In dieser Anleitung wird gezeigt, wie Sie eine wiederverwendbare Pipeline erstellen, die Daten aus Cloud Storage liest, Qualitätsprüfungen durchführt und in Cloud Storage schreibt.
Wiederverwendbare Pipelines haben eine reguläre Pipelinestruktur. Sie können jedoch die Konfiguration für jeden Pipelineknoten entsprechend den von einem HTTP-Server bereitgestellten Konfigurationen ändern. Beispielsweise kann eine statische Pipeline Daten aus Cloud Storage lesen, Transformationen anwenden und in eine BigQuery-Ausgabetabelle schreiben. Wenn Sie möchten, dass sich die Transformation und die BigQuery-Ausgabetabelle auf Grundlage der Cloud Storage-Datei ändern, die die Pipeline liest, erstellen Sie eine wiederverwendbare Pipeline.
Lernziele
- Verwenden Sie das Cloud Storage-Argument-Setter-Plug-in, damit die Pipeline bei jeder Ausführung verschiedene Eingaben lesen kann.
- Verwenden Sie das Cloud Storage-Argument-Setter-Plug-in, damit die Pipeline bei jeder Ausführung verschiedene Qualitätsprüfungen durchführen kann.
- Schreiben Sie die Ausgabedaten jeder Ausführung in Cloud Storage.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
- Cloud Data Fusion
- Cloud Storage
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Hinweise
- Melden Sie sich bei Ihrem Google Cloud-Konto an. Wenn Sie mit Google Cloud noch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Cloud Data Fusion, Cloud Storage, BigQuery, and Dataproc APIs aktivieren.
- Erstellen Sie eine Cloud Data Fusion-Instanz.
Cloud Data Fusion-Weboberfläche aufrufen
Wenn Sie Cloud Data Fusion verwenden, nutzen Sie sowohl die Google Cloud Console als auch die separate Cloud Data Fusion-Weboberfläche. In der Google Cloud Console können Sie ein Google Cloud Console-Projekt erstellen sowie Cloud Data Fusion-Instanzen erstellen und löschen. In der Weboberfläche von Cloud Data Fusion können Sie die Funktionen von Cloud Data Fusion über die verschiedenen Seiten wie Pipeline Studio oder Handler nutzen.
Öffnen Sie in der Google Cloud Console die Seite Instanzen.
Klicken Sie in der Spalte Aktionen für die Instanz auf den Link Instanz aufrufen. Die Weboberfläche von Cloud Data Fusion wird in einem neuen Browsertab geöffnet.
Cloud Storage Argument Setter-Plug-in bereitstellen
Rufen Sie in der Weboberfläche von Cloud Data Fusion die Seite Studio auf.
Klicken Sie im Menü Aktionen auf GCS Argument Setter.
Aus Cloud Storage lesen
- Rufen Sie in der Weboberfläche von Cloud Data Fusion die Seite Studio auf.
- Klicken Sie auf arrow_drop_down Quelle und wählen Sie Cloud Storage aus. Der Knoten für eine Cloud Storage-Quelle wird in der Pipeline angezeigt.
Klicken Sie im Cloud Storage-Knoten auf Eigenschaften.
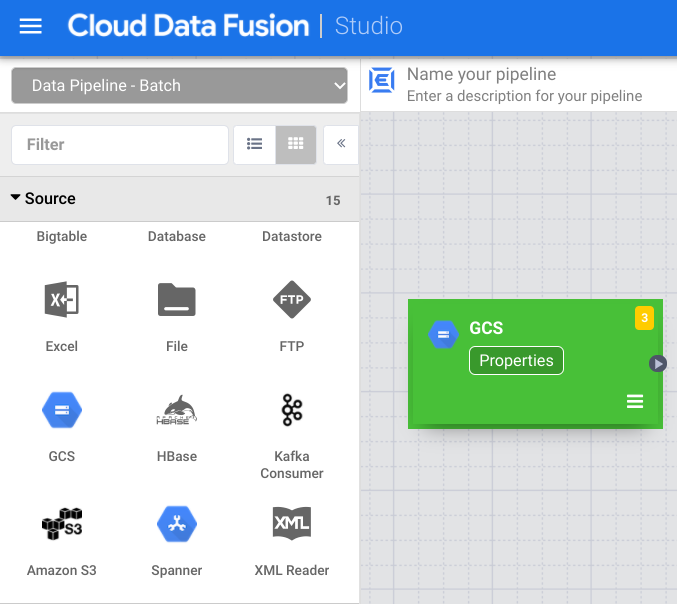
Geben Sie im Feld Referenzname einen Namen ein.
Geben Sie im Feld Pfad
${input.path}ein. Dieses Makro steuert, was der Cloud Storage-Eingabepfad in den verschiedenen Pipelineausführungen sein wird.Entfernen Sie im rechten Bereich "Ausgabeschema" das Feld offset aus dem Ausgabeschema. Klicken Sie dazu in der Zeile des Offset-Felds auf das Papierkorbsymbol.
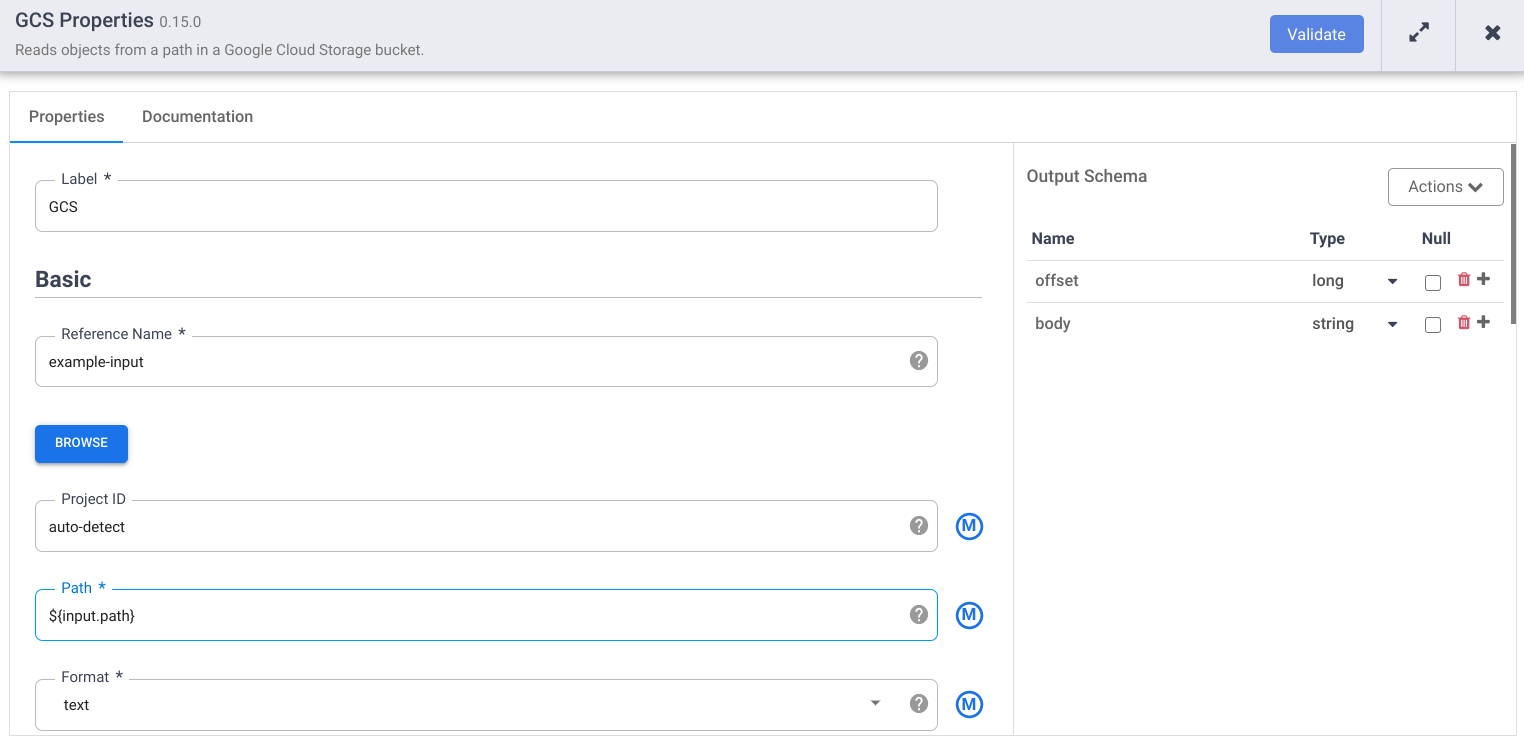
Klicken Sie auf Validieren und beheben Sie etwaige Fehler.
Klicken Sie auf , um das Dialogfeld Eigenschaften zu schließen.
Daten transformieren
- Rufen Sie in der Cloud Data Fusion-Weboberfläche auf der Seite Studio Ihre Datenpipeline auf.
- Wählen Sie im Drop-down-Menü Transform arrow_drop_down die Option Wrapperr aus.
- Ziehen Sie im Pipeline Studio-Canvas einen Pfeil vom Cloud Storage-Knoten auf den Wrapper-Knoten.
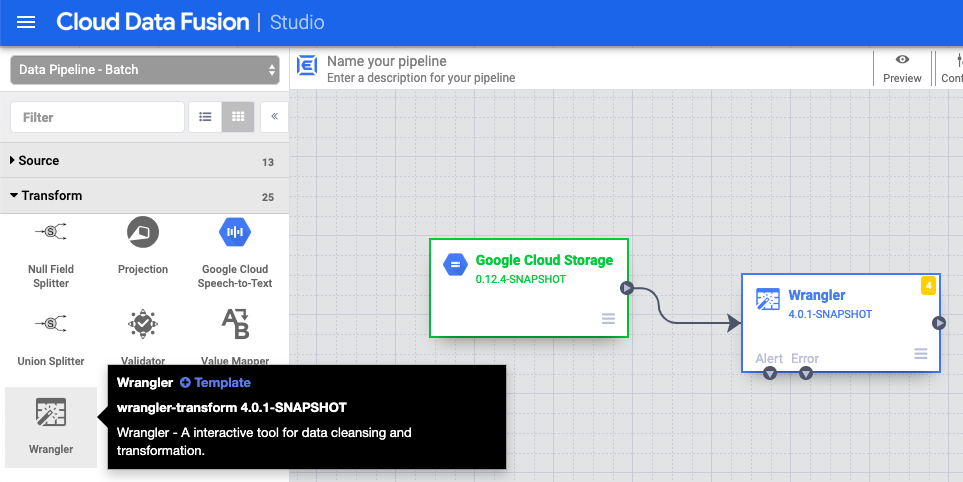
- Gehen Sie in der Pipeline zum Handler-Knoten und klicken Sie auf Eigenschaften.
- Geben Sie in das Feld Name des Eingabefelds
bodyein. - Geben Sie im Feld Schema den Wert
${directives}ein. Dieses Makro steuert, was die Transformationslogik in den verschiedenen Pipelineausführungen sein wird.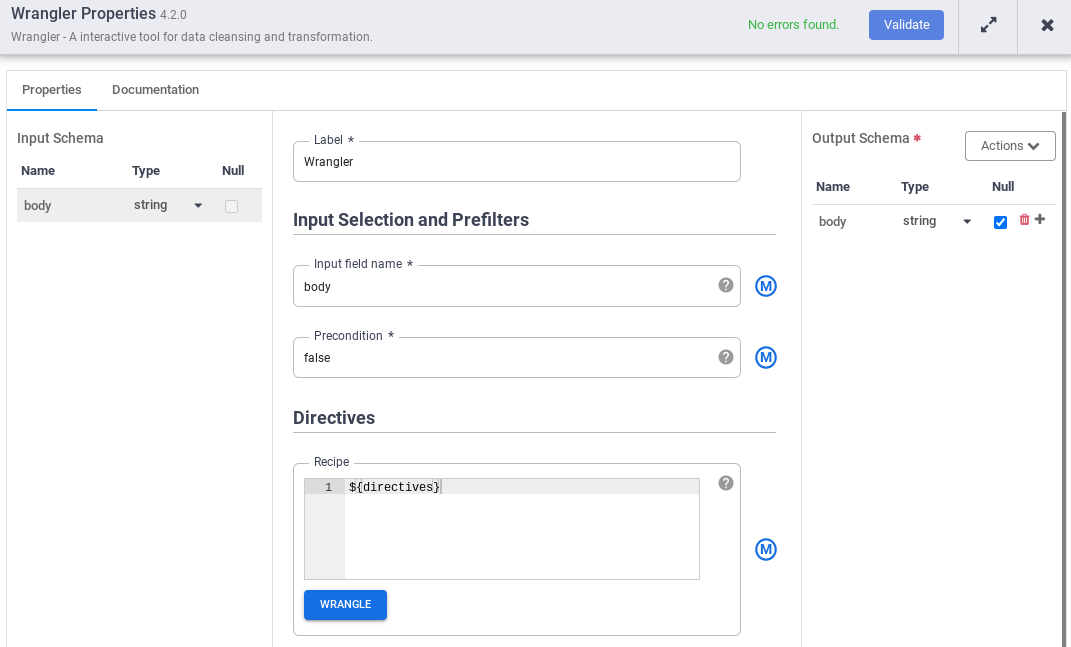
- Klicken Sie auf Validieren und beheben Sie etwaige Fehler.
- Klicken Sie auf , um das Dialogfeld Eigenschaften zu schließen.
In Cloud Storage schreiben
- Rufen Sie in der Cloud Data Fusion-Weboberfläche auf der Seite Studio Ihre Datenpipeline auf.
- Wählen Sie im Drop-down-Menü arrow_drop_down Senke die Option "Cloud Storage" aus.
- Ziehen Sie im Pipeline Studio-Canvas einen Pfeil vom Wrapper-Knoten auf den gerade hinzugefügten Cloud Storage-Knoten.
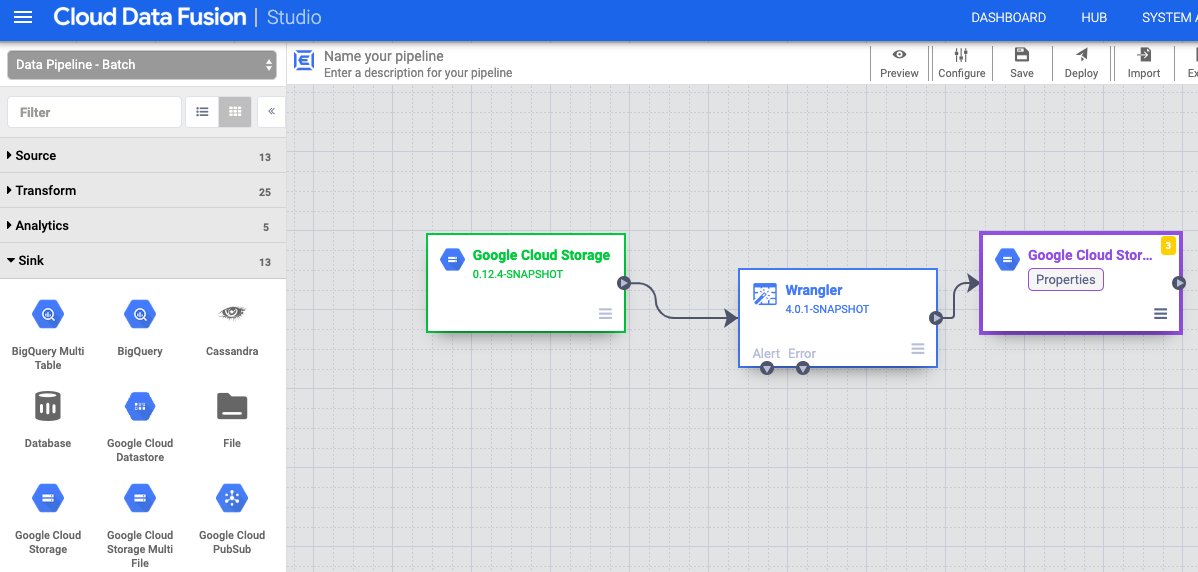
- Wechseln Sie zum Knoten der Cloud Storage-Senke in Ihrer Pipeline und klicken Sie auf Eigenschaften.
- Geben Sie im Feld Referenzname einen Namen ein.
- Geben Sie im Feld Pfad den Pfad eines Cloud Storage-Buckets in Ihrem Projekt ein, in den die Pipeline die Ausgabedateien schreiben kann. Wenn Sie keinen Cloud Storage-Bucket haben, erstellen Sie einen.
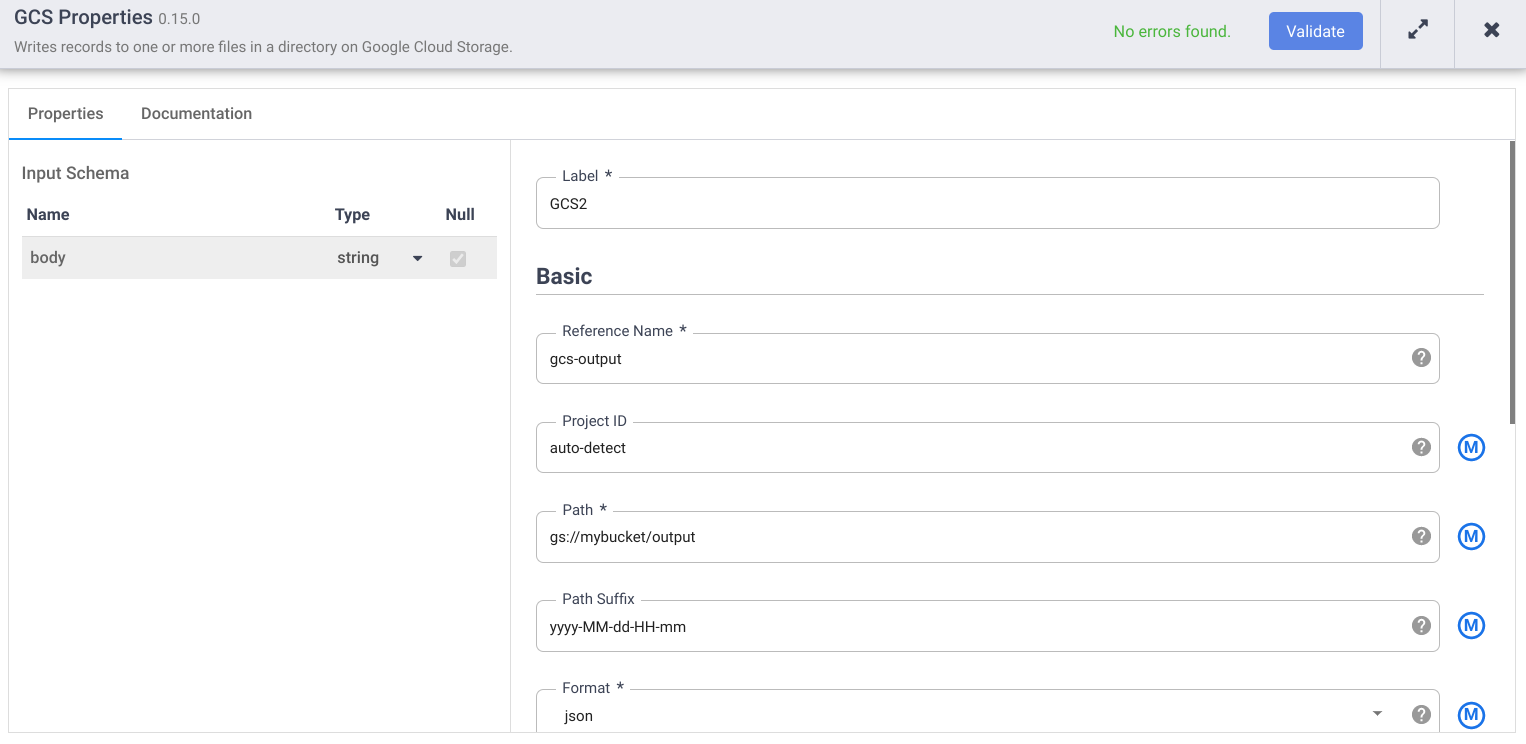
- Klicken Sie auf Validieren und beheben Sie etwaige Fehler.
- Klicken Sie auf , um das Dialogfeld Eigenschaften zu schließen.
Die Makroargumente festlegen
- Rufen Sie in der Cloud Data Fusion-Weboberfläche auf der Seite Studio Ihre Datenpipeline auf.
- Klicken Sie im Drop-down-Menü arrow_drop_down Bedingungen und Aktionen auf GCS-Argumentsatzer.
- Ziehen Sie im Pipeline Studio-Canvas einen Pfeil vom Knoten "Cloud Storage Argument Setter" zum Knoten Cloud Storage.
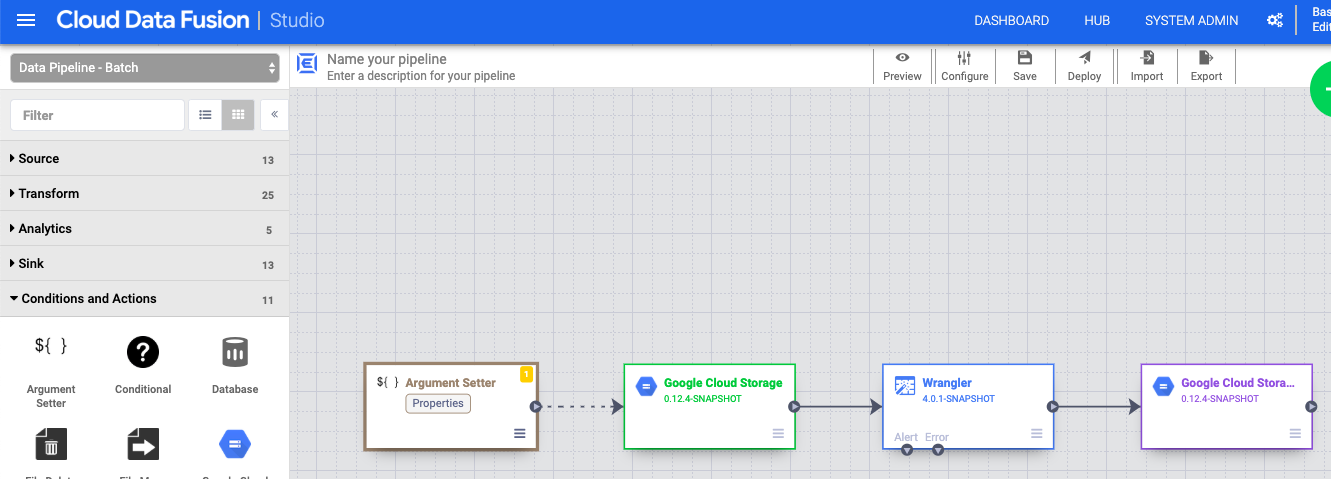
- Wechseln Sie in der Pipeline zum Knoten "Cloud Storage Argument Setter" und klicken Sie auf Eigenschaften.
Geben Sie im Feld URL die folgende URL ein:
gs://reusable-pipeline-tutorial/args.jsonDie URL entspricht einem öffentlich zugänglichen Objekt in Cloud Storage, das die folgenden Inhalte enthält:
{ "arguments" : [ { "name": "input.path", "value": "gs://reusable-pipeline-tutorial/user-emails.txt" }, { "name": "directives", "value": "send-to-error !dq:isEmail(body)" } ] }Das erste der beiden Argumente ist der Wert für
input.path. Der Pfadgs://reusable-pipeline-tutorial/user-emails.txtist ein öffentlich zugängliches Objekt in Cloud Storage, das die folgenden Testdaten enthält:alice@example.com bob@example.com craig@invalid@example.comDas zweite Argument ist der Wert für
directives. Mit dem Wertsend-to-error !dq:isEmail(body)wird Wrangler so konfiguriert, dass alle Zeilen herausgefiltert werden, die keine gültige E-Mail-Adresse sind. Beispiel:craig@invalid@example.comwird herausgefiltert.Klicken Sie auf Validieren, um sicherzustellen, dass keine Fehler vorliegen.
Klicken Sie auf , um das Dialogfeld Eigenschaften zu schließen.
Ihre Pipeline bereitstellen und ausführen
Klicken Sie in der oberen Leiste der Seite Pipeline Studio auf Pipeline benennen. Benennen Sie die Pipeline und klicken Sie auf Speichern.
Klicken Sie auf Bereitstellen.
Klicken Sie auf das Drop-down-Menü arrow_drop_down neben Ausführen, um die Laufzeitargumente zu öffnen und die Makroargumente (Laufzeit)
input.pathunddirectivesanzusehen.Lassen Sie die Wertefelder leer, um Cloud Data Fusion darüber zu informieren, dass der Cloud Storage-Argument-Setter-Knoten in der Pipeline die Werte dieser Argumente während der Laufzeit festlegt.
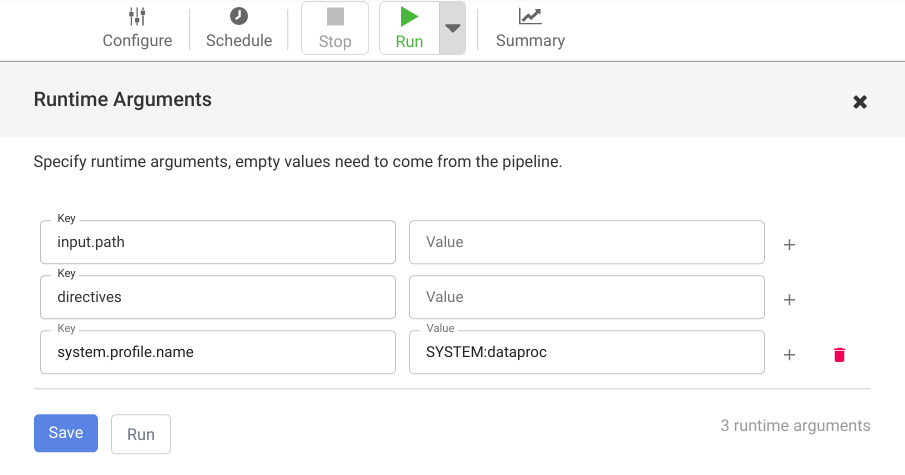
Klicken Sie auf Ausführen.
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
Nachdem Sie diese Anleitung abgeschlossen haben, bereinigen Sie die in Google Cloud erstellten Ressourcen, damit sie keine kostenpflichtigen Kontingente verbrauchen. In den folgenden Abschnitten erfahren Sie, wie Sie diese Ressourcen löschen oder deaktivieren.
Löschen Sie die Cloud Data Fusion-Instanz.
Folgen Sie der Anleitung zum Löschen Ihrer Cloud Data Fusion-Instanz.
Projekt löschen
Am einfachsten vermeiden Sie weitere Kosten durch Löschen des für die Anleitung erstellten Projekts.
So löschen Sie das Projekt:
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.
Nächste Schritte
- Anleitungen lesen
- Weiteres Tutorial durcharbeiten