En esta página, se proporciona información de segundo plano sobre la conexión a tus fuentes de datos desde instancias públicas o privadas de Cloud Data Fusion desde entornos de diseño y ejecución.
Antes de comenzar
Las Herramientas de redes en Cloud Data Fusion requieren conocimientos básicos de lo siguiente:
Proyecto de inquilino
Cloud Data Fusion crea un proyecto de usuario que contiene los recursos y servicios necesarios para administrar canalizaciones en tu nombre, como cuando ejecuta canalizaciones en los clústeres de Dataproc que se encuentran en tu proyecto de cliente.
El proyecto de usuario no se expone directamente, pero cuando
creas una instancia privada, debes usar el nombre del proyecto para configurar el intercambio de tráfico de
VPC. Cada instancia privada en el proyecto de usuario tiene su propia
red de VPC y subred.
El proyecto puede tener varias instancias de Cloud Data Fusion. Tú
administras los recursos y servicios que contiene cuando accedes a una instancia en
la IU de Cloud Data Fusion o Google Cloud CLI.
Para obtener más información, consulta la documentación de Service Infrastructure sobre proyectos de usuario.
Proyecto de cliente
El cliente crea y posee este proyecto. Según la configuración predeterminada, Cloud Data Fusion crea un clúster de Dataproc efímero en este proyecto para ejecutar tus canalizaciones.
Instancia de Cloud Data Fusion
Una instancia de Cloud Data Fusion es una implementación única de Cloud Data Fusion, en la que diseñas y ejecutas canalizaciones. Puedes crear varias instancias en un solo proyecto y especificar la región de Google Cloud en la que se crearán las instancias de Cloud Data Fusion. Según tus requisitos y restricciones de costos, puedes crear una instancia que use la edición Developer, Basic o Enterprise de Cloud Data Fusion. Cada instancia contiene una implementación independiente y única de Cloud Data Fusion que contiene un conjunto de servicios que controlan la administración del ciclo de vida de la canalización, la organización, la coordinación y la administración de metadatos. Estos servicios se ejecutan con recursos de larga duración en un proyecto de usuario.
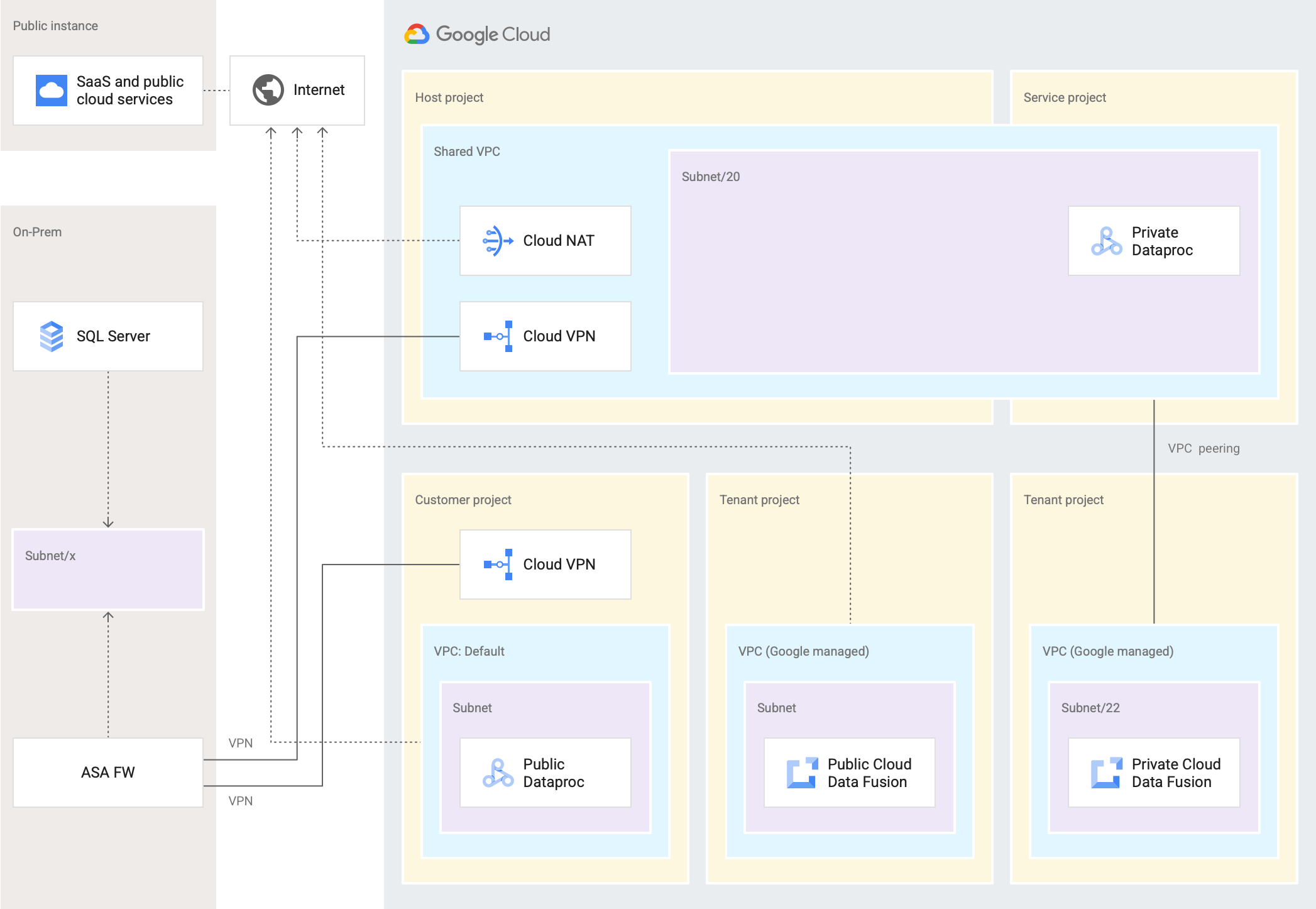
Diagrama de red
En el siguiente diagrama, se muestran las conexiones cuando compilas canalizaciones de datos que extraen, transforman, combinan, agregan y cargan datos de varias fuentes de datos locales y en la nube.
En Cloud Data Fusion 6.4 y versiones posteriores, consulta los diagramas para controlar la salida en una instancia privada y conectarse a una fuente pública.
Para las versiones anteriores a la 6.4, en el siguiente diagrama de arquitectura del sistema, se muestra cómo Cloud Data Fusion se conecta con fuentes de datos de servicios como Preview o Wrangler en un proyecto de usuario y Dataproc en un proyecto de cliente.
Diseño y ejecución de canalizaciones
Cloud Data Fusion proporciona una separación de los entornos de diseño y ejecución, lo que te permite diseñar una canalización una vez y, luego, ejecutarla en varios entornos. El entorno de diseño reside en el proyecto de usuario, mientras que el entorno de ejecución se encuentra en uno o más proyectos de clientes.
Ejemplo: Diseña tu canalización con los servicios de Cloud Data Fusion, como Wrangler y Preview. Esos servicios se ejecutan en el proyecto de usuario, en el que la función de agente de servicio de Cloud Data Fusion administrada por Google controla el acceso a los datos. Luego, ejecuta la canalización en tu proyecto de cliente para que use tu clúster de Dataproc. En el proyecto del cliente, la cuenta de servicio predeterminada de Compute Engine controla el acceso a los datos. Puedes configurar tu proyecto para que use una cuenta de servicio personalizada.
Para obtener más información sobre la configuración de cuentas de servicio, consulta cuentas de servicio de Cloud Data Fusion.
Entorno de diseño
Cuando creas una instancia de Cloud Data Fusion en tu proyecto de cliente, Cloud Data Fusion crea automáticamente un proyecto de usuario independiente administrado por Google a fin de ejecutar los servicios necesarios para administrar el ciclo de vida de las canalizaciones y los metadatos, la IU de Cloud Data Fusion y las herramientas de diseño como Vista previa y Wrangler.
Resolución de DNS en Cloud Data Fusion
Para resolver los nombres de dominio en tu entorno de diseño cuando derivas y obtienes una vista previa de los datos que transfieres a Google Cloud, usa el intercambio de tráfico de DNS (disponible a partir de Cloud Data Fusion 6.7.0). Te permite usar nombres de dominio o de host para fuentes y receptores, que no necesitas volver a configurar con tanta frecuencia como las direcciones IP.
Se recomienda la resolución de DNS en tu entorno de diseño en Cloud Data Fusion, cuando pruebas conexiones y canalizaciones de vista previa que usan nombres de dominio de servidores locales o de otros servidores (como bases de datos o servidores FTP), en una red de VPC privada.
Para obtener más información, consulta Intercambio de tráfico de DNS y Reenvío de Cloud DNS.
Entorno de ejecución
Después de verificar e implementar tu canalización en una instancia, ejecuta la canalización de forma manual o según un programa de tiempo o un activador de estado de la canalización.
Ya sea que Cloud Data Fusion o el cliente aprovisionen y administren el entorno de ejecución, el entorno existe en tu proyecto de cliente.
Instancias públicas (opción predeterminada)
La forma más fácil de aprovisionar una instancia de Cloud Data Fusion es crear una instancia pública. Sirve como punto de partida y proporciona acceso a extremos externos en la Internet pública.
Una instancia pública en Cloud Data Fusion usa la red de VPC predeterminada del proyecto.
La red de VPC predeterminada tiene las siguientes características:
- Subredes generadas automáticamente para cada región
- Enruta tablas
- Reglas de firewall para garantizar la comunicación entre tus recursos de procesamiento
Herramientas de redes entre regiones
Cuando creas un proyecto nuevo, un beneficio de la red de VPC predeterminada es que propaga de forma automática una subred por región con un rango de direcciones IP predefinido, expresado como un bloque CIDR. Los rangos de direcciones IP comienzan con 10.128.0.0/20, 10.132.0.0/20, en todas las regiones globales de Google Cloud.
Para garantizar que tus recursos de procesamiento se conecten entre sí en todas las regiones, la red de VPC predeterminada establece las rutas locales predeterminadas para cada subred. Cuando configuras la ruta predeterminada a Internet (0.0.0.0/0), obtienes acceso a Internet y capturas el tráfico de red sin enrutar.
Reglas de firewall
La red de VPC predeterminada proporciona un conjunto de reglas de firewall:
| Predeterminada | Descripción |
|---|---|
Permite de forma predeterminada icmp |
Habilita el protocolo icmp para 0.0.0.0/0 de destino |
| Default allow internal | Habilitar tcp:0-65535; udp:0-65535; icmp para la fuente 10.128.0.0/9, que abarca 10.128.0.1 como mínimo y hasta 10.255.255.254 direcciones IP como máximo |
Permite de forma predeterminada rdp |
Habilita tcp:3389 para 0.0.0.0/0 de destino |
Permite de forma predeterminada ssh |
Habilita tcp:22 para 0.0.0.0/0 de destino |
Esta configuración predeterminada de la red de VPC minimiza los requisitos para configurar servicios de nube, incluido Cloud Data Fusion. Debido a preocupaciones sobre la seguridad de la red, las organizaciones no suelen permitirte usar la red de VPC predeterminada para las operaciones comerciales. Sin la red de VPC predeterminada, no puedes crear una instancia pública de Cloud Data Fusion. En su lugar, crea una instancia privada.
La red de VPC predeterminada no otorga acceso abierto a los recursos. En cambio, Identity and Access Management (IAM) controla el acceso:
- Se requiere una identidad validada para acceder a Google Cloud.
- Después de acceder, necesitas un permiso explícito (por ejemplo, la función de visualizador) para ver los servicios de Google Cloud.
Instancias privadas
Algunas organizaciones requieren que todos sus sistemas de producción estén aislados de las direcciones IP públicas. Una instancia privada de Cloud Data Fusion cumple con ese requisito en todo tipo de configuración de red de VPC.
Instancias privadas en la versión 6.4 y anteriores
En las versiones de Cloud Data Fusion anteriores a la 6.4, los entornos de diseño y ejecución solo usan direcciones IP internas. No usan direcciones IP de Internet públicas conectadas a ninguna Compute Engine de Cloud Data Fusion. Como herramienta de diseño, la instancia privada de Cloud Data Fusion no puede acceder a las fuentes de datos en la Internet pública.
En cambio, diseña la canalización en una instancia pública. Luego, para la ejecución, muévela a una instancia privada en un proyecto de cliente, en la que controlas las políticas de VPC del proyecto. Debes conectarte a tus datos desde ambos proyectos.
Acceso a los datos en entornos de diseño y ejecución
En una instancia pública, la comunicación de red se realiza a través de Internet abierta, lo que no se recomienda para entornos críticos. Para acceder de forma segura a tus fuentes de datos, ejecuta siempre tus canalizaciones desde una instancia privada en tu entorno de ejecución.
En la versión 6.4 de Cloud Data Fusion, cuando diseñas tu canalización, no puedes acceder a las fuentes de datos en la Internet abierta desde una instancia privada. En su lugar, debes diseñar tu canalización en un proyecto de usuario mediante una instancia pública para conectarte a las fuentes de datos en Internet. Después de compilar tu canalización, muévela a un proyecto de cliente y ejecútala en una instancia privada para que puedas controlar las políticas de VPC. Debes conectarte a tus datos desde ambos proyectos.
Acceso a las fuentes
Si el entorno de ejecución se ejecuta en una versión de Cloud Data Fusion anterior a la 6.4, solo puedes acceder a los recursos dentro de la red de VPC. Configura Cloud VPN o Cloud Interconnect para acceder a las fuentes de datos locales. Las versiones de Cloud Data Fusion anteriores a la 6.4 solo pueden acceder a las fuentes en la Internet pública si configuras una puerta de enlace de Cloud NAT.
Cuando accedas a fuentes de datos, instancias públicas y privadas, haz lo siguiente:
- Realiza llamadas salientes a las API de Google Cloud mediante el Acceso privado a Google
- Comunícate con un entorno de ejecución (Dataproc) a través del intercambio de tráfico de VPC
En la siguiente tabla, se comparan instancias públicas y privadas durante el diseño y la ejecución de varias fuentes de datos:
| Fuente de datos | Instancia pública de Cloud Data Fusion (tiempo de diseño) |
Dataproc público de Cloud Data Fusion (ejecución) |
Instancia privada de Cloud Data Fusion (tiempo de diseño) |
Dataproc privado de Cloud Data Fusion Dataproc (ejecución) |
|---|---|---|---|---|
| Fuente de Google Cloud (después de otorgar permisos y configurar reglas de firewall) |
||||
| Fuente local (después de configurar la VPN/la interconexión, otorgar permisos y establecer reglas de firewall) |
||||
| Fuente de Internet pública (después de otorgar permisos y configurar reglas de firewall) |
versiones ≥ 6.4 versiones < 6.4 |
¿Qué sigue?
- Control de acceso en Cloud Data Fusion
- Cuentas de servicio en Cloud Data Fusion
- Crea una instancia pública
- Crea una instancia privada