This page describes how to execute transformations to BigQuery instead of Spark in Cloud Data Fusion.
For more information, see the Transformation Pushdown overview.
Before you begin
Transformation Pushdown is available in version 6.5.0 and later. If your pipeline runs in an earlier environment, you can upgrade your instance to the latest version.
Enable Transformation Pushdown on your pipeline
Console
To enable Transformation Pushdown on a deployed pipeline, do the following:
Go to your instance:
In the Google Cloud console, go to the Cloud Data Fusion page.
To open the instance in the Cloud Data Fusion web interface, click Instances, and then click View instance.
Click Menu > List.
The deployed pipeline tab opens.
Click the desired deployed pipeline to open it in the Pipeline Studio.
Click Configure > Transformation Pushdown.
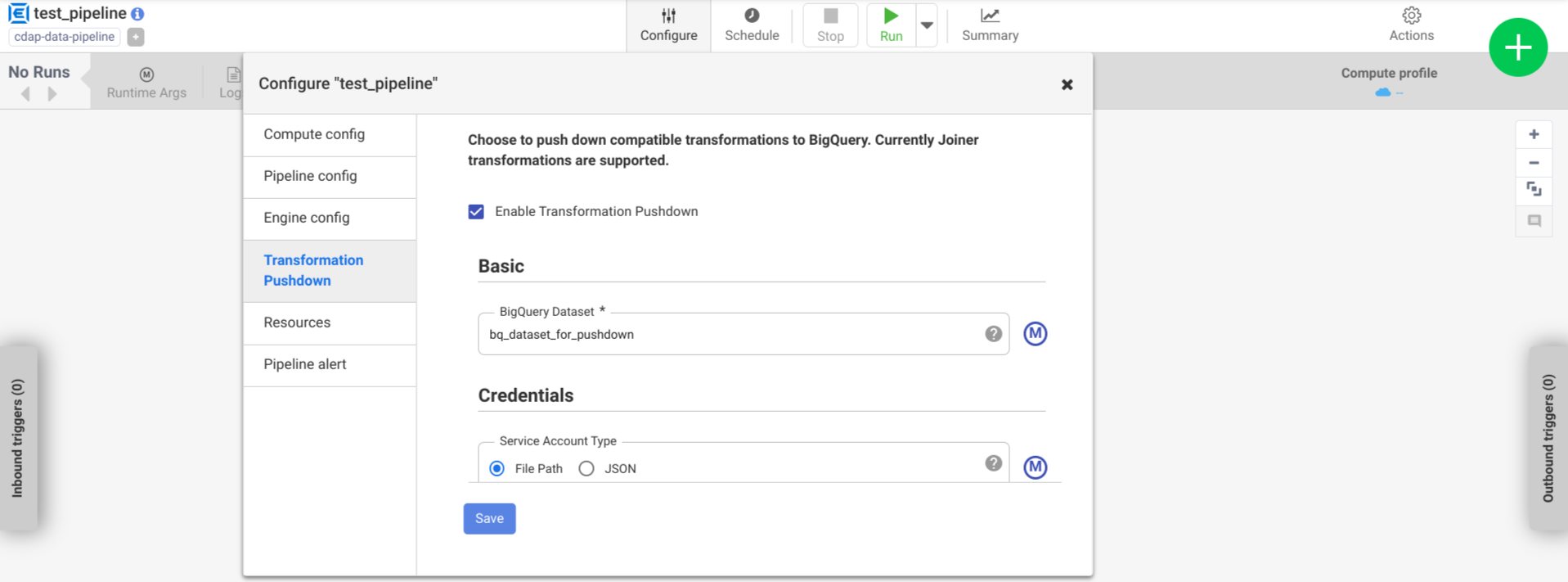
Click Enable Transformation Pushdown.
In the Dataset field, enter a BigQuery dataset name.
Optional: To use a macro, click M. For more information, see Datasets.
Optional: Configure the options, if needed.
Click Save.
Optional configurations
| Property | Supports macros | Supported Cloud Data Fusion versions | Description |
|---|---|---|---|
| Use connection | No | 6.7.0 and later | Whether to use an existing connection. |
| Connection | Yes | 6.7.0 and later | The name of the connection. This connection provides project and
service account information. Optional: Use the macro the function, ${conn(connection_name)}. |
| Dataset Project ID | Yes | 6.5.0 | If the dataset is in a different project than where the BigQuery job runs, enter the dataset's project ID. If no value is given, by default, it uses the project ID where the job runs. |
| Project ID | Yes | 6.5.0 | The Google Cloud project ID. | .
| Service Account Type | Yes | 6.5.0 | Select one of the following options:
|
| Service Account File Path | Yes | 6.5.0 | The path on the local file system to the service account key used
for authorization. It's set to auto-detect when running
on a Dataproc cluster. When running on other clusters,
the file must be present on every node in the cluster. The default is
auto-detect. |
| Service Account JSON | Yes | 6.5.0 | The content of the service account JSON file. |
| Temporary Bucket Name | Yes | 6.5.0 | The Cloud Storage bucket that stores the temporary data. It's automatically created if it doesn't exist, but it's not automatically deleted. The Cloud Storage data gets deleted after it gets loaded into BigQuery. If this value isn't provided, a unique bucket is created and then deleted after the pipeline run finishes. The service account must have permission to create buckets in the configured project. |
| Location | Yes | 6.5.0 | The location where the BigQuery dataset is created.
This value is ignored if the dataset or temporary bucket already
exists. The default is the
US
multi-region. |
| Encryption Key Name | Yes | 6.5.1/0.18.1 | The customer-managed encryption key (CMEK) that encrypts data written to any bucket, dataset, or table created by the plugin. If the bucket, dataset, or table already exists, this value is ignored. |
| Retain BigQuery Tables after Completion | Yes | 6.5.0 | Whether to retain all BigQuery temporary tables that are created during the pipeline run for debugging and validation purposes. The default is No. |
| Temporary Table TTL (in hours) | Yes | 6.5.0 | Set table TTL for BigQuery temporary tables, in
hours. This is useful as a failsafe in case the pipeline is
canceled and the cleanup process is interrupted (for example, if
the execution cluster is shut down abruptly). Setting this value to
0 disables the table TTL. The default is
72 (3 days). |
| Job Priority | Yes | 6.5.0 | The priority used to execute BigQuery jobs. Select
one of the following options:
|
| Stages to force pushdown | Yes | 6.7.0 | Supported stages to always execute in BigQuery. Each stage name must be on a separate line. |
| Stages to skip pushdown | Yes | 6.7.0 | Supported stages to never execute in BigQuery. Each stage name must be on a separate line. |
| Use BigQuery Storage Read API | Yes | 6.7.0 | Whether to use the BigQuery Storage Read API when extracting records from BigQuery during pipeline execution. This option can improve the performance of Transformation Pushdown, but incurs additional costs. This requires Scala 2.12 to be installed in the execution environment. |
Monitor performance changes in the logs
The pipeline runtime logs include messages that show the SQL queries that are run in BigQuery. You can monitor which stages in the pipeline get pushed into BigQuery.
The following example shows the log entries when pipeline execution begins. The
logs indicate that the JOIN operations in your pipeline have been pushed down
BigQuery for execution:
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'Users' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'Users'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'UserPurchases' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'Purchases'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'UserPurchases'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'MostPopularNames' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'FirstNameCounts'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'MostPopularNames'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@193] - Starting pull for dataset 'MostPopularNames'
The following example shows the table names that will be assigned for each of the datasets involved in the pushdown execution:
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset Purchases stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserDetails stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset FirstNameCounts stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserProfile stored in table <TABLE_ID>
As the execution continues, the logs show the completion of push stages, and
eventually the execution of JOIN operations. For example:
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@235] - Executing join operation for dataset Users
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@118] - Creating table `<TABLE_ID>` using job: <JOB_ID> with SQL statement: SELECT `UserDetails`.id AS `id` , `UserDetails`.first_name AS `first_name` , `UserDetails`.last_name AS `last_name` , `UserDetails`.email AS `email` , `UserProfile`.phone AS `phone` , `UserProfile`.profession AS `profession` , `UserProfile`.age AS `age` , `UserProfile`.address AS `address` , `UserProfile`.score AS `score` FROM `your_project.your_dataset.<DATASET_ID>` AS `UserProfile` LEFT JOIN `your_project.your_dataset.<DATASET_ID>` AS `UserDetails` ON `UserProfile`.id = `UserDetails`.id
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@151] - Created BigQuery table `<TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@245] - Executed join operation for dataset Users
When all stages have completed, a message shows that the Pull operation has
been completed. This indicates that the BigQuery export process
has been triggered and records will start being read into the pipeline after
this export job begins. For example:
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@196] - Completed pull for dataset 'MostPopularNames'
If the pipeline execution encounters errors, they are described in the logs.
For details about the execution of the BigQuery JOIN
operations, such as resource utilization, execution time, and error causes, you
can view the BigQuery Job data using the Job ID, which appears in
the job logs.
Review pipeline metrics
For more information about the metrics that Cloud Data Fusion provides for the part of the pipeline that's executed in BigQuery, see BigQuery pushdown pipeline metrics.
What's next
- Learn more about Transformation Pushdown in Cloud Data Fusion.