Nesta página, descrevemos como ler várias tabelas de um banco de dados do Microsoft SQL Server usando a origem Várias tabelas. Use a fonte de várias tabelas quando quiser que o pipeline leia a partir de várias tabelas. Se você quiser que o pipeline leia uma única tabela, consulte Como ler uma tabela do SQL Server.
A origem de várias tabelas gera dados com vários esquemas e inclui um campo de nome de tabela que indica a tabela de origem dos dados. Ao usar a origem de várias tabelas, use um dos coletores de várias tabelas, várias tabelas do BigQuery ou vários arquivos do GCS.
Antes de começar
- Faça login na sua conta do Google Cloud. Se você começou a usar o Google Cloud agora, crie uma conta para avaliar o desempenho de nossos produtos em situações reais. Clientes novos também recebem US$ 300 em créditos para executar, testar e implantar cargas de trabalho.
-
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud.
-
Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
-
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud.
-
Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
-
Ative as APIs Cloud Data Fusion, Cloud Storage, BigQuery, and Dataproc.
- Crie uma instância do Cloud Data Fusion.
- Verifique se o banco de dados do SQL Server pode aceitar conexões do Cloud Data Fusion. Para fazer isso com segurança, recomendamos que você crie uma instância particular do Cloud Data Fusion.
Ver sua instância do Cloud Data Fusion
Ao usar o Cloud Data Fusion, você usa o console do Google Cloud e a IU separada do Cloud Data Fusion. No console do Google Cloud, é possível criar um projeto do Google Cloud, além de criar e excluir instâncias do Cloud Data Fusion. Na IU do Cloud Data Fusion, é possível usar as várias páginas, como o Studio ou o Administrador, para usar os recursos do Cloud Data Fusion.
No console do Google Cloud, acesse a página do Cloud Data Fusion.
Para abrir a instância na interface da Web do Cloud Data Fusion, clique em Instâncias e depois em Ver instância.
Armazenar a senha do SQL Server como uma chave segura
Adicione a senha do SQL Server como uma chave segura para criptografar na instância do Cloud Data Fusion. Posteriormente neste guia, você garantirá que sua senha seja recuperada usando o Cloud KMS.
No canto superior direito de qualquer página do Cloud Data Fusion, clique em Administrador do sistema.
Clique na guia Configuration.
Clique em Fazer chamadas HTTP.

No menu suspenso, escolha PUT.
No campo do caminho, digite
namespaces/NAMESPACE_ID/securekeys/PASSWORD.No campo Corpo, digite
{"data":"SQL_SERVER_PASSWORD"}.Clique em Enviar.
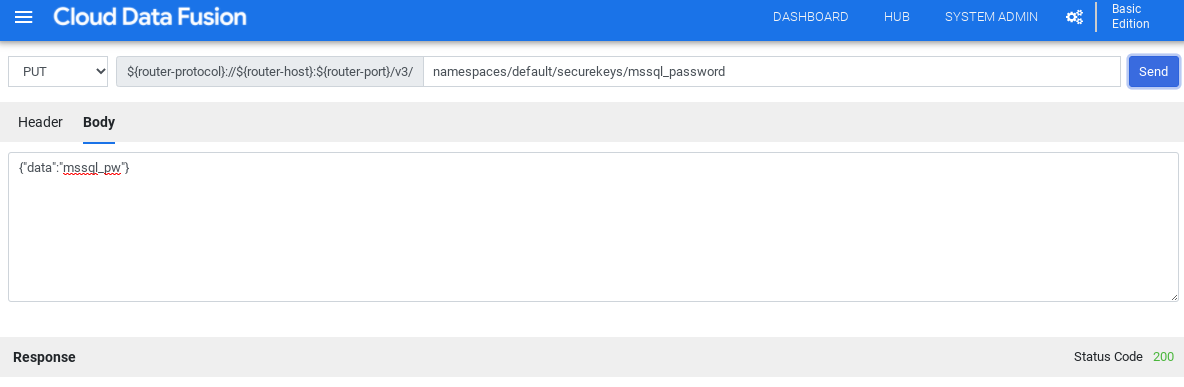
Verifique se a Resposta recebida é o código de status 200.
Acessar o driver JDBC para SQL Server
Como usar o Hub
Na IU do Cloud Data Fusion, clique em Hub.
Na barra de pesquisa, digite
Microsoft SQL Server JDBC Driver.Clique em Driver JDBC do Microsoft SQL Server.
Clique em Fazer download. Siga as etapas de download mostradas.
Selecione Implantar. Faça upload do arquivo JAR da etapa anterior.
Clique em Finish.
Como usar o Studio
Acesse Microsoft.com.
Escolha o download e clique em Fazer o download.
Na IU do Cloud Data Fusion, clique em Menu e navegue até a página do Studio.
Clique em Adicionar.
Em Driver, clique em Fazer upload.
Faça upload do arquivo JAR salvo na etapa 2.
Clique em Próxima.
Configure o driver inserindo um Nome.
No campo Class name, insira
com.microsoft.sqlserver.jdbc.SQLServerDriver.Clique em Finish.
Implante os plug-ins de várias tabelas
Na IU da Web do Cloud Data Fusion, clique em Hub.
Na barra de pesquisa, digite
Multiple table plugins.Clique em Múltiplos plug-ins de tabela.
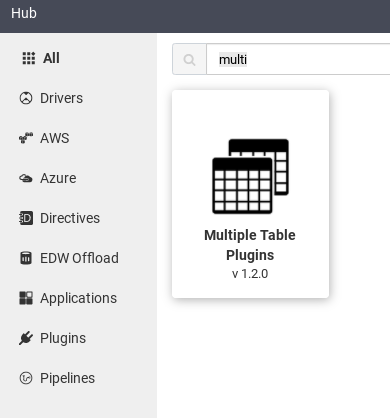
Selecione Implantar.
Clique em Concluir.
Clique em Criar um pipeline.
Conectar-se ao SQL Server
Na IU do Cloud Data Fusion, clique em Menu e navegue até a página do Studio.
No Studio, expanda o menu Origem.
Clique em Várias tabelas de banco de dados.
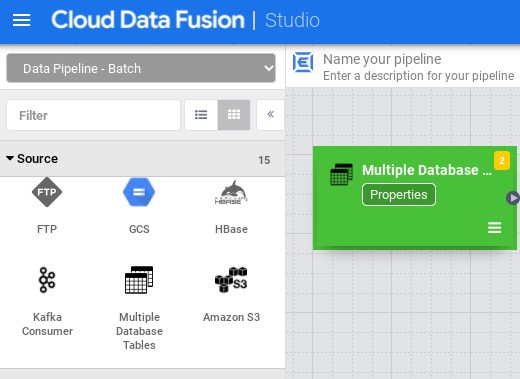
Coloque o ponteiro sobre o nó Várias tabelas de banco de dados e clique em Propriedades.
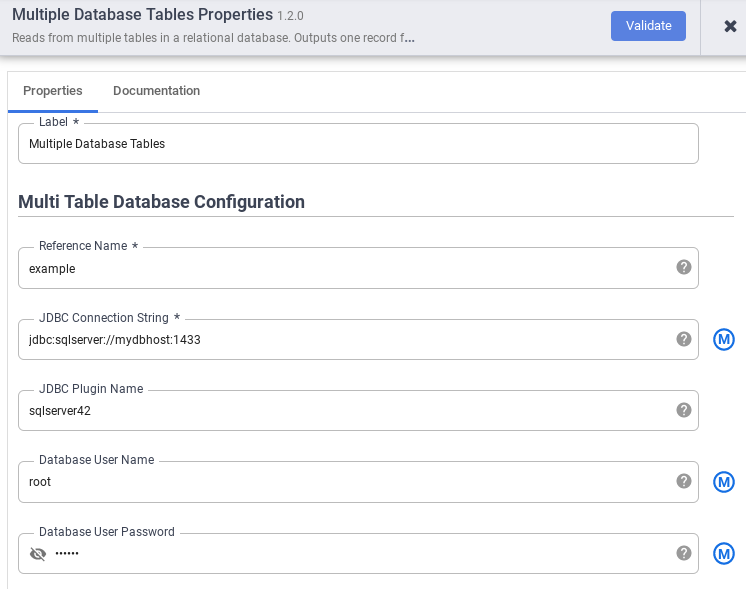
No campo Nome da referência, especifique um nome de referência que será usado para identificar a origem do SQL Server.
No campo String de conexão JDBC, insira a string de conexão JDBC. Por exemplo,
jdbc:sqlserver://mydbhost:1433. Para ver mais informações, consulte Como criar o URL de conexão.Digite o Nome do plug-in do JDBC, o Nome de usuário do banco de dados e a Senha do usuário do banco de dados.
Clique em Validate (Validar).
Clique em Fechar.
Conectar-se ao BigQuery ou ao Cloud Storage
Na IU do Cloud Data Fusion, clique em Menu e navegue até a página do Studio.
Expanda Coletor.
Clique em Várias tabelas do BigQuery ou Vários arquivos do GCS.
Conecte o nó Várias tabelas de banco de dados com Várias tabelas do BigQuery ou Vários arquivos do GCS.
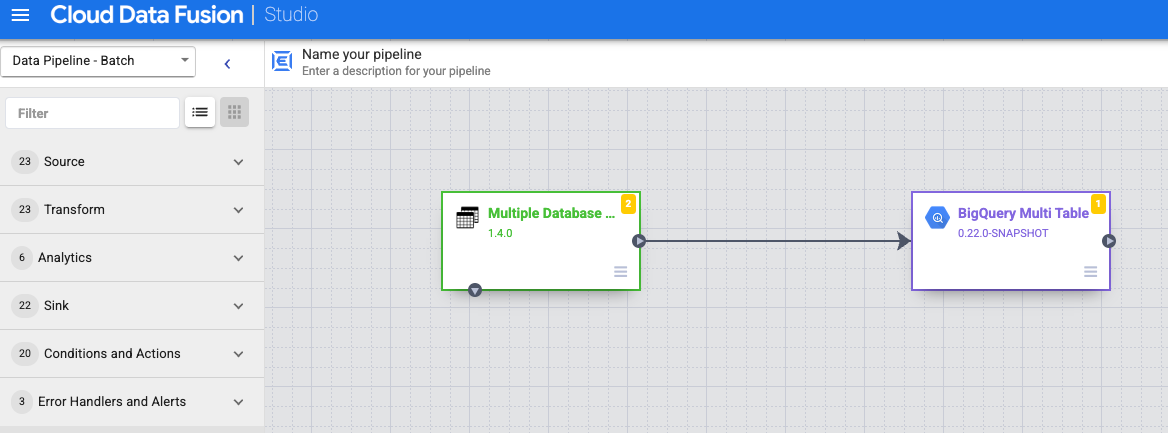
Mantenha o ponteiro do mouse sobre o nó Várias tabelas do BigQuery ou Vários arquivos do GCS, clique em Propriedades e configure o coletor.
Para mais informações, consulte Coletor de várias tabelas do Google BigQuery e Coletor de vários arquivos do Google Cloud Storage.
Clique em Validate (Validar).
Clique em Fechar.
Executar visualização do pipeline
Na IU do Cloud Data Fusion, clique em Menu e navegue até a página do Studio.
Clique em Visualização.
Clique em Executar. Aguarde a conclusão da visualização.
Implante o pipeline.
Na IU do Cloud Data Fusion, clique em Menu e navegue até a página do Studio.
Selecione Implantar.
execute o pipeline
Na IU do Cloud Data Fusion, clique em Menu.
Clique em Lista.
Clique no pipeline.
Na página de detalhes do pipeline, clique em Executar.
A seguir
- Saiba mais sobre o Cloud Data Fusion.
- Siga um dos tutoriais.