualisations correspondantes à droite :
S'il s'agit d'une
PCollection, l'outil d'inspection affiche ses données (de manière dynamique si les données sont toujours présentes pour lesPCollectionsillimitées) avec des widgets supplémentaires pour ajuster la visualisation après avoir cliqué sur le boutonAPPLY.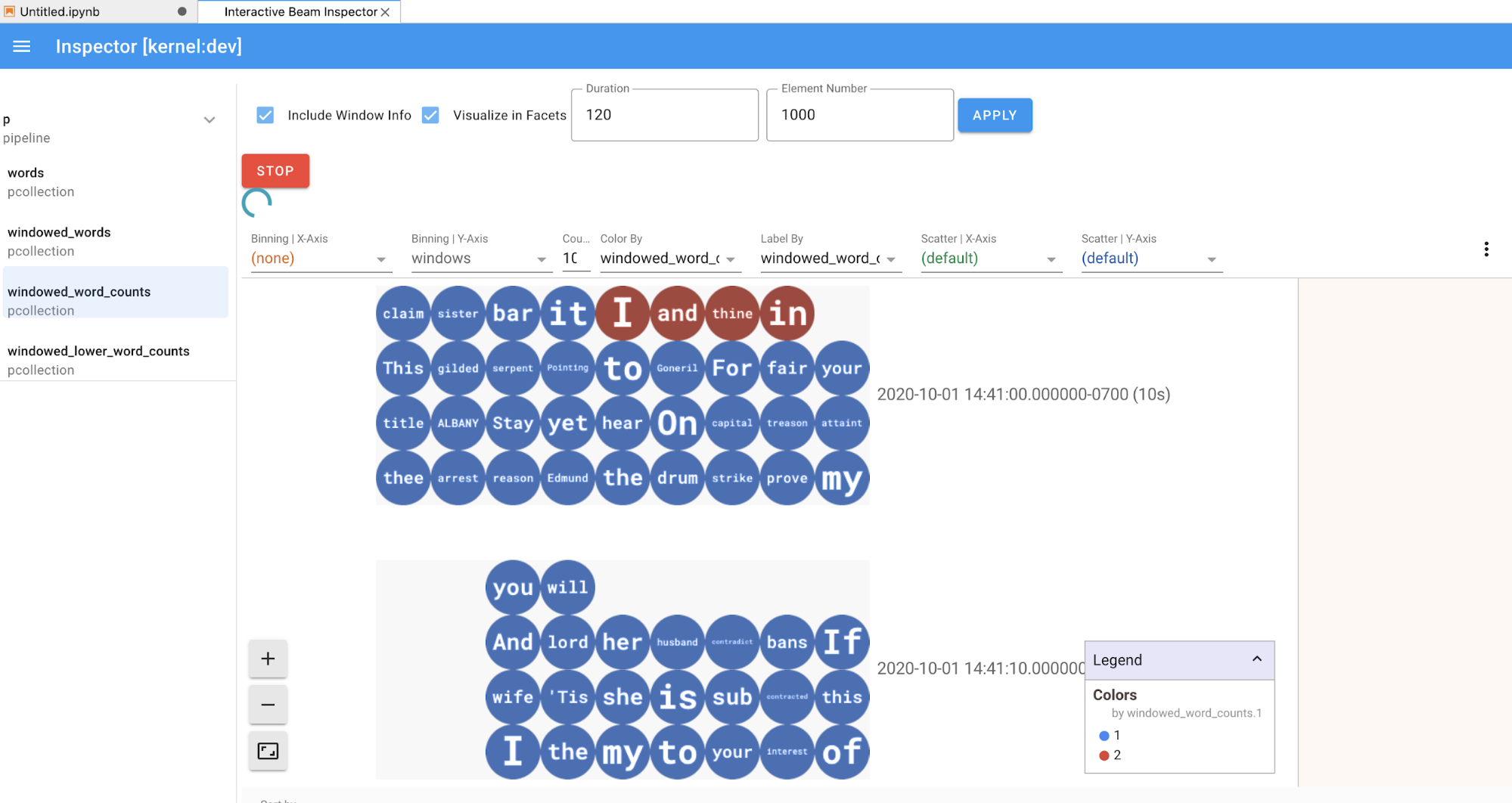
Étant donné que l'outil d'inspection et le notebook ouvert partagent la même session de noyau, ils se bloquent l'un l'autre. Par exemple, si le notebook est occupé à exécuter du code, l'outil d'inspection ne se met à jour qu'une fois l'exécution du notebook terminée. À l'inverse, si vous souhaitez exécuter du code immédiatement dans votre notebook pendant que l'outil d'inspection visualise une
PCollectionde manière dynamique, vous devez cliquer sur le boutonSTOPpour arrêter la visualisation et libérer le noyau de manière préemptive dans le notebook.S'il s'agit d'un pipeline, l'outil d'inspection affiche le graphique correspondant.
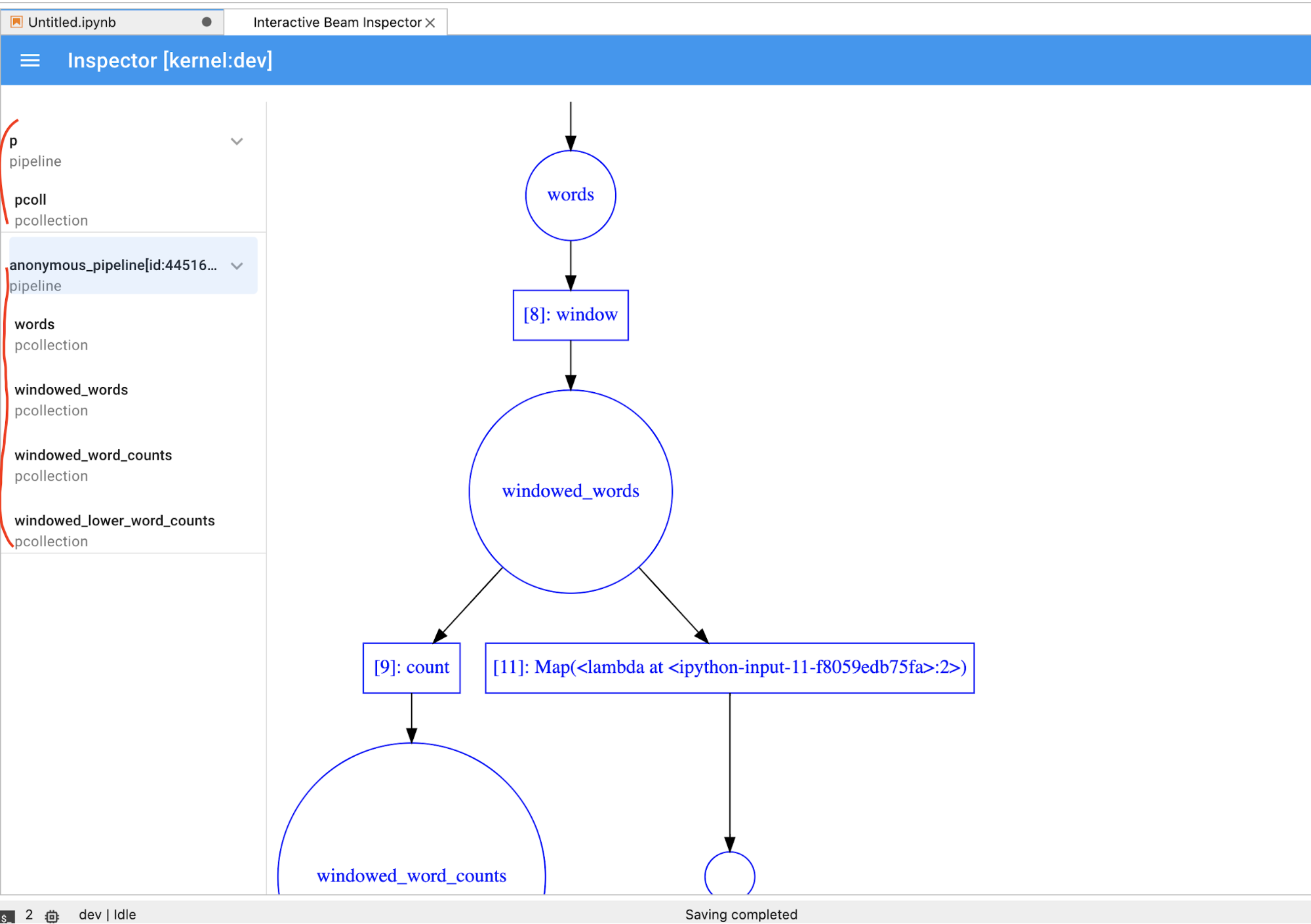
Vous remarquerez peut-être des pipelines anonymes. Ces pipelines comportent des PCollections auxquelles vous pouvez accéder, mais ils ne sont plus référencés par la session principale. Par exemple :
p = beam.Pipeline()
pcoll = p | beam.Create([1, 2, 3])
p = beam.Pipeline()
L'exemple précédent crée un pipeline vide p et un pipeline anonyme contenant un pcoll PCollection. Vous pouvez accéder au pipeline anonyme à l'aide de pcoll.pipeline.
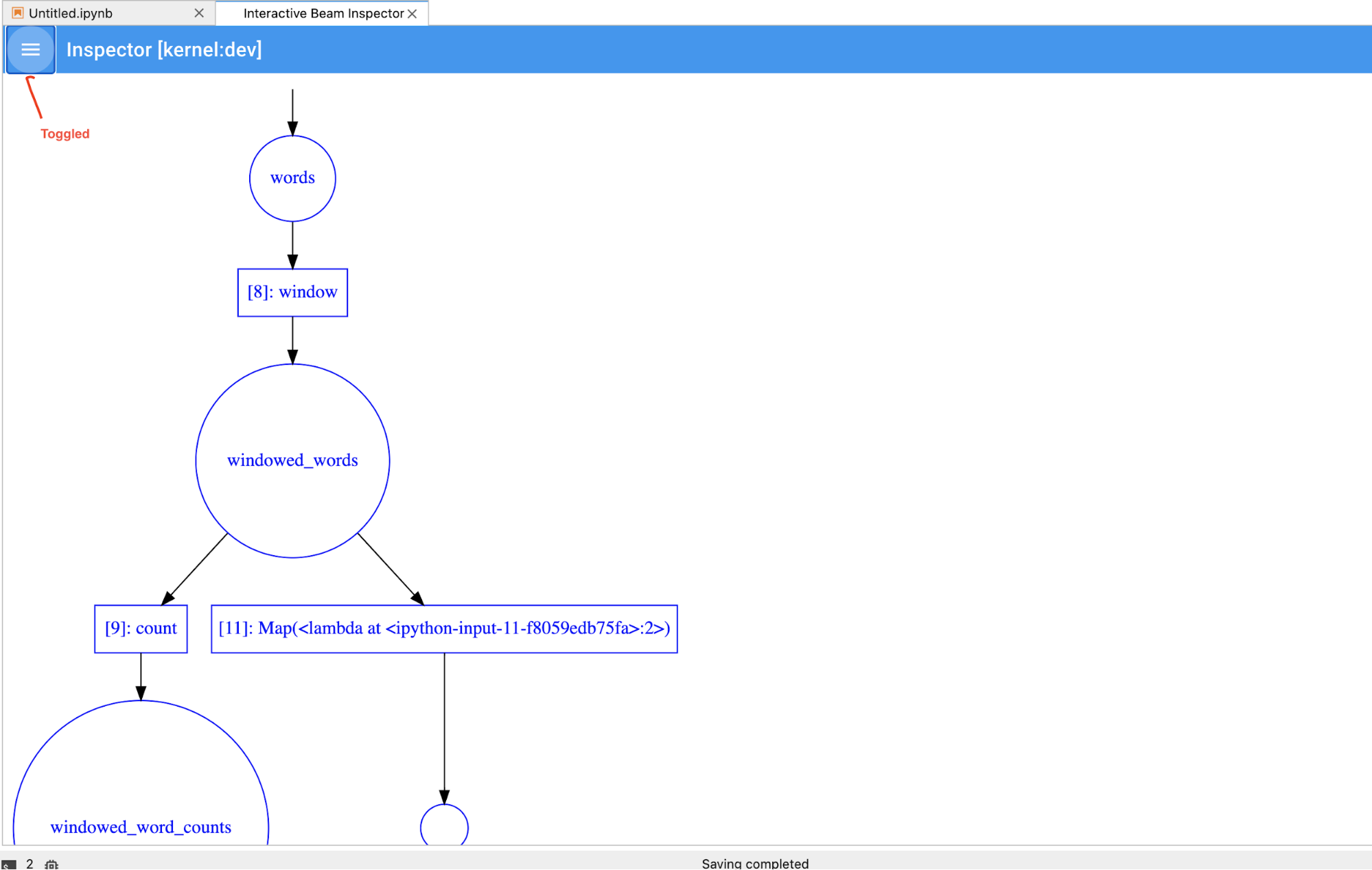
Vous pouvez activer/désactiver le pipeline et la liste PCollection pour économiser de l'espace pour les visualisations volumineuses.
Comprendre l'état d'enregistrement d'un pipeline
Outre les visualisations, vous pouvez également inspecter l'état d'enregistrement d'un pipeline ou de l'ensemble des pipelines de votre instance de notebook en appelant describe.
# Return the recording status of a specific pipeline. Leave the parameter list empty to return
# the recording status of all pipelines.
ib.recordings.describe(p)
La méthode describe() fournit les informations suivantes :
- Taille totale (en octets) de tous les enregistrements du pipeline sur le disque
- Heure de début du démarrage de la tâche d'enregistrement en arrière-plan (en secondes à partir de l'époque Unix)
- État actuel du pipeline de la tâche d'enregistrement en arrière-plan
- Variable Python pour le pipeline
Lancer des tâches Dataflow à partir d'un pipeline créé dans votre notebook
- Facultatif : Avant d'utiliser votre notebook pour exécuter des tâches Dataflow, redémarrez le noyau, réexécutez toutes les cellules et vérifiez le résultat. Si vous ignorez cette étape, les états masqués du notebook peuvent affecter le graphique de la tâche dans l'objet de pipeline.
- Activez l'API Dataflow.
Ajoutez la déclaration d'importation suivante :
from apache_beam.runners import DataflowRunnerTransmettez vos options de pipeline.
# Set up Apache Beam pipeline options. options = pipeline_options.PipelineOptions() # Set the project to the default project in your current Google Cloud # environment. _, options.view_as(GoogleCloudOptions).project = google.auth.default() # Set the Google Cloud region to run Dataflow. options.view_as(GoogleCloudOptions).region = 'us-central1' # Choose a Cloud Storage location. dataflow_gcs_location = 'gs://<change me>/dataflow' # Set the staging location. This location is used to stage the # Dataflow pipeline and SDK binary. options.view_as(GoogleCloudOptions).staging_location = '%s/staging' % dataflow_gcs_location # Set the temporary location. This location is used to store temporary files # or intermediate results before outputting to the sink. options.view_as(GoogleCloudOptions).temp_location = '%s/temp' % dataflow_gcs_location # If and only if you are using Apache Beam SDK built from source code, set # the SDK location. This is used by Dataflow to locate the SDK # needed to run the pipeline. options.view_as(pipeline_options.SetupOptions).sdk_location = ( '/root/apache-beam-custom/packages/beam/sdks/python/dist/apache-beam-%s0.tar.gz' % beam.version.__version__)Vous pouvez ajuster les valeurs des paramètres. Par exemple, vous pouvez remplacer la valeur
regionparus-central1.Exécutez le pipeline avec
DataflowRunner. Cette opération exécute votre tâche sur le service Dataflow.runner = DataflowRunner() runner.run_pipeline(p, options=options)pest un objet de pipeline issu de l'étape Créer votre pipeline.
Pour obtenir un exemple sur la façon d'exécuter cette conversion sur un notebook interactif, consultez le notebook "Nombre de mots Dataflow" de votre instance de notebook.
Vous pouvez également exporter votre notebook en tant que script exécutable, modifier le fichier .py généré à l'aide des étapes précédentes, puis déployer votre pipeline sur le service Dataflow.
Enregistrer votre notebook
Les notebooks que vous créez sont enregistrés en local dans votre instance de notebook en cours d'exécution. Si vous réinitialisez ou arrêtez l'instance de notebook pendant le développement, ces notebooks sont conservés tant qu'ils sont créés dans le répertoire /home/jupyter.
Toutefois, si une instance de notebook est supprimée, ces notebooks sont également supprimés.
Pour les conserver en vue d'une utilisation ultérieure, téléchargez-les localement sur votre poste de travail, enregistrez-les dans GitHub ou exportez-les dans un autre format de fichier.
Enregistrer votre notebook sur des disques persistants supplémentaires
Si vous souhaitez conserver votre travail, tel que les notebooks et les scripts sur différentes instances de notebook, vous pouvez les stocker sur un disque persistant.
Créez ou associez un disque persistant. Suivez les instructions pour utiliser
sshafin de vous connecter à la VM de l'instance de notebook et d'exécuter des commandes dans Cloud Shell ouvert.Notez le répertoire dans lequel le disque persistant est installé, par exemple
/mnt/myDisk.Modifiez les détails de la VM de l'instance de notebook pour ajouter une entrée à
Custom metadata: clécontainer-custom-params; valeur-v /mnt/myDisk:/mnt/myDisk.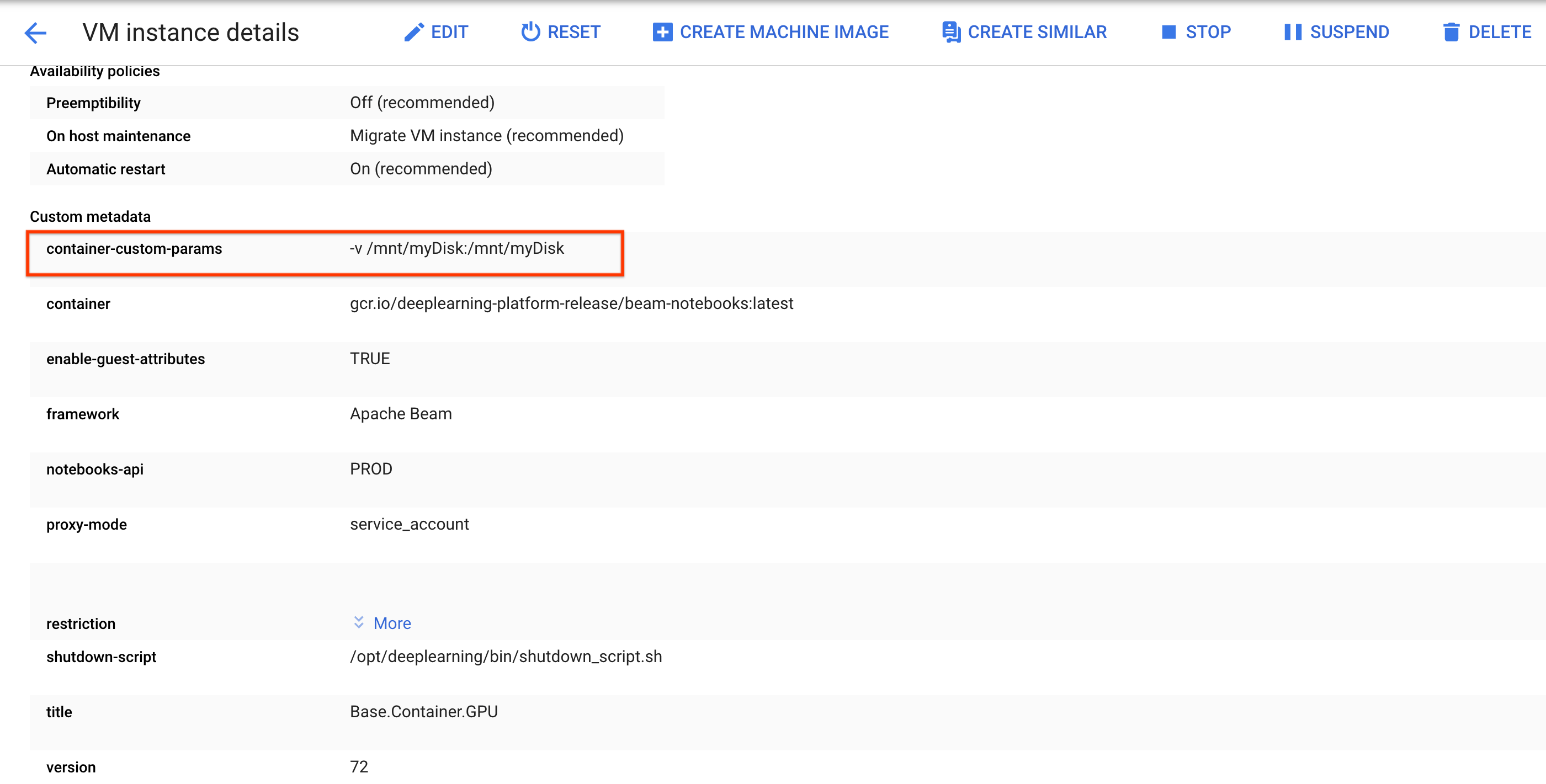
Cliquez sur Enregistrer.
Pour mettre à jour ces modifications, réinitialisez l'instance de notebook.
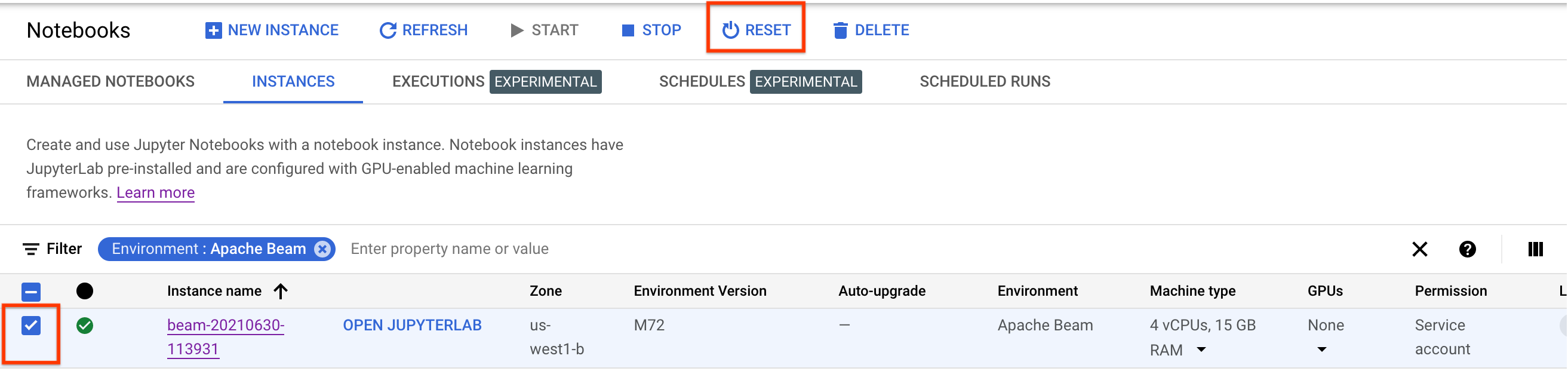
Après la réinitialisation, cliquez sur Open JupyterLab (Ouvrir JupyterLab). L'UI de JupyterLab peut prendre un certain temps à s'afficher. Une fois l'UI affichée, ouvrez un terminal et exécutez la commande suivante :
ls -al /mnt. Le répertoire/mnt/myDiskdoit être listé.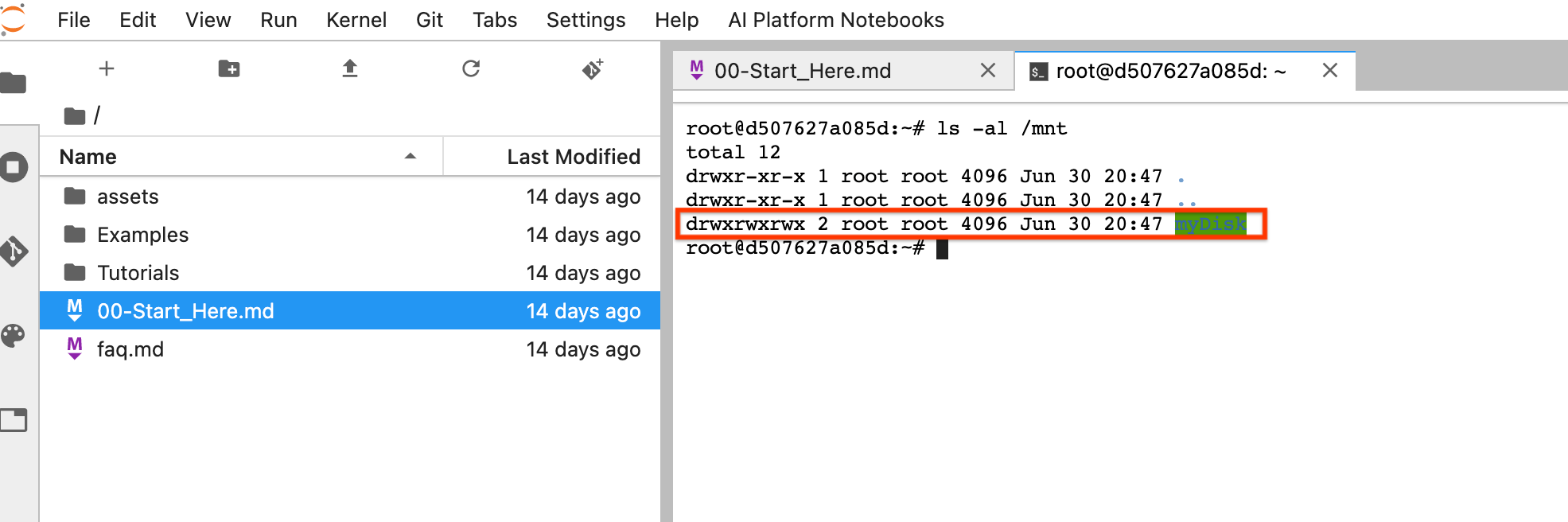
Vous pouvez maintenant enregistrer votre travail dans le répertoire /mnt/myDisk. Même si l'instance de notebook est supprimée, le disque persistant existe dans votre projet. Vous pouvez ensuite associer ce disque persistant à d'autres instances de notebook.
Effectuer un nettoyage
Une fois que vous avez fini d'utiliser votre instance de notebook Apache Beam, arrêtez l'instance de notebook pour nettoyer les ressources que vous avez créées sur Google Cloud.
Étapes suivantes
- Découvrez les fonctionnalités avancées que vous pouvez utiliser avec vos notebooks Apache Beam. Les fonctionnalités avancées incluent les workflows suivants :