Data Catalog アセット リネージの統合については、代わりに Dataplex でリネージを表示するをご覧ください。
Cloud Data Fusion のデータリネージ
Cloud Data Fusion のデータリネージを使用すると、次のことができます。
不正なデータイベントの根本原因を見つける。
データの変更を行う前に、影響分析を行う。
Cloud Data Fusion は、データセット レベルとフィールド レベルでリネージを提供し、時間の制約があり、時系列でリネージを表示します。
データセット レベルのリネージでは、選択された期間におけるデータセットとパイプラインの関係が表示されます。
フィールド レベルのリネージでは、ソース データセット内のフィールド セットに対して実行され、ターゲット データセット内に別のフィールド セットを生成するオペレーションが表示されます。
チュートリアルの事例
このチュートリアルでは、2 つのパイプラインを使用します。
Shipment Data Cleansingパイプラインは、小さなサンプル データセットから未加工の配送データを読み取り、変換を適用してデータをクリーンアップします。Delayed Shipments USAパイプラインは、クレンジングされた配送データを読み取り、分析して、しきい値を超えて遅延した米国内の配送を見つけます。
これらのチュートリアル パイプラインは、元データをクリーンアップしてから下流の処理へ送信する一般的なシナリオを示しています。元データから分析出力に対するクリーニングされた配送データまでのデータ証跡は、Cloud Data Fusion のリネージ機能を使用して探索できます。
目標
- サンプル パイプラインを実行してリネージを生成する
- データセット レベルとフィールド レベルのリネージを調べる
- ハンドシェイク情報をアップストリーム パイプラインからダウンストリーム パイプラインに渡す方法を学ぶ
費用
このドキュメントでは、Google Cloud の次の課金対象のコンポーネントを使用します。
- Cloud Data Fusion
- Cloud Storage
- BigQuery
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Data Fusion, Cloud Storage, Dataproc, and BigQuery APIs.
- Cloud Data Fusion インスタンスを作成します。
- 次のリンクをクリックして、これらの小さなサンプル データセットをローカルマシンにダウンロードします。
Cloud Data Fusion UI を開く
Cloud Data Fusion を使用する際は、Google Cloud コンソールと個別の Cloud Data Fusion UI の両方を使用します。Google Cloud コンソールでは、Google Cloud プロジェクトの作成、Cloud Data Fusion インスタンスの作成と削除を行うことができます。Cloud Data Fusion UI では、さまざまなページ(リネージなど)を使用して、Cloud Data Fusion の機能にアクセスできます。
Google Cloud コンソールで [インスタンス] ページを開きます。
インスタンスの [操作] 列で、[インスタンスの表示] リンクをクリックします。新しいブラウザタブで Cloud Data Fusion UI が開きます。
[統合] ペインで、[Studio] をクリックして Cloud Data Fusion の [Studio] ページを開きます。

パイプラインをデプロイして実行する
未加工の配送データをインポートします。[Studio] ページで、[インポート] をクリックするか、[+] > [パイプライン] > [インポート] をクリックしてから、始める前にでダウンロードした配送データ クレンジング パイプラインを選択してインポートします。

パイプラインをデプロイします。[スタジオ] ページの右上にある [デプロイ] をクリックします。デプロイ後、[パイプライン] ページが開きます。
パイプラインを実行します。[パイプライン] ページの中央上部にある [実行] をクリックします。
遅延配送データとパイプラインをインポート、デプロイ、実行します。配送データ クレンジングのステータスが [Succeeded] になった後、始める前にでダウンロードした、米国での遅延配送のデータに上述の手順を適用します。[Studio] ページに戻ってデータをインポートし、つづいて [Pipeline] ページからこの 2 つ目のパイプラインをデプロイして実行します。2 番目のパイプラインが正常に完了したら、残りの手順に進みます。
データセットを検出する
リネージを調べる前に、データセットを見つける必要があります。Cloud Data Fusion UI の左側のナビゲーション パネルで [メタデータ] を選択して、メタデータの [検索] ページを開きます。配送データ クレンジング データセットは、参照データセットとして「Cleaned-Shipments」を指定しているため、検索ボックスに「shipment」を挿入します。検索結果にはこのデータセットが含まれます。

タグを使用したデータセットを検出する
メタデータ検索では、Cloud Data Fusion パイプラインによって利用、処理、生成されたデータセットが検出されます。パイプラインは、テクニカル メタデータとオペレーション メタデータを生成して収集する構造化フレームワークで実行されます。テクニカル メタデータには、データセット名、タイプ、スキーマ、フィールド、作成時間、処理情報が含まれます。このテクニカル情報は、Cloud Data Fusion のメタデータ検索とリネージ機能で使用されます。
Cloud Data Fusion は、検索条件として使用できるタグや Key-Value プロパティなどのビジネス メタデータを含むデータセットのアノテーションもサポートしています。たとえば、未加工の配送データセットにビジネスタグ アノテーションを追加して検索するには、次を行います。
配送データ クレンジング パイプライン の 未加工の配送データノードの [プロパティ] ボタンをクリックして [Cloud Storage のプロパティ] ページを開きます。
[メタデータを表示] をクリックして [検索] ページを開きます。
[ビジネスタグ] で [+] をクリックし、タグ名(英数字とアンダースコアも使用可能)を入力して Enter キーを押します。

リネージを調べる
データセット レベルのリネージ
[検索] ページに表示されている [クリーンアップされた配送] のデータセット名をクリックし(データセットの検出から)、[Lineage] タブをクリックします。リネージグラフで、このデータセットが、Raw_Shipping_Data データセットを使用した配送データ クレンジング パイプラインによって生成されたことが示されます。

左右の矢印を使用すると、前後のデータセット リネージ間を移動できます。この例では、グラフに「クリーンアップされた配送」データセットの完全なリネージが表示されます。
フィールド レベルのリネージ
Cloud Data Fusion のフィールド レベルのリネージは、データセットのフィールドと、フィールド セットに実行して別のフィールド セットを生成する変換との間の関係を示します。データセット レベルのリネージと同様に、フィールド レベルのリネージには時間の制約があり、結果を時系列で変化します。
データセット レベルのリネージのステップから続けて、[クリーンアップされた配送] のデータセット レベルのリネージグラフの右上にある [フィールド レベルのリネージ] ボタンをクリックし、フィールド レベルのリネージグラフを表示します。
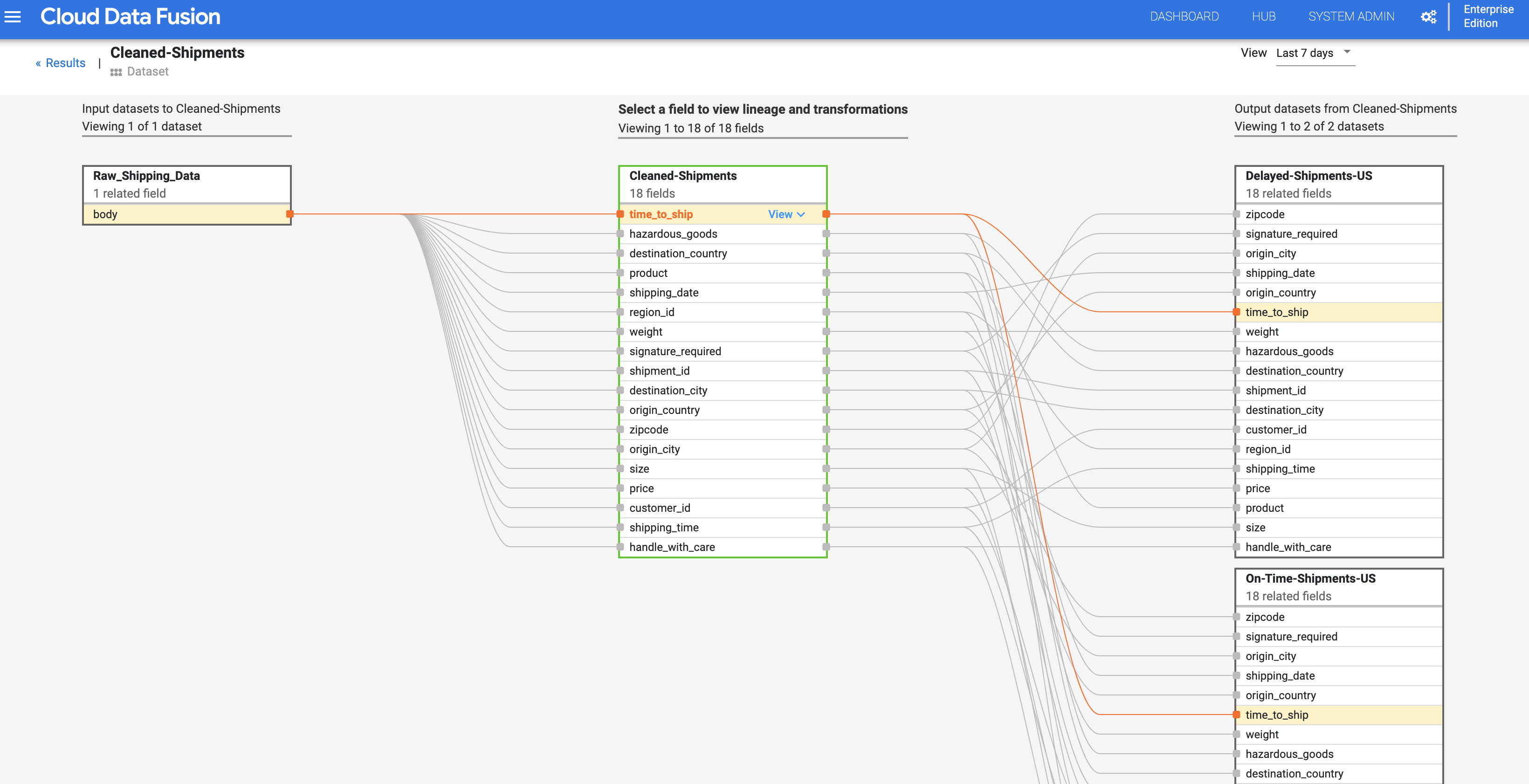
フィールド レベルのリネージグラフには、フィールド間の関係が表示されます。フィールドを選択して、そのリネージを表示できます。[表示] > [フィールドを固定] を選択して、そのフィールドのリネージのみを表示します。

[表示] > [影響を表示] を選択して、影響を分析します。

原因と影響を示すリンクでは、フィールドの両側で行われた変換が人間が読める台帳形式で表示されます。この情報は、レポートとガバナンスにおいて不可欠であることが考えられます。
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
チュートリアルを完了したら、Google Cloud で作成したリソースをクリーンアップし、以後は課金されないようにします。次のセクションで、このようなリソースを削除または無効にする方法を説明します。
チュートリアル データセットを削除する
このチュートリアルでは、プロジェクトに複数のテーブルを含む logistics_demo データセットを作成します。

Google Cloud コンソールの BigQuery ウェブ UI からデータセットを削除できます。
Cloud Data Fusion インスタンスを削除する
Cloud Data Fusion インスタンスを削除する手順に従います。
プロジェクトを削除する
課金をなくす最も簡単な方法は、チュートリアル用に作成したプロジェクトを削除することです。
プロジェクトを削除するには:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.