Nesta página, descrevemos como ler dados de um banco de dados PostgreSQL em uma instância do Cloud Data Fusion.
Antes de começar
- Crie uma instância do Cloud Data Fusion.
- Ative seu banco de dados PostgreSQL para aceitar conexões do Cloud Data Fusion. Para fazer isso com segurança, recomendamos que você use uma instância particular do Cloud Data Fusion.
Funções exigidas
Para ter as permissões necessárias para se conectar a um banco de dados PostgreSQL, peça ao administrador para conceder a você os seguintes papéis do IAM:
-
Trabalho do Dataproc (
roles/dataproc.worker) na conta de serviço do Dataproc no projeto que contém o cluster -
Executor do Cloud Data Fusion (
roles/datafusion.runner) na conta de serviço do Dataproc no projeto que contém o cluster -
Para usar o Cloud SQL sem o proxy do Cloud SQL Auth:
Cliente do Cloud SQL (
roles/cloudsql.client) no projeto que contém a instância do Cloud SQL
Para mais informações sobre como conceder papéis, consulte Gerenciar acesso.
Talvez você também consiga receber as permissões necessárias por meio de papéis personalizados ou outros papéis predefinidos.
Abrir sua instância no Cloud Data Fusion
No console do Google Cloud, acesse a página do Cloud Data Fusion.
Para abrir a instância na interface da Web do Cloud Data Fusion, clique em Instâncias e depois em Ver instância.
Armazenar a senha do PostgreSQL como uma chave segura
Digite sua senha do PostgreSQL como uma chave segura para criptografar na instância do Cloud Data Fusion. Para mais informações sobre chaves, consulte Cloud KMS.
Na IU do Cloud Data Fusion, clique em Administrador do sistema > Configuração.
Clique em Fazer chamadas HTTP.

No menu suspenso, escolha PUT.
No campo do caminho, digite
namespaces/default/securekeys/pg_password.No campo Corpo, digite
{"data":"POSTGRESQL_PASSWORD"}. SubstituaPOSTGRESQL_PASSWORDpela sua senha do PostgreSQL.Clique em Enviar.
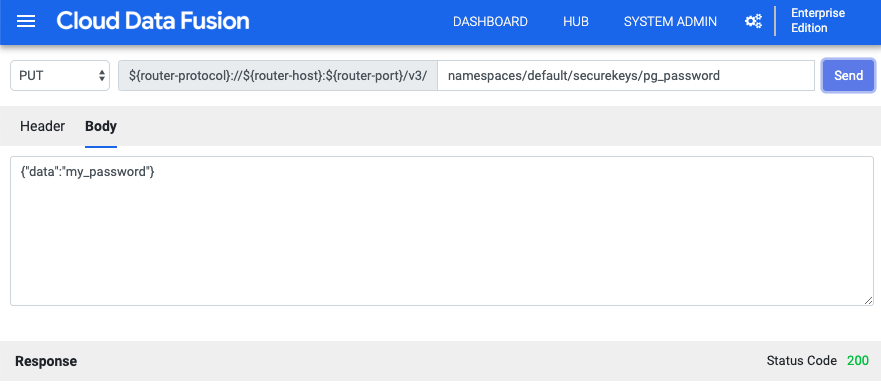
O campo Resposta notifica você sobre erros.
Conectar-se ao Cloud SQL para PostgreSQL
Na IU do Cloud Data Fusion, clique no menu menu e navegue até a página Administrador.
Clique em Adicionar conexão.
Escolha Database como o tipo de origem para se conectar.
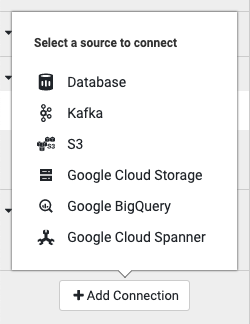
Em Google Cloud SQL para PostgreSQL, clique em Fazer upload.

Faça upload de um arquivo JAR que contenha o driver do PostgreSQL. Seu arquivo JAR precisa seguir o formato
NAME-VERSION.jar. Se o arquivo JAR não seguir esse formato, renomeie-o antes de fazer o upload.Clique em Próxima.
Digite o nome do driver, da classe e da versão nos campos.
Clique em Finish.
Na janela Adicionar conexão que é aberta, clique em Google Cloud SQL para PostgreSQL. Seu nome JAR aparecerá em Google Cloud SQL para PostgreSQL.

Preencha os campos de conexão obrigatórios. No campo Senha, selecione a chave segura armazenada anteriormente. Isso garante que sua senha seja recuperada usando o Cloud KMS.
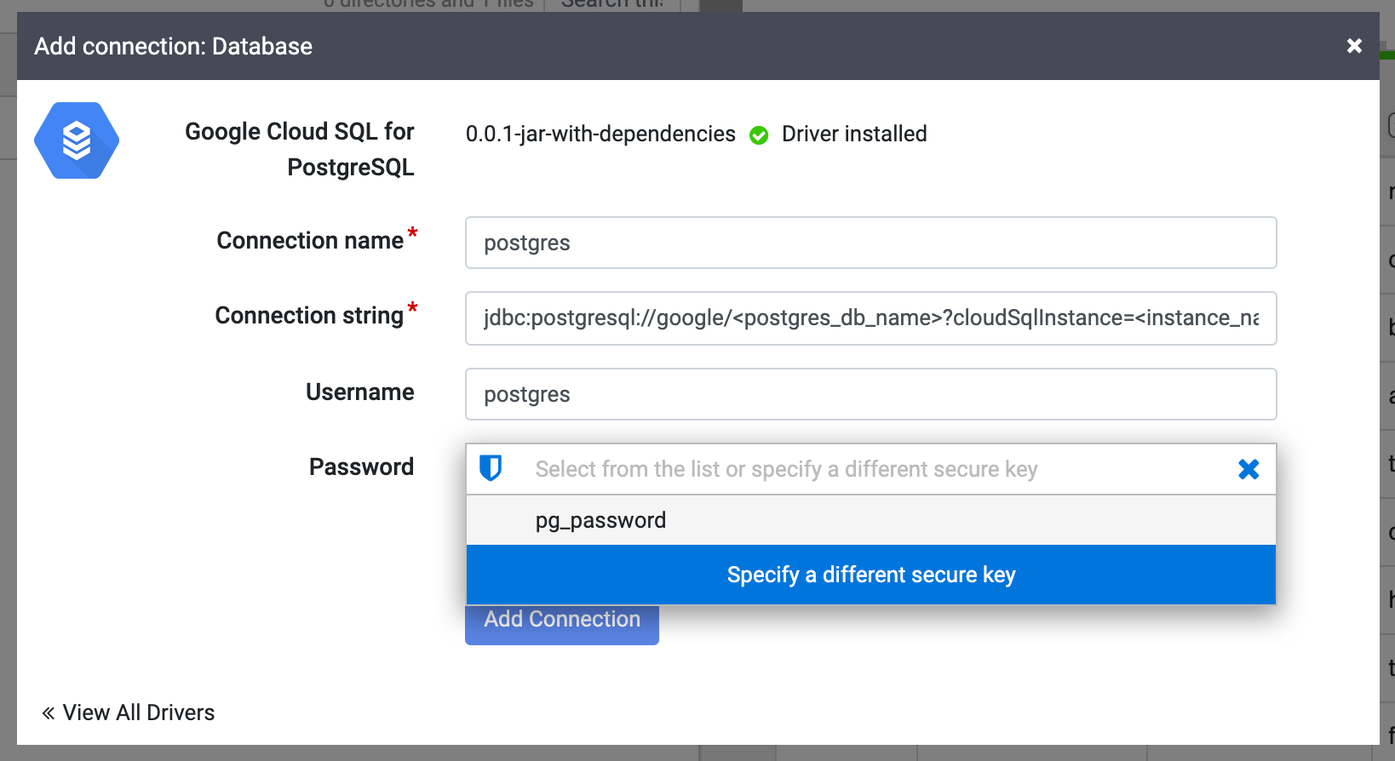
No campo String de conexão, insira sua string de conexão como:
jdbc:postgresql://google/DATABASE_NAME?cloudSqlInstance=INSTANCE_CONNECTION_NAME&socketFactory=com.google.cloud.sql.postgres.SocketFactory&useSSL=false
Substitua:
DATABASE_NAME: o nome do banco de dados do Cloud SQL listado na guia Bancos de dados da página de detalhes da instância.INSTANCE_CONNECTION_NAME: o nome da conexão da instância do Cloud SQL, conforme exibido na guia Visão geral da página de detalhes da instância.

Exemplo:
jdbc:postgresql://google/postgres?cloudSqlInstance=dis-demo:us-central1:pgsql-1&socketFactory=com.google.cloud.sql.postgres.SocketFactory&useSSL=false
Ative a API Cloud SQL Admin.
Clique em Testar conexão para garantir que a conexão possa ser estabelecida com o banco de dados.
Clique em Adicionar conexão.
Depois que o banco de dados do PostgreSQL estiver conectado, será possível aplicar transformações aos dados (no Wrangler), criar um pipeline e gravar a saída em um coletor (no Studio).